LLM:RoPE位置编码
论文:https://arxiv.org/pdf/2104.09864.pdf
代码:https://github.com/ZhuiyiTechnology/roformer
发表:2021

绝对位置编码:其常规做法是将位置信息直接加入到输入中(在x中注入绝对位置信息)。即在计算 query, key 和 value 向量之前,会计算一个位置编码向量  ,先加到词嵌入
,先加到词嵌入  上,然后再乘以对应的变换矩阵
上,然后再乘以对应的变换矩阵  :
:
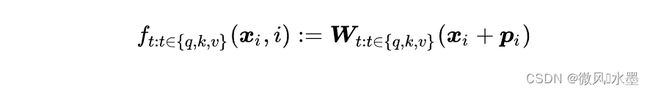
而经典的位置编码PE的计算方式是采用上篇文章提到的Sinusoidal 函数。
-
优势: 实现简单,可预先计算好,不用参与训练,速度快。
-
劣势: 没有外推性,即如果预训练最大长度为512的话,那么最多就只能处理长度为512的句子,再长就处理不了了。当然,也可以将超过512的位置向量随机初始化,然后继续微调。
相对位置编码:相对位置并没有完整建模每个输入的位置信息,而是在算Attention的时候考虑当前位置与被Attention的位置的相对距离,由于自然语言一般更依赖于相对位置,所以相对位置编码通常也有着优秀的表现。 (在k, v中注入相对位置信息)
- 优势: 直接地体现了相对位置信号,效果更好。具有外推性,处理长文本能力更强。
RoPE旋转式位置编码(Rotary Position Embedding)
1:RoPE通过绝对位置编码的方式实现相对位置编码,综合了绝对位置编码和相对位置编码的优点。
2:主要就是对attention中的q, k向量注入了绝对位置信息,然后用更新的q,k向量做attention中的内积就会引入相对位置信息了。
旋转位置编码RoPE 是目前大模型中广泛使用的一种位置编码,包括但不限于Llama、Baichuan、ChatGLM、Qwen等。
RoPE推导
图解RoPE旋转位置编码及其特性
十分钟读懂旋转编码(RoPE)
Transformer升级之路:2、博采众长的旋转式位置编码 - 科学空间|Scientific Spaces
复杂的推导公式,可以这3个链接进行理解。着重看一下公式11和公式13:有助于理解后面的RoPE的代码实现。


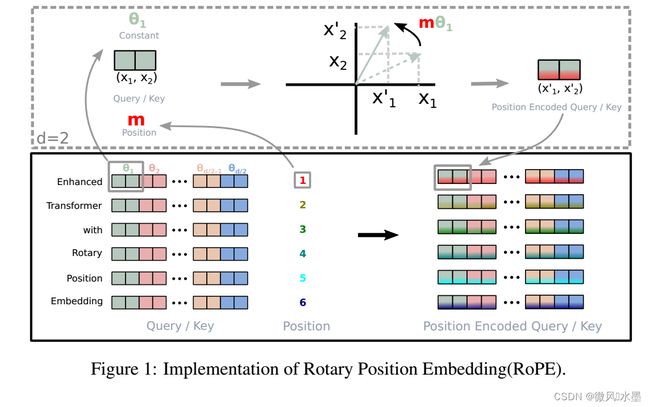
结合论文的图例:
1:对于 token 序列中的每个词嵌入向量,首先计算其对应的 query 和 key 向量
2:然后对每个 token 位置都计算对应的旋转位置编码
3:接着对每个 token 位置的 query 和 key 向量的元素按照 两两一组 应用旋转变换
4:最后再计算 query 和 key 之间的内积得到 self-attention 的计算结果
RoPE代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
def sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, device):
# (max_len, 1)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(-1)
# (output_dim//2)
ids = torch.arange(0, output_dim // 2, dtype=torch.float) # 即公式里的i, i的范围是 [0,d/2]
theta = torch.pow(10000, -2 * ids / output_dim)
# (max_len, output_dim//2)
embeddings = position * theta # 即公式里的:pos / (10000^(2i/d))
# (max_len, output_dim//2, 2)
embeddings = torch.stack([torch.sin(embeddings), torch.cos(embeddings)], dim=-1)
# (bs, head, max_len, output_dim//2, 2)
embeddings = embeddings.repeat((batch_size, nums_head, *([1] * len(embeddings.shape)))) # 在bs维度重复,其他维度都是1不重复
# (bs, head, max_len, output_dim)
# reshape后就是:偶数sin, 奇数cos了
embeddings = torch.reshape(embeddings, (batch_size, nums_head, max_len, output_dim))
embeddings = embeddings.to(device)
return embeddings
def RoPE(q, k):
# q,k: (bs, head, max_len, output_dim)
batch_size = q.shape[0]
nums_head = q.shape[1]
max_len = q.shape[2]
output_dim = q.shape[-1]
# (bs, head, max_len, output_dim)
pos_emb = sinusoidal_position_embedding(batch_size, nums_head, max_len, output_dim, q.device)
# cos_pos,sin_pos: (bs, head, max_len, output_dim)
# 看rope公式可知,相邻cos,sin之间是相同的,所以复制一遍。如(1,2,3)变成(1,1,2,2,3,3)
cos_pos = pos_emb[..., 1::2].repeat_interleave(2, dim=-1) # 将奇数列信息抽取出来也就是cos 拿出来并复制
sin_pos = pos_emb[..., ::2].repeat_interleave(2, dim=-1) # 将偶数列信息抽取出来也就是sin 拿出来并复制
# q,k: (bs, head, max_len, output_dim)
q2 = torch.stack([-q[..., 1::2], q[..., ::2]], dim=-1)
q2 = q2.reshape(q.shape) # reshape后就是正负交替了
# 更新qw, *对应位置相乘
q = q * cos_pos + q2 * sin_pos
k2 = torch.stack([-k[..., 1::2], k[..., ::2]], dim=-1)
k2 = k2.reshape(k.shape)
# 更新kw, *对应位置相乘
k = k * cos_pos + k2 * sin_pos
return q, k
def attention(q, k, v, mask=None, dropout=None, use_RoPE=True):
# q.shape: (bs, head, seq_len, dk)
# k.shape: (bs, head, seq_len, dk)
# v.shape: (bs, head, seq_len, dk)
if use_RoPE:
q, k = RoPE(q, k)
d_k = k.size()[-1]
att_logits = torch.matmul(q, k.transpose(-2, -1)) # (bs, head, seq_len, seq_len)
att_logits /= math.sqrt(d_k)
if mask is not None:
att_logits = att_logits.masked_fill(mask == 0, -1e9) # mask掉为0的部分,设为无穷大
att_scores = F.softmax(att_logits, dim=-1) # (bs, head, seq_len, seq_len)
if dropout is not None:
att_scores = dropout(att_scores)
# (bs, head, seq_len, seq_len) * (bs, head, seq_len, dk) = (bs, head, seq_len, dk)
return torch.matmul(att_scores, v), att_scores
if __name__ == '__main__':
# (bs, head, seq_len, dk)
q = torch.randn((8, 12, 10, 32))
k = torch.randn((8, 12, 10, 32))
v = torch.randn((8, 12, 10, 32))
res, att_scores = attention(q, k, v, mask=None, dropout=None, use_RoPE=True)
# (bs, head, seq_len, dk), (bs, head, seq_len, seq_len)
print(res.shape, att_scores.shape)
参考
1:https://zhuanlan.zhihu.com/p/641274061
2:十分钟读懂旋转编码(RoPE)-腾讯云开发者社区-腾讯云
3:LLM学习记录(五)--超简单的RoPE理解方式 - 知乎
4:一文通透位置编码:从标准位置编码、旋转位置编码RoPE到ALiBi、LLaMA 2 Long_alibi位置编码-CSDN博客