Python+OpenCV+OpenPose实现人体姿态估计(人体关键点检测)
目录
1、人体姿态估计简介
2、人体姿态估计数据集
3、OpenPose库
4、实现原理
5、实现神经网络
6、实现代码
1、人体姿态估计简介
人体姿态估计(Human Posture Estimation),是通过将图片中已检测到的人体关键点正确的联系起来,从而估计人体姿态。
人体关键点通常对应人体上有一定自由度的关节,比如颈、肩、肘、腕、腰、膝、踝等,如下图。
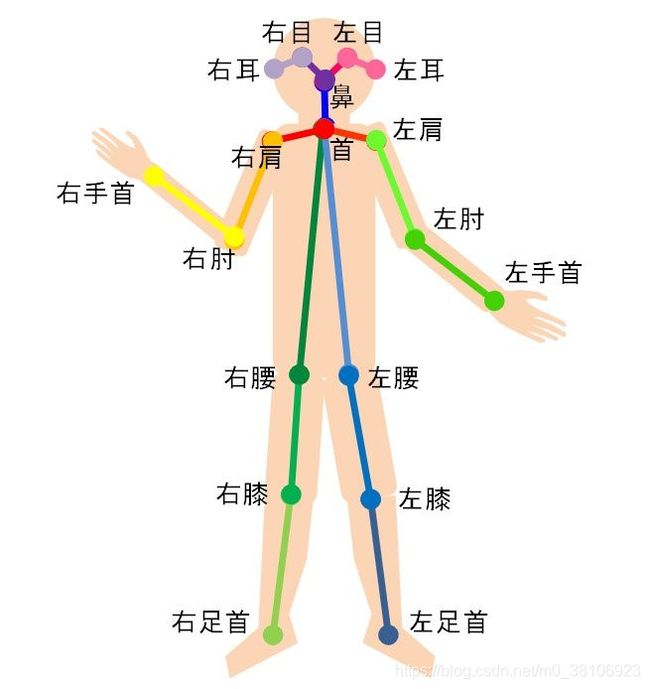

通过对人体关键点在三维空间相对位置的计算,来估计人体当前的姿态。
进一步,增加时间序列,看一段时间范围内人体关键点的位置变化,可以更加准确的检测姿态,估计目标未来时刻姿态,以及做更抽象的人体行为分析,例如判断一个人是否在打电话等。

人体姿态检测的挑战:
- 每张图片中包含的人的数量是未知的。
- 人与人之间的相互作用是非常复杂的,比如接触、遮挡等,这使得联合各个肢体,即确定一个人有哪些部分变得困难。
- 图像中人越多,计算复杂度越大(计算量与人的数量正相关),这使得实时检测变得困难。
2、人体姿态估计数据集
由于缺乏高质量的数据集,在人体姿势估计方面进展缓慢。在近几年中,一些具有挑战性的数据集已经发布,这使得研究人员进行研发工作。人体姿态估计常用数据集:
- COCO Keypoints challenge
- MPII Human Pose Dataset
- VGG Pose Dataset
- CMU Panoptic Dataset(本案例所用数据集)
3、OpenPose库

OpenPose人体姿态识别项目是美国卡耐基梅隆大学(CMU)基于卷积神经网络和监督学习并以Caffe为框架开发的开源库。可以实现人体动作、面部表情、手指运动等姿态估计。适用于单人和多人,具有极好的鲁棒性。是世界上首个基于深度学习的实时多人二维姿态估计应用,基于它的实例如雨后春笋般涌现。
其理论基础来自Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields ,是CVPR 2017的一篇论文,作者是来自CMU感知计算实验室的曹哲(http://people.eecs.berkeley.edu/\~zhecao/#top),Tomas Simon,Shih-En Wei,Yaser Sheikh 。
人体姿态估计技术在体育健身、动作采集、3D试衣、舆情监测等领域具有广阔的应用前景,人们更加熟悉的应用就是抖音尬舞机。
OpenPose项目Github链接:https://github.com/CMU-Perceptual-Computing-Lab/openpose
4、实现原理
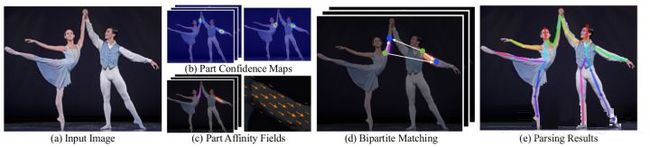
- 输入一幅图像,经过卷积网络提取特征,得到一组特征图,然后分成两个岔路,分别使用 CNN网络提取Part Confidence Maps 和 Part Affinity Fields;
- 得到这两个信息后,我们使用图论中的 Bipartite Matching(偶匹配) 求出Part Association,将同一个人的关节点连接起来,由于PAF自身的矢量性,使得生成的偶匹配很正确,最终合并为一个人的整体骨架;
- 最后基于PAFs求Multi-Person Parsing—>把Multi-person parsing问题转换成graphs问题—>Hungarian Algorithm(匈牙利算法)
(匈牙利算法是部图匹配最常见的算法,该算法的核心就是寻找增广路径,它是一种用增广路径求二分图最大匹配的算法。)
5、实现神经网络
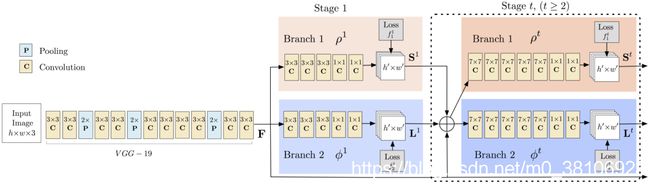
阶段一:VGGNet的前10层用于为输入图像创建特征映射。
阶段二:使用2分支多阶段CNN,其中第一分支预测身体部位位置(例如肘部,膝部等)的一组2D置信度图(S)。 如下图所示,给出关键点的置信度图和亲和力图 - 左肩。

第二分支预测一组部分亲和度的2D矢量场(L),其编码部分之间的关联度。 如下图所示,显示颈部和左肩之间的部分亲和力。

阶段三: 通过贪心推理解析置信度和亲和力图,对图像中的所有人生成2D关键点。
6、实现代码
```python import cv2 as cv import numpy as np import argparse
parser = argparse.ArgumentParser() parser.addargument('--input', help='Path to image or video. Skip to capture frames from camera') parser.addargument('--thr', default=0.2, type=float, help='Threshold value for pose parts heat map') parser.addargument('--width', default=368, type=int, help='Resize input to specific width.') parser.addargument('--height', default=368, type=int, help='Resize input to specific height.')
args = parser.parse_args()
BODY_PARTS = { "Nose": 0, "Neck": 1, "RShoulder": 2, "RElbow": 3, "RWrist": 4, "LShoulder": 5, "LElbow": 6, "LWrist": 7, "RHip": 8, "RKnee": 9, "RAnkle": 10, "LHip": 11, "LKnee": 12, "LAnkle": 13, "REye": 14, "LEye": 15, "REar": 16, "LEar": 17, "Background": 18 }
POSE_PAIRS = [ ["Neck", "RShoulder"], ["Neck", "LShoulder"], ["RShoulder", "RElbow"], ["RElbow", "RWrist"], ["LShoulder", "LElbow"], ["LElbow", "LWrist"], ["Neck", "RHip"], ["RHip", "RKnee"], ["RKnee", "RAnkle"], ["Neck", "LHip"], ["LHip", "LKnee"], ["LKnee", "LAnkle"], ["Neck", "Nose"], ["Nose", "REye"], ["REye", "REar"], ["Nose", "LEye"], ["LEye", "LEar"] ]
inWidth = args.width inHeight = args.height
net = cv.dnn.readNetFromTensorflow("graph_opt.pb")
cap = cv.VideoCapture(args.input if args.input else 0)
while cv.waitKey(1) < 0: hasFrame, frame = cap.read() if not hasFrame: cv.waitKey() break
frameWidth = frame.shape[1]
frameHeight = frame.shape[0]
net.setInput(cv.dnn.blobFromImage(frame, 1.0, (inWidth, inHeight), (127.5, 127.5, 127.5), swapRB=True, crop=False))
out = net.forward()
out = out[:, :19, :, :] # MobileNet output [1, 57, -1, -1], we only need the first 19 elements
assert(len(BODY_PARTS) == out.shape[1])
points = []
for i in range(len(BODY_PARTS)):
# Slice heatmap of corresponging body's part.
heatMap = out[0, i, :, :]
# Originally, we try to find all the local maximums. To simplify a sample
# we just find a global one. However only a single pose at the same time
# could be detected this way.
_, conf, _, point = cv.minMaxLoc(heatMap)
x = (frameWidth * point[0]) / out.shape[3]
y = (frameHeight * point[1]) / out.shape[2]
# Add a point if it's confidence is higher than threshold.
points.append((int(x), int(y)) if conf > args.thr else None)
for pair in POSE_PAIRS:
partFrom = pair[0]
partTo = pair[1]
assert(partFrom in BODY_PARTS)
assert(partTo in BODY_PARTS)
idFrom = BODY_PARTS[partFrom]
idTo = BODY_PARTS[partTo]
if points[idFrom] and points[idTo]:
cv.line(frame, points[idFrom], points[idTo], (0, 255, 0), 3)
cv.ellipse(frame, points[idFrom], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
cv.ellipse(frame, points[idTo], (3, 3), 0, 0, 360, (0, 0, 255), cv.FILLED)
t, _ = net.getPerfProfile()
freq = cv.getTickFrequency() / 1000
cv.putText(frame, '%.2fms' % (t / freq), (10, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 0))
cv.imshow('OpenPose using OpenCV', frame)```
本项目实现代码及模型参见网址:https://download.csdn.net/download/m0_38106923/11265524
关注公众号,发送关键字:关键点检测,获取资源。