Leetcoder Day12|二叉树part01
语言:Java/C++
目录
二叉树理论基础
二叉树种类
满二叉树
完全二叉树
二叉搜索树
平衡二叉搜索树
二叉树的存储方式
二叉树的遍历方式
二叉树的定义
二叉树的递归遍历
二叉树的迭代遍历
二叉树的统一迭代法
今日心得
二叉树理论基础
二叉树种类
在数据结构中对二叉树的考察往往是重点之一,二叉树常分为平衡二叉树、二叉搜索树、完全二叉树、满二叉树等,其中满二叉树和完全二叉树是常见的类型。
先列举二叉树的一些基本性质:
- 在二叉树的第i层上至多有2^(i-1)个结点(i>=1)
- 深度为k的二叉树至多有2^k-1个结点(k>=1)
- 对任何一棵二叉树T,如果其叶子结点数为n0,度为2的结点数为n2,则n0=n2+1
- n总=n0+n1+n2
- 具有n个结点的完全二叉树的深度为[log2^n]+1
满二叉树
如果一棵二叉树只有度为0的结点和度为2的结点,并且度为0的结点在同一层上,则这棵二叉树为满二叉树。

满二叉树特点:
- 深度为k,有2^k-1个节点
- 叶子只能出现在最下一层,出现在其他层就不可能达成平衡
- 非叶子结点的度一定是2
- 在同样深度的二叉树中,满二叉树的结点个数最多,叶子数最多
完全二叉树
若设二叉树的高度为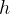 ,除第层外,其他各层的节点数都达到最大个数,第层有叶子节点,并且叶子节点都是从左到右依次排布。(堆为完全二叉树)
,除第层外,其他各层的节点数都达到最大个数,第层有叶子节点,并且叶子节点都是从左到右依次排布。(堆为完全二叉树)

满二叉树一定是一个棵完全二叉树,但完全二叉树不一定是满的。
完全二叉树特点:
- 叶子结点只能出现在最下俩层
- 最下层的叶子一定集中在左部连续位置
- 倒数二层,若有叶子结点,一定都在右部连续位置
- 如果结点度为1,则该结点只有左孩子,即不存在只有右子树的情况(度为分支的数目)
- 同样结点数的二叉树,完全二叉树的深度最小
- 具有n个结点的完全二叉树的深度为[log2^n]+1
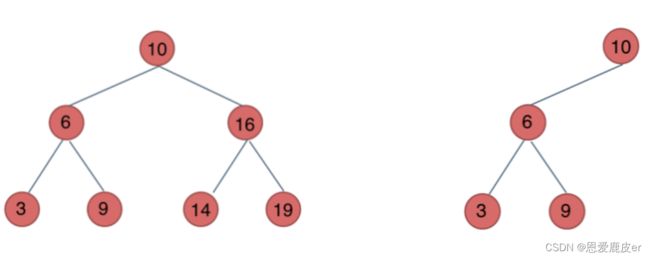
二叉搜索树
二叉搜索树是有数值的,是一个有序树,性质如下:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉排序树
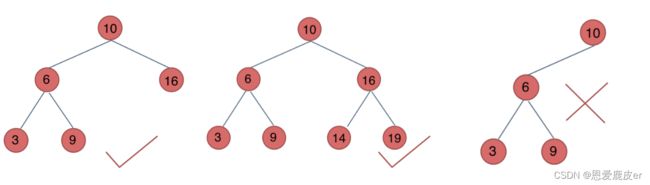
平衡二叉搜索树
又被称为AVL(Adelson-Velsky and Landis)树,且具有以下性质:
- 是一棵空树或它左右两个子树的高度差的绝对值不超过1
- 左右两个子树都是一棵平衡二叉树。
C++中map、set、multimap,multiset的底层实现都是平衡二叉搜索树,所以map、set的增删操作时间时间复杂度是logn。unordered_map、unordered_set,unordered_map、unordered_set底层实现是哈希表。
二叉树的存储方式
二叉树一般用链式存储,也可以顺序存储。链式存储方式就用指针, 顺序存储的方式就是用数组。因此顺序存储元素在内存是连续分布的,而链式存储则是通过指针把分布在各个地址的节点串联一起。
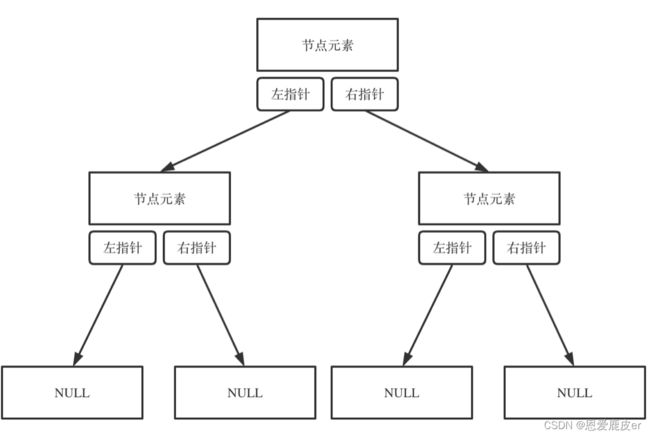
链式存储结构图

顺序存储结构图
数组存储遍历二叉树性质:如果父节点的数组下标是 i,那么它的左孩子就是 i * 2 + 1,右孩子就是 i * 2 + 2。
二叉树的遍历方式
二叉树主要有两种遍历方式:
- 深度优先遍历:先往深走,遇到叶子节点再往回走。(栈)
- 广度优先遍历:一层一层的去遍历。(队列)
这两种遍历是图论中最基本的两种遍历方式
- 深度优先遍历
- 前序遍历(递归法,迭代法)中左右
- 中序遍历(递归法,迭代法)左中右
- 后序遍历(递归法,迭代法)左右中
- 广度优先遍历
- 层次遍历(迭代法)
深度优先遍历常使用递归的方式来实现,昨天在栈和队列时提到栈其实就是递归的一种实现结构,也就说前中后序遍历的逻辑其实都是可以借助栈使用递归的方式来实现的。
广度优先遍历常使用队列来实现,这也是队列先进先出的特点所决定的,因为需要先进先出的结构,才能一层一层的来遍历二叉树。
二叉树的定义
链式存储的二叉树节点的定义方式:
C++ :
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
};Java:
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}二叉树的递归遍历
递归确实也是我每次找不到入口越写越乱的一个部分,其实之前在进行数组和字符串练习时也多次用到递归,简单的几行代码的逻辑还是需要总结一个方法来指引。还是之前提到的,做题要先捋清楚要解决什么问题,完成什么部分,做项目亦是如此。首先需要确定下来递归算法的三个要素:
- 确定递归函数的参数和返回值: 确定哪些参数是递归的过程中需要处理的,那么就在递归函数里加上这个参数, 并且还要明确每次递归的返回值是什么进而确定递归函数的返回类型。
- 确定终止条件: 写完了递归算法, 运行的时候,经常会遇到栈溢出的错误,就是没写终止条件或者终止条件写的不对,操作系统也是用一个栈的结构来保存每一层递归的信息,如果递归没有终止,操作系统的内存栈必然就会溢出。
- 确定单层递归的逻辑: 确定每一层递归需要处理的信息。在这里也就会重复调用自己来实现递归的过程。
前序遍历144
1. 确定递归函数的参数和返回值:因为要打印出前序遍历节点的数值,所以参数里需要传入vector来放节点的数值。还需要给出根节点cur。因为只需要进行节点打印不需要有返回值,所以函数返回类型为void。
void traversal(TreeNode* cur, vector& vec) 2. 确定终止条件:终止条件就是判断什么时候函数执行结束。前序遍历本质还是深度优先搜索,所以当一边没有节点的时候便返回继续进行另一次遍历,因此终止条件就是当前节点为空节点。
if (cur == NULL) return;
3. 确定单层递归的逻辑:前序遍历是中左右的循序,所以在单层递归的逻辑,是要先取中节点的数值并放入数组中。然后取左孩子,再取右孩子。
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右前序遍历 C++:
class Solution {
public:
void traversal(TreeNode* cur, vector& vec) {
if (cur == NULL) return;
vec.push_back(cur->val); // 中
traversal(cur->left, vec); // 左
traversal(cur->right, vec); // 右
}
vector preorderTraversal(TreeNode* root) {
vector result;
traversal(root, result);
return result;
}
}; Java:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public void traversal(TreeNode root, List vec){
if(root == null) return;
vec.add(root.val);
traversal(root.left, vec);
traversal(root.right, vec);
}
public List preorderTraversal(TreeNode root) {
List result = new ArrayList();
traversal(root, result);
return result;
}
} 中序遍历145
中序遍历只需要在递归中顺序变为左中右即可,java代码如下
class Solution {
public void traversal(TreeNode root, List vec){
if(root==null) return;
traversal(root.left, vec);
vec.add(root.val);
traversal(root.right, vec);
}
public List inorderTraversal(TreeNode root) {
List result = new ArrayList ();
traversal(root, result);
return result;
}
} 后序遍历94
后序遍历只需要在递归中顺序变为左中右即可,java代码如下:
class Solution {
public void traversal(TreeNode root, List vec){
if(root==null) return;
traversal(root.left, vec);
traversal(root.right, vec);
vec.add(root.val);
}
public List postorderTraversal(TreeNode root) {
List result= new ArrayList();
traversal(root, result);
return result;
}
} 二叉树的迭代遍历
前序遍历
前序遍历是中左右,每次先处理的是中间节点,那么先将根节点放入栈中,因为栈是FILO特性,所以先将右孩子加入栈,再加入左孩子。这样才符合出栈时的中左右顺序。
class Solution {
public List preorderTraversal(TreeNode root) {
Stack st =new Stack<>();
List result = new ArrayList<>();
if(root == null) return result;
st.push(root);
while(!st.isEmpty()){
TreeNode node=st.peek();
st.pop();
result.add(node.val);
if(node.right!=null) st.push(node.right);
if(node.left!=null) st.push(node.left);
}
return result;
}
} 中序遍历
和递归不同,迭代方法中,想要只调整前序遍历的顺序就写出中序和后序比较困难。前序遍历中因为要访问的元素和要处理的元素顺序是一致的,都是中间节点,所以处理逻辑相对简单。而中序遍历是左中右,先访问的是二叉树顶部的节点,然后一层一层向下访问,直到到达树左面的最底部,再开始处理节点(也就是在把节点的数值放进result数组中),这就造成了处理顺序和访问顺序是不一致的。
因此在使用迭代法写中序遍历,就需要借用指针的遍历来帮助访问节点,栈则用来处理节点上的元素。具体思路是这样的,设置一个指针,如果当前节点不为空,说明还没有访问到左边的最底部,因此将访问过的节点都压入栈中不弹出,直到节点为空,则弹出最左边的节点。然后将当前节点的值存入result中并将指针指向其右孩子。
class Solution {
public List inorderTraversal(TreeNode root) {
List result =new ArrayList<>();
TreeNode cur= root;
Stack st = new Stack<>();
if(root==null) return result;
while(cur!=null || !st.isEmpty()){
if(cur!=null){
st.push(cur);
cur=cur.left;
}
else{
cur=st.peek();
st.pop();
result.add(cur.val);
cur=cur.right;
}
}
return result;
}
} 后序遍历
本来我还是想按照中序遍历一样,设置指针和栈存放,但是看到卡哥的这个思路更妙。因为在前序遍历的时候,因为考虑到栈的特性,先把右孩子入栈再把左孩子入栈。先序遍历是中左右,后续遍历是左右中,那么我们只需要调整一下先序遍历的代码顺序,就变成中右左的遍历顺序,然后在反转result数组,输出的结果顺序就是左右中了。
class Solution {
public List postorderTraversal(TreeNode root) {
List result = new ArrayList<>();
TreeNode cur = root;
Stack st= new Stack<>();
if(root==null) return result;
st.push(root);
while(!st.isEmpty()){
cur=st.peek();
st.pop();
result.add(cur.val);
if(cur.left!=null) st.push(cur.left);
if(cur.right!=null) st.push(cur.right);
}
Collections.reverse(result);
return result;
}
} 二叉树的统一迭代法
在上一个思路迭代法中,前中后遍历的风格不是很一致。因此介绍一下统一写法。
中序遍历中无法同时解决访问节点(遍历节点)和处理节点(将元素放进结果集)不一致的情况。那我们就将访问的节点放入栈中,把要处理的节点也放入栈中但是要做标记。
如何标记呢,就是要处理的节点放入栈之后,紧接着放入一个空指针作为标记。 这种方法也可以叫做标记法。
class Solution {
public List inorderTraversal(TreeNode root) {
List result = new LinkedList<>();
Stack st = new Stack<>();
if (root != null) st.push(root);
while (!st.empty()) {
TreeNode node = st.peek();
if (node != null) {
st.pop(); // 将该节点弹出,避免重复操作,下面再将右中左节点添加到栈中
//前序遍历
if (node.right!=null) st.push(node.right); // 添加右节点(空节点不入栈)
if (node.left!=null) st.push(node.left); // 添加左节点(空节点不入栈)
st.push(node); // 添加中节点
st.push(null); // 中节点访问过,但是还没有处理,加入空节点做为标记。
//中序遍历
if (node.right!=null) st.push(node.right); // 添加右节点(空节点不入栈)
st.push(node); // 添加中节点
st.push(null); // 中节点访问过,但是还没有处理,加入空节点做为标记。
if (node.left!=null) st.push(node.left); // 添加左节点(空节点不入栈)
//后序遍历
if (node.right!=null) st.push(node.right); // 添加右节点(空节点不入栈)
st.push(node); // 添加中节点
st.push(null); // 中节点访问过,但是还没有处理,加入空节点做为标记。
if (node.left!=null) st.push(node.left); // 添加左节点(空节点不入栈)
} else { // 只有遇到空节点的时候,才将下一个节点放进结果集
st.pop(); // 将空节点弹出
node = st.peek(); // 重新取出栈中元素
st.pop();
result.add(node.val); // 加入到结果集
}
}
return result;
}
} 今日心得
今天主要重温了二叉树的一些基本原理并重点练习了二叉树深度优先搜索中的前中后三种遍历的三种写法,迭代方法是必须要掌握的!!需要常练习。