交叉注意力融合时域、频域特征的FFT + CNN -BiLSTM-CrossAttention轴承故障识别模型
目录
往期精彩内容:
前言
1 快速傅里叶变换FFT原理介绍
第一步,导入部分数据
第二步,故障信号可视化
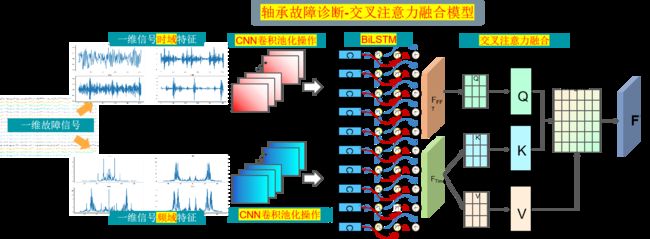
第三步,故障信号经过FFT可视化
2 轴承故障数据的预处理
2.1 导入数据
2.2 制作数据集和对应标签
3 交叉注意力机制
3.1 Cross attention概念
3.2 Cross-attention算法
4 基于FFT+CNN-BiLSTM-CrossAttention的轴承故障识别模型
4.1 网络定义模型
4.2 设置参数,训练模型
4.3 模型评估
代码、数据如下:

往期精彩内容:
Python-凯斯西储大学(CWRU)轴承数据解读与分类处理
Python轴承故障诊断 (一)短时傅里叶变换STFT
Python轴承故障诊断 (二)连续小波变换CWT_pyts 小波变换 故障-CSDN博客
Python轴承故障诊断 (三)经验模态分解EMD_轴承诊断 pytorch-CSDN博客
Pytorch-LSTM轴承故障一维信号分类(一)_cwru数据集pytorch训练-CSDN博客
Pytorch-CNN轴承故障一维信号分类(二)-CSDN博客
Pytorch-Transformer轴承故障一维信号分类(三)-CSDN博客
Python轴承故障诊断 (四)基于EMD-CNN的故障分类-CSDN博客
Python轴承故障诊断 (五)基于EMD-LSTM的故障分类-CSDN博客
Python轴承故障诊断 (六)基于EMD-Transformer的故障分类-CSDN博客
Python轴承故障诊断 (七)基于EMD-CNN-LSTM的故障分类-CSDN博客
Python轴承故障诊断 (八)基于EMD-CNN-GRU并行模型的故障分类-CSDN博客
基于FFT + CNN - BiGRU-Attention 时域、频域特征注意力融合的轴承故障识别模型-CSDN博客
基于FFT + CNN - Transformer 时域、频域特征融合的轴承故障识别模型-CSDN博客
大甩卖-(CWRU)轴承故障诊数据集和代码全家桶-CSDN博客
Python轴承故障诊断 (九)基于VMD+CNN-BiLSTM的故障分类-CSDN博客
Python轴承故障诊断 (十)基于VMD+CNN-Transfromer的故障分类-CSDN博客
Python轴承故障诊断 (11)基于VMD+CNN-BiGRU-Attenion的故障分类-CSDN博客
前言
创新点:利用交叉注意力机制融合模型!
本文基于凯斯西储大学(CWRU)轴承数据,进行快速傅里叶变换(FFT)的介绍与数据预处理,最后通过Python实现基于FFT的CNN-BiLSTM-CrossAttention模型对故障数据的分类。凯斯西储大学轴承数据的详细介绍可以参考下文:
Python-凯斯西储大学(CWRU)轴承数据解读与分类处理_cwru数据集时域图-CSDN博客
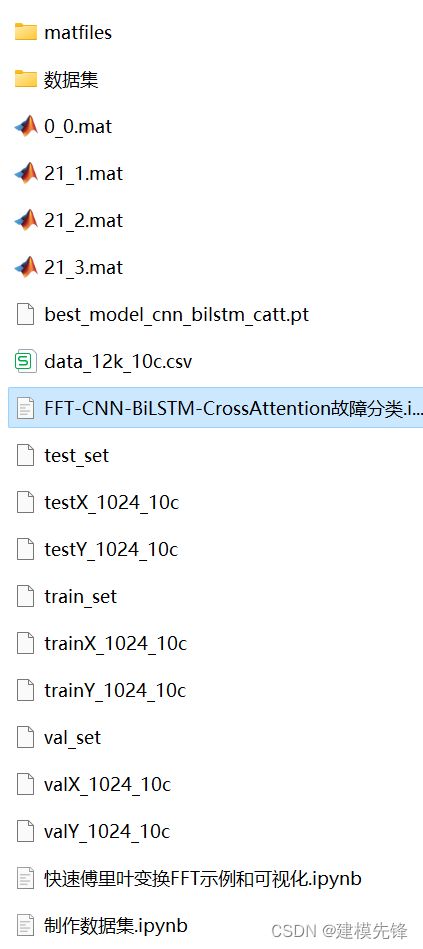
模型整体结构
模型整体结构如下所示,一维故障信号经过FFT变换的频域特征以及信号本身的时域特征分别经过CNN卷积池化操作,提取全局特征,然后再经过BiLSTM提取时序特征,使用交叉注意力机制融合时域和频域的特征,通过计算注意力权重,使得模型更关注重要的特征再进行特征增强融合,最后经过全连接层和softmax输出分类结果。
时域和频域特征提取:
-
对时域信号应用FFT,将信号转换到频域。
-
利用CNN对频域特征进行学习和提取。
-
CNN的卷积层可以捕捉频域特征的局部模式。
BiLSTM网络:
-
将时域信号输入BiLSTM网络。
-
BiLSTM(双向长短时记忆网络)可以有效地捕捉时域信号的长期依赖关系。
交叉注意力机制:
-
使用交叉注意力机制融合时域和频域的特征。
-
这可以通过计算注意力权重,使得模型更关注重要的特征
1 快速傅里叶变换FFT原理介绍
傅里叶变换是一种信号处理和频谱分析的工具,用于将一个信号从时间域转换到频率域。而快速傅里叶变换(FFT)是一种高效实现傅里叶变换的算法,特别适用于离散信号的处理。

第一步,导入部分数据
fromscipy.ioimportloadmat
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
# 读取MAT文件
data1 = loadmat('0_0.mat') # 正常信号
data2 = loadmat('21_1.mat') # 0.021英寸 内圈
data3 = loadmat('21_2.mat') # 0.021英寸 滚珠
data4 = loadmat('21_3.mat') # 0.021英寸 外圈
# 注意,读取出来的data是字典格式,可以通过函数type(data)查看。第二步,故障信号可视化

第三步,故障信号经过FFT可视化
2 轴承故障数据的预处理
2.1 导入数据
参考之前的文章,进行故障10分类的预处理,凯斯西储大学轴承数据10分类数据集:
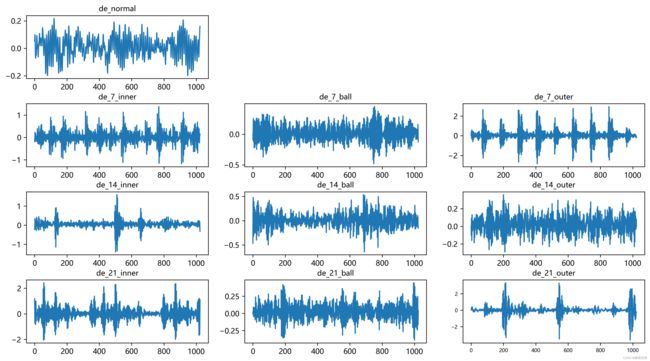
train_set、val_set、test_set 均为按照7:2:1划分训练集、验证集、测试集,最后保存数据

上图是数据的读取形式以及预处理思路
2.2 制作数据集和对应标签

3 交叉注意力机制
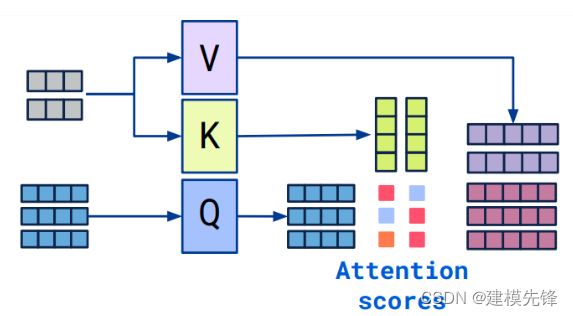
3.1 Cross attention概念
-
Transformer架构中混合两种不同嵌入序列的注意机制
-
两个序列必须具有相同的维度
-
两个序列可以是不同的模式形态(如:文本、声音、图像)
-
一个序列作为输入的Q,定义了输出的序列长度,另一个序列提供输入的K&V
3.2 Cross-attention算法
-
拥有两个序列S1、S2
-
计算S1的K、V
-
计算S2的Q
-
根据K和Q计算注意力矩阵
-
将V应用于注意力矩阵
-
输出的序列长度与S2一致
![]()
在融合过程中,我们将经过FFT变换的频域特征作为查询序列,时序特征作为键值对序列。通过计算查询序列与键值对序列之间的注意力权重,我们可以对不同特征之间的关联程度进行建模。
4 基于FFT+CNN-BiLSTM-CrossAttention的轴承故障识别模型
4.1 网络定义模型
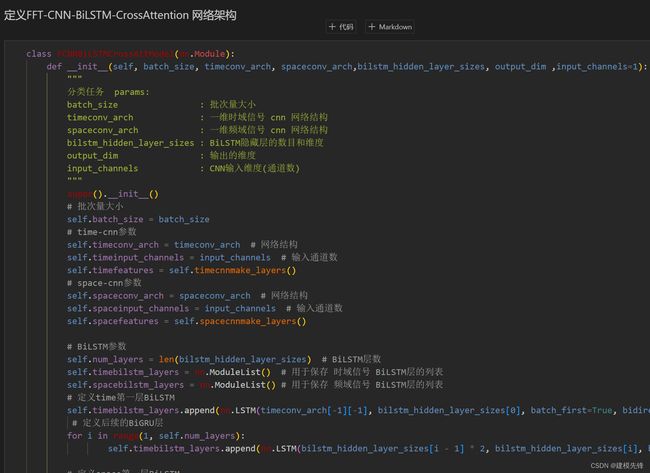
注意:输入故障信号数据形状为 [32, 1024], batch_size=32, ,1024代表序列长度。
4.2 设置参数,训练模型
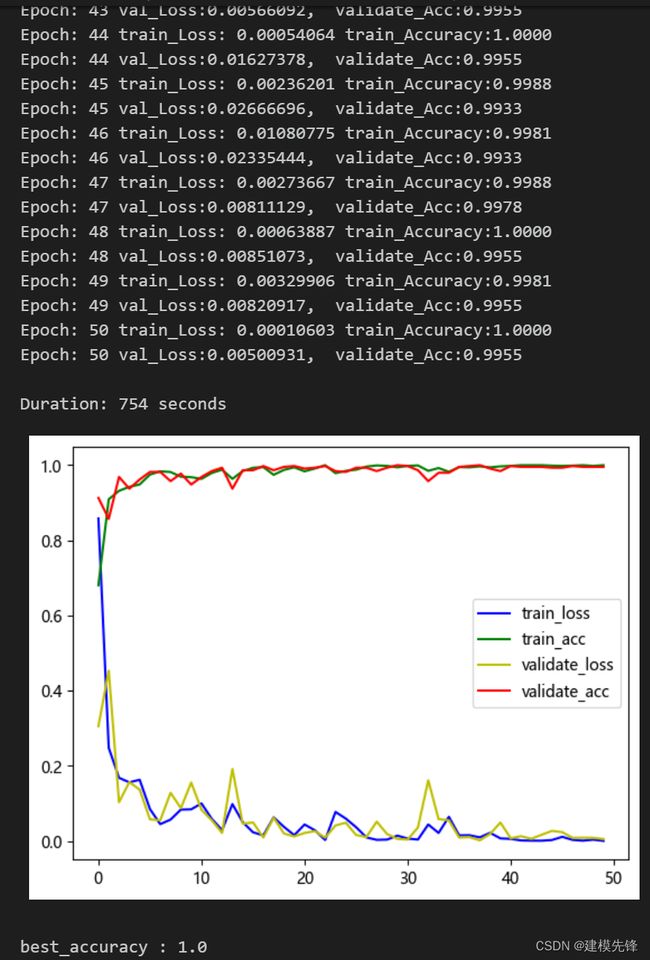
50个epoch,准确率100%,用FFT+CNN-BiLSTM-CrossAttention融合网络模型分类效果显著,模型能够充分提取轴承故障信号的空间和时序特征和频域特征,收敛速度快,性能优越,精度高,交叉注意力机制能够对不同特征之间的关联程度进行建模,从故障信号频域、时域特征中属于提取出对模型识别重要的特征,效果明显。
4.3 模型评估
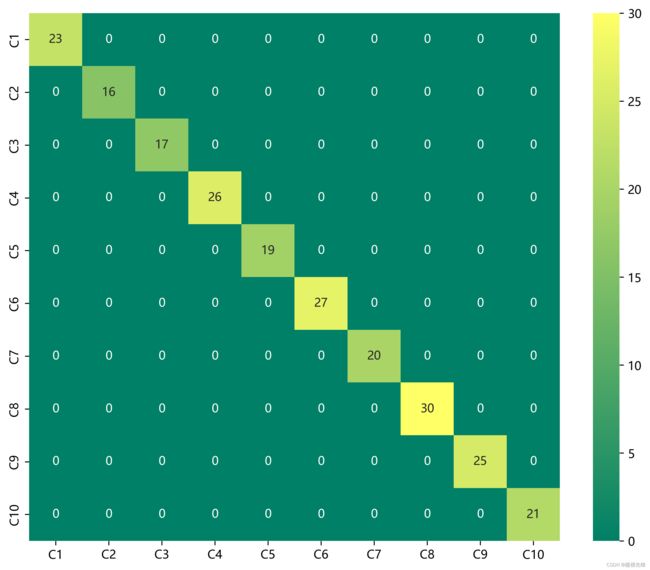
准确率、精确率、召回率、F1 Score
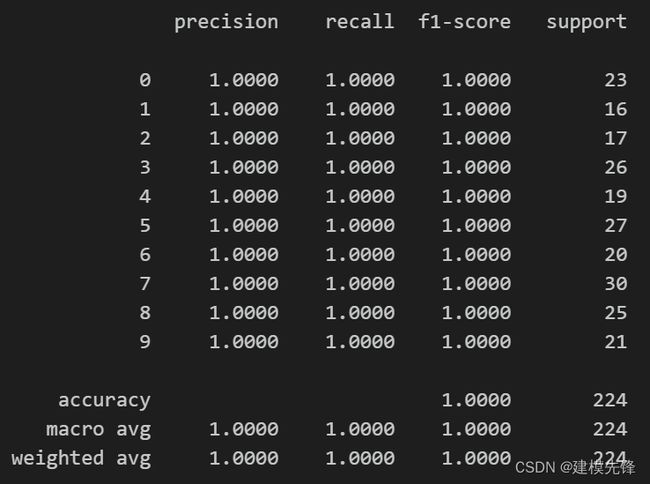
故障十分类混淆矩阵:
代码、数据如下: