消费者传递保证语义
Kafka服务器端并不会记录消费者的消费位置,而是由消费者自己决定如何保存其消费的offset. 0.8.2版本之前消费者会将其消费位置记录zookeeper中,在后面的新版本中,消费者为了缓解zookeeper集群的压力,在Kafka服务器端添加了一个名字是__consusmer_offsets的内部topic,简称为offset topic,他可以用来保存消费者提交的offset,当出现消费者上线或者下线时会触发消费者组的rebalance操作,对partitions重新进行分配,等待rebalance完成之后,消费者就可以读取offset topic中的记录的offset,并从此offset开始继续消费。你也可以根据业务需求将offset存储在别的存储介质中,比如数据库等
在消费者消费消息的过程中,提交offset的时间显得十分重要 ,因为它决定了消费者故障重启后的消费位置。如果我们设置自动提交,需要将enable.auto.commit = true, auto.commit.interval.ms则设置了自动提交的时间间隔,这是最简单的提交offset的方式。每次在poll的时候都会检测是否需要自动提交,并提交上次poll方法返回的最后一个消息的offset,为了避免消息丢失,建议poll方法之前要处理完上次poll方法拉取的全部消息。KafkaConsumer还提供了2个手动提交offset的方法分别是:commitSync()和commitAsync(),他们都可以指定提交的offset的值,前者是同步提交。后者是异步提交
(Delivery Guarantee Semantic)传递保证语义有三个级别:
# At most once: 最多一次,消息可能会丢失,但不会重复传递
# At least once: 至少一次,消息绝不会丢,但是可能会重复船赌
# Exactly once: 每一条消息只会被传递一次
对于生产者而言:当生产者向Kafka发送消息,正常得到响应,可以确认生产者不会重复发送消息,但是发送消息之后,如果遇到网络问题,没有得到响应生产者就无法判断该消息是否成功提交到Kafka,这时候生产者就会重新发送,所以就有可能出现消息重复传递,出现At
least once的情况,为了实现exactly once语义,这里提供2个可选的方案:
方案一:每一个分区只有一个生产者写入消息,当出现异常或者超时的时候,生产者就要查询这个分区最后一个消息用来决定是重新传递还是继续发送
方案二:为每一个消息添加一个唯一的主键,生产者不对消息做处理,这部分处理交给消费者来做,消费者对消息进行去重
优先选择第二种,如果业务方面内提供合适字段作为主键或者是有一个全局的id生成器
对于消费者而言:消费者处理消息与提交offset的顺序,在很大程度上决定了消费者是哪一个语义:
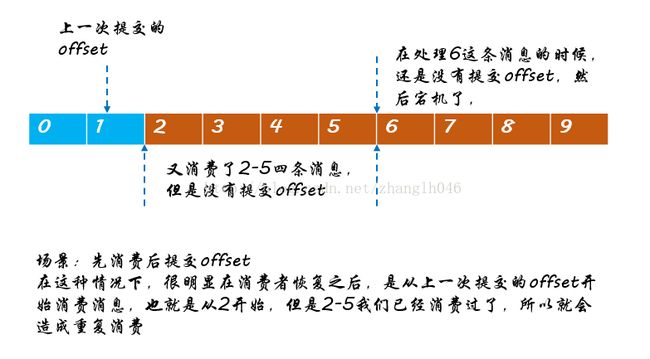
场景一:先消费消息,再提交offset(at leastonce语义)
也就是可能会发生重复消费的情况
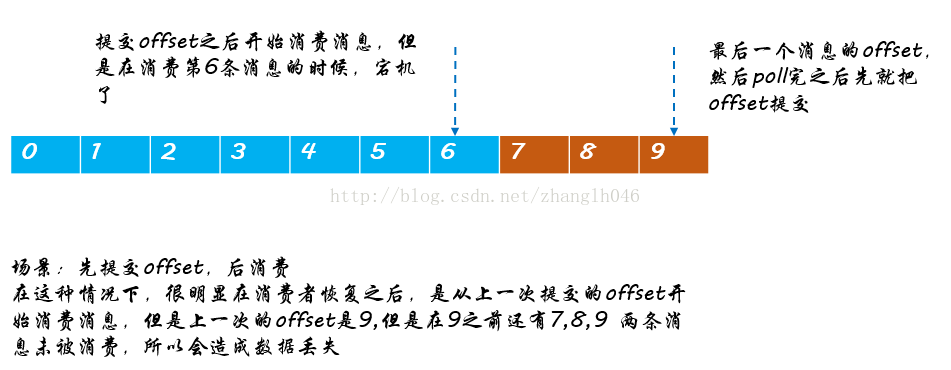
场景二:先提交offset,在消费消息(at most once)
会丢失数据的情况
为了实现exactly once语义,提供一种方案:消费者关闭自动提交offset的功能且不再手动提交offset,这样就不使用offset topic这个内部topic记录offset,而是由消费者自己保存offset. 在这里可以用事务的原子性来实现exactly once. 我么将offset和消息处理结果放在一个事务中,事务执行成功则认为此消息被消费,否则事务回滚需要重新消费。当出现宕机重启或者rebalance的时候消费者可以关系型数据库中找到对应的offset,然后调用KafkaConsumer.seek()方法手动设置消费位置,消费者从这个offset开始继续消费
消费者并不知道Consumer Group什么时候会发生rebalance操作,哪一个分区分配给哪一个消费者消费。我们可以通过向KafkaConsumer添加ConsumerRebanlanceListener接口来解决这个问题:
# onPartitionsRevoked: 消费者停止拉取数据之后,rebalance之前发生,我们可以在此方法中实现手动提交offset,这就避免了rebalance到指定重复消费问题
Rebalance之前,可能是消费者A消费者在消费partition-01,Rebalance之后,可能就是消费者B消费者在消费partition-01,如果rebalance之前没有提交offset,那么消费者就有可能从上一次提交offset的位置开始消费
# onPartitionsAssigned: 在rebalance之后,消费者拉取数据之前调用,我们可以在此方法中调整或者定义offset的值