高性能小模型SLM最新优化方案和热门应用盘点,附配套模型和开源代码
当大多数人都还在卷谁的大模型参数规模大的时候,聪明人已经开始搞“小模型”了(doge)。
这里的小模型指的小型语言模型(Small Language Model,简称SLM),通常用于解决资源受限或实时性要求较高的场景,比如一些边缘设备(智能手机、物联网设备和嵌入式系统等),大模型难以运行其上。
目前我们对大模型的探索已经到了瓶颈,因高能耗、巨大的内存需求和昂贵的计算成本,我们的技术创新工作受到了挑战与限制。而对比大模型,小模型耗资少、响应快、可移植性强、泛化能力高...在一些特定情况下,可以提供更高效、更灵活的选择。因此,更多人开始着眼于小巧且兼具高性能的小模型相关的研究。
我今天就帮同学们整理了目前效果不错的高性能小模型,以及一些优秀的小模型性能优化方案和应用成果,包括研究者们在大模型与小模型结合方面做出的尝试。原文共16篇。
这些模型与方案的配套论文和项目代码我全都打包完毕,需要的同学看看文末
高性能小模型
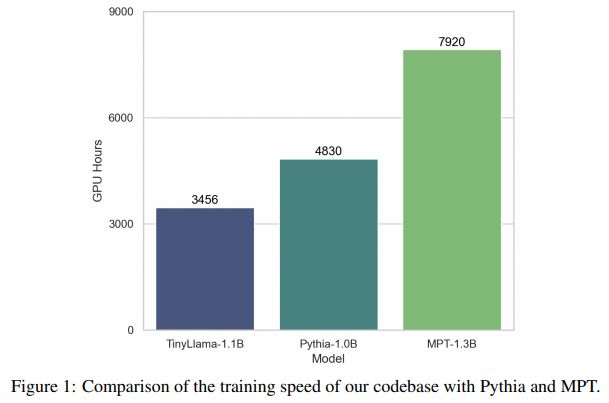
TinyLlama-1.1B
论文:TinyLlama: An Open-Source Small Language Model
一个开源的小型语言模型
「模型简介:」本文介绍了TinyLlama小型语言模型,该模型在大约1万亿个标记上进行了约3个周期的预训练,具有紧凑的1.1B参数规模。TinyLlama基于Llama 2(Touvron等人,2023b)的架构和分词器构建,利用了开源社区贡献的各种先进技术(例如FlashAttention(Dao,2023)),实现了更好的计算效率。尽管其规模相对较小,但TinyLlama在一系列下游任务中表现出色,显著优于现有规模相当的开源语言模型。
LiteLlama
「模型简介:」SLM-LiteLlama是对 Meta AI 的 LLaMa 2 的开源复刻版本,但模型规模显著缩小。它有 460M 参数,由 1T token 进行训练。LiteLlama-460M-1T 在RedPajama数据集上进行训练,并使用 GPT2Tokenizer 对文本进行 token 化。作者在 MMLU 任务上对该模型进行评估,结果证明,在参数量大幅减少的情况下,LiteLlama-460M-1T 仍能取得与其他模型相媲美或更好的成绩。

Phi-1、Phi-1.5、Phi-2
论文:Textbooks Are All You Need II: phi-1.5 technical report
phi -1.5技术报告
「模型简介:」本文继续研究基于Transformer的小型语言模型的能力。之前的工作包括一个1000万参数的模型,可以产生连贯的英语,以及一个13亿参数的模型,其Python编程性能接近最先进水平。作者采用了“Textbooks Are All You Need”的方法,专注于自然语言中的常识推理,并创建了一个新的13亿参数模型,名为phi-1.5。该模型在自然语言任务上的性能与大5倍的模型相当,在更复杂的推理任务上超越了大多数非前沿的大型语言模型。

RoBERTa
论文:RoBERTa: A Robustly Optimized BERT Pretraining Approach
一种鲁棒优化的BERT预训练方法
「模型简介:」本文介绍了BERT预训练的复制研究,仔细测量了许多关键超参数和训练数据大小的影响。作者发现BERT的训练不足,并且可以匹配或超过所有在其之后发布的模型的性能。作者的最佳模型在GLUE、RACE和SQuAD上取得了最先进的结果。这些结果强调了以前被忽视的设计选择的重要性,并对最近报告的改进来源提出了质疑。

FLAME
论文:FLAME: A Small Language Model for Spreadsheet Formulas
一种用于电子表格公式的小型语言模型
「模型简介:」FLAME是一个专为电子表格公式设计的轻量级语言模型。它基于Transformer架构,通过在Excel公式上训练,实现了高效、精准的公式创作和修复功能。与大型语言模型相比,FLAME具有更小的参数规模(60M)和更少的训练数据需求,同时保持了出色的性能。通过利用领域知识,FLAME在公式修复、补全和检索方面超越了其他大型模型,如Codex的Davinci和Cushman变体以及CodeT5。

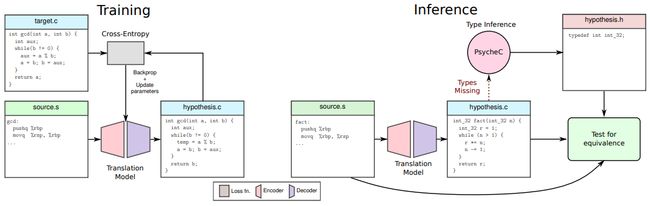
SLaDe
论文:SLaDe: A Portable Small Language Model Decompiler for Optimized Assembly
用于优化汇编的便携式小型语言模型反编译器
「模型简介:」SLaDe是一个针对优化汇编的便携式小型语言模型反编译器。它基于Transformer架构,通过在真实世界的代码上进行训练,并使用类型推理引擎,能够生成更可读和更准确的程序。与传统的反编译器相比,SLaDe能够推断出上下文之外的类型,并生成正确的代码。在评估中,SLaDe在4000多个ExeBench函数上的准确度比最先进的工业级反编译器Ghidra高出6倍,比大型语言模型ChatGPT高出4倍,并且生成的代码更易于阅读。
大模型结合小模型
Small Models are Valuable Plug-ins for Large Language Models
小模型是大型语言模型的有价值的插件
「简述:」论文介绍了一种名为Super In-Context Learning(SuperICL)的方法,它允许黑盒大型语言模型与本地微调的小型模型一起工作,从而在监督任务上获得更好的性能。作者的实验表明,SuperICL可以提高性能,超越最先进的微调模型,同时解决上下文学习中的不稳定性问题。此外,SuperICL还可以增强小型模型的能力,例如多语言性和可解释性。

An Emulator for Fine-Tuning Large Language Models using Small Language Models
使用小型语言模型微调大型语言模型的模拟器
「简述:」论文介绍了emulated fine-tuning(EFT)方法,用于分离大型语言模型预训练和微调阶段获得的知识与技能。作者使用强化学习框架,引入了一种模拟预训练和微调不同规模结果的方法。实验表明,扩大微调规模可以提高帮助性,而扩大预训练规模可以提高真实性。此外,EFT还能够在测试时调整竞争性行为特征,而无需额外的训练。最后,作者提出了一种特殊形式的EFT,称为LM up-scaling,通过将小型微调模型与大型预训练模型进行集成来提高指令遵循模型的帮助性和真实性,而无需额外的超参数或训练。

优化方案与热门应用
Orca 2: Teaching Small Language Models How to Reason
教小型语言模型如何推理
「简述:」Orca 2是一个教小型语言模型如何推理的系统。它继续探索如何通过改进训练信号来增强小型LM的推理能力。与之前的系统不同,Orca 2不仅模仿大型模型的输出,还教小型模型使用不同的策略来处理不同的任务。这种策略选择基于每种任务的最有效解决方案。Orca 2在15个基准测试中表现出色,超越了类似大小的其他模型,并在评估高级推理能力的复杂任务上达到了与大5-10倍的模型相似的性能水平。

It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners
小型语言模型也是少量学习者
「简述:」论文介绍了一种名为“绿色语言模型”的小型语言模型,它可以通过将文本输入转换为包含任务描述的填空问题,并结合基于梯度的优化来实现与GPT-3类似的性能。这种小型语言模型的参数数量比大型语言模型小几个数量级,因此更加环保且易于使用。此外,利用未标记的数据可以进一步提高其性能。作者还指出了成功实现自然语言理解所需的关键因素。

FINETUNED LANGUAGE MODELSARE ZERO-SHOT LEARNERS
微调语言网络 FLAN
「简述:」论文介绍了一种简单的方法来提高语言模型的零样本学习能力。作者通过指令微调——在一系列数据集上对语言模型进行微调,这些数据集用自然语言指令模板描述——显著提高了未见过的任务的零样本性能。作者将这个经过指令微调的模型称为FLAN,并在多个NLP数据集上进行评估。结果显示,FLAN比未经修改的对应模型和GPT-3的少数样本表现更好。该方法的关键因素包括微调数据集的数量、模型规模和自然语言指令。

Transcending Scaling Laws with 0.1% Extra Compute
用 0.1% 的额外计算超越缩放定律
「简述:」论文介绍了UL2R方法,可以在少量额外计算和不需要新数据的情况下,通过在几个步骤上继续训练最先进的大型语言模型(如PaLM)来显著提高现有语言模型及其缩放曲线的性能。作者介绍了一组新的模型,称为U-PaLM,其规模分别为8B、62B和540B。令人印象深刻的是,在540B规模下,U-PaLM实现了与最终的PaLM 540B模型相同的性能,但只花费了大约一半的计算预算。该方法证明了U-PaLM在许多自然语言处理任务中具有更好的性能。

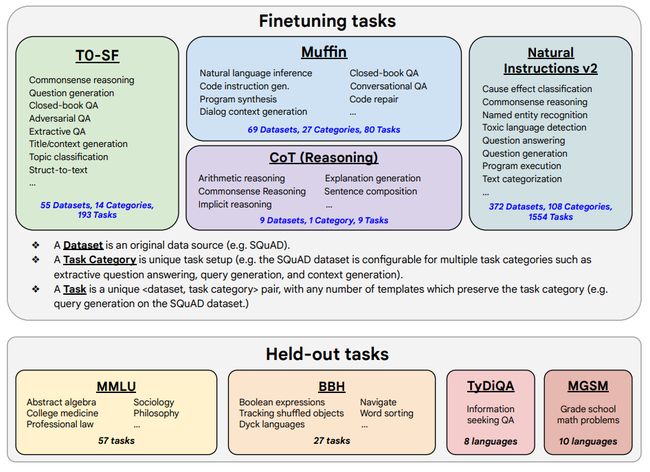
Scaling Instruction-Finetuned Language Models
扩展指令微调语言模型的规模
「简述:」指令微调是一种改进语言模型性能的方法。通过在指令形式的数据集上进行微调,可以提高模型对未见任务的泛化能力。本文重点探讨了三个方面的扩展:任务数量、模型规模和思维链数据上的微调。研究发现,这些方面的指令微调可以显著提高各种模型类别、提示设置和评估基准的性能。Flan-PaLM 540B在多个基准测试中取得了最佳性能,如五次射击的MMLU测试中达到了75.2%的准确率。此外,作者还公开了Flan-T5的检查点,即使与更大规模的模型相比,它也具有出色的少量样本性能。
LLaVA-ϕ: Efficient Multi-Modal Assistant with Small Language Model
具有小型语言模型的高效多模态助手
「简述:」论文介绍了LLaVA-ϕ高效多模态助手,它使用小型语言模型Phi-2来促进多模态对话。研究表明,即使只有2.7B参数的更小的语言模型,只要使用高质量的语料库进行训练,也可以有效地参与涉及文本和视觉元素的复杂对话。该模型在公开可用的基准测试中表现出色,并在实时环境中进行交互的系统和应用方面具有潜力。

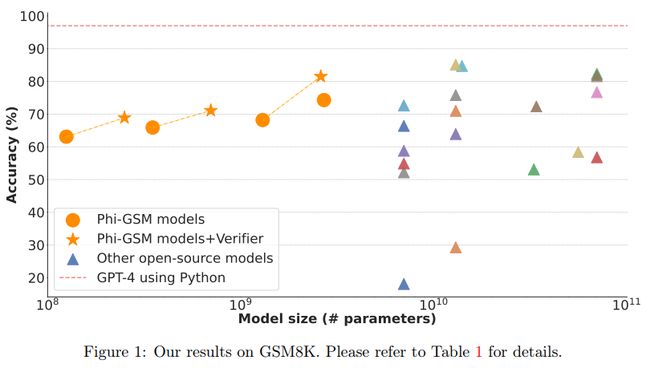
TinyGSM: achieving > 80% on GSM8k with small language models
使用小型语言模型在GSM8k上实现> 80%的性能
「简述:」论文介绍了TinyGSM方法,使用小型语言模型来解决小学数学问题。作者提出了一个由12.3M个小学数学问题和相应的Python解决方案组成的合成数据集TinyGSM,完全由GPT-3.5生成。在经过微调后,作者发现一个由两个参数为1.3B的模型组成的对可以实现81.5%的准确性,超过了现有模型几个数量级。该方法非常简单,包括两个关键组件:高质量的数据集TinyGSM和使用验证器从多个候选生成中选择最终输出。
Length-Adaptive Distillation: Customizing Small Language Model for Dynamic Token Pruning
为动态标记剪枝定制小型语言模型
「简述:」长度自适应蒸馏方法可以帮助加速模型推理,通过让小型语言模型更适应动态标记剪枝来提高速度。它包括两个阶段的知识蒸馏框架,第一阶段是模仿和重建教师模型的输出,第二阶段是适应标记剪枝并吸收特定任务的知识。这种方法可以使小型语言模型更加定制化,并在速度和性能之间实现更好的权衡。在GLUE基准上的实验结果证明了这种方法的有效性。

关注下方《学姐带你玩AI》
回复“小模型”获取全部论文+代码
码字不易,欢迎大家点赞评论收藏