每日SQL一练#20231030
每日SQL一练#20231030
qaq终于在凌晨刷完leetcode高频SQL50题。有道题做了两天,太难受了。

这里说下我觉得比较难的一道题。 题目链接:1164. 指定日期的产品价格
题干信息
产品数据表: Products
sql复制代码+---------------+---------+
| Column Name | Type |
+---------------+---------+
| product_id | int |
| new_price | int |
| change_date | date |
+---------------+---------+
(product_id, change_date) 是此表的主键(具有唯一值的列组合)。
这张表的每一行分别记录了 某产品 在某个日期 更改后 的新价格。
编写一个解决方案,找出在2019-08-16这一天全部产品的价格,假设所有产品在修改前的价格都是 10 。
以 任意顺序 返回结果表。 结果格式如下例所示。
示例 1:
diff复制代码输入:
Products 表:
+------------+-----------+-------------+
| product_id | new_price | change_date |
+------------+-----------+-------------+
| 1 | 20 | 2019-08-14 |
| 2 | 50 | 2019-08-14 |
| 1 | 30 | 2019-08-15 |
| 1 | 35 | 2019-08-16 |
| 2 | 65 | 2019-08-17 |
| 3 | 20 | 2019-08-18 |
+------------+-----------+-------------+
输出:
+------------+-------+
| product_id | price |
+------------+-------+
| 2 | 50 |
| 1 | 35 |
| 3 | 10 |
+------------+-------+
题干解析
在16号这一天的价格计算的逻辑不难,难点在于如何求得两个跟8月16日最近的日期。
错误思路
一开始我想的是,通过日期计算,减去2019-08-16这天的日期,然后根据日期差的绝对值按照产品ID分组升序排序,最终每款产品前面两行的值即是离16日最近的日期。
mysql复制代码select
product_id,
new_price,
change_date, daydiff,
row_number() over(partition by product_id order by abs(daydiff) asc) as rn
from (select
product_id,
new_price,
change_date,
datediff(change_date, "2019-08-16") as daydiff
from Products) as t
这个想法在上面示例数据是可行的。 但是如果每款产品存在多行与8月16日日期相近的数据的话,上述SQL就会取得错误的日期。而且这样没有办法判断rn=1还是rn=2的日期较大(对于16日而言)。
因为下面的数据与实例的数据不同,所以粘贴一下下面的代码测试数据
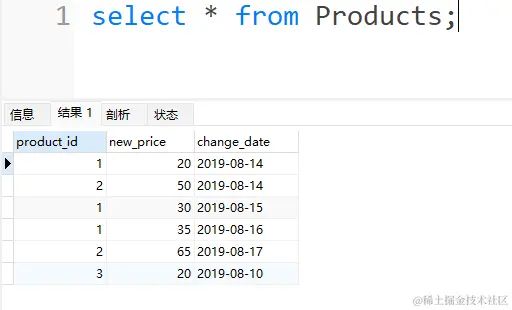
那么这里换一种思路,需要求解大于16日的日期中最小的日期,以及小于16日的日期中最大的日期,这两个日期,方便后续进行价格的计算。 同样,也是与16日的日期进行相减计算日期差,但是这里分开来计算,即大于16日的日期跟小于16日的日期分开两个SQL进行求解
mysql复制代码-- 计算出大于2019-08-16的最小的日期
select
product_id,
new_price,
change_date,
datediff(change_date, "2019-08-16") as daydiff,
row_number() over(partition by product_id order by datediff(change_date, "2019-08-16") asc) as rn
from Products
where datediff(change_date, "2019-08-16")>=0
;
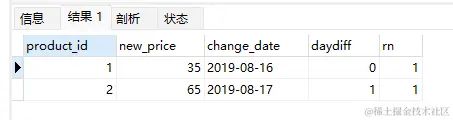
因为这里过滤掉了小于16日的日期,且数据量较少,所以看到的数据只有2行
mysql复制代码-- 计算出小于2019-08-16的最大的日期
select
product_id,
new_price,
change_date,
datediff("2019-08-16", change_date) as daydiff,
row_number() over(partition by product_id order by datediff("2019-08-16", change_date) asc) as rn
from Products
where datediff("2019-08-16", change_date)>=0
;

因为我两个SQL都用了大于等于,所以如果存在16日的数据,这两个SQL都会查询出来,这个对后面的判断更加简单。 还有一点就是,id为3的产品因为只有小于16日的数据,所以只有在第二个SQL才查询出来,也就是说存在部分产品只有16日前后修改过一次价格,在后面的SQL中需要用full outer join,但是很不巧,MySQL是没有这个full outer join的,但是可以用left outer join union right outer join来实现。(注意这里必须要用union进行去重)
关于16日的价格,这里给出几种判断逻辑:
- 16日当天修改过价格
- 只有一行数据,日期小于16号,则取最新日期
- 只有一行数据,日期大于16号,则取变价前的值
- 两个日期都大于16号,则取变价前的值
- 日期一大一小,则取小的值
- 最大的日期都小于16日,则取最新的变价
- 最小的也大于16日,则取变价前的值
解题
先求解16日前后最近的日期
mysql复制代码-- 计算出大于2019-08-16的最小的日期
with tmp as (select
product_id,
new_price,
change_date,
datediff(change_date, "2019-08-16") as daydiff,
row_number() over(partition by product_id order by datediff(change_date, "2019-08-16") asc) as rn
from Products
where datediff(change_date, "2019-08-16")>=0),
tmp2 as (
-- 计算出小于2019-08-16的最大的日期
select
product_id,
new_price,
change_date,
datediff("2019-08-16", change_date) as daydiff,
row_number() over(partition by product_id order by datediff("2019-08-16", change_date) asc) as rn
from Products
where datediff("2019-08-16", change_date)>=0)
;
然后将上述两个临时表做full outer join
mysql复制代码-- 计算出大于2019-08-16的最小的日期
with tmp as (select
product_id,
new_price,
change_date,
datediff(change_date, "2019-08-16") as daydiff,
row_number() over(partition by product_id order by datediff(change_date, "2019-08-16") asc) as rn
from Products
where datediff(change_date, "2019-08-16")>=0),
tmp2 as (
-- 计算出小于2019-08-16的最大的日期
select
product_id,
new_price,
change_date,
datediff("2019-08-16", change_date) as daydiff,
row_number() over(partition by product_id order by datediff("2019-08-16", change_date) asc) as rn
from Products
where datediff("2019-08-16", change_date)>=0)
select
ta.product_id,
ta.price1,
tb.price2,
ta.date1,
tb.date2
from
(select product_id, new_price as price1, change_date as date1 from tmp where rn=1) as ta
left outer join
(select product_id, new_price as price2, change_date as date2 from tmp2 where rn=1) as tb
on ta.product_id=tb.product_id
union
select
tb.product_id,
ta.price1,
tb.price2,
ta.date1,
tb.date2
from
(select product_id, new_price as price1, change_date as date1 from tmp where rn=1) as ta
right outer join
(select product_id, new_price as price2, change_date as date2 from tmp2 where rn=1) as tb
on ta.product_id=tb.product_id
;
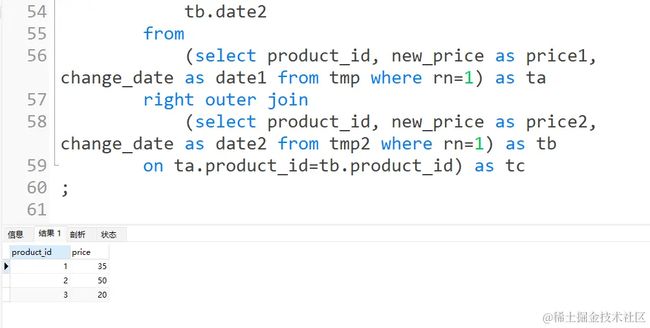
结果如下图所示:

然后对上述表进行求解即可:
mysql复制代码-- 计算出大于2019-08-16的最小的日期
with tmp as (select
product_id,
new_price,
change_date,
datediff(change_date, "2019-08-16") as daydiff,
row_number() over(partition by product_id order by datediff(change_date, "2019-08-16") asc) as rn
from Products
where datediff(change_date, "2019-08-16")>=0),
tmp2 as (
-- 计算出小于2019-08-16的最大的日期
select
product_id,
new_price,
change_date,
datediff("2019-08-16", change_date) as daydiff,
row_number() over(partition by product_id order by datediff("2019-08-16", change_date) asc) as rn
from Products
where datediff("2019-08-16", change_date)>=0)
select
product_id,
case
when date1='2019-08-16' then price1 -- 等于16号
when date2='2019-08-16' then price2
when date2 is null and date1<'2019-08-16' then price1 -- 只有一行数据,日期小于16号,则取最新日期
when date2 is null and date1>'2019-08-16' then 10 -- 只有一行数据,日期大于16号,则取变价前的值
when date1>date2 and date2>'2019-08-16' then 10 -- 两个日期都大于16号,则取变价前的值
when date1>date2 and date1>'2019-08-16' and date2<'2019-08-16' then price2 -- 一大一小,则取小的值
when date1<'2019-08-16' and date2<'2019-08-16' then price1 -- 最大的日期都小于16日,则取最新的变价
when date2>'2019-08-16' then 10 -- 最小的也大于16日,则取变价前的值
when date1 is null and date2<'2019-08-16' then price2
else null
end as price
from
(select
ta.product_id,
ta.price1,
tb.price2,
ta.date1,
tb.date2
from
(select product_id, new_price as price1, change_date as date1 from tmp where rn=1) as ta
left outer join
(select product_id, new_price as price2, change_date as date2 from tmp2 where rn=1) as tb
on ta.product_id=tb.product_id
union
select
tb.product_id,
ta.price1,
tb.price2,
ta.date1,
tb.date2
from
(select product_id, new_price as price1, change_date as date1 from tmp where rn=1) as ta
right outer join
(select product_id, new_price as price2, change_date as date2 from tmp2 where rn=1) as tb
on ta.product_id=tb.product_id) as tc
;
这里采用的是case进行处理。 那么如果是用if进行判断呢?(这里不建议用) 首先if语句没有办法将所有情况写到一列中,每种判断逻辑需要单独一列,后续在用ifnull将结果合并为一列,过程繁琐,而且可读性差,修改逻辑的话代码可维护性差!!! 这里粘贴下错误的示例:

这段代码在数据量少的情况下是可以执行成功的,如上述的测试数据
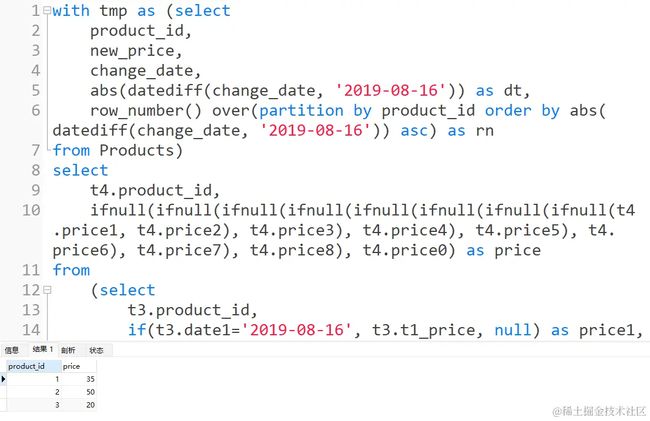
这里查看下中间状态的数据,即最终结果前的状态


因为这个数据量太少了,对于判断逻辑来说,所以会存在大量的空列。 同时也说明了case对于if的优越性!!!所以能用case的情况下尽量用case,会使代码整体的可读性以及观赏性上一个档次的。哈哈
作者:saberbin
链接:https://juejin.cn/post/7294965012749025306
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。