《算法分析与设计》复习笔记
目录
一、算法的基本概念
1.1 算法的定义
1.2 算法的“好坏”如何衡量?
1.3 描述算法的时间复杂度 ⭐
1.4 如何评价算法
二、 分治法
2.1 分治法的求解步骤
2.2 平衡的概念
2.3 递归式解法
2.3.1 主定理法 ⭐
2.4 分治法的使用条件
2.5 分治法实例
2.5.1 快速排序
2.5.2 最大元最小元问题
2.5.3 最近点对
2.5.4 寻找顺序统计量(求第i小、最大元、最小元、中位数)
三、动态规划
3.1 动态规划的适用范围
3.2 动态规划的求解步骤
3.3 动态规划方法求解实例
3.3.1 矩阵连乘(区间DP问题)
3.3.2 LCS(最长公共子序列)
3.3.3 最大子段和
四、贪心
4.1 贪心算法的基本思想
4.2 贪心算法的适用情况
4.3 贪心算法实例
4.3.1 活动安排问题
4.3.2 单元最短路径 Dijkstra算法
4.3.3 最小生成树Prim 及 kruskal算法
五、随机算法
5.1 随机算法的分类⭐
5.2 Sherwood算法
5.3 随机算法求解实例⭐
5.3.1 快排(随机化版本)
5.3.2 求第i小元素(随机化版本)
5.3.3 Test String Equality (比较两个串是否相等)
5.3.4 Pattern Matching(一个串是不是另一个串的子串)
5.3.5 主元素问题
六、回溯法与分支限界法
6.1 生成问题状态
6.2 回溯法
6.3 分支限界法
6.3 回溯法常见的解空间树
6.3.1 子集树
6.3.2 排列树
6.4 求解实例
6.4.1 01背包问题(子集树)
6.4.2 TSP(排列树)
七、NP完全性理论⭐
7.1 最优化问题和判定问题
7.2 P, NP, NPC, NP-hard问题
7.2.1 什么是P, NP, NPC, NP-hard问题
7.2.2 P, NP, NPC, NP-hard问题之间的关系
7.3 规约(问题的多项式变换)
7.3.1 什么是规约
7.3.2 规约的作用
7.4 NPC问题实例
八、近似算法
8.1 近似算法的性能
8.2 实例——装箱问题(Bin Packing)
一、算法的基本概念
1.1 算法的定义
算法是由若干条指令组成的有穷序列,具有5个特性:确定性、能行性、输入、输出、有穷性
1.2 算法的“好坏”如何衡量?
用计算时间来衡量一个算法的好坏在不同的机器之间无法比较,需要用独立于具体计算机的客观衡量标准:
问题的规模:一个或多个整数,作为输入数据量的测度
基本计算:解决给定问题时占支配地位的运算
算法的计算量函数:用问题规模的某个函数来表示算法的基本运算量,这个表示基本运算量的函数称为算法的时间复杂度,用 T(n) 来表示
1.3 描述算法的时间复杂度 ⭐
Ο,表示渐进上界(tightness unknown),小于等于的意思,近似复杂度。
Ω,表示渐进下界(tightness unknown),大于等于的意思,近似复杂度。
Θ,表示确界,既是上界也是下界(tight),就是相等,准确的复杂度。
n! 与2^n 相比,当n>3的时候,n! 会更大一点

1.4 如何评价算法
正确性(首要因素)、高效性、健壮性、简单性、最优性
二、 分治法
2.1 分治法的求解步骤
求解步骤:分解、求解、合并;(先分后治)
他的求解过程就用递归的方式来求解
2.2 平衡的概念
把一个问题分成两个规模相近的子问题,例如快速排序,分成的两个子问题只要不是特别极端的情况,也算平衡。
2.3 递归式解法
代换法、递归树方法、主定理。(这里只详细介绍主方法,其他方法可以参考慕课上一个北航的老师的讲解,哔哩哔哩上也有视频,这个老师的主定理法讲的也非常好,理解起来很快 [2.2.1]--2.2递归式求解上_哔哩哔哩_bilibili)
先认识一下递归方程:T(n) = aT(n/b) + f(n)
其中,a:归约后子问题的个数,
n/b :归约后子问题的规模(aT(n/b) 为 叶子成本)
f(n):组合子问题时产生的工作量(f(n) 为合并成本)

2.3.1 主定理法 ⭐
1、主定理法内容
对于递归式T(n) = aT(n/b) + f(n),比较根节点代价之和f(n)和叶子节点代价之和![]() 的大小
的大小

也就是在比较合并成本和叶子成本,究竟谁更大。粗略的理解如下:
① f(n)多项式意义大于 ![]() ,不止渐进大于且相差n^ε,所以总体代价以f(n)为主;(这里忽略了对正则条件的理解,感觉不影响使用,想了解深层原理可以看一下课本)
,不止渐进大于且相差n^ε,所以总体代价以f(n)为主;(这里忽略了对正则条件的理解,感觉不影响使用,想了解深层原理可以看一下课本)
② f(n)与 ![]() 等阶,最后的结果要再乘以logn
等阶,最后的结果要再乘以logn
③ f(n)多项式意义小于![]() ,不止渐进小于且相差n^ε,所以总体代价为
,不止渐进小于且相差n^ε,所以总体代价为![]()
这三种情况画在线段上如下图所示,所以中间哪些无法覆盖的部分就是这个定理无法涵盖的情况。具体的讲解还是可以看看那个北航老师的视频。

2. 主定理法的应用
例1:求解递推方程T(n) = 9T(n/3)+n
解:上述递推方程中,a=9, b=3, f(n) = n
![]() =
= ![]() = n²,
= n², ![]() ,ε取1
,ε取1
所以,T(n) = Θ(n²)
分析:在这个题中,a=9, b=3, f(n) = n,先求
=
= n²
(再与 f(n)进行对比,发现
相当于也是就上述的情况③,ε取1,T(n) = Θ(n²)
例2:求解递推方程T(n) = T(2n/3)+1
解:上述递推方程中,a=1, b=3/2, f(n) = 1
![]() =
= ![]() = n^0=1,
= n^0=1,
所以,T(n) = Θ(log n)
分析:在这个题中,a=1, b=3/2, f(n) = 1,先求
(再与 f(n)进行对比,发现与
也是就上述的情况②,所 以最后的T(n)就是
即 T(n) = Θ(log n)
例3:求解递推方程T(n) = 3T(n/4)+nlogn
解:上述递推方程中,a=3, b=4, f(n) = nlogn
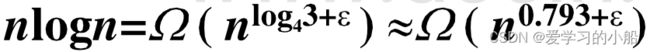
取ε = 0.2, 则T(n) = nlogn
分析:在这个题中,a=3, b=4, f(n) = ,先求
次数是比 n小的,
再与 f(n)进行对比,发现 f(n)中 n 的部分是1次方,比
也是就上述的情况1,所 以最后的T(n)就是f(n),
即 T(n) = Θ(n log n)
不能使用主定理的:
例4:T(n)=2T(n/2)+nlogn
分析:在这个题中,a=2, b=2, f(n) = nlogn,先求
(再与 f(n)进行对比,发现f(n) 的 n 部分 与
这种情况,等于落入了①和②之间的红点,就是不满足使用主定理的,可以考虑使用拓展定理

总体来看,从只考虑做题的角度理解例3和例4,就是:比较![]() 与f(n) 中n 的次数,先不管f(n)中的 logn ,如果f(n)的次数高,就取f(n),如果
与f(n) 中n 的次数,先不管f(n)中的 logn ,如果f(n)的次数高,就取f(n),如果 ![]() 的次数高,就取
的次数高,就取![]() ,
,
但是如果f(n)中的n的次数与![]() 相等,然后f(n)还有logn 的部分,就属于是主定理一般情况无法解决的了,可以用递归树,也可以用主定理的扩展形式。
相等,然后f(n)还有logn 的部分,就属于是主定理一般情况无法解决的了,可以用递归树,也可以用主定理的扩展形式。
3. 主定理的扩展形式

扩展形式中,对于情况②,增加了![]() ,也就是说,如果遇到f(n)的n的次方与
,也就是说,如果遇到f(n)的n的次方与![]() 相等,哪怕f(n)有log n 的部分,总体的T(n) 还是f(n) 再乘一个 log n,画在线段中,也就是多了以下的一些点的情况。
相等,哪怕f(n)有log n 的部分,总体的T(n) 还是f(n) 再乘一个 log n,画在线段中,也就是多了以下的一些点的情况。

还看例4:T(n)=2T(n/2)+nlogn
解: a=2, b=2, f(n) = nlogn,先求 ![]() = n
= n
f(n) = Θ(![]()
![]() ), k=1
), k=1
T(n) = Θ(![]()
![]() ) = Θ(
) = Θ( ![]() )
)
参考链接 :
北航老师的讲解视频:[2.2.2]--2.2递归式求解下_哔哩哔哩_bilibili一个写的很清楚的博客:
【算法设计与分析】12 主定理及其应用_杨柳_的博客-CSDN博客_t(n)=3t(n/4)+nlogn
有例题的文档:2.8.主定理的应用 - 豆丁网
关于一个疑问的解答:
T(n)=3T(n/4)+nlgn与T(n)=2T(n/2)+nlgn在主定理的应用上有什么区别? - 知乎
2.4 分治法的使用条件
(1)问题缩小到一定的规模(子问题)时易解决
(2)原问题与分解后的子问题同类(即该问题具有最优子结构性质)
(3)原问题的解可以由子问题的解合并得到
(4)子问题相互独立,不包含公共问题。
2.5 分治法实例
2.5.1 快速排序
1、过程:
分解:根据选取的主元大小,将数组分成两部分,[p …… q-1] 和 [q+1 …… r], 是的前部分都小于这个主元A[q], 后半部分都大于A[q]
解决:递归调用快速排序算法,分别对分成的两段进行排序
合并:由于子数组是原地排序,所以合并的时候不需要操作
2、分治法的思想体现在:
挑主元,用主元作为基准元素,依次遍历数组,完成划分过程,这个划分的过程就是分治中标准的分解的过程
3、复杂度分析
快排:平均O(nlogn),最坏情况O(n^2)
插入排序:将未排序的元素一个一个地插入到有序的集合中,插入时把所有有序集合从后向前扫一遍,找到合适的位置插入。 最坏时间复杂度O(n^2)
归并排序:需要额外空间:O(n) 时间复杂度:O(nlogn)
快排的最坏时间复杂度产生的原因:
例如说主元每次都是最右边的元素,而这个数组本身又是递增的,那每次分解,都只能分解成长度为 n-1 和 1 的两个数组,相当于,每次遍历只能排好一个数组,每次都需要对n个元素进行遍历,并且要划分n次才能分好,复杂度就是O(n^2)
4、快排的随机版本
随机的选取主元,使得在概率上避免最坏情况
代码思路参考:
Acwing算法基础学习笔记(一)快排和归并_爱学习的小船的博客-CSDN博客
2.5.2 最大元最小元问题
1、问题描述
高级表述:给定n个数据元素,找出其中的最大元和 最小元
翻译:就是求一个数组中的最大的数和最小的数
2、解题思路
如果直接求解,就是遍历整个数组,记一下最大或者最小的数,这样找到最大元需要n-1 次,再找最小元需要 n-2 次,总共需要 2n-3 次
先分析是否满足分治法的使用条件:
其实仔细想,可以发现,求一个数组的最大最小元,可以分成求子数组的最大最小值,然后再合并起来,他是拥有最优子结构并且子问题相互独立的,满足分治法的使用条件
所以就可以尝试一下分治法啦,先考虑特殊情况:
if n=1 ,就可以直接判断出,最大元和最小元
如果n>1,步骤还是考虑分治法的三部曲:
- 分解:将一个数组平均分成两份
- 求解:对左右两份数组都分别递归调用这个算法,求取每份的最大或者最小,直到数组只剩俩数或者一个数,底层就只需要一次
- 合并:合并的时候,比较左右两边的最大元和最小元
- 找最大元的过程如图所示:
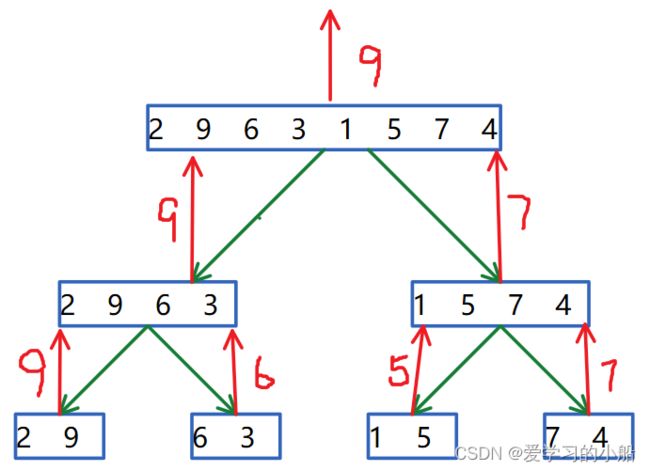
- 找最大元的过程如图所示:
3、分治法求数组最大元、最小元的算法下界
算法的复杂度是线性的,算法下界为3n/2-2。分析过程如图:

4、算法实现
#include
using namespace std;
void findMaxMin(int str[], int l, int r,int &max, int &min)
{
// 递归出口
if(l==r){
max = str[l];
min = str[l];
}else{
int mid = (l + r) >> 1;
int lmax,lmin,rmax,rmin; //分别记录两边的最大最小值
//递归执行左右两段
findMaxMin(str, l, mid, lmax,lmin);
findMaxMin(str, mid+1, r, rmax, rmin);
//合并比较左右的最大值最小值
if(lmax >= rmax){
max = lmax;
}else{
max = rmax;
}
if(lmin <= rmin){
min = lmin;
}else{
min = rmin;
}
}
}
int main()
{
int str[] = {2,9,6,3,1,5,7,4};
int l = 0, r=7;
int maxmin[] = {0,0};
int max,min;
findMaxMin(str, l, r, max, min);
cout << "max:" < 2.5.3 最近点对
1、问题描述
就是求空间内,最近的两个点(最简单的就是一维问题,然后可以上升为二维的)
2、一维的最近点对的解题思路
同理,先分析是否满足分治法的适用条件:可以把空间分成两部分,求每个小空间的最近距离,但是在合并的时候,交界处比较难处理,但是也算是满足条件
分治法求解:
分解:用各个点坐标的中位数m 作为分割点,分成两个点集
解决:递归调用该算法,分别寻找两个点集上最接近的点对{p1, p2}、{q1, q2}及距离d1,d2
合并:整个点集的最近点对或者是{p1, p2},或者是 {q1,q2},或者是某个{p3,q3},其中p3和q3分属两个点集(整个情况在合并的时候要仔细分析)
合并策略:
如果说两个点集的交界处有更近的点,那找到这俩个点,需要扫描的范围其实不会超过,两边的最近距离d的二倍,画个图如下所示,这2d的范围中,最多只可能会有4个点,如果说p1和p2之间还有其他的的点,那就会构成比d更近的距离了
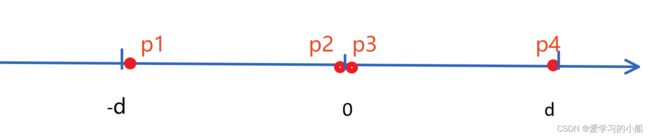
所以,合并的时候,我们需要在从分割点 出发 分别往左右扫描扫描到d的距离,看看是否会出现更近的情况就可以啦
3、二维最近点对问题的解题思路
有了一维的基础,再考虑二维的问题就好理解多了,直接来分治法求解过程:
(1)预处理:将点集P中的点,按照X Y坐标从小到大顺序排列
(2)分解:计算x坐标中位数m,选择一条垂线L:x=m,将点集P分成左右两部分PL和PR,分解到最后的递归出口,剩1~3个点时,就可以直接计算了

(3)解决:递归调用该算法,分别找PL和PR中的最近点对及距离,距离分别记为δL, δR,置δ = min(δL, δR)
(4)合并:考察带状区域中的点
① 找出以L为中心线,宽度为2的带状区域
② 获得带状区域中排序后的点集Y’
③ 对Y’中的每个点,检查其后面的7个点,计算距离并更新最近点对的距离
为啥是7个点呢,看以下分析:
其实跟一维一个道理,再这个带状区域中,最多只可能存在8个点,如下图,因为如果再想多一个点,就会在L的一边存在比δ更进的距离,所以,只需要分析一个点往后的7个点就足够了

4、时间复杂度分析
递归式为:T(n) = 2T(n/2)+f(n)
f(n) = O(n)
得出最后时间复杂度:==> T(n) = O(nlgn)
2.5.4 寻找顺序统计量(求第i小、最大元、最小元、中位数)
最大元最小元都可以看作 求第i小元素的特例,本节给出两种解决方法
1、期望线性时间求解方式 (期望线性时间:Ө(n),最坏情况Ө(n^2))
(1)分解:使用random partition 对数组进行划分(随机选取一个主元x 把数组划分为两部分,A[l...q-1]的元素比x 小,A[q+1...r]的元素比x 大,排完后,x在A[q] 的位置上)
(2)解决:(参考快排的思路)
①如果 x 的位置 q = i,说明这个x就是我们要找的第i小元素,直接返回x
② 如果 x 的位置 q 比要找的 i 大,那证明第i小元素在左边的那一段,也就是A[l...q-1]中,i 不需要改变,递归执行
③ 如果 x 的位置 q 比要找的 i 小,那证明第i小元素在右边的那一段,也就是A[q+1...r]中,i 需要更新: i = i - q + 1(加一是因为,第一个数组下标为0),递归执行
(3)合并:找到了直接返回,无需合并
2、最坏情况线性时间求解方法
为啥会产生最坏情况呢?——如果每次选取的主元的都不是这个元素,且,导致划分的左右区间不平衡,导致每一轮分解,只能排除掉一个元素,那时间复杂度就是Ө(n^2)
为了更好的避免最坏情况,就在选取主元的时候更科学一点,它也是基于数组的划分操作,而且利用特殊的手段保证每次划分两边的子数组都比较平衡;与上面算法不同之处是:本算法不是随机选择主元,而是采取一种特殊的方法选择“中位数”,这样能使子数组比较平衡,避免了上述的最坏情况(Ө(n^2))。选出主元后,后面的处理和上述算法一致。
(1)将输入的数组中的n个元素,5个分成一组, 共ceil(n/5)组(ceil函数可以看作进一法)(如下图,每一列是一组)
(2)首先对每组中的元素进行插入排序,然后选择每一组的中位数(图中黄色的点)
(3)对第二步中的中位数们,递归调用SELECT以找到中位数的中位数(也就是从黄色点中找中位数:红色点x)
(4)x 就是我们在 分解partition阶段的主元,(之后的【解决、合并】操作,就与上边那个算法一样了,)按照中位数x 对数组进行划分,确定中位数x的位置p
(5)如果i=k,则返回x。否则,如果i

三、动态规划
3.1 动态规划的适用范围
分解子问题,子问题重叠,
具有最优子结构的性质(即 大问题的最优解包含小问题的最优解)
求解的方式是自底向上,先求小问题
3.2 动态规划的求解步骤
问题结构分析----递推关系建立----自底向上分析----最优方案追踪
3.3 动态规划方法求解实例
3.3.1 矩阵连乘(区间DP问题)
1、问题描述
(1)两个矩阵A和B ,维度分别是 p×q 和 q×r,这两个矩阵相乘需要做p*q*r次乘法
(2)三个矩阵A, B, C,维度分别为10*100,100*5, 5*50,
①如果按照A*B*C的顺序,A*B 需要 10*100*5 = 5000 , (A*B)*C 需要 10*5*50 = 2500 总共需要 7500次
②但是如果按照A*(B*C)的顺序,B*C 需要 100*5*50= 25000,A*(B*C) 需要 10*100*50 = 50000 总共需要75000次
所以不同的计算顺序所产生的代价不同,
(3)n个矩阵相乘,求最小化乘法运算次数?
P数组由n-1个数据组成,记录矩阵的维度,例如刚刚(2)中的情况,P数组就是{10,100,5,50} P[i]×P[i+1] 即为 第i个矩阵的维度
2、分析步骤
step1: 问题结构分析
先考虑4个矩阵的情况,从M1乘到M4, 如下图所示
第一次选择分割点的时候,有3种分法(如第2层),则第一层的最优结果可以从第二层的情况的基础上进行分析,找到最优的情况,
同理要算第二层各自也有不同的分割方法(如第3层)第三层中又有很多重复的问题,所以这个问题既有最优子结构,子问题之间也有重复,我们就可以考虑动态规划的方法

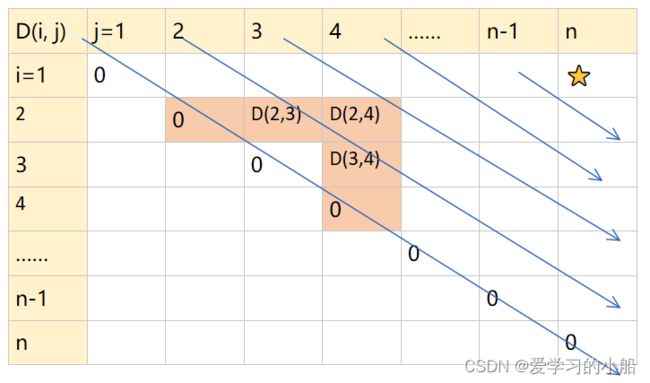
step2: 递推关系建立:
D数组 为动态规划数组,(i, j)位置上的数表示 矩阵从 i位置乘到 j位置的 最优次数P数组 由n-1个数据组成,记录矩阵的维度,例如刚刚 1、(2)中的情况,P数组就是{10,100,5,50} P[i-1]×P[i] 即为 第i个矩阵的维度
例如 U1 × U2 需要做的乘法次数,就是 P(0)*P(1)*P(2)
如果算(U1 × U2)✖ U3 的次数就是 上一步U1 × U2 的次数,加上P(0)*P(2)*P(3) ,如果把i=1, k=2, j=3带入,则其实就是P(i-1)*P(k)*P(j)
如上图所示,从下标为 i 的矩阵乘到 j,在 k 处分割的最优情况,就等于 从 下标为 i 的矩阵乘到 k的最优情况 D(i, k),加上从k+1 乘到j 的最优情况D(k+1, j) ,再加上两边合并的时候要做的乘法次数P(i-1)*P(k)*P(j) 来计算(就上图中第三行的几个数相加)

在遍历不同的k的分割方法,取最小的分割方法,得到递归方程如下所示:
- D[i,j] = min i≤k
- D[i,j] = 0, if i=j
step3: 自底向上计算:
建立备忘录如下表所示,初始化:当i=j的时候,D为0,即对角线为0,又因为i是矩阵乘法的起点,j为矩阵的右边,所以i eg: 取 i= 2 ,j = 4 ,则 k 可以遍历的范围为{2,3} k=2 时,D[i, j] = D[2,2] + D[3,4] +P1×Pk×Pj , k=3 时,D[i, j] = D[2,3] + D[4,4] +Pi-1×Pk×Pj 我将这几个用到的框标成橙色,可以看出,每次一个框的生成,取决于其向左,以及向下的框,所以,我们在生成DP表的时候,顺序就如下图所示: 用x表示链长,就是遍历x 从 1 到 n -1 ,也就是 链长从最短--> 最长,最优解就在链长最长的位置 D(1,n)上 递归出口: i=j 的时候,就是 链长为1 step4: 最优方案追踪 // 建立rec矩阵,存放k的取值来源 //时间复杂度:O(n^3) 1、问题描述 子序列:就是一个字符串去掉某些字符之后组成的新串:例如abcdefg 的 子串有f, abc, bde……可以不连续,但是不能改变相对顺序,例如 ba 就不是找个字符串的子串 LCS 就是求 两个字符串X和Y 的 最长的公共子序列 2、解题步骤 step1:问题结构分析 如果蛮力法解决问题,就是枚举检查每一种长度的所有的子序列,然后一个个对比,可以想象,例如对比长度为3的子串之后,在对比长度为4的子串的时候,字符串只是比长度为3的情况一些情况多了一个字符,那对比长度为4的子串的时候,其实可以只对比多的那一个字符就可以了,如下图所示,很明显,这个问题有最优子结构性质,且子问题相互重叠。 step2:递推关系建立 建立一个动态规划数组D,(i,j)位置上的数表示:X字符串的 1~i 位 和 Y 字符串的1~j位置的最长公共子串的长度 分析子问题:只用比较两个字符串,分别加入的两个字符的情况即可,得到方程如下: if X[i] == Y[j], 则D[i,j] = D[i-1, j-1]+1; step3:自底向上分析 初始化状态:当i=0 或者j = 0 的时候,没有公共子串,所以记为0, 如上图所示,每个数据的更新来源取决于左、左上、上,这三个表格,所以执行顺序就如下表所示,最优解在D[n,m]处 step4:最优方案追踪 //建立一个rec二维数组,记录每个位置上更新的来源,最后根据方向,找最优子结构 //时间复杂度O(n·m) 1、问题描述 在一个整数序列中,某个区间的所有数的和即为子段和,求子段和的最大值 //这个题也可以用分治法来解决,O(nlogn) 2、分析过程 step1:问题结构分析 如果用暴力解法,那就需要两个纸质直接对整个数组进行遍历,复杂度O(n^3),但是自信分析,找问题子结构,会发现,区间内的最大值,可以分成子区间的最大值,然后 只用考虑新加的某个元素,具有子问题重叠,且有最优子结构,可以用dp 子问题界定:设前边界为1,后边界为i,且D[i] 是子序列A[1,…,i] 必须包含A[i]的向前连续眼神的最大字段和 step2:递推关系建立 这个题中,可以直接建立一个一维动态数组D,就是上一步中的D[i] ,最后的输出结果的时候,遍历下这个数组,找到最大的值就行 在新增 i 位置的时候,就比较一下 上一个位置的最大字段和 是不是正数,如果是正数,就把这个值累加上去,如果上一个值为负数,则1~i位置的最大字段和,就是i位置上的元素,递归方程如下 D[i] = max{D[i-1]+A[i], A[i]} , 1 我刚开始很不理解,为什么不用考虑A[i]的正负?其实,本身D[i]记录的元素 就是指必须要包含A[i] 的,所以不需要考虑A[i] 的正负,只需要考虑,是重新开始记数呢,还是累加前边的最大字段和来记数,这里感觉跟其他的动态规划不是特别一样,如果不太清楚的小伙伴,其实画个表就很明白了。 假设A数组为 {-3, 4, 5, 3, -2, 9, -2},动态规划数组D 与 A 如下所示 A[i]<0 则 D[i-1]=0 则 D[2] = 0+4 D[i-1]=4 则 D[3] = 4+(-5) D[i-1]=-1<0 则 D[4] = A[4] D[i-1]=3 则 D[5] = 3+(-2) D[i-1]=1 则 D[2] = 1+9 D[i-1]=10 则 D[2] = 10+(-2) 最后在对D[i]进行遍历,找到最大的就是D[6]=10 // 时间复杂度 O(n) ●适用于求解最优化问题的算法往往包含一系列步骤,每一步都有一组选择 贪心算法是自顶向下的,有的时候,为了保证贪心算法可以获得全局最优解,需要做个证明,要证明贪心选择的安全性。 比如01背包问题,就不能做全局最优解。因为01背包问题,物品不可分割,它无法保证最终剩下的物品能将背包装满,部分闲置的背包空间会使单位重量背包空间的价值降低 但是背包问题是可以的,因为背包问题可以将某个物品分成小部分装进去,不会出现闲置的背包空间,所以可以用贪心策略) 1、可以根据下列步骤设计贪心算法 听慕课一个老师讲的例子挺好的: 2、许多可以用贪心算法求解的问题,具备以下两种性质 (1)贪心选择性质 指所求问题的整体最优解可以通过一系列局部最优的选择,即贪心选择来达到 (2)最优子结构性质 当一个问题的最优解包含其子问题的最优解时,称此问题具有最优子结构性质 1、问题描述 设有n个活动的集合E={1,2,…,n} 2、贪心策略 按照最早结束活动优先,贪心就体现在,总是选择最早结束的相容活动(即时间不冲突) 3、解决步骤 (1)先将活动按照结束时间递增排列 (2)一开始选择活动1,然后依次检查后边的活动是否与前边已选的时间相容 (3)不冲突就加入选择,冲突就不加入 4、时间复杂度 不带排序的话O(n),排序另需要O(nlogn) 1、问题描述 ➢给定带权有向图G =(V,E),其中每条边的权是非负实数| 2、贪心策略 总是每次从V-S集合中选择具有最短特殊路径长度的顶点u,将u加入S,并对dist数组进行修改,贪心体现在:对V-S中的点的选择上 3、时间复杂度 对于具有n个顶点和e条边的带权有向图,如果用带权邻接矩阵表示这个图,其时间复杂度为O(n^2) 1、prim算法 ● 先置 S= {1} (其实意思就是,从节点1出发,先将1加入S,S为已走过的节点集合,每次选择还没有走过的节点 j,也就是在V里,但是不在S里的节点,比较其与已经在S中的节点i 的边,选择最小的边,将节加入集合) 2、Kruskal算法 先将n个顶点看作n个孤立连通分支,将边从小到大排序,若某边加入不形成回路,就选这个边加入生成树中 Las Vegas:不一定有解,但有解的话一定正确(我们关注其求不到解的概率) Monte Carlo:可能会出错,我们关注他出错的概率(不能保证解是正确的,但是通过算法反复执行,能够使错误概率很小),每次执行的算法是独立的,故k次执行均发生错误的概率为(1-p)K 属于拉斯维加斯算法,总能求得一个解,并且这个解是正确的 如果某个问题已经有了一个平均情况下较好的确定性算法,但是该算法在最坏情况下效率不高,此时引入一个随机数发生器(通常是服从均匀分布,根据问题需要也可以产生其他的分布),可将一个确定性算法改成一个随机算法,使得对于任何输入实例,该算法在概率意义下都有很好的性能,例如快排、第i小元素 随机地找主元,属于拉斯维加斯,更属于sherwood 利用拉斯维加斯原理,先在n个数中随机找一个数,将其余n-1个跟他比较,将数组按照大于等于小于,分成三个部分,然后再比较这k跟i之间的关系,要么就找到了,要么就缩小范围,再次调用找。 ●在n个数中随机的找一个数A[i]=x,然后将其余n-1个数与x比较,分别放入三个数组中: S,(元素均 若以等概率方法在n个数中随机取数,则该算法用到的比较数的期望值不超过4n 1、问题描述 设A处有一个长字符串x,B处也有一个长字符串y,A将x发给B,由B判断是否 x=y 2、算法分析 属于蒙特卡洛算法,随机性体现在取的那个小于M的素数p是随机的(M和p 见下一小节(3\常用指纹))(其实也就是说,指纹的选取是随的) ●首先判断俩串长度是否相等,不相等,直接x ≠ y 3、常用指纹 ●令I(x)是x的编码,取Ip(x) = I(x) (mod p)作为x的指纹(就是取余操作,比较余数是否相等) 4、误判率 ●误匹配的概率小于1/n,当n很大时,误匹配的概率很小 1、问题描述 给定两个字符串X=x1,…, xn; Y= y1,…,ym,判断Y是否是X的子串 2、算法分析 (1)蒙特卡洛算法 ●记X(j) 字符串 表示 从X的第j位开始、长度与Y一样样的子串 随机性还是体现在 取的那个小于M的素数p是随机的 时间复杂度分析: ●计算Ip(Y)、Ip(X( 1))及2m mod p的时间不超过O(m)次运算 ●由于循环最多执行n-m+1次,故这部分的时间复杂度为0(n),于是,总的时间复杂性为O(m+n) 失败的概率: 与x的长度有关,与Y的长度无关 (2)拉斯维加斯算法 ●在蒙特卡洛算法的基础下,若Ip (X(j)) = Ip (Y),不返回j,而是取比较Y和X(j) 该算法出错的概率为0 1、问题描述 其实就是看一个数组中,有没有哪个数出现的概率大于 n/2 (也就是,占据了这个数组一半以上),如果有,这个数就是主元素,如果没有,数组就没有主元素 2、算法分析 选取一个不超过数组个数的随机数n,然后以n+1作为元素下标选择元素,判断该元素是否为主元素 计算的时间与调用次数有关,属于蒙特卡洛算法 ●扩展节点:一个正在产生自己儿子的节点 1、基本概念 回溯法是基于DFS(深度优先搜索)进行改进的,寻着一条可能的解的路径走下去,如果继续下去不满足条件,则剪枝换一个路径继续,它是一种可以避免不必要搜索的穷举式搜索法。(还是穷举的,只是在一定意义上减少了计算量)适用于一些组合数较大的问题 2、搜索思路 (1)先定义问题的解空间 常用剪枝函数: 约束函数:在扩展结点处减去不满足约束的子树 限界函数:剪去得不到最优解的子树 1、基本概念 分支限界法是基于BFS(广度优先搜索)的,但是也不完全是DFS的,以广度优先或以最小消耗优先的方式搜索解空间树。 2、基本思想 (1)在分支限界法中,每一个活结点只有一次机会成为扩展节点,活结点一旦成为扩展节点,就一次性产生其所有的儿子节点,在这些儿子节点中,导致不可行解或导致非最优解的儿子结点被舍弃,其余儿子节点被加入到活结点表中 (2)此后,从活结点表中取下一结点成为当前扩展结点,并重复上述结点拓展过程,这个过程一直持续到找到所需的解或活结点表为空时为止 当所给问题是从n个元素的集合S中找出S满足某种性质的子集时,相应的解空间树成为子集树(看上去可能不是很好理解,但是可以看一下6.4.1的01背包问题的解空间树,其实就是把每个物品当作一个结点,以0或1 作为边,然后构成的各种选的结果,就是子集树) 当所给问题是确定n个元素满足某种性质的排列时,相应的解空间树称为排列树(这个如果可以参考6.4.2的TSP问题的排列树,就是把物品当做边,然后构成了不同的排列组合,形成的一棵树) 边表示选或者不选,节点表示现在背包中的情况。 参考链接: 0-1背包问题-分支限界法(优先队列分支限界法)_迷雾总会解的博客-CSDN博客_0-1背包问题分支限界法 1. 问题描述 某售货员要到若干城市去推销商品,已知各城市之间的路程(或旅费)。他要选定一条从驻地出发,经过每个城市一次,最后回到驻地的路线,使总的路程(或总旅费)最短(或最小)。 2. 排列树 假设城市编号为1,2,3,4,每两个城市之间的距离如下图所示 (1)定义解空间:X={12341, 12431,13241,13421,14231,14321} 参考链接: 解空间树(排列树).ppt (book118.com) ● 判定问题:回答“YES”和“NO”的问题 ● 最优化问题(不是Yes-No问题)可以与一 个判定问题相对应。 例如说:找到一个图G中的最大团是最优化问题;图中是否有K团就是判定问题 ● P类问题是多项式时间内可解的 ● NP类问题是多项式时间内可验证 ● NPC问题:存在这样一个NP问题,所有的NP问题都可以约化成它。这种问题不只一个,它有很多个,它是一类问题。这一类问题就是NPC 问题。其定义要满足2个条件: ● NP-hard问题:满足NPC问题定义的第二条而不满足第一条。即所有的NP问题都能约化到它,但是他不一定是一个NP问题。 问题A可以规约为B(记作A≤pB) (≤p亦称Karp规约),可以理解为问题B的解一定就是问题A的解,因此解决A不会难于解决B。由此可知问题B的时间复杂度一定大于等于问题A。 《算法导论》中有一个例子:现在有两个问题:求解一个一元一次方程和求解一个一元二次方程。那么我们说,前者可以规约为后者,意即知道如何解一个一元二次方程那么一定能解出一元一次方程。我们可以写出两个程序分别对应两个问题,那么我们能找到一个“规则”,按照这个规则把解一元一次方程程序的输入数据变一下,用在解一元二次方程的程序上,两个程序总能得到一样的结果。这个规则即是:两个方程的对应项系数不变,一元二次方程的二次项系数为0。 ● 若问题A可规约为B,且问题B是多项式时间可判定的,则问题A也一定是多项式时间可判定的 ● 要证明一个判定问题B是NP-C的,除了要证明B是多项式时间可验证的(从而B属于NP类),还要找一个NP-C问题A,证明A可以在多项式时间里变换为B,且A的任一实例回答为‘Yes’ 当且仅当 与之对应的B的实例回答为‘Yes’ ● K-团问题: 参考链接: 现代优化算法三部曲 | 入门介绍 - 知乎 (zhihu.com) P问题、NP问题、NPC问题、NP-hard问题详解_困比比的博客-CSDN博客_p问题 若一个最优化问题的最优值为 c *,求解该问题的一个近似算法求得的近似最优解相应的目标函数值为 c,则将该近似算法的近似比定义为 max{c * / c, c / c *}( ⭐注意:近似比不会小于 1) 在通常情况下,近似比是问题输入规模n的一个函数ρ(n),即 max{c*/c, c/ c*} ≤ ρ(n) 1、问题描述 设有n个物体u1 ,u2 ,…,un,每个物体的体积不超过1。另外,有足够多的、体积为1的箱子。箱子、物体均是长方体且截面相同,如何装箱,使得所用箱子数最少? 2、First-Fit(FF)算法 ● 按照箱子顺序,对每个箱子剩余的体积逐一进行检查,一旦碰到第一个能够装进当前物体的箱子时,就立即把该物体装入这个箱子。对每个物体反复执行上述程序。 3、First-Fit Decreasing(FFD)算法 ● 先将所有物品从大到小排序,然后再使用FF法 总结一下相关可以看一看的链接: 算法设计与分析复习_Lemon_Yam的博客-CSDN博客_算法分析与设计复习 算法设计与分析【北京航空航天大学】_哔哩哔哩_bilibili

3.3.2 LCS(最长公共子序列)

if X[i] != Y[j], 则D[i,j] = max{D[i-1, j],D[i, j-1]}


3.3.3 最大子段和
0, if A[1] ≤0
i(位置)
1
2
3
4
5
6
7
A[i](原数组)
-3
4
-5
3
-2
9
-2
D[i]
0
4
-1
3
1
10
8
操作
D[1]=0
四、贪心
4.1 贪心算法的基本思想
●贪心算法总是作出在当前看来是最好的选择
●贪心算法并不从整体最优上加以考虑,它所作出的选择只是在某种意义上的局部最优选择
●贪心算法不能对所有问题都得到整体最优解,但对许多问题它能产生整体最优解
●在一些情况下,即使贪心算法不能得到整体最优解,其最终结果却是最优解的很好近似
●与动态规划方法相比,贪心算法更简单,更直接
4.2 贪心算法的适用情况
就例如我们在做人生的选择的时候,人生的阶段可以分为幼儿园-小学-初中-高中-大学 等等,然后贪心就是在每一个阶段做出最优的选择,然后将每个阶段的最优选择联合起来,就是人生的最优解
这是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别
动态规划算法通常以自底向上的方式解各子问题
贪心算法则通常以自顶向下的方式进行,以迭代的方式作出相继的贪心选择,每作一次贪心选择就将所求问题简化为规模更小的子问题
问题的最优子结构性质是该问题可用动态规划算法或贪心算法求解的关键特征4.3 贪心算法实例
4.3.1 活动安排问题
➢其中每个活动都要求使用同一资源,如报告厅等
➢而在同一时间内只有一个活动能使用这一资源
➢每个活动i 都有一个要求使用该资源的起始时间si 和一个结束时间fi,且si < f i
➢如果选择了活动i,则它在半开时间区间 [si ,f i ) 内占用资源,若区间[si ,f i )与区间[sj ,f j )不相交,则称活动i与 活动j是相容的
➢也就是说,当si ≥f j或sj≥fi时,活动i与活动j相容
目标:要在所给的活动集合中选出最大的相容活动 子集合4.3.2 单元最短路径 Dijkstra算法
➢给定V中的一个顶点,称为源
➢要求计算从源到所有其他各顶点的最短路长度(这里路的长度是指路上各边权之和)4.3.3 最小生成树Prim 及 kruskal算法
● 然后,每次选择 i ∈ S,j ∈V-S,且c[i][j] 最小的边,将 j 加入S,
● 直到S=V五、随机算法
5.1 随机算法的分类⭐
5.2 Sherwood算法
5.3 随机算法求解实例⭐
5.3.1 快排(随机化版本)
5.3.2 求第i小元素(随机化版本)
●若|S1|≥k,则调用Select(k,S1)
●若(|S1|+|S2|)≥k,则第k小元素就是x
●否则就有(|S1|+|S2|) < k,此时调用Select(k-lS1|-|S2l, S3)5.3.3 Test String Equality (比较两个串是否相等)
●如果长度相等,则采用“取”指纹的方法(指纹的选取是随机的):
➢A对x进行处理,取出x的“指纹”,然后将x的“指纹”发给B
➢由B检查x的“指纹”是否等于y的“指纹”
➢若取k次“指纹”(每次取法不同), 每次 两者结果均相同,则认为x与y是相等的
➢随着k的增大,误判率可趋于0
●这里的p是一个小于M的素数,M可根据具体需要调整
●设x≠y,如果取k个不同的小于2n2的素数来求Ip(x)和Ip(y)
●即k次试验均有Ip(x)=Ip(y)但x≠y (误匹配)的概率小于1/(n^k)
●当n较大、且重复了k次试验时,误匹配的概率趋于05.3.4 Pattern Matching(一个串是不是另一个串的子串)
●从起始位置j=1开始到j=n-m+1,不去逐一比较X(j)与Y,而仅逐一比较X(j)的指纹
Ip (X(j)) 与Y的指纹Ip (Y)
●由于Ip (X(j+1))可以很方便地根据Ip(X(j))计算出来,故算法可以很快完成
●Ip(X(j+1))的计算,只需用0(1)时间
●若相等,则返回j;否则,继续循环
5.3.5 主元素问题
多次调用上述方法,若找到主元素,则返回True
六、回溯法与分支限界法
6.1 生成问题状态
●活结点:一个自己已经生成了,但是其儿子还没有全部生成的节点
●死节点:一个所有儿子都已经产生了的节点6.2 回溯法
(2)确定易于搜索的解空间结构
(3)以深度优先方式,从根节点出发搜索解空间树,并在搜索中用剪枝函数的避免无效搜索
(4)算法搜索到解空间树的任一点时,先判断该节点是否包含问题的解
● 如果肯定不包含,则跳过该节点为根的子树的搜索,逐层向其祖先节点回溯
● 否则,进入该子树,继续按深度优先策略搜索
6.3 分支限界法
6.3 回溯法常见的解空间树
6.3.1 子集树
6.3.2 排列树
6.4 求解实例
6.4.1 01背包问题(子集树)
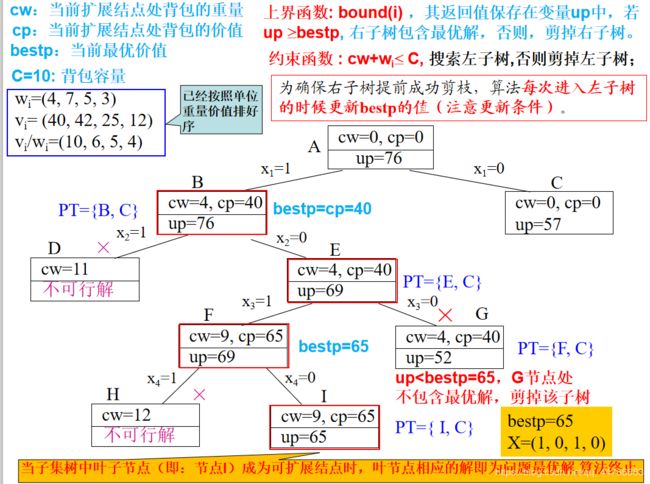
6.4.2 TSP(排列树)
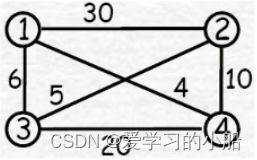
(2)构造解空间树:
(边表示每次选择的城市)
(3)从A出发按照DFS搜索整棵树
最优解:13241,14231;成本为25
七、NP完全性理论⭐
7.1 最优化问题和判定问题
(团 是指一个无向图G中,一组两两相连的节点组成的集合,K团就是这个团中有K个节点,最大团就是两两相连的节点组成的最大的团)7.2 P, NP, NPC, NP-hard问题
7.2.1 什么是P, NP, NPC, NP-hard问题
➢它是一个NP问题;
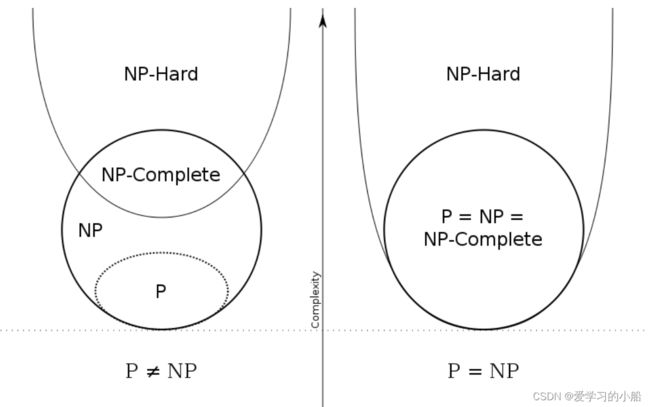
➢所有NP问题都能规约到它。7.2.2 P, NP, NPC, NP-hard问题之间的关系
7.3 规约(问题的多项式变换)
7.3.1 什么是规约
7.3.2 规约的作用
7.4 NPC问题实例

➢给定一个无向图 G=(V, E) 和一个正整数 k,判定图 G 是否包含一个 k 团
➢一个图 G 的 k 团是 G 的 k 个顶点的集合,使得这个集合中每对顶点之间都有边
● 子集和问题:
➢有一个数集 A={a1, a2, … , an} 及一个目标数 S,问 A 中是否能找出一个子集 A’,使得 A’ 中元素和为 S
● 顶点覆盖:
➢ 顶点覆盖的最优化问题:在一个无向图 G 中,找一个顶点数最少的顶点集,满足:任一条边的两个顶点中至少有一个在此集合中
➢顶点覆盖的判定问题:无向图 G 中是否存在顶点数为 k 的顶点覆盖
即:无向图 G 中是否存在 k 个顶点的子集,使得图 G 中的任一条边的两个顶点中至少有一个在此集合中
八、近似算法
8.1 近似算法的性能
8.2 实例——装箱问题(Bin Packing)
● FF算法满足:对于任何装箱实例I,都有FF(I)≤2OPT(I),更为准确的,都有FF(I)≤取下界的[17/10 OPT(I)],且存在OPT(I)任意大的实例I,使得FF(I)≥17/10(OPT(I)-1) (OPT(I)为最优解)
● 对所有装箱问题的实例I,有FFD(I)≤ 11/9OPT(I)+1