Scrapy入门-爬取需要登录后才能访问的数据
本篇是Scrapy入门系列第四篇,建议读者依顺序循序渐进阅读,有任何疑问可以在评论区留言。另外,您的支持是我坚持更新的最大动力,右上角点关注给个鼓励吧。
前面几篇文章抓取的均是公开的数据,即没有控制访问权限即可浏览的数据。但还是存在一些网站(比如教学管理系统、内部论坛等),它会首先要求你登录,然后才能访问到后续的内容。这种情况下,就要首先解决登录授信的问题。在开始编码实现前,我们先了解下登录授信的原理。
Cookie
Cookie,引用百度百科的定义“是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息”。网站就是判断一个请求里带的cookie是否有效,来判断客户请求是否已登录过,来避免每次访问一个新的网页,都要求重新登录(这样就反人类了)。
那客户端是如何拿到cookie的呢,下面是一个流程图。
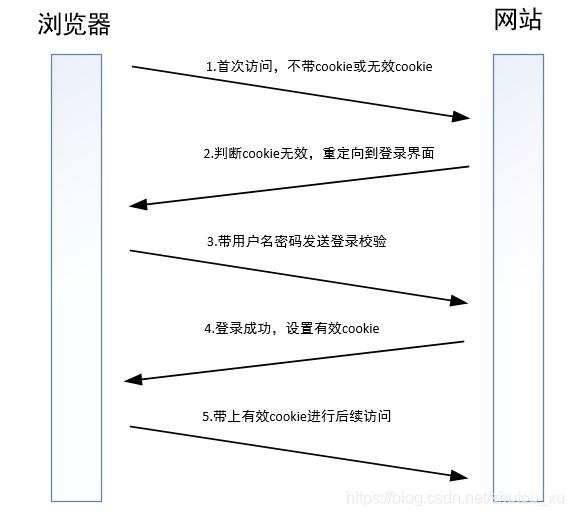
如上图所示,客户端的cookie是网站验证你的登录请求成功后,在应答的Set-Cookie域里面设置,客户端收到后会记录在本地,并在后续的请求中带上。
所以,要实现模拟登录抓取数据,有两个思路。一是我们的程序就要模拟上面流程图的第3步和第4步,获取一个有效的cookie。二是先通过浏览器登录网址获取到cookie,再复制到我们的抓取脚本中。这两个方式各有优劣,下面我们依次来看下。
发包模拟登录
这是最正统的方法,脚本完成后可以自动化运行,也不用担心cookie过期等问题。但是就是技术门槛比较高,特别是带验证码(特别是一些复杂验证码,如滑动拼图,选择图片等)的登录,非常难以实现。还有的在客户端发包时就会对密码进行加密(不依赖https),这样就成为更难逾越的鸿沟。
我们以豆瓣网为例(因为它比较简单),来介绍下scrapy框架如何实现登录。
首先是尝试登录豆瓣网,利用F12开发者工具查看请求送的字段。
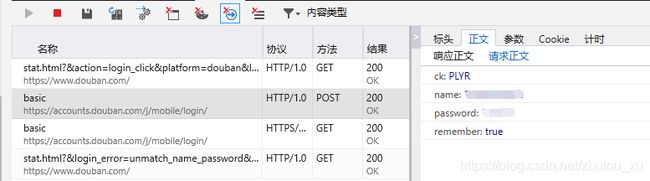
下面我们开始编码,编码思路就是首先访问豆瓣登录界面,再模拟发送登录验证POST请求,登录成功后,再访问账户个人订单界面(带上登录返回的cookie信息),验证cookie有效性。Scrapy项目的生成以及常规前置工作在前面几篇文章已详细说明,这里不再赘述。
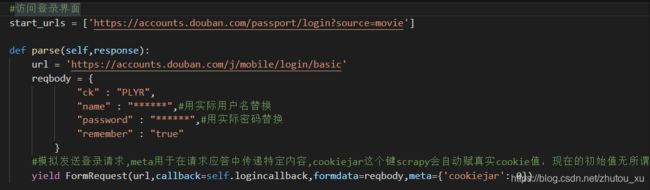
如上图所示,我们使用了FormRequest构造了一个POST请求,请求字段就是我们在浏览器看到的。这里注意要定义一个特殊的meta元素cookiejar,meta是用于在请求应答中传递数据的字典,针对cookiejar这个特色键,scrapy会自动赋登录返回的cookie值,现在的初始值无所谓,我们填0
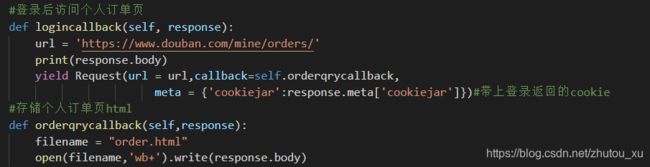
如上图所示,登录后我们用一个GET请求访问个人订单页,这里就用上了meta里的cookiejar的值,在新的请求包里带上了应答的cookie。Scrapy运行输出如下:
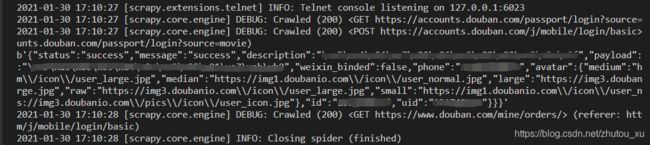
手动带上cookie发包
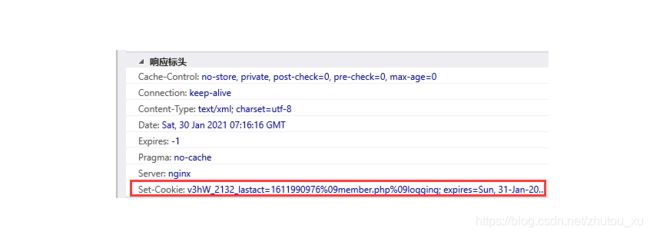
手动带上已知有效的cookie是一种最快捷的方式,很适合在临时抓包或者验证码难以处理的情况下。缺点就是cookie容易过期,需要重新设置。如下图所示我们首先用浏览器登录后访问网页,复制请求包里的Cookie字段值。
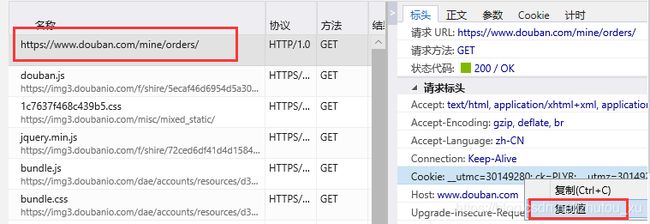
在爬虫的settings.py文件中,设置请求头的cookie为复制的值,这里要注意同步把COOKIES_ENABLED开关置为False,让scrapy不再对cookie进行额外处理。

爬虫的主体逻辑就非常简单了,直接访问需要爬取的页面即可,不用其余处理。

本文介绍了两种模拟登录后爬取网站数据的方法,对于模拟发包进行登录,由于验证码机制,难度会比较大,需要一定的技术深度。后面笔者还会推出扫码登录、cas单点登录、自动图片验证码识别登录等文章,可以关注我不错过后续精彩。赏个赞和推荐吧!