大语言模型系列-Transformer
文章目录
- 前言
- 一、Attention
- 二、Transformer结构
- 三、Transformer计算过程
-
- 1. 编码器(Encoder)
-
- 1)Self-Attention层
- 2)Multi-Head-Attention层
- 3)Add & Norm层
- 2. 解码器(Decoder)
-
- 1)Masked Multi-head Self Attention层
- 2)Encoder-Decoder Attention层
- 3. 输出
- 4. 训练和预测
- 5. 损失函数
- 总结
前言
前文大语言模型系列-ELMo提到了,RNN的缺陷限制了NLP领域的发展,2017年Transofrmer的横空出世,NLP领域迎来了基于Transformer的预训练模型(LLM)的大爆发。
Transformer由谷歌的2017年论文《Attention is All You Need》提出。
Transformer通过引入注意力机制解决了RNN存在的以下问题:
- RNN编码器-解码器结构中,仅将最后一个隐藏状态传递给解码器,会丢失信息
- RNN难以并行计算
提示:以下是本篇文章正文内容,下面内容可供参考
一、Attention
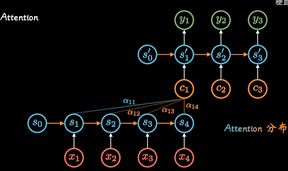
- 循环神经网络(RNN)模型建立了网络隐藏层之间的时序关联 , 每一时刻的隐藏层 s t s_t st,不仅取决于输入 x t x_t xt,还取决于上一时刻隐藏层信息 s t − 1 s_{t-1} st−1

- 两个RNN组合可以形成Encoder-Decoder模型

- 但是这种不管输入多长,都统一压缩成长度编码C的做法,会导致信息的丢失,因此出现了Attention机制:即通过每个时间输入不同的C解决这个问题,其中 a t a_t at表明了在 t t t时刻所有输入的权重,以 c t c_t ct的视角看过去, a t a_t at权重就是不同输入的注意力,因此也被称为Attention分布
- 后来随着GPU等大规模并行运算的发展,人们发现RNN的顺序结构很不方便,难以并行运算,效率太低

- 便去掉了Encoder(RNN)隐藏层,衍生出自注意力(Self-Attention)

- 但去除Encoder隐藏层的同时也失去了上下文的关联,可以通过位置编码的方法增加数据的先后关系(位置编码在词嵌入完成后再进行计算)

ps:RNN有天然的时序关系,在输入“我爱你”这句话时,会先输入“我”…,Self-Attention可以将一句话同时输入同时处理,实现并行计算,增加了速度,但是这种方法损失了单词间的先后关系
二、Transformer结构
Transformer是典型的编码器-解码器架构
编码组件部分由一堆编码器(Encoder)构成(论文中是将6个编码器叠在一起)。解码组件部分也是由相同数量(与编码器对应)的解码器(Decoder)组成的。
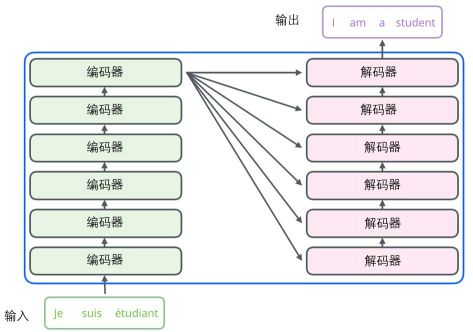
所有的Encoder在结构上都是相同的,但它们没有共享参数。
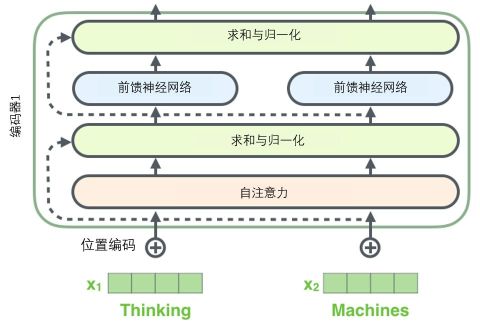
- 每个Encoder都可以分解成两个子层:自注意力层、前馈神经网络层
- 每个Decoder都可以分解成三个子层:自注意力层、编码解码注意力层、前馈神经网络层,其中编码解码注意力层用于接收编码器输出

Transformer完整结构图如下图,图中的Self-Attention变成了多头注意力机制(Multi-Head Attention),下文会详细解释。

三、Transformer计算过程
1. 编码器(Encoder)
像大部分NLP应用一样,首先将每个输入单词通过词嵌入算法转换为词向量。每个单词都被嵌入为512维的向量,用这些简单的方框来表示这些向量。

词嵌入过程只发生在最底层的编码器中。所有的编码器都有一个相同的特点,即它们接收一个向量列表,列表中的每个向量大小为512维。在底层(最开始)编码器中它就是词向量,但是在其他编码器中,它就是下一层编码器的输出(也是一个向量列表)。向量列表大小是我们可以设置的超参数——一般是我们训练集中最长句子的长度。
将输入序列进行词嵌入之后,每个单词都会流经Encoder中的两个子层。

1)Self-Attention层
- 第一步是生成每个单词的查询向量q、键向量k和值向量v
将输入的词向量矩阵与三个权重矩阵( W Q , W K , W V W^Q,W^K,W^V WQ,WK,WV)相乘,获得查询向量矩阵(Q)、键向量矩阵(K)和值向量矩阵(V),其中每个单独词向量的查询向量、键向量和值向量为 q i , k i , v i q_i,k_i,v_i qi,ki,vi

- 第二步是通过查询向量q、键向量k计算每个单词对编码当下单词的贡献分数,计算方式为:该单词查询向量 q i q_i qi点乘其他所有单词的键向量 k j k_j kj,结果除以8再softmax
ps:假设我们在为这个例子中的第一个词“Thinking”计算自注意力向量,我们需要拿输入句子中的每个单词对“Thinking”打分。这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。

- 第三步是通过贡献分数和值向量v计算自注意力输出,计算方式为:将每个值向量 v t v_t vt乘以softmax分数,然后求和
ps:

这样Self-Attention的计算就完成了(注意:这里为了演示,以单个词向量的计算为例,实际中,这些计算是以矩阵Q、K、V形式完成计算的),具体公式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac {QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V
2)Multi-Head-Attention层
Transformer中使用的是注意力层的计算使用的是多头注意力机制,Multi-Head-Attention是Self-Attention的扩展,与上述相同的Self-Attention计算基本相同,区别在于使用八个不同的Q、K、V权重矩阵,进行八次Self-Attention得到八个不同的Z矩阵,然后把这些矩阵拼接在一起,用一个附加的权重矩阵 W o W^o Wo与它们相乘得到结果。

Multi-Head-Attention在两方面提高了注意力层的性能:
- 扩展了模型专注于不同位置的能力:多头注意力可以协同工作,以更好地处理长距离的依赖关系。每个头可以关注不同距离的上下文,有助于模型更好地捕捉全局信息。
- 更好的捕捉多重关系:多头注意力允许模型在同一时间关注输入序列的不同部分,每个注意头都可以学习关注序列中不同的特征。这有助于模型更好地捕捉输入序列中的多重关系和模式。
3)Add & Norm层
接下来,对Multi-Head-Attention的输出进行求和与归一化(Add & Norm,这里的Norm具体指Layer-Normalization),然后输入到前馈神经网络中, 注意Encoder的每个子层周围都有一个残差连接,并跟随一个求和归一化(如下图所示)。
将Encoder向量都进行可视化,结果如下所示:

这样我们就基本清楚了Encoder的具体内容与计算情况,相比于Encoder,Decoder多了一个Encoder-Decoder Attention层 。假设一个 Transformer 是由 2 层编码器和两层解码器组成的,如下图所示。
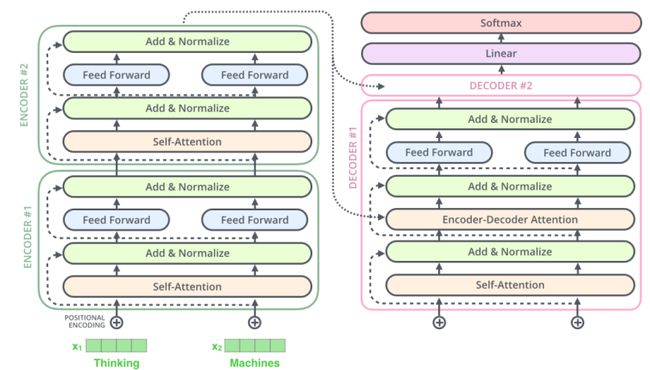
注意编码器最终会输出一组Attention向量 K 和 V到解码器,计算方式是初始化一个新的 W K W^K WK和 W V W^V WV权重矩阵和最后一个Encoder层输出 Z n Z_n Zn相乘。
2. 解码器(Decoder)
Decoder结构相比于Encoder结构有两大区别:
- 多头注意力层和Add & Norm层中间多了一个Encoder-Decoder Attention层
- 多头注意力层变为Masked Multi-head Self Attention
1)Masked Multi-head Self Attention层
掩膜多头注意力层和多头注意力层类似,但其只允许关注输出序列中早于当前位置之前的单词。具体做法是Masked:在 Self Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置。

2)Encoder-Decoder Attention层
编码器输出的Attention向量K 和 V将会输入到每个解码器的Encoder-Decoder Attention层,这有助于解码器把注意力集中到输入序列的合适位置。
Encoder-Decoder Attention层的原理和多头注意力层类似,不同之处是:Encoder-Decoder Attention层是使用前一层的输出来构造 Q 矩阵,而 K、V矩阵来自于编码器的输出。
3. 输出
解码器的输出,会经过最后的全连接层(Linear)和 Softmax 层得到最终的输出结果,这里以英语翻译为例:
全连接层会把解码器输出的向量,映射到一个更长的向量,这个向量称为 logits 向量。假设我们的模型词汇表有 10000 个英语单词,则 logits 向量有 10000 个数字,每个数表示一个单词的分数。
然后,Softmax 层会把这些分数转换为概率(把所有的分数转换为正数,并且加起来等于 1),最高概率的那个数字对应的词将作为这个时间步的输出。
4. 训练和预测
以英语翻译为例
训练过程如下:
- 第一个时间步,输入起始符,对应的输出为I
- 第二个时间步,输入起始符+我,对应的输出为Love
- 第三个时间步,输入起始符+我+爱,对应的输出为China
- 第三个时间步,输入起始符+我+爱+中国,对应的输出为结尾符end of sentence
ps:注意训练阶段输入输出都是已知的,所以可以并行执行,预测过程则只能按时间步进行
预测过程如下:
- 第一个时间步,输入起始符+Encoder Enbeddings,对应的输出为I
- 第二个时间步,输入Encoder Enbeddings+I,对应的输出为am
- 第三个时间步,输入Encoder Enbeddings+am,对应的输出为a
- 第四个时间步,输入Encoder Enbeddings+a,对应的输出为student
- 第五个时间步,输入Encoder Enbeddings+student,对应的输出为结尾符 < e o s >

5. 损失函数
Transformer的损失函数其实就是对比模型输出的概率分布与实际的概率分布,序列生成任务中常使用负对数似然损失(Negative Log-Likelihood Loss, NLL Loss),又称为交叉熵(cross-entropy)损失
- 每个时间步的输出向量即为一个概率分布,长度是 vocab_size
- 第一个概率分布中,最高概率对应的单词是 “I”
- 第二个概率分布中,最高概率对应的单词是 “am”
- 以此类推,直到第 5 个概率分布中,最高概率对应的单词是 < e o s >

总结
Transformer最初诞生于NLP领域,但到目前为止,已经成为了各个领域(CV、语音信号处理、多模态等)最新最火的架构,尤其是Transformer的注意力机制,比CNN看得更宽更远(能够处理长距离依赖,而CNN往往只能看到局部信息),比LSTM训练更快。
当训练数据集不够大的时候,Transformer的表现通常比同等大小的CNN网络要差一些,但当拥有足够多的数据进行预训练的时候,Transformer的表现就会超过CNN,突破Transformer缺少归纳偏置的限制,可以在下游任务中获得较好的迁移效果。
ps:CNN具有两种归纳偏置,一种是局部性(locality/two-dimensional neighborhood structure),即图片上相邻的区域具有相似的特征;一种是平移不变形(translation equivariance), f(g(x))=g(f(x)) ,其中g代表卷积操作,f代表平移操作。当CNN具有以上两种归纳偏置,就有了很多先验信息,需要相对少的数据就可以学习一个比较好的模型。