[多智能体强化学习] 王树森YouTube课程笔记
前言
近期在设计V2X资源分配任务下的状态空间和动作空间,可以说是一筹莫展,是自己菜,现在看来可能也是涉及到一些关于 多智能体强化学习 实现过程中过于细节的点,目前的知识储备还不够。因此打算用半周到一周的时间重电,希望之后能有进展。
本文内容来自于友人LX所推荐的油管教程,链接如下:多智能体强化学习,一共两节课40min左右。教程废话不多干货不少,老师的声音还好听,推荐直接去看原教程。
这里还要多一嘴,那就是对于强化学习来说,单主体和多主体的界限,在某种程度上来说是很模糊的,并不是场景中有多个主体需要我们来为其决定动作,就一定是多智能体强化学习,这里暂时不用深究,等你的研究举到具体问题再来思考即可。
如果你对上面这段话感兴趣,可以查看我的这篇博文,其在车联网场景中讨论了使用 sarl(Single Agent Reinforcement Learning) 和 marl(Multi-Agent Reinforcement Learning) 的可行性
本文为一个新入坑RL学生的粗浅见解,若有错误及表述不清楚的地方还烦请不吝赐教
下面是我目前遇到的问题整理,不感兴趣的读者请直接跳过查看正文
- 状态和奖励的构建时遇到的困难其实和我的使用场景,亦或者说模型相关,因为我现在的应用场景并非一个典型的RL问题,所说的非典型表现如下:
- 1.场景中存在多个主体(即多辆车,多到啥程度呢?400+)。这里的处理方法是使每个agent轮流观察环境,当一个agent观察环境后立即做出action,并将此aciton作用于环境。
- 2.目前的指标设计是一个全局的指标,他的计算需要基于全部agent的action,这就导致一个后果是,连续两次用来计算reward的action_set(包含全部agent的action),其实只有单个agent的action有变化,因此也导致reward应该不会发生太大变化。所以这个是用sarl解决多agent场景的正常现象还是需要重新设计reward?
- 3.本场景中,虽然动作空间一致,但是对于每辆车来说,仅在选择部分动作时有意义,这里的意义可以大致理解为:“围棋中,虽然棋子放置的位置是整个棋盘,但是实际每一步的时候都是不能落在已经落子的位置”,对于没有意义的动作我们称之为非法动作,对于这个非法动作,是要在执行动作时考虑,还是在计算reward的时候通过设置惩罚来体现?
- 若在执行动作时考虑,因为合法动作可通过观察得到,所以直接将这些合法的动作作为状态传到agent?
- 若在计算reward时考虑reward = lambda *A - (1-lambda) *B,A是一个0.002-0.004的数值,由信息速率等物理量计算而来,但B就完全没有啥依照了,你设成1w也行,0.及也行,到底该如何设置?我目前设置B=A(现在看来这个有点蠢,因为这样的话岂不是有惩罚近0无惩罚近1了?)
目录
基本概念 Multi-Agent Reinforcement Learning
常见场景设定
1.Fully cooperative
2.Fully competitive
3.Mixed Cooperative & competitive
4.Self-interested (利己主义)
专业术语(需要与单agent的强化学习区分)
【状态,动作,状态转移】
【奖励】
【回报】
【策略网络】
【回报的随机性的来源】
【状态价值函数】
收敛
【single-Agent 下的收敛】
【Multi-Agent 下的收敛】
使用SARL的困境
解法
Fully decentralized 去中心化
Fully centralized 完全中心化
Centralized training with decentralized execution 中心化训练 去中心化执行
推荐阅读
基本概念 Multi-Agent Reinforcement Learning
常见场景设定
1.Fully cooperative
特点:多个agent利益一致,有共同的目标,比如共同拼装一辆车的多个机器手臂
![[多智能体强化学习] 王树森YouTube课程笔记_第1张图片](http://img.e-com-net.com/image/info8/14cd66d52e20426eb84647b5f12ae816.jpg)
2.Fully competitive
特点:多个agent之间,一方收益是另一方的损失,比如比赛场上的两个机器人,零和博弈一般是这种。
![[多智能体强化学习] 王树森YouTube课程笔记_第2张图片](http://img.e-com-net.com/image/info8/3e3de85e24d94ebd901408dd6cd3250a.jpg)
3.Mixed Cooperative & competitive
特点:多个agent 分成多个集团,集团内部是合作,集团之间是竞争。比如机器人足球赛
![[多智能体强化学习] 王树森YouTube课程笔记_第3张图片](http://img.e-com-net.com/image/info8/528a0c8c990d405485f38891a38c1f6b.jpg)
4.Self-interested (利己主义)
特点:环境中有多个agent,一个agent的动作会改变环境的状态,此动作可能让其他agent受益或受损,但是它不在乎,他只在乎自身的利益最大化。比如股票的自动交易系统:股市有很多自动交易系统,他们的决策仅依据自身利益最大,但他们的决策结果在客观上会影响股价,进而导致其他自动交易系统受益或受损。无人车的动作操控也属于此类!(这里虽然重点在操控上,但是V2X的资源分配也有异曲同工之妙)
专业术语(需要与单agent的强化学习区分)
【状态,动作,状态转移】
![[多智能体强化学习] 王树森YouTube课程笔记_第4张图片](http://img.e-com-net.com/image/info8/dad821c29b874a0eb1d3057adce75e40.jpg)
这里需要注意的是上表表示环境中的agent的编号,状态转移时,与单主体下一个状态依赖当前状态和单个agent的动作不同,此时下一个状态依赖于全部agent的动作:![]()
【奖励】
![[多智能体强化学习] 王树森YouTube课程笔记_第5张图片](http://img.e-com-net.com/image/info8/4762663933ac4abab58833412c46dbaa.jpg)
类似地,上标表示agent的编号(要注意上标为2的时候不是平方啊233),另外需要注意他这里一直有一个隐含设定就是 「奖励」的数目 = agent的数目,所以在完全合作的场景下,即便所有agent目标一致,它还是设定了每个agent都有一个 Reward ,只不过这些Reward的数值相同罢了。
从最后一行可以看出,奖励也取决于所有agent的动作。
对于多主体强化学习中,状态转移和奖励都并非依赖单个action而是所有agent的action这点,一般会认为是随着agent数量增多之后一个理所当然的举动,这里提供这样一个视角:我们的 RL Machine(这里具体来讲是RL的策略网络)也可能以单个agent的状态为输入,该agent的动作为输出,通过遍历所有agent的方法来应对多agent的场景。
在这种情况下,状态转移和奖励如果仅包含当前agent的action貌似也符合直觉,不知道后文会不会提到上述情况。
【回报】
![[多智能体强化学习] 王树森YouTube课程笔记_第6张图片](http://img.e-com-net.com/image/info8/5c9547293e6a45c8a81a81c918da9857.jpg)
是奖励的加权和
【策略网络】
![[多智能体强化学习] 王树森YouTube课程笔记_第7张图片](http://img.e-com-net.com/image/info8/16f97e8fc0a547ddab01868a04face44.jpg)
需要注意的是,这里的状态 s,是针对环境来说的,因此只有一个。因为 s 通常是面向 agent 的,所以不要看到这里的s没有上标就想当然的以为这个是单个 agent 的状态了,因为表征环境,所以这里的 s 更贴近于全部 agent 的状态集合。
还有就是这里考虑的共用policy的方式,也不是多个agent使用一个policy,而是多个policy的参数在数值上相等。(虽然实现中的处理方法可能是用一个变量表征,但是这里的思维模型个人感觉有必要提一下)
【回报的随机性的来源】
![[多智能体强化学习] 王树森YouTube课程笔记_第8张图片](http://img.e-com-net.com/image/info8/29dc8527da81498d92d7c639da455bb3.jpg)
这里类似一个层级结构:
U 依赖于 R
R 依赖于 S、A
而S和A的随机性分别来自于状态转移是个概率、policy network的输出也是个概率(即并非直接输出到底选择哪个action)。
【状态价值函数】
![[多智能体强化学习] 王树森YouTube课程笔记_第9张图片](http://img.e-com-net.com/image/info8/2856abc0631a452e98d81d2cf082ef2f.jpg)
需要注意的是第 i 个 agent 的状态价值是关于所有 agent 的 policy 参数 ![]() ,而非他自己的 policy参数
,而非他自己的 policy参数 ![]() 。这是符合直觉的,因为回报U与奖励R有关,奖励R与所有agent的动作有关,而 agent 的动作又与其各自的 policy 参数有关。
。这是符合直觉的,因为回报U与奖励R有关,奖励R与所有agent的动作有关,而 agent 的动作又与其各自的 policy 参数有关。
然后看右值,只依赖于状态s_t。
【这里提到了multi-agent的一个难点:仅优化自己的policy不一定会让V变大】
收敛
给出了一个对于收敛的定义性描述:
无法通过改进策略来获得更大的期望回报。
【single-Agent 下的收敛】
![[多智能体强化学习] 王树森YouTube课程笔记_第10张图片](http://img.e-com-net.com/image/info8/f9e3fb32e8e642dda6fc41217acaf147.jpg)
收敛:改变参数 但状态价值函数的期望J不再增加
但状态价值函数的期望J不再增加
【Multi-Agent 下的收敛】
![[多智能体强化学习] 王树森YouTube课程笔记_第11张图片](http://img.e-com-net.com/image/info8/abbfcd59e88e477ba6c9f92e32abbb47.jpg)
其余所有agent策略不变的前提下,单独改变一个agent的策略,不会获得更大的期望。
使用SARL的困境
![[多智能体强化学习] 王树森YouTube课程笔记_第12张图片](http://img.e-com-net.com/image/info8/0c1c6f61ee0645fdbe9f059508f214a3.jpg)
设定:每个车有自己的policy(车i 的 policy 用 表征),多个agent独立与环境交互
表征),多个agent独立与环境交互
这里提到了 独立 :因此我认为不存在agent生成action后暂时不作用于env,而是要等全部agent都生成action后一齐作用于env的情况。
![[多智能体强化学习] 王树森YouTube课程笔记_第13张图片](http://img.e-com-net.com/image/info8/dd08d465556345bbafbbac2deac3db7d.jpg)
以上计算需要对每一个agent都算一次,如下:
![[多智能体强化学习] 王树森YouTube课程笔记_第14张图片](http://img.e-com-net.com/image/info8/67f372ca56d04d46addb9a0b69beeb42.jpg)
结论是如果按照这种计算方法那么可能此算法永远不能收敛,
因为我们对于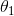 (式1)进行优化时,
(式1)进行优化时,![]() 都可能在不停的变化,目标函数一直在变,那要怎么找到最佳的呢?【这里认为变化是在对J进行遍历的时候进行的,每一轮对J的优化都能达成,但是下一轮开始的时候,又要重新优化一个新的J函数,所以说J的优化可达成,但是迭代永不收敛】
都可能在不停的变化,目标函数一直在变,那要怎么找到最佳的呢?【这里认为变化是在对J进行遍历的时候进行的,每一轮对J的优化都能达成,但是下一轮开始的时候,又要重新优化一个新的J函数,所以说J的优化可达成,但是迭代永不收敛】
解法
不完全观测 Partial Observations
对于客观的状态 s ,每辆车不可能掌握关于其全部信息,对于 i 号 agent 能获得的部分关于环境的信息(观测值)我们记作

这里的
表示,可以稍微注意一下
Fully decentralized 去中心化
含义:每个agent独立和环境交互(这里猜测是轮流交互的,即按照以下流程:agent1观察并获得动作action1 - action1作用于环境 - agent2观察并获得动作action2 - action2作用于环境 - ... 以此类推)
agent之间彼此不知道互相的动作,并且各自有各自的policy
![[多智能体强化学习] 王树森YouTube课程笔记_第15张图片](http://img.e-com-net.com/image/info8/86b4c4986ab248789dcb550a83079668.jpg)
现在有个问题就是,他这里每个agent的观测值 o ,不知道他 o1 o2 是否是对同一个时点的Env的观测
如果是的话,就说明获得动作值a后没有立即作用于Env,而是将所有agent的action收集起来之后一同作用于Env,在这个期间Env实际是静止的,o1 o2 的区别在于不同agent观测能力的不同;- 如果不是的话,说明获得动作值后立即作用于Env,这时候 o1 o2 的区别不光在于不同agent的观测能力不同,他们的观测对象,也就是那个Env,客观上也存在不同,因为agent观察的Env还没有接受action1的影响,而agent2观察的Env已经接受过action1地影响了。
这种方法的缺点在于:认为agent之间完全独立,忽视了agent相互之间的影响,这是不合理的。
Fully centralized 完全中心化
含义:agent将自己的观测值、奖励值 发送给中央控制器,中央控制器根据所有agent的观测值来一次性获得所有agent的动作。
![[多智能体强化学习] 王树森YouTube课程笔记_第16张图片](http://img.e-com-net.com/image/info8/1d926c6991e04fd2b69c7e3e0e4d7e54.jpg)
这里中央控制器上有n个策略网络和n个价值网络,策略网络的结构相同但参数不同,如下是agenti获取action的过程:
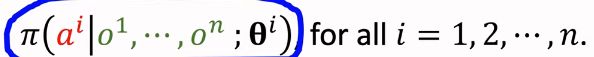
缺点:因为要收集完所有agent的信息后才能决策,因此整体速度要根据最慢的成员来决定,算法速度慢是其缺点。视频提到,此算法一般无法做到实时决策。
Centralized training with decentralized execution 中心化训练 去中心化执行
含义:agent有各自的policy,中央控制器会收集agent的state action reward,中央控制器帮助agent训练policy,训练结束后撤掉中央控制器,用自己的policy做决策。
这种方法和 上一种(Fully centralized )的区别在于,使用Actor-Critic算法的时候,他的policy network在agent上,而value network在中央控制器上(value network的输入是所有的o和所有的a)![[多智能体强化学习] 王树森YouTube课程笔记_第17张图片](http://img.e-com-net.com/image/info8/9c689b6ca9434b56b696fb3fd74683c7.jpg)
![[多智能体强化学习] 王树森YouTube课程笔记_第18张图片](http://img.e-com-net.com/image/info8/f2572e8e04864e7fbe43703f7881e8ad.jpg)
推荐阅读
![[多智能体强化学习] 王树森YouTube课程笔记_第19张图片](http://img.e-com-net.com/image/info8/6af566c15a724a75a8be3d9fedfba8c4.jpg)