《iOS应用开发》——2.2节九个基本的程序构建块
本节书摘来自异步社区《iOS应用开发》一书中的第2章,第2.2节九个基本的程序构建块,作者【美】Richard Warren,更多章节内容可以访问云栖社区“异步社区”公众号查看
2.2 九个基本的程序构建块
iOS应用开发
我不跟你开玩笑。Objective-C的先前版本学起来非常艰难。一些方面,诸如内存管理,我们只能机械地按照一系列严格的规则来练习。即使是那样,你也很容易出错,导致程序故障、错误以及崩溃。幸运的是,苹果公司持续改进了Objective-C语言并且减少了它的复杂性。因此,我们就只需要花更少的时间驯服程序语言,而有更多的时间来解决实际问题。
然而,如果你之前没有做过任何面向对象编程,那么你可能会有点头大了。有很多需要掌握的新概念:类、对象、子类、父类、重载方法等。
另一方面,有其他面向对象的程序开发经验也未必如你期望的帮助那么大。Objective-C处理对象的方式和Java、C++等语言还不太一样。过多地依赖你之前的经验或许会让你误入歧途。
说了这么多,其实你只要真正记住九个关键要素就可以了。这些要素是创建其他任何事物的基础:标准C数据类型、结构、枚举、函数、运算符、对象、方法、协议以及类别/扩展。一旦你弄清楚了这些(并且最重要的是弄清楚它们之间的区别),你就掌握了90%的内容了。
总体来说,这些要素可以被分为两类:数据和过程。数据(C数据类型、结构、枚举以及对象)代表了我们要处理的信息。如果你将Objective-C代码和英语语句类比,数据就相当于名词。而另一类,过程(C运算符、函数以及方法)就是过程,即操作或者变换数据。它们相当于动词。我们的应用程序本质上来说就是一系列定义数据和操作数据的步骤。
2.2.1 C数据类型
Objective-C是建立在C编程语言基础上的。因此,C数据类型是可用的最基本的程序构造要素。其他的数据结构仅仅是将C数据类型以更复杂的形式组合在一起的高级技术。
所有的C数据类型本质上都是固定长度的0和1的二进制串,它们可以是8位、16位、32位或者64位长。不同的数据类型定义了我们如何解释那些二进制位。首先,我们将数据类型划分成两大类:整型和浮点型(见表2.1)。
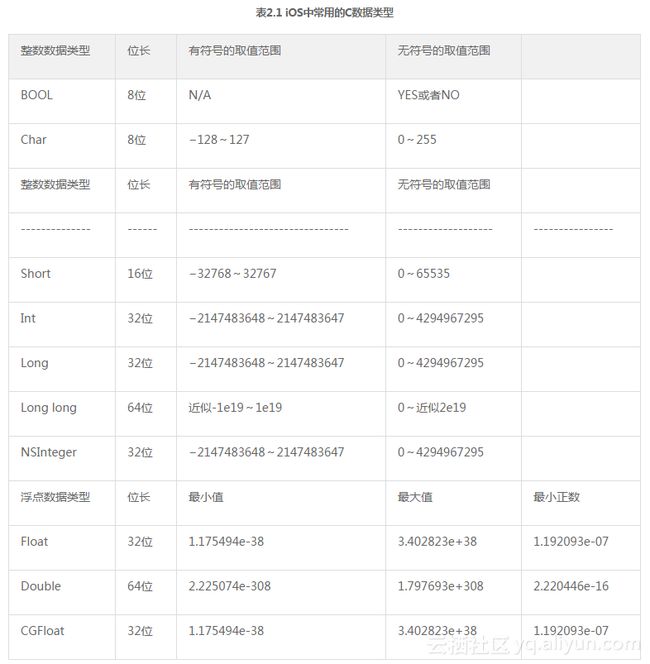
整型是用来储存离散信息的。在大多数情况下这代表了正的和负的整数值,但有时也能代表其他的符号信息(例如BOOL被用来代表YES和NO值,而char被用来代表ASCII字符)。整数类型包含BOOL、char、short、int、long和long long数据类型。这些数据类型之间的区别就是它们表示每个值时所用的二进制数据位数数量。占用的位数越多,可以代表的值的范围就越大,然而,数据也就占用了更大的存储空间。离散的值可能会是带符号的或者不带符号的变量。这决定了数值是如何被解释的。带符号的数据类型可以是正值或者负值,而不带符号的数据类型总是0或者更大的值。
注意:
数据类型的具体尺寸大小既取决于你使用的编译器,也取决于目标平台。例如,int数值可以是32位长的,也可以是64位长的。所以,你的程序不应该假设数值的位长,也不应该假设每个数据类型的最小值和最大值。而是在运行时使用sizeof()函数和定义在limits.h和float.h中的宏指令来确定这些数值。*
浮点数(float和double)用来近似表示连续数值——基本上是任何有小数点的数。这里我就不多讲小数数值的理论和实践了,你可以去找一本导论性的计算机科学教材来查看所有不懂的细节。只需要知道,小数数值都只是近似值就可以了。两个完全相等的数学公式很有可能产生非常不同的结果。然而,除非在做精确的科学计算,否则的话只有可能在比较数值的时候会出错。例如,你可能是想要得到3.274,但是你的表达式返回的结果是3.2739999999999999。虽然这两个数值不相等,但是也非常近似了。你能够注意到的区别可能只是四舍五入的错误。因此,你应该检查看看你的值是不是在一个有效的范围内(3.2739 < x < 3.2741),而不是去寻找严格相等的值。
C有两种浮点型:float和double。顾名思义,double是float的两倍长。额外的尺寸既扩大了数值的范围,并且也提高了数值的准确度。由于这个原因,我们通常都会用double而不用float。在有些程序语言中,这是正确的惯用法。我在写Java语言时用过float数据类型的次数屈指可数。然而在Objective-C中,float更加常用。
事实上,尽管C数据类型很多,我们经常使用的只有BOOL、int和floats。然而,我们经常感觉使用了很多数据类型,那是因为core框架库频繁地使用typedef为int和float(或者偶然还有其他数据类型)创建别名。有时候这么做是为了提供一致性以及提高在不同平台之间移植性。例如,CGFLoat和NSInteger的大小都被定义成目标处理器的整数类型的大小(32位或者是64位)。其他条件相等的情况下,这些值将会是特定的处理器中最高效的数据类型。其他数据类型被定义为能更好地传达它们意图的形式,例如NSTimeInterval。
你可以通过文档来看看这些数据类型是如何被定义的。例如,在Xcode中,通过在Help菜单选择Documentation and API Reference,就可以打开文档。你可能需要在文档中查找一会儿,你会在Reference > Foundation Data Type Reference > NSTimeInterval中找到关于NSTimeInterval的描述,定义如下:
typedef double NSTimeInterval;正如你所看到的,NSTimeInterval只是double的一个别名。
2.2.2 C数据结构
简单的数据类型总是好的,但是我们经常需要将数据组织成复杂一点的结构。这些结构大致分为三个主要类别:指针、数组和结构体。
指针
指针是最简单的数据类型,至少在概念上是最简单的。本质上来说,指针是指向一个值的内存地址的变量。它允许对数值的间接访问和修改。
你可以通过在类型声明和变量名称之间加一个星号来声明一个指针。你也可以在变量名称之前使用星号来解引用指针(来设置或者读取那个地址空间的值)。同样地,在一个常规变量之前添加一个&记号,可以取得该变量的地址。你也可以做一些疯狂的尝试,比如创建指针的指针,用来增加一层间接引用。
int a = 10; // 创建变量a
int* b = &a; // 创建指针b, 指向变量a的地址
*b = 15; // 将变量a的值变为15
int** c; // 创建一个指向int类型的值的指针的指针注意:
当你声明一个指针时,编译器不会为它指向的值申请内存空间。它只会请求足够的空间来储存内存地址。你可以用指针来指向一个实际存在的变量(正如我们在上述例子中所做的)或者手动在堆上管理它的内存。我们在本章后面的部分讨论内存管理的时候将会更加深入地讨论这个问题。
就它们本身而言,指针并不有趣;然而,它们是更加复杂的数据结构的基础。此外,指针虽然在概念上来说非常简单,其实很难掌握。指针通常是程序故障的来源,并且这些故障非常不容易被找到和修复。对指针更加全面的讲述不在本章的范围内。幸运的是,正常情况下我们只在引用Objective-C对象的时候才会使用指针,并且这些对象大部分都会有自己的语法。
数组
数组允许我们定义一系列固定长度的值。所有这些值都应该是同一个类型的。例如,如果我们需要一组10个整数值,我们仅需像下面这样定义:
int integerList[10]; // 声明一个包含10个整数的数组
我们可以通过把想要访问的索引放置在方括号中来访问数组中的成员。需要注意的是,数组的是索引是从0开始的。第一项是0而不是1。
integerList[0] = 150; // 设置数组的第一项
integerList[9] = -23; // 设置数组中的最后一项
int a = integerList[0]; // 将a设置为150
我们还能使用C常量数组语法来声明有初始值的数组。我们将常量数组写在一对花括号里,值使用逗号分隔。
int intList2[] = {15, 42, 9}; // 隐式地声明一个包含3个整数的数组
// 接着使用常量数组设置它们的值
上例所示,我们甚至不需要定义intList2的长度。它的长度自动设置为与常量数组相同的长度。或者,你也可以明确地设置intList2的大小,但是它必须等于或者大于常量数组的长度。
数组同样也被用于代表C类型的字符串。例如,如果你想要在C语言中存储某人的姓名,你通常会将其存储为一个char类型的数组。
Char firstName[255];由于C类型的字符串是基于数组的,所以它们有固定的大小。这将导致一个非常常见的错误根源。是的,254个字符应该足够来储存大多数人的姓名了,但是你总会碰到一个需要255个字符的人名(更不用提国际字符集了)。
正如这个例子所示,字符串不需要用完整个数组,但是它必须控制在所分配的内存空间之内。事实上,数组的大小必须等于或者大于字符串中的字符数量+1。C类型的字符串总是以一个空字符结尾。
字符串值可以通过常量字符串(即在任何值上加上双引号)赋值。C语言自动追加空字符。在下面这个例子中,s1和s2是完全一样的。
char s1[5] = "test";
char s2[5] = {'t', 'e', 's', 't', '\0'};注意:
‘A’和“A”是完全不同的数据类型。在C语言中,单引号是用来表示char字符值的。因此,‘A’是一个值为65的char字符(大写字母A的ASCII值)。另外,“A”是值为{‘A’,‘0’}的char字符组成的数组。
类似指针,数组也可以变得非常复杂,尤其是将它们传入或者从函数返回的时候,另外,我们还没有开始讨论类似多维数组和动态数组的高级话题。幸运的是,除非你要调用C程序库,我们几乎不会在Objective-C中用到数组。作为替代,我们将会使用Objective-C的集合类(NSArray、NSSet或者NSDicitionary)。对于字符串,我们将会使用NSString。
结构体
结构体是最灵活的C数据类型。虽然数组允许声明同一组相同类型的数据,然而结构体却可以让我们将不同类型的数据组合在一起,并且可以使用名称来访问这些数据。并且,不像C风格数组,Cocoa Touch大量使用了C结构体。特别是,很多核心框架库全部是用纯C编写的,使得这些库在Cocoa(Objective-C)和Carbon(C语言)项目中都可以使用(Carbon是一个比较老的技术,现在还在MAC OS X桌面应用程序中时有用到)。
为了看一个比较典型的结构体,在Xcode参考文档中查找CGPoint。你将会看到它的声明如下:
struct CGPoint {
CGFloat x;
CGFloat y;
};
typedef struct CGPoint CGPoint;首先,框架库创建了一个叫做CGPoint的结构。这个结构有两个域:x和y。在这个例子中,两个域碰巧都是同样的数据类型(CGFloat)。
接着,我们用typedef来定义一个叫做CGPoint的类型。这是CGPoint结构体的别名。这也许看起来会很奇怪,但其实是很有帮助的。如果没有使用typedef定义别名,那么在我们的代码中只能一直使用“struct CGPoint”来引用这个结构体。不过,现在我们就可以简化掉struct关键词,将它看作和其他任何一种数据类型一样的类型。
你可以像下面这样访问域:
CGPoint pixelA; // 创建CGPoint变量
pixelA.x = 23.5; // 设置x域
pixelA.y = 32.6; // 设置y域
int x = pixelA.x; // 从x域读取值苹果公司的框架库通常会同时提供数据结构和一组函数来操作它们。如果可能,参考文档会将相关的结构体和程序组织在一起。对于任何一个结构体类型,苹果公司都提供了一个方便的方法用来创建它的实例,一个方法用来比较结构体,以及对这个结构体执行常见操作的一些方法。对于CGPoint来说,这些方法包括CGPointMake()、CGPointEqual ToPoint()和CGRectContainsPoint()。
当结构变得越来越复杂的时候这些程序会显得更加重要。举个例子:CGRect结构体,这个结构体也有两个域:origin和size。然而这两个域各自本身又都是结构体。Origin是CGPoint,而size是一个CGSize。
下面的代码展现了3种创建一个CGRect结构体的方法。3种方法都是等效的。
CGRect r1;
r1.origin.x = 5;
r1.origin.y = 10;
r1.size.width = 10;
r1.size.height = 20;
CGRect r2 = CGRectMake(5, 10, 10, 20);
CGRect r3 = {{5, 10}, {10, 20}};尤其要注意我们是如何用结构常量来创建r3的。理论上来说,这些很简单。每一组花括号代表了一个结构(正如之前代表常量数组的花括号一样)。用逗号分隔的列表代表了域声明的顺序。
因此,外边的花括号代表CGRect的结构。里边的第一对花括号是origin,第二对是size。最后,从两个里面的两个结构体里获得域的值。CGRect还不是特别复杂,随着我们的结构变得复杂,常量结构体的结构也会变得越来越难懂。一般而言,我只会使用常量结构体来创建简单的数据结构和数组。其他时候,我会使用帮助函数(例如r2所示)来快速创建结构,并且在需要额外灵活性的时候我就采用直接赋值(例如r1所示)。不过,以后你不可避免地会接触到使用了结构体常量的第三方代码,因此你应该能够识别它们。
注意:
如果你在编译使用了自动引用计数(ARC)的应用程 序(本书中我们将会在所有的应用程序中使用ARC),你不能将Objective-C的对象储存在一个结构体内。相反,你应该用Objective-C类来管理这些数据。为了使用自动内存管理,我们需要遵守几个规则。我们会在本章后面的“内存管理”章节详细探讨。
2.2.3 枚举类型
假设我们想要在代码中表示周一到周日。我们可以使用字符串并且拼出这些单词。但是在使用这个方法时,会存在几个问题。首先,它需要额外的内存和计算来存储和比较日期。此外,字符串的比较非常微妙。Saturday、saturday和SATURDAY都是代表的同一天吗?如果你拼错了某天的名字怎么办?如果你输入了一个和有效日期不匹配的字符串怎么办?一个可选的办法就是手动为每个日期分配一个无符号的char类型值。在这个例子中,关键字const告诉编译器这些值在被初始化以后就不能再改变了。
const unsigned char SUNDAY = 0;
const unsigned char MONDAY = 1;
const unsigned char TUESDAY = 2;
const unsigned char WEDNESDAY = 3;
const unsigned char THURSDAY = 4;
const unsigned char FRIDAY = 5;
const unsigned char SATURDAY = 6;
const unsigned char HUMPDAY = WEDNESDAY;这样也可行,但是没有办法将这些日期作为一个组。例如,你不能指定一个函数的参数必须是一周当中的某一天。这种情况下就产生了枚举。枚举为定义一组离散值提供了一个简洁、优雅的方法。例如,一周当中的每天可以这样表示:
typedef enum {
SUNDAY,
MONDAY,
TUESDAY,
WEDNESDAY,
THURSDAY,
FRIDAY,
SATURDAY
} DAY;
const DAY HUMPDAY = WEDNESDAY;正如先前在结构体的例子中所提及的,我们同样也用typedef来声明我们的枚举类型。在这个例子中,我们在typedef中嵌套了枚举的声明。两种方式都是完全有效的C语言代码。此外,我们还可以给枚举一个名称(例如,typedef enum DAY{…}DAY;),不过我们总是通过类型的名称来访问它,所以给枚举一个名称似乎是多余了。
现在,这和无符号的char字符例子不是完全一样了。枚举稍微多占用了一些内存。不过,它们肯定能更节省打字。更重要的是,枚举更好地表达了我们的意图。当我们将HUMPDAY定义为一个无符号的常量char字符时,也就是表明这个字符可能保存一个0~255之间的值。在枚举的例子中,我们会明确说出HUMPDAY只能被设置成DAY常量中的一个值。当然,你也可以设置一个无效值。
const DAY HUMPDAY = 143; // 虽然这也能正常编译
// 但这是错误的考虑到编码规范,为枚举类型赋值时最好要使用名称常量。尽管编译器不会发现赋值错误,但是它也会有助于发现其他方面的错误,尤其当枚举和switch语句结合使用时。
默认地,枚举将会给第一个常量赋值为0,并且一组常量中的值是逐一递增。此外,你也可以给一个或多个名称常量指定明确的值。你也可以给多个常量赋值相同的值,让它们互为别名。
typedef enum {
BOLD = 1;
ITALIC = 2;
UNDERLINE = 4;
ALL_CAPS = 8;
SUBSCRIPT = 16;
STRONG = BOLD
} STYLE;Cocoa Touch使用了大量的枚举类型。当你浏览iOS SDK时,你会发现两个常见的应用模式。首先,它在互斥的选项中使用枚举。这里,你只能从有限的选择中选出一个选项。我们的DAY枚举就是这样的。任何DAY变量或者参数只能保存一个DAY值。
其他情况,枚举代表了标志值,你能够使用它们组合形成更复杂的值。我们的STYLE枚举就是这种类型。我们通常会选择代表不同比特位的常量值。你可以用位操作运算符OR来组合这些常量值。同样,你也可以使用位操作运算符AND来分离它们。这让你能以单个变量来存储STYLE任何的组合值。
STYLE header = BOLD | ITALIC | ALL_CAPS; // 将风格设置为粗体
// 斜体并且所有都大写
if ((header & BOLD) == BOLD) { // 检查看看是否
//这里处理粗体文本 // 粗体位被设置了
}2.2.4 运算符
运算符是C语言预定义的一组编程单元。你可以用运算符来创建表达式,即电脑将会执行的一组命令。例如,表达式a = 5使用了赋值运算符来设置变量的值,使它等于常量值5。在这个例子中,= 就是运算符,a和5是操作数(也就是操作的对象)。
运算符实现了大量的任务,然而,大部分运算符都可以被归类为几大类:赋值运算符(=、+=、-=、=等)、算术运算符(+、-、、/、%等)、比较运算符(==、<、>、!=等)、逻辑运算符(&&、||、!)、位运算符(&、|、^)和关系运算符([]、*、&)。
还能以操作数的数量来对运算符进行归类。一元运算符只有单个操作数。运算符可以放置在操作数之前或者之后,取决于具体的运算符。
a++ // 变量值加1
-b // b的相反数。如果b等于5,那么-b等于-5
!c // 逻辑NOT。如果c是true,那么!c就是false
二元运算符有两个操作数,并且运算符一般都是放置在操作数之间。
a + b // 将两个操作数的值相加
a <= b // 如果a的值小于或等于b,那么就返回true
a[b] // 读取数组a中的索引为b的元素值
最后,C语言有唯一的一个三元运算符,即三元条件运算符。
a ? b : c // 如果a的值是true,那么返回b值,否则返回c值
注意:
在有些情况中,两个不同的运算符可能会用相同的符号。例如,乘和间接引用运算符都是用一个星号。编译器会根据操作数的数量来选择正确的运算符。例如在a=bc中,第一个星号是间接引用运算符(一元运算符),允许我们设置a指向的内存位置的值。第二个星号是相乘运算符(二元运算符)。
优先级
每一个运算符都有优先级,决定了它和其他运算符之间的优先关系。有着较高优先级的运算符先于优先级较低的运算符执行。这对于大多数人来说在小学数学课上就很熟悉了。乘法和除法较加法和减法来说就有着较高的优先级。
只要当一个表达式中还有一个以上运算符时(大部分表达式都不止一个运算符),你就必须考虑优先次序。比如这个简单的表达式a = b + c。加号首先执行,并且总和被赋值给a变量。
大多数情况下,优先级是有逻辑意义的。然而,存在很多的规则,并且有些规则会让人吃惊。你可以用圆括号让表达式以任意的次序执行。圆括号内的表达式会自动优先执行。因此,如果对运算符的优先级有疑问的话,就用圆括号吧!
当表达式求值时,计算机将会从最高优先级的操作数开始求值。然后就用这个值代替这个运算符和操作数,形成一个新的表达式。接着这个表达式会继续计算,一直到得出最后的值。
5 + 6 / 3 * (2 + 5) // 初始表达式
5 + 6 / 3 * 7 // 圆括号中的操作数首先被计算
5 + 2 * 7 // 当两个运算符有着相同的优先级时
// 从左向右运算
5 + 14 // 在做加法之前首先做乘法
19 // 最终的值这里有几条基本原则:任何在函数或方法的参数中的表达式都要在函数或方法调用执行之前进行求值。类似地,任何在数组下标索引值中的表达式都要在访问数组之前进行求值。函数调用、方法调用以及数组索引访问都在大多数其他运算符之前进行。赋值也在大多数(但不是全部)其他运算符之前进行。下面是一些例子:
a = 2 * max(2 + 5, 3); // max() 返回了变量中的最大值
// 变量a被赋值为14
a[2 + 3] = (6 + 3) * (10 - 7); // 索引值5的值被设置为27
a = ((1 + 2) * (3 + 4)) > ((5 + 6) * (7 + 8)); // 变量a被设置为false2.2.5 函数
函数对于C程序语言来说是程序的主要骨干。C应用程序大部分是由定义数据结构,然后编写函数来操作这些结构组成。
函数通常与结构体一起使用,尤其是在处理底层框架时。然而,你会发现有一些函数是专门设计与Objective-C对象结合使用的。事实上,我们在第1章中接触过这样一个函数:UIApplicationMain()。
和运算符不一样,函数可以由程序设计者来定义。这让我们可以封装一系列代码以便以后重用。
函数是在实现文件(文件名以.m结束)中定义的。它以函数签名开始,它定义了函数的名称、返回值以及函数的参数。参数写在圆括号内,以逗号分隔成一个列表,列表中,每个参数都声明了一个数据类型和一个名称。
紧跟在函数名后的是一对花括号。我们可以将任何数量的表达式放置在这个花括号中。当函数被调用时,这些表达式就以它们出现的顺序依次执行。
CGFloat calculateDistance(CGPoint p1, CGPoint p2) {
CGFloat xDist = p1.x - p2.x;
CGFloat yDist = p1.y - p2.y;
// 使用勾股定理计算距离
return sqrt(xDist * xDist + yDist * yDist);
}在上面的例子中,从左到右,CGFloat是返回值,calculateDistance是函数名,CGPoint p1和CGPoint p2是函数的两个参数。
在这个函数中,我们首先创建了两个局部变量。这些变量是存储在堆栈中的并且当程序返回时会被自动删除。我们将两点的x坐标和y坐标之间的差值赋给这些变量。
下面一行是空白的。空白会自动被编译器忽略,应该使用空格空行来组织代码,让代码更加容易跟踪和理解。接着就是我们的注释。编译器会忽略//符号后的任何内容一直到这一行的结尾,同样也会忽视/和/之间的任何内容,这就让我们能跨多行写一些注释。
最后,我们看到了return这个关键字。它对表达式求值后就退出函数,将表达式的值(如果有)返回给调用者。calculateDistance()函数使用勾股定理计算了两个点之间的距离。这里我们用乘法运算符对x和y的距离分别作了平方,并将它们加在一起。接着我们将得出的值传递给C语言数学库中的sqrt``()函数并且返回了结果。
你可以通过函数名,再加上使用圆括号括起来的以逗号分隔的一个参数值列表来调用函数。这些参数值可以是常量值、变量甚至是其他的表达式。不过,这个值的类型必须和相应的参数类型相匹配。C可以转换一些基本的数据类型。例如,在一个需要double类型参数的函数你可以传递一个int数据。如果这个函数返回了一个值,我们通常会将这个返回值赋值给变量或者在表达式中使用它。
不是所有的函数都有返回值。有一些函数会产生副作用(它们在应用中会产生某种持续的变化,有可能会将数据显示到屏幕上或者是改变我们的数据结构的某些内容)。例如,printf()函数可以用来将消息显示到控制台上。
CGPoint a = {1, 3};
CGPoint b = {-3, 7};
CGFloat distance = calculateDistance(a, b);
printf("The distance between (%2.1f, %2.1f) and (%2.1f, %2.1f)
→is %5.4f\n",
a.x, a.y,
b.x, b.y,
distance);在这个例子中,我们首先创建了两个点点结构体变量。接着我们调用了calculateDistance()函数,将a值赋给参数p1,b值赋给参数p2。然后我们将返回值赋给distance变量。最后,我们调用了printf()函数,传给它格式化字符串和我们的数据。
printf()函数从一个可变长度的参数列表创建它的消息。第一个参数是格式化字符串,后面跟着逗号分隔的值的列表。printf()函数将会扫描这个格式化字符串,查找占位符(即一个百分号后跟着一个或多个字符)。在这个例子中,我们用了%2.1f的格式转换说明符,它告诉printf()插入一个至少两位并且小数点后有一位数的浮点值。%5.4f的格式转换说明符表示有5位数字且小数点后有4位的浮点值。然后,printf()使用参数列表的值依次替换格式转换说明符。
如果你运行这段代码,它会将下面的消息显示在控制台上:“The distance between(1.0,3.0) and(-3.0,7.0)is 5.6569”。
最后,在C语言中你必须在函数被使用之前先定义它。大多数时候我们简单地把函数的声明放在相应的头文件中(文件名以.h结束)。函数声明就是函数签名之后加一个分号。
CGFloat calculateDistance(CGPoint p1, CGPoint p2);我们在应用程序中使用函数之前只需要导入头文件即可。
通过值传递
在C语言中,所有的函数都通过值来传递它们的参数。这意味着编译器会创建变量的本地副本。这些副本在函数中使用,当函数返回时就会从内存中删除。一般来说,这意味着你可以对本地副本做任何你想做的操作,而原始的值将会保持不变。这是一件很棒的事。看看下边这个例子。
void inner(int innerValue) {
printf("innerValue = %d\n", innerValue);
innerValue += 20;
printf("innerValue = %d\n", innerValue);
}
void outer() {
int outerValue = 10;
printf("outerValue = %d\n", outerValue);
inner(outerValue);
printf("outerValue = %d\n", outerValue);
}
这里,printf()将会用int值来代替%d格式转换说明符。调用outer()函数将会在控制台上显示下列消息:
outerValue = 10
innerValue = 10
innerValue = 30
outerValue = 10
正如你所见,当我们改变innerValue的值时outerValue保持不变。然而,这只是其一。考虑下面的代码:
void inner(int* innerPointer) {
printf("innerValue = %d\n", *innerPointer);
*innerPointer += 20;
printf("innerValue = %d\n", *innerPointer);
}
void outer() {
int buffer = 10;
int* outerPointer = &buffer;
printf("outerValue = %d\n", *outerPointer);
inner(outerPointer);
printf("outerValue = %d\n", *outerPointer);
}从表面上看,这看起来非常类似于前面的代码。不过,也有一些重要的区别。首先,我们创建了一个buffer变量并把其值设置为10。然后我们创建一个指向buffer的指针,并把该指针传入inner()函数。然后,inner()修改了innerPointer参数指向的值。这一次,我们可以得到下面的输出:
outerValue = 10
innerValue = 10
innerValue = 30
outerValue = 30这里,无论是innerValue还是outerValue都发生了变化。我们还是通过传值来传递参数。然而,这次的值是buffer变量的地址。Inner()函数得到了这个地址的一个副本,但是这个地址仍然指向内存中的同一块数据。当我们对指针解引用(无论是修改它还是打印出它的值),我们实际上是在访问buffer变量的值。
野指针
即使buffer变量在getPointer()方法结束时就会被删除,储存在内存中的实际值不会立即变化。有些时候,应用程序会重用这块内存空间,重写当前的值。然而,指针暂时会继续起作用,就像没有出错一样。
这是最糟糕的一种程序故障,这样的故障将来随时会导致应用程序崩溃。这个错误甚至会出现在完全不相关的代码部分。这种错误很难追查和修复。
说白了,函数可以通过指针参数变量来修改指向的值。这是非常重要的,因为不管是objective-C的对象还是C风格数组都是作为指针来传递的。每当你使用这些数据类型时,都必须避免意外修改了底层数据。
返回值同样也是通过值传递的,但由于函数在返回时已经删除了原始的值,这个过程又变得稍稍有点复杂。考虑下面的这个函数:
int* getPointer() {
int buffer = 100;
int* pointer = &buffer;
return pointer;
}当该函数被调用时,我们创建了一个名为buffer的局部变量,接着还创建了buffer的一个指针。接着函数返回了指针。正如我们先前所讨论的,指针被复制了,但是只是buffer的地址被复制了。新的指针仍然指向buffer。然而,当函数结束时,buffer被删除了。最后留下的这个指针只是指向了某个没有定义的内存块。
对象与类
当论及对象时,我们通常是指两个不同的方面:类和对象本身。类是定义。它描述了对象拥有的方法和实例变量。另一方面,对象是内存中的类的实例。你可以从一个类创建出多个对象,每个对象会有相同的一组特性,但是实例变量相互之间都是独立的。在一个对象上设置实例变量或者调用方法并不会影响由该类创建出来的其他对象。
可以这样认为:类是设计蓝图,对象是房子。同样一个蓝图,你可以建造几幢不同的房子。每个房子都有setThermostatToTemperature: 方法。但是,在我的房子里调用setThermostatToTemperature: 并不会影响你的房子里的恒温器设定。
2.2.6 对象
目前为止我们所讨论的语言特征都是来自于C语言的。然而,在介绍对象的过程中,我们将抛开C,进入Objective-C的世界。
从表面上来看,对象将结构体的数据管理和一系列相关的函数联系在一起(虽然在这种情况下我们称它们为方法)。从底层来看,这其实就是它们实现的方式。然而,对象给我们提供了一般C代码没有的几点优势。
封装
封装是面向对象代码的主要优点之一。对象应该隐藏它们大部分的复杂性,只需要公开供开发者有效使用该类的函数和变量。
换一种方式说,对象功能就像黑盒。它们有一个公开的接口,这个接口描述了外部能访问的所有方法和变量。对象的真正实现代码会包含任何数量的私有实例变量和方法;然而,如果你想要在你的代码中使用该对象,你应该不必了解任何这些实现的细节。
由于Objective-C是一种高度动态、反射的编程语言,公开接口更多的是一种建议而不是严格的教条。你能够访问隐藏的实例变量和方法,但是这么做会破坏封装性,这样做很糟糕。当然,短期内这样做也许让事情变得更简单了,但是你也有可能将自己带入长期的痛苦之中。
在理想的世界中,一个对象的接口应该保持不变。随着时间的推移,你可以添加新的方法,但是不能移除或者改变任何已有的方法。但是内部的实现细节是允许改变的。对象的开发者在不同版本中,可以完全重新设计和实现,只要你的使用该类的代码仅仅是通过接口和对象交互,那么一切都能继续正常运行。
当然,我们生活在现实世界中,我们经常需要改变对象的接口,尤其是在早期的开发过程中。如果仅有你自己一个人在使用这个对象,这就不是大问题,但是如果其他人也在使用你的类,那么你就需要和他们协调一下这些改变了。
举个例子,苹果公司偶尔也会将方法标记为已过时。虽然这些方法仍旧可以正常运行,但是,开发者们应该停止使用它们,因为它们在未来的发布版本中可能会被删除。这给了开发者们在这些变化生效之前重新设计应用程序的机会。
继承
继承性是面向对象代码的第二个主要优点。类可以继承另一个类的实例变量和方法,并且可以修改这些方法或者添加新的方法和实例变量,以便进一步特殊化新的类。最重要的是,我们仍然能在可以使用父类的地方使用子类。
比如说,我们有一个称为Vehicle的类。它包含了一个交通工具所有常见的一些特性:能让你设置或者获取司机、乘客、货物、当前位置、目的地等方法。甚至还有一些方法来查询交通工具的性能,比如:canOperateOnWater、canFly、cruiseSpeed等。
然后我们就可以创建都是从Vehicle继承而来的子类——Boat、Airplane和Car。Boat子类可以重载canOperateOnWater方法,返回YES。类似地,飞机可以重载canFly方法,返回YES。
最后,我们可以创建Car的子类Maserati和Yugo。Maserati的行驶速度会返回150MPH,而Yugo的速度将会返回15MPH(或者是相近的值,我确定)。
接着,让我们来看一下使用Vehicle的函数:canVehicleReach LocationInTime (Vehiclevehicle,Locationlocation,Timedeadline)。我们可以向这个函数传递Boat、Airplane、Car、Maserati,或者Yugo中的任何实例。类似地,我们可以向estimatedTimeToFinishIndy500 (Carsample Car)函数传递任意的Car、Maserati或者Yugo对象。
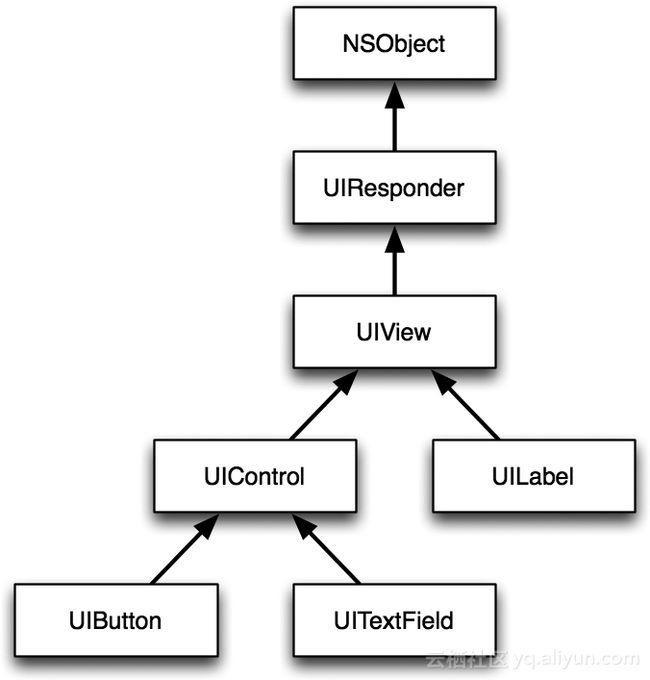
当接触到Cococa Touch视图对象时(见图2.1),我们就会频繁地使用继承和类层级。UIView继承了UIResponder,而UIResponder又是由NSObject继承而来。NSObject是一个根类,几乎所有其他的对象都是继承它而来。也有一些例外(例如NSProxy),但这些只是很特殊的情况。
NSObject根类确保了所有的对象都有一组基本的方法(内存管理、相等测试和类归属测试等)。接着,UIResponder给对象添加了响应运动和触摸事件的接口,让它们可以参与响应链。最后,UIView添加了在屏幕上管理和显示矩形区域的支持。
图2.1同样还显示了一些UIView的子类。正如你所看见的,一些屏幕元素(如UILabel)直接由UIView继承而来。其他的(UIButton``和UITextField)是由UIControl继承而来的,UIControl添加了注册事件的接收目标以及当事件发生时分发操作消息的支持。
抽象类
在我们的示例类层级中,Vehicle、Boat、Airplane和Car可以实现为抽象类。抽象类是不能被创建对象实例的(或者,至少不是常规的实例)。通常这个类中会有一个或更多的方法未被定义。要使用抽象类,你必须首先创建一个定义了所有需要定义的方法的子类。接着你就可以创建这个子类的实例了。
Objective-C没有为抽象类提供显式的支持。不过,我们可以通过在未定义的程序中抛出异常来创建准抽象类。查看一下NSCoder的参考文档,看看抽象类如何在实际中使用。
让我们来看一个具体的例子。UIView有一个名为addSubview:的方法。这个方法让你可以添加另一个显示在当前的视图里的UIView。由于UILabel、UIButton和UITextField都是由UIView继承而来的(无论是直接或间接的),它们都可以用addSubview:方法来添加。此外,它们同样也继承了addSubview:方法。理论上,你可以添加一个子视图到按钮或者文本字段中(虽然很难想象这个操作有什么用途)。更实际的是,子类同样也继承了UIView的frame属性。这让你可以在父类的坐标系统中设置子类的尺寸大小和位置。所有继承了UIView(无论是直接还是间接的)的类都包含frame属性。
浏览父类的方法
如果查看UIButton的类参考文档,你不会找到关于frame属性的任何信息。这是因为类参考文档仅仅记录了这个类新增声明的方法。因此,怎样才能找到继承来的所有方法呢?
在类参考文档的最顶端,你可以看见一行标示着“Inherits from”,列出了可以回到NSObject父类的完整继承链。慢慢由继承链往回查看,你可以查看所有可用的方法和属性。
实例化对象
Objective-C创建对象需要两个步骤。首先,你需要在堆上分配内存。接着,用对象的初始值来初始化这个内存区域。第一个步骤可以通过alloc类方法来完成。第二个步骤可以使用init或者这一族中的一个方法来完成。
例如,下边这行将会创建一个空的NSString对象:
NSString* myString = [[NSString alloc] init];这里有几个值得注意的重点。首先,我们将NSString变量声明为一个指针。它将会指向堆上存储对象数据的内存地址。
正如我们即将会看到的,Objective-C方法是用方框号调用的。这里,我们在init方法中嵌套了alloc方法。这是非常重要的,因为很多类是通过类簇来实现的。这里的API描述了一个类,但是实际的实现却使用了类的两个或者更多的变体。根据不同的情况,会创建不同的版本,通常用来提高性能。然而,所有这些复杂性对开发者都是隐藏的。
由于init(和该族中的方法)将会返回一个新的对象,你需要保存init的返回值而不是alloc的返回值,这是极其重要的。嵌套init和alloc方法确保你存储了正确的对象。
事实上NSString是一个类簇。我们可以通过分解步骤来查看,如下所示:
// 创建一个空的字符串
NSString* allocString = [NSString alloc];
NSLog(@"allocString: pointer = %p, class = %@",
allocString, allocString.class);
NSString* initString = [allocString init];
NSLog(@"initString: pointer = %p, class = %@",
initString, initString.class);NSLog()和printf()的功能非常相似。第一个参数是一个常量NSString。正如我们之前所看到的,双引号创建了C风格的字符串。通过在第一个引号之前加上@,就可以让编译器生成一个NSString。
然后,NSLog会扫描这个字符串,查找占位符。大部分时候,这些占位符和printf()使用的占位符是一样的。然而,还是有一些小的变化。例如,%``@用来显示对象。
基本上,这个代码在控制台输出了alloc和init调用前后都的指针值和类的名称。当你运行这个代码,它会产生下面的输出(注意实际的指针值毫无疑问会产生变化):
allocString: pointer = 0x4e032a0, class = NSPlaceholderString
initString: pointer = 0x1cb334, class = NSCFString正如你所看到的,指针和类在init被调用后都改变了。并且,NSString实际上是NSCFString子类的一个成员。
多样的初始化的方法
一个对象可能有多个初始化的方法。NSString就有好几个:init、initWithString:、initWithFormat:、initWithContentsOfFile: encoding:error:等。这些方法为设定字符串的初始值提供了多个可选的方式。完整的清单可以在NSString类的参考文档中找到。
此外,NSString还有一些便利的方法,通常以string开头的类方法:string、stringWithString:、stringWithFormat:、string WithContentOfFile:encoding:error``:等。它们将分配和初始化的步骤合并在一个方法中了。
虽然[NSString string]和[[NSString alloc]init]看上去很相似,但是在系统管理对象的内存方式上它们有着微妙但是却尤为重要的区别。过去,我们不得不小心正确地使用每一个方法。幸运的是,现在如果你使用了ARC(自动引用计数),这些差异就会消失,从而你就可以自由选用最适合你的应用程序和编程风格的方法。
如何定义类
我们分两步来定义一个类:接口和实现。接口通常定义在类的头文件(文件名以.h结束)中。这让我们在项目的其他任何部分可以轻易地导入类声明。接口应该定义有效使用该类所需的所有信息,这包含公有方法(可以在类外部被调用的方法),以及该类的父类和实例变量。
这看上去可能有些奇怪。毕竟,使用对象的主要目的是封装。实例变量不是应该隐藏在实现文件中吗?
好吧,是这样的。在理想的世界中它们应该是这样。然而,早先版本的编译器需要这些信息来对子类的实例变量进行内存布局。在Objective-C 2.0中,我们可以用属性来避免这个限制。如果你在开发iOS应用程序,或者是在为Mac OS X 10.5或更高版本开发64位应用程序,你可以为属性自动合成这些实例变量。我们在下一节中将会更加深入地讨论属性。现在只需要知道在接口中声明的实例变量并不是所有内容就可以了。
接口以@interface关键词开始,以@end结束。格式如下:
@interface ClassName : SuperClassName {
//此处声明实例变量
//在iOS系统中如果使用了属性,这些就是可选的
}
// 在此处声明公有方法和属性
@end应用程序中每一个类都需要一个唯一的类名称。如果你在创建一个将来会在其他的项目中使用的程序库,你应该在类名称前加上前缀,这样就确保了它不会和其他的程序库和框架库冲突。苹果公司的框架库也遵循这个建议,一般在类名称前加上NS或者UI。
每个类有且只能有一个父类。你通常会使用NSObject,除非你创建其他类的子类。实例变量定义在花括号中,而方法定义在花括号后面。
实际的代码存储在实现文件中(文件名以.m结束)。和接口类似,实现以@implementation关键词开始以@end结束。它将只包含方法和属性的定义。
@implementation ClassName
//在此处定义方法和属性
@end我们将会在下一节中加更深入地讨论方法和属性。
2.2.7 方法
一旦修饰的东西都剥离后,Objective-C方法也仅仅只是一个C函数。因此,我们学习的关于函数的所有知识都能同样地应用到方法中。然而,当我们调用C函数时,函数和它的参数在编译时就会被连接(静态绑定),这是一个非常重要的区别。相反,在Objective-C中我们并没有实际调用方法,我们会向对象发送一个消息,请求对象调用方法。然后对象就会根据方法名来选择实际使用的方法。选择器、函数和参数是在运行时进行连接的(动态绑定)。
这有很多的实际意义。首先,也是最重要的是,你可以发送任何方法给任何对象。毕竟,我们在运行时才会动态地添加方法的实现,或者我们可能干脆将方法转发给另外一个对象。
更常见的是,我们和对象标识符类型id一起使用这个特征,对象标识符类型id可以引用任何对象(包括类对象)。注意到我们在声明id变量时不会使用星号,因为id类型已经被定义为对象的指针了。
id myString = @"This is a string"; // 这是一个NNString
id myStringClass = [myString class]; // 这是一个类对象
id类型和动态绑定双剑合璧,为我们避免了静态绑定语言通常所需的大量复杂而冗长的结构。但是这并不意味着我们就可以万事大吉了,作为开发者,我们通常要比编译器更了解我们的应用程序。
例如,如果我们只将NSString对象放入一个数组中,我们就知道数组中所有的对象都会响应长度消息。在C++或者Java中,我们需要说服编译器让我们调用这个方法(一般是通过转换这个对象的类型)。Objective-C(大多数情况下)编译器会相信我们知道自己在做什么。
然而,并不是只有西部牛仔才会做事鲁莽,我们普通人也会。Xcode的编译器和静态分析器在分析代码和查找常规错误(比如拼错了方法的名称)方面做得非常好,即使我们在写高度动态的代码。
发送消息给NIL
在Objective-C中,向nil发送消息是完全合法的。这对有着Java背景的人来说通常是一种震撼。在Java中,如果你调用了null的一个方法(null和nil是完全相同的,都是一个值为0的指针,从根本上说就是一个指向空值的指针),你的程序就会崩溃。在Objective-C中,这个程序只是会返回0或者nil(取决于返回类型)。
Objective-C的初学者通常认为这么做会隐藏错误。Java为了防止程序继续以不好的状态运行并可能产生错误的输出,或者在以后的每个时刻莫名其妙地崩溃了,调用null方法时它会立即崩溃。这是有一定道理的。然而,一旦你接受了可以向nil发送消息的事实,你就可以用它来创建简洁、优雅的算法。
我们来看一下最常见的设计模式之一。想象一个需要下载100个订阅的RSS阅读器。首先你可以调用一个方法来下载XML文档,接着分析XML。由于潜在的网络问题,第一个方法有可能是非常不可靠的。在Java中,我们需要检查并且确保我们收到了一个有效的结果。
XML xml = RSS.getXMLforURL(myURL);
// 确保我们有一个有效的XML对象
if (xml != null) {
xml. parse();
...
}
在Objective-C中,这些检查是不需要的。如果XML是零值,方法调用了只是不产生任何作用而已。
XML* xml = [RSS getXMLforURL:myURL];
[xml parse];
...同样,让我们来面对它,null指针在Java应用中是一个非常常见的故障来源。Java的null指针违反了原本严格的静态类型。如果你将它赋值给一个对象变量,那么你应该可以将它和其他对象一样看待,包括调用实例方法和接收合理的结果。
调用方法
Objective-C方法使用方括号来调用。在方括号中,包含接收者和消息。接收者可以是其值为对象的任何变量(包括self)、super关键字,或者类名(针对类方法)。消息是方法名和任何参数。
[receiver message]
在C语言中,方法的参数放在函数名称后面的圆括号里,而Objective-C有点不一样。如果方法没有参数,方法名就是一个单词(通常使用驼峰式命名法,第一词的首字母小写,以后每个词的首字母大写)。
[myObject myFunctionWithNoArguments];如果方法接受一个参数,名称就以一个冒号(:)结束并且变量紧跟其后。
[myObject myFunctionWithOneArgument:myArgument];
多个参数将会分布在方法的整个名称中。通常,方法名称会暗示每个位置接受的参数类型。
[myObject myFunctionWithFirstArgument:first
secondArgument:second
thirdArgument:third];当引用方法时,我们一般会把它名字的所有部分集中在一起,不带空格或者参数。例如,上述的方法命名为myFuncitonWithFirstArgument: secondArgument:thirdArgument:。
虽然初看上去这种风格显得笨拙,但是在编程的时候会很有帮助。几乎不可能因为不小心将参数写错顺序(在C类型的语言中我经常会干这种事情)。将方法名称和参数交叉写在一起也鼓励使用更长的更具表达力的方法名,并且为了我的稿费,这样总是一件好事。
方法通常声明在类的@interface区块里,然后定义在@implementation区块里。就像C语言中的函数一样,声明就是方法签名之后再加上一个分号。定义是方法签名之后再加上一对花括号,花括号中包含代码块。
类方法
类方法在类上面调用(使用类名称),而不是在某个特定的对象上。我们已经在实际的例子中接触过了类方法,alloc是一个类方法的例子——我们调用的是[NSString alloc],而不是[myStringObject alloc]。
大部分的类方法是简化创建新对象的便利方法。其他的类方法会封装与类相关的一些实用函数。例如,NSString定义了一个名为availableStringEncodings的类方法。你可以调用这个方法来获得NSString类支持的所有字符编码方式,一个以nil结尾的字符串列表。
方法签名以+或者-字符开始。-用于实例方法,而+用于类方法。接着把返回类型放在圆括号中,然后是方法名称。参数定义在名称的适当位置。紧随分号之后是放置在圆括号中的参数类型,再是参数名称。
- (void)simple; //没有参数,没有返回值
- (int)count; // 没有参数,返回一个整数
- (NSString*) nameForID:(int)id; // 有一个整数类型的参数
// 返回一个字符串对象
// 有多个参数的类方法
+ (NSString*) fullNameGivenFirstName:(NSString*)first
middleName:(NSString*)middle
lastName:(NSString*)last;
``
Objective-C方法总是有两个隐藏的参数:self和_``cmd。s``elf参数引用方法的接收者并且可以用来访问属性或者调用其他的实例方法。_``cmd参数是方法的选择器。
选择器是SEL类型的唯一标识符,它用来在运行时查找方法。你可以使用@selector()从方法名称创建一个SEL。你还可以使用NSString`` ``FromSelector()获得一个SEL的字符串描述。
当你开始不断添加方法到对象时,C语言函数和Objective-C方法的关联就会真正清晰起来,如下所示:// 在@implementation区块之前定义
void myFunction(id self, SEL _cmd) {
NSLog(@"Executing my method %@ on %@",
NSStringFromSelector(_cmd),
self);}
// 在@implementation区块内定义
-
(void)addMethod {
SEL selector = @selector(myMethod); class_addMethod(self, selector, (IMP)myFunction, "v@:");}
运行类方法addMethod将会在运行时将myMethod添加到当前的 类中。然后就可以调用[``myObject myMethod``],而它将会调用函数myFunction`` ``(myObject,`` ``@selector`` ``(myMethod))。
初始化
我们已经讨论了对象实例化的两个步骤。现在让我们来看看初始化方法本身,这些方法其实和我们将会写的其他任何方法一样,不过,这里有一些约定我们需要遵循,以便保证事情正常的进行。
首先是名称。所有的初始化方法习惯以init开始。帮你自己(和任何将来有可能维护你的代码的人)一个巨大的帮吧!并且总是遵循这个命名规范。
其次,有两个方法需要特别>{注意:}类的指定初始化方法以及父类的指定初始化方法。
每个类都应该有一个指定初始化方法,负责执行对象所有的设置和初始化的方法。通常,这是一个有着最多参数数量的初始化方法。其他的初始化方法都应该调用指定初始化方法,让它完成所有的“重活”和“脏活”。
类似地,指定初始方法需要调用它的父类的指定初始化方法。通过将类层级链接在一起,指定初始化方法链接指定初始化方法,我们确保了整个类层级中的对象得以正确地初始化。
最后,你的类应该总是重载它的父类的指定初始化方法。这会将任何调用发送给父类的任何指定初始化方法(或者类层级中的任何类的任何初始化方法)的调用重新发送回子类的指定初始化方法,然后在类层级中往上发送。
让我们来看一个具体的例子。想象我们正在创建一个Employee类。这将会是NSObject的一个子类。NSObject只有一个初始化方法init。这是(默认)它的指定初始化方法。而我们创建的Employee类将会有三个实例变量:_firstName、_lastName和_id。它的指定初始化方法将会设定这三个值。
先让我们从Code Snippet库中拖进一个空白的init方法。在实用工具区底部,点击Code Snippet标签(它看上去像一对花括号),然后向下滚动直到找到Objective-C init方法(见图2.2)。你可以点击将它拖曳到你的实现文件中。
 修改自动生成的模版代码,如下所示。你还需要将方法签名复制到Employee类的接口代码块中。
修改自动生成的模版代码,如下所示。你还需要将方法签名复制到Employee类的接口代码块中。//指定初始化方法
- (id)initWithFirstName:(NSString *)firstName
lastName:(NSString *)lastName
id:(int)id {
self = [super init];
if (self) {_firstName = [firstName retain];
_lastName = [lastName retain];
_id = id;
}
return self;}
通常来说,当我们在对象上调用方法,对象首先会搜索在对象所属的类中定义的匹配的方法。如果它不能找到匹配的方法,就会到父类中搜索,并且继续查找整个类层级。关键词super允许我们显式地查找在self父类中定义的方法。通常用于你重载了一个现有的方法,而你想要调用原始的实现版本。关键词super使得你可以访问该版本的方法。
因此,这个方法以将[``super init``]的值赋给self变量开始。调用这个方法将会忽略init当前的实现并且开始在类层级中搜索更老的实现版本。
将返回值赋给self也许看上去很古怪,但是这只是我们之前看过的问题的变化。记得当我们讨论初始化对象时,我们总是嵌套init和alloc调用,因为init有可能和alloc返回一个不同的对象。这个代码所要面对的也是相同的基本问题。s``elf包含了alloc返回的值。然而,[``super init``]可能会返回一个不同的值。我们需要确保我们的代码正确初始化了,并且返回[``super init``]返回的值。
Objective-C程序员新手通常会对给self赋一个新的值感到很纠结,但是请记住,它是我们方法的隐藏参数,这意味着它只是一个局部变量。它没有什么神奇的,我们可以给它赋新值,就像我们给其他变量赋值一样。
接着,if语句检查了[``super nil``]有没有返回nil。只要我们有一个有效的对象,就开始执行初始化——将方法的参数赋值给对象的实例变量。最后,我们的初始化方法返回self。
目前为止,一切都很好。我们通过指定初始化方法来调用父类的指定初始化方法。现在我们只需要重载父类的指定初始化方法就可以了。// 重载父类的指定初始化方法
- (id) init {
// 这里必须调用我们的指定初始化方法
return [self initWithFirstName:@"John" lastName:@"Doe" id:-1];
}
这个方法必须调用对象的指定初始化方法。这里,我们仅仅是输入了合理的默认值。如果我们创建了任何其他的初始化器,它们也一定会遵循这个模式并且调用initWithfirstName:lastName:id``:来真正设置我们的实例变量。
注意:
我冒着唧唧歪歪之嫌,再次强调,你应该只在默认初始化器中设置实例变量。所有其他的初始化器应该调用默认初始化器。它们不应该再设置任何变量或者自己做任何其他的初始化。
便利方法
很多类有一些便利方法,这些方法使得可以通过一次方法的调用来完成对象的实例化。大多数情况下,这些方法与初始化方法对应。
例如,Emloyee类可能有一个方法employeeWithFirstName:`` ``lastName:id。这个方法是指定初始化方法的一个简单包装。其他的便利方法可能在调用指定初始化方法之前或者之后会引入相当复杂的计算,但是最基本的思路是一样的。-
(id) employeeWithFirstName:(NSString *)firstName
lastName:(NSString *)lastName id:(int)id {return [[self alloc] initWithFirstName:firstName
lastName:lastName id:id];}
在示例代码中,有一个非常重要的约定:我们在这个方法中使用[``self alloc``]而不是[``Employee alloc``]。请记住,self指代消息的接收者。由于这是一个类方法,self应该被设定为Employee类。然而,假如我们创建了一个名为PartTimeEmployee的子类。我们可以在PartTimeEmployee中调用employeeWithFirstName:lastName:`` ``id并且一切还会按照预期的那样运行。通过调用[``self alloc``],我们的实现正确地分配和初始化了一个PartTimeEmployee对象。然而,如果我们对类进行硬编码,那么它只会返回Employee对象。// 返回一个Employee对象
id firstPerson = [Employee employeeWithFirstName:@"Mary"
lastName:@"Smith"
id:10];// 返回一个PartTimeEmployee对象
id secondPerson = [PartTimeEmployee employeeWithFirstName:@"John"
lastName:@"Jones"
id:11];属性
默认情况下,一个对象的实例变量在对象实现程序块的外部是不能访问的。不过,你可以将这些变量声明为@public,但是我们不建议这么做。如果你想要让外部的代码访问这些值,你应该编写访问器方法。
以往,访问器方法主要是些枯燥的样板代码,它们只是将值传进或传出你的类。由于手动的内存管理,编写和维护它们通常枯燥乏味。幸运的是,在Objective-C 2.0里,苹果公司提供了一个自动创建访问器的工具:属性。
我们在类的接口中声明属性,如下所示:@property (attributes) variableType propertyName;
属性决定了我们的访问器如何实现。表2.2描述了常见的属性。如果要看完整的清单,请查看苹果公司的参考文档中的Objective-C Programming Language、Declared Properties。
 属性默认情况下是assign和readwrite。同样,不管是什么理由,并没有显式的atomic属性。任何没有指定nonatomic的属性都会使用同步、线程安全的getters和setters来创建。当然,这个同步会伴随引起轻微的性能损耗。
注意:
在iOS 5.0版本之前,属性经常会使用retain来处理手动的内存管理。然而,retain在ARC下编译时就不再有效了。请查看本章后面的“内存管理”一节,以获得更多的信息。
@property声明自动地定义了访问器方法,如下所示:
属性默认情况下是assign和readwrite。同样,不管是什么理由,并没有显式的atomic属性。任何没有指定nonatomic的属性都会使用同步、线程安全的getters和setters来创建。当然,这个同步会伴随引起轻微的性能损耗。
注意:
在iOS 5.0版本之前,属性经常会使用retain来处理手动的内存管理。然而,retain在ARC下编译时就不再有效了。请查看本章后面的“内存管理”一节,以获得更多的信息。
@property声明自动地定义了访问器方法,如下所示:// 这个属性
@property (nonatomic, copy) NSString* firstName;
// 声明了这些方法
- (NSString*)firstName;
- (void)setFirstName:(NSString*)firstName;
获取器使用了属性的名称并且返回了实例变量的当前值。设置器将set添加到属性名称之前并且会将参数(或者参数的副本)赋给实例变量。
现在,我们需要告诉编译器实现这些方法。通常我们会在类的@implementation程序块里添加一个@synthesize指令。
@synthesize firstName;
这就产生了被请求的方法(如果它们还没有被实现,如果你愿意你仍然还可以选择创建手动版本的)。默认情况下,访问器方法将会获取和设定存储在类的firstName实例变量中的值。如果你已经在@interface程序块中声明了这个变量,读取器就会使用它,否则,@synthesize将会为你新建一个实例变量。
或者,我们还可以为实例变量指定一个不同的名称。下面的代码将会使用_``firstName实例变量而不是firstName。@synthesize firstName = _firstName;
我总是像上面这样重新命名我的实例变量。按照惯例,下划线将实例变量标识为私有的,不可以直接被访问的实例变量。这正是我们想要的。一般来说,你应该通过属性来访问你的实例变量,即使是在类的@implementation程序块中。如果你使用了默认的实例变量名称,那就太容易忘记,以致于错误地直接访问实例变量了。@synthesize与@dynamic
@synthesize指令严格说来并不是必需的。如果你自己实现了所有的访问器方法那么就不需要这个指令了。另外一种选择,你可以使用@dynamic指令。这就相当于告诉了编译器,“嘿,相信我吧!这些方法都会准备好的。”
当你计划在运行时提供方法(使用类似动态加载或者动态方法解析技术)或者更有可能的是,当你要重新声明父类的属性时,你可以使用@dynamic指令。在这两种情况下,@dynamic都会阻止访问器方法无定义的警告。
你可以通过直接调用生成的方法或者使用点表示法来使用属性,如下所示:// 这些是完全相等的
NSString* name = [myClass firstName];
NSString* name = myClass.firstName;
// 这些也是完全相等的
[myClass setFirstName:@"Bob"];
myClass.firstName = @"Bob";
你还可以通过使用self变量在类的实例方法定义内部访问属性。// 这些是完全相等的
NSString* name = [self firstName];
NSString* name = self.firstName;
// 这些也是完全相等的
[self setFirstName:@"Bob"];
self.firstName = @"Bob";
使用属性有助于产生整洁、一致的代码。更重要的是,它确保了诸如键-值观察之类的技术运转正确。然而,有一个地方应该直接读取实例变量:在类的指定初始化方法中。
注意:
很多守旧的Objective-C程序员看上去很厌恶点表示法,就像憎恨电话销售员那样。他们认为点表示法是没有必要的,让人困惑的。就我个人来说,我喜欢这样的方式:点表示法对应我们在C风格的结构体中获得和设置值的方式。这使得访问器方法和其他方法清晰地区分开来。然而,因人而异,你应该选择自己使用起来最舒服的表示法。
一般来说,初始化方法应该避免做任何有可能产生错误的操作、调用外部方法或者是耗尽CPU时间等。一般的共识,你的属性应该是相对简单的任务,没有任何意外的副作用,因此使用属性应该不会坑了你。然而,总是有这样的时候,有些人最终会将自定义的设置器添加到属性中,不经意间使你的初始化方法变得不稳定。因此,直接赋值不是一个坏主意。
**2.2.8 协议**
一些面向对象的编程语言(最有名的是C++和Python)允许多重继承,类可以直接从多个父类中继承行为。这样会产生问题,尤其是当两个父类都定义了相同的方法时。这听起来像是小概率事件,但是它总是会意外地发生。如果一组类继承自一个通用的父类(并且所有的类继承自一个根父类),那么两个父类都会含有通用父类的方法的副本。如果在两个父类的类层级中任何一个地方重载了这些方法中的一个,你的子类就会继承那个方法的多个实现。
其他的一些语言(例如Java和Objective-C),它们不允许多重继承,很大程度是由于多重继承所造成的复杂性。然而,确实有些时候你仍然想要从一些不相关的类中获取一些通用的行为。一些静态的、强类型的语言中更是这样,例如Java。
假如说你想要有一个对象数组,并且你想要迭代访问每个对象,调用它的makeNoise()方法。一种方法就是创建一个NoisyObject父类,然后让数组中的所有对象都继承这个类。理论上听起来不错,然而这并不是总能实现。有时你的对象必须从另一个已有的类层级继承得来。在C++中,这没有问题。类可以继承两个类。在Java中,我们可以使用Noisy接口来模拟多重继承。任何实现这个接口的类都必须也要实现makeNoise()方法。
在Objective-C中就不用过分担心这点。Objective-C语言没有Java这样严格的静态类型(以及伴随它而来的问题)。毕竟,我们可以向任何对象发送任何消息。因此,这确实是一个传达我们意图的方式。你只要确保数组里所有的对象实现了makeNoise方法,那么你就可以动手了。然而,我们经常想要明确地捕获这些需求。在这种情况下,协议和Java的接口扮演着相似的角色,不过协议还有别的用处。
协议声明了一系列方法。默认情况下,这些方法是必需的。采用协议的任何类必须实现所有必需的方法。然而,我们也可以声明方法为可选的。采用协议的类可以实现可选的方法,但它们并不是必需。
乍看起来,可选的方法看上去有点古怪。毕竟,任何对象可以实现任何方法,并不需要协议的允许。然而,Objective-C的协议真正传达了开发者的意图,谨记这一点是非常重要的。开发者在为委托开发协议时,通常使用可选的方法。这里,他们会为方法撰写文档,说明委托可以重载这些方法,从而可以监控或者改变委托类的行为。我们将会在本章后面讨论委托的时候深入研讨这个话题。
采用协议
为了采用一个协议,只要在类的@interface程序块中的父类声明后的三角括号里,添加一个逗号隔开的协议列表就可以了。@interface ClassName : SuperClassName
{
...@end
你必须还要实现任何必需的还没有被实现的方法。注意你不需要在@interface程序块中声明这些方法。协议已经帮你完成了这些工作。
声明协议
协议声明和类声明看起来很相似,只不过协议声明没有实例变量的区块。其余的就像类的@interface区块一样,协议通常都声明在头文件中——可以在其本身的头文件中,也可以在一个和它密切相关的头文件(例如,委托协议通常都声明在委托类的头文件里)。@protocol ProtocolName
// 在此处声明必需的方法
// 协议方法默认是必需的
@optional
// 在此处声明可选的方法
// 所有在@optional关键词后声明的方法都是可选的
//
@required
// 在此处追加声明必需的方法
//在@required关键词后声明的所有方法又都是必需的@end
正如你所见,你可以使用@optional和@required关键词以你看着最舒服的方式来划分你的方法。在@optional关键词(直到下一个@required关键词)后声明的所有方法都是可选的。在@required关键词(直到下一个@optional关键词)后声明的所有方法都是必需的。
一个协议同样也可以包含其他协议。你只需要将它们列在协议名称后的三角括号里就可以了。任何采用了一个协议的类同样也采用了该协议所包含的所有协议。@protocol ProtocolName
...@end
**2.2.9 类别和扩展**
类别让你能够向现有的类中添加新的方法,甚至是库或框架中无法访问源代码的类。类别的用途有许多。首先,我们不需要再依靠创建无数的子类来扩展一个类的行为。当你想要向现有的类添加一个或两个帮助函数时,类别通常非常有用,例如,将push:和pop方法添加到NSMutableArray中。
你还可以添加方法到类层级中较高层次的类中。这些方法就会和其他方法一样,沿着类层级被继承下来。你甚至可以修改NSObject或其他根类,将行为添加到应用程序中的每个对象。然而,一般来说,你应该尽量避免对编程语言做出这样大范围的改动。这有可能会产生意想不到的结果。至少,它们肯定会在一定程度上令使用者对代码感到混乱。
最后,你可以利用类别来将大型的、复杂的类分割成更容易管理的代码块,每个类别都包含一组相关的方法。Cocoa Touch框架通常都这么做,在它们自己的类别中声明专用的帮助方法。
创建类别
我们创建类别就像创建新的类一样。@interface程序块看上去基本上和它对应的类完全相等。它们只有两点不同。首先,我们在圆括号中写类别名称,而不是声明父类,并且后面可以有选择性地跟着一系列类别所采用的协议。其次,创建类别时没有专门用来声明实例变量的程序块。在类别中不能添加实例变量。如果需要添加额外的实例变量,你只能创建一个子类。@interface ClassName (CategoryName)
// 在此处声明方法
@end
@implementation程序块和类的版本更加相似。唯一不同的地方就是在圆括号中加入了类别名称。
@implementation ClassName (CategoryName)
// 在此处实现扩展方法
}
这里是一个为NSMutableArray类创建的简单的Stack类别。
// 在Stack.h文件中
import
@interface NSMutableArray (Stack)
- (void)push:(id)object;
- (id)pop;
@end
//在Stack.m文件中
import "Stack.h"
@implementation NSMutableArray (Stack)
- (void)push:(id)object {
[self addObject:object];
} - (id)pop {
// 如果stack是空的就返回nil
if (self.count == 0) return nil;
// 从数组中删掉最后一个对象并返回这个对象
id object = [self lastObject];[self removeLastObject];
return object;
}
@end
扩展和类别非常相似,只有两个重要的区别。首先,它没有名称。其次,在扩展中定义的方法必须在类的主@implemetation程序块中实现。扩展经常被用来声明私有方法。它们一般放置在类的主实现文件@implementation程序块的前面。@interface ClassName ()
// 在此处声明私有方法
@end
由于扩展在@synthesize被调用之前就声明了,你可以在扩展中声明新的属性。正如其他属性一样,我们不需要在头文件中声明实例变量,@sythesize调用会为我们创建。这让我们将可以私有实例变量隐藏起来,不让暴露在公共接口中。
你甚至可以在公有界面中将一个属性声明为只读的,并且在扩展中重新声明成读写的。这将会产生公有的获取器方法和私有的设置器方法。
注意: