通过对TCPWindowSize的调整对网络流量的性能优化
1. TCP参数简述
为改善终端用户对数据流量的要求,现对TCP的参数做简单的分析,并通过TCP参数的调整,以期达到提高用户使用感知度的目的。
TCP参数如下:
• MTU─The Maximum Transfer Unit
• TCP1323Opts─ RFC 1323 TCP options: window scaling and timestamp
• MaxDupAcks─Maximum duplicate acknowledgements
• TCPWindowSize─TCP Window Size
• Sack─Selective Acknowledgement
以上均为影响网络性能的TCP参数,但最重要的是TCP窗口的大小。它决定了在给定时间里一个系统可以传输多少数据。每个TCP包都有一个头信息,头信息中有一定“窗口”域用来指明该系统接受数据缓冲区的大小。窗口大可以使远程系统传输较多的数据,窗口小则限制了传输的数据量,从而影响了网络的性能。因此要想最大限度地利用网络,应该选择适当的窗口大小,使之与可用宽带相匹配。若TCP窗口过小,终端用户将无法充分地利用网络上的可用宽带;如果TCP窗口过大,可能会导致错误恢复方面的问题,这样也会大大降低网络性能。
一般来说,所有系统都有一缺省的TCP窗口大小。有些应用允许调用系统级的API,根据每个连接来设置TCP窗口大小。正确设置窗口大小,发送端就可以不停地发送数据,因为当所有的数据传完时,接收应答正好出现。
当窗口过大时,TCP很难恢复丢失的数据。如一个远程的Web服务器得知某一客户设置的窗口大小为A,那么即使网上同时可传输的窗口大小只有B,它也会试图传送窗口大小为A的数据,这样就会有A-B窗口大小的数据在服务器和客户端之间的某一路由器处排队。如果数据丢失需要重传,需重传的数据必须排在后面,结果客户端认为连接不可恢复就会放弃该连接。另外,客户端不断地重复向服务器发送接收应答,也可能导致服务器中断连接。
选择MTU 的大小,设置TCP最大片段大小(MSS)为1460=1500-40,40为最小TCP/IP包头的大小,在没有给出具体数值的时候,我们可设置TcpWindowSize = 6*MSS,须遵守的规则:TcpWindowSize=2*n*MSS , 若TCP参数在C/S端有推荐设置,TCP/IP的包头会相应的增长,则不应采用TcpWindowSize=2*n*MSS的设置,依据网管要求进行设置。只注意网上的数据量,并不能确定TCP窗口值的大小。必须了解连接使用的最大段大小,因为TCP的延迟接收应答,算法规定必须收到两个完整的TCP包时才能发送接收应答。
实际上,缺省窗口大小应为MSS的4倍。如果接受窗口为MSS的2倍的话,发送端必须等待接收应答;如果接受窗口为MSS的4倍的话,发送者至少可以发送四个包,在头两个包的接收应答返回时,最后一个包刚刚发送。如果网络延迟较长时,接受窗口的大小应为MSS的6倍或8倍。
TCP窗口域只有16位,因此其最大值为65535。如果网络传输速度慢但有很大的容量,优化的窗口大小可能超过它,这时需要使用TCP窗口的高级选项。
TCP参数调整位置:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
1、 SackOpts
2、 TCP1323Opts
3、 TCPMaxDupAcks
4、 TCPWindowSize
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Interfaces
1、MTU
参考:TCP传输慢问题分析 - 知乎 (zhihu.com)
通过滑动窗口机制来控制接收窗口,表示着自己此刻还能接收多少字节的报文。当这个窗口太小,那发送方只能按照这个窗口去发送数据,整体下来传输速率就肯定会低很多。
RWND默认情况下占头部的16个bit,可以通过windows scaling 放大到32个bit。
2、发送方的CWND基本上是没办法具体确认的,它的变化遵循一系列大佬给定的算法和接受到的ACK有关,这些算法涉及到:慢启动、拥塞避免、拥塞发生、快速恢复。
来简单的说下上面四个过程,其中慢启动、拥塞避免差不多就如下所示:
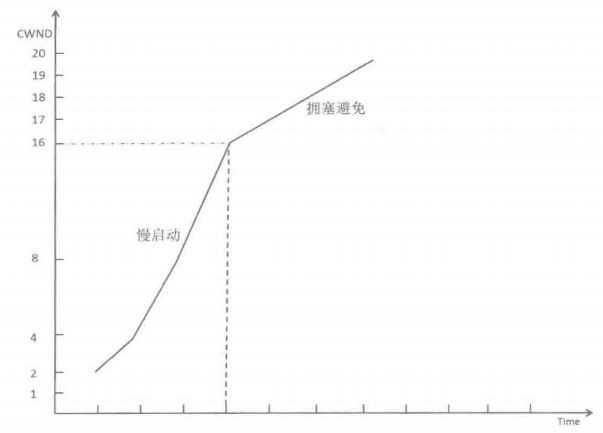
- 慢启动是从一个叫初始CWND的数值开始增长,这个初始CWND可能是2,可能是3也可能是10,代表多少个MSS的大小。Linux后来的版本里默认的初始值是10。
- 慢启动过程中,发送方不断的接受到确认的ACK,在每经历一个RTT时间后CWND呈指数增长。所以虽然刚开始只有几个报文可以发送,但是指数的增长提速很快。
- 慢启动到了一定的大小(ssthresh)就开始进入拥塞避免阶段,增长速度由指数增长变成了线性增长,主要是怕速度太快导致网络拥塞。
- 拥塞避免的线性增长过程中如果发生了丢包导致超时重传或者快速重传就会启动拥塞算法,拥塞算法很多,都是为了减小CWND以及减小ssthresh的值。
- 然后重新进入线性增长阶段,继续慢慢的增长。
用一张图来说明慢启动的过程差不多就是这样:
说完了上面这些,来看下可能会导致传输效率低下的几个方面,以及对应的解决办法。
解决方案
一、网络自身质量差导致的大量的重传、丢包导致传输速率上不去
按照上面所说的,网络中大量的丢包和重传,势必会严重的影响CWND的增长。
这种情况下,如果网络本来就烂的要死,那我们还想着继续用大马力去传文件只会给这个网络添堵。所以适当的做法应该是尽可能的让自己传输不影响网络,所以有两种方案可以选择:
- 降低发送方CWND的增长;
发送方的CWND增长的慢了,也就是发送数据的速率慢了,自然对网络的影响就小了。但是这里有一点疑问,我们的本意是提高传输速率,那降低CWND的增长岂不是反而降低了传输速率了?实际上并不是这样,要知道网络质量差导致的丢包重传对CWND的影响是巨大的,如下图所示
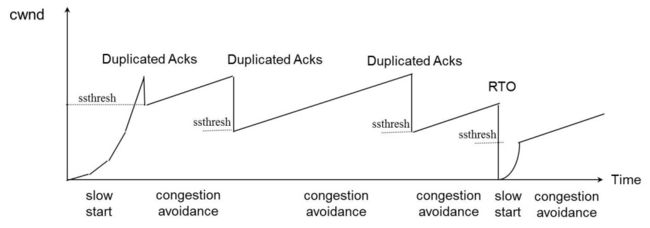
大多数拥塞算法在遇到快速重传的时候都会把CWND降低到一半并降低ssthresh,在遇到超时重传更严重,直接把CWND置成1了又得重新开始。而如果只是降低CWND的增长速度,顶多就是早点进入拥塞避免阶段的线性增长,整体的传输速率仍然是得到了提升。
降低CWND增长的方法,可以通过改小ssthresh的值,使指数增长过程持续的更短一点以及改小初始CWND,让增长的数值变小:
Linux:
ip route方法,对通过此路由的TCP连接有效,可同时修改初始化的CWND和ssthresh。
ip route change $r initCWND 10 ssthresh 10000
( $r 用ip route 显示的结果填充,ssthresh的值很多时候默认都是65535)
Windows的方法我没查到。
- 降低接收方的RWND;
降低接收方的RWND,这样就限制了发送方发送数据的速率,从而实现降低传输速率来防止丢包。
Linux:
可以在 /etc/sysctl.conf 里面插入
net.ipv4.tcp_rmem =
Windows:
需要修改注册表:不需要重启
对于 Windows 2000,展开以下注册表子项:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Interfaces
对于 Windows Server 2003 及以后,展开以下注册表子项:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters
在编辑菜单上 新建,然后单击 DWORD 值,在新值框中键入TcpWindowSize ,单击修改。在数值数据框中键入所需的窗口大小。
只说了如何修改,那怎么确认到底应该修改成多大的窗口呢?给一个计算方式:
[TCP Window Size in bits] = [Throughput in bits per second] * [Latency in seconds]
即RWND的值等于链路吞吐和带宽延迟的乘积的时候能最大化。
比如链路带宽是100Mb,通过ping对方得到的延迟是50ms,那么RWND就应该是
100 * 0.05 = 5Mb = 5 * 1000 * 1000 / 8 ≈ 60 0000 bytes
(实际上计算延迟应该使用更精确的方法,比如在wireshark中去查看。另外也可以用这个公式来计算一个tcp连接的理论上最大的带宽。)
需要注意,上面给出的linux的修改方式只是通过修改tcp_rmem 缓冲区大小来间接的影响RWND,实际上 tcp_rmem 里面还得维护一些tcp的状态信息,所以真实获得的 RWND 会比tcp_rmem要小1/2或者小1/4,具体小多少根据linux的某些设置。
二、CWND的增长过慢导致速度上不去
前面也提到了CWND是决定发送方的发送数据的窗口大小,在一个带宽以及网络质量都正常的环境下,如果CWND因为某些限制一直提不上去,那么本着传输速率取RWND和CWND中小的那一个原则,RWND配置的再大也无济于事。
影响CWND的增长可能有以下几个方面:
1)拥塞算法,不同的算法对CWND的增长和减少都有一定的差别,可以修改但肯定不是最优的方案。
2)初始CWND的值,CWND在慢启动时间内都是 *2 的速度增长,初始的CWND变大的话肯定能提高增长速度,但是一般也不推荐改动,修改方式在前面已经提到。
3)sthresh门限,CWND的慢启动在什么时候结束就是由ssthresh限制,可以把ssthresh的值改大,这样慢启动的过程就会持续的更长时间,CWND的增长速度自然就会加大,修改方法在前面已经提到。
4)增加接收方的ACK数量,CWND的增长和接受到的报文ACK数量是有直接关系的,也就是最理想的情况下,发送方的每个报文都能触发接收方回复一个ACK,这样CWND就能按照算法预期的增长。但实际上有某些软硬件的特性会影响ACK报文的数量,
比如:
网卡的TSO/GSO/LSO/LRO功能,目的在于减轻CPU的负载,让TCP分段的时候交给网卡处理,这样上层处理的一个大包由好几个报文组成,进行回复ACK的时候自然也只是回复大包,那ACK的数量就肯定会变少。
处理的方法也很简单,关闭网卡的这些特性:
Linux:
ethtool -K ethx tso off gso off lso off lro off # 有的接口可能不支持其中的部分特性,执行这个命令的时候会报错,也可以挨个执行off命令。
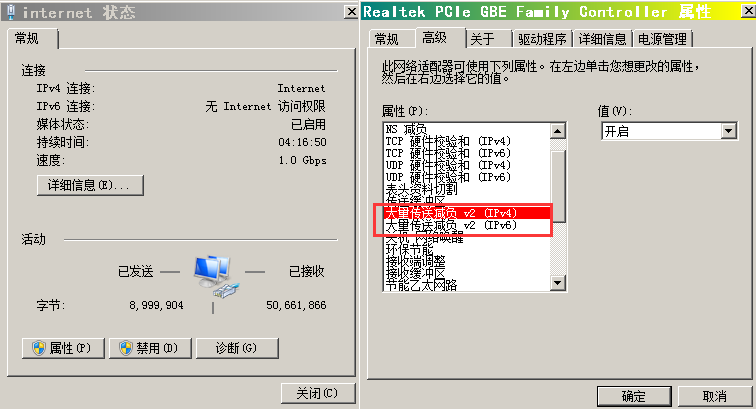
Windows:
网卡的“配置”里面关闭“大量传送减负”,如果是英文的话就是“Large Send Offload V2 (IPv4)”
三、没有开启SACK功能导致重传效率低
Sack功能是TCP三次握手过程中协商的一个参数,旨在发送Duplicate ACK告诉发送方指定报文没收到的时候,顺带再告诉发送方已经接收到了后面的报文段,这样发送方只需要重传丢失的部分,对于SACK中提及的已经收到的报文段则不需要重传。
用一张图表示SACK功能的作用:
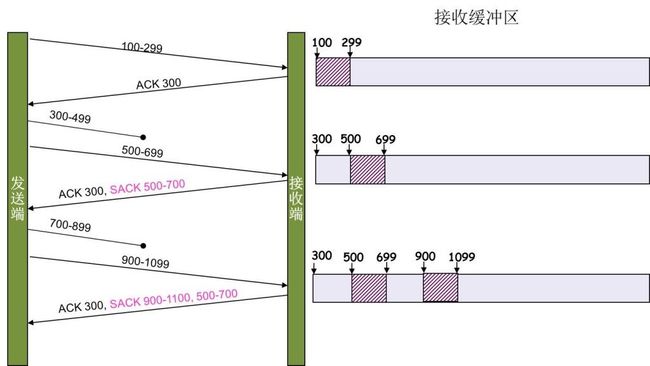
300-499片段丢失,收到了500-699的片段,那么接收方在回应ACK报文时,ack=300,sack携带的范围是500-699。这样发送方就明白了300-499之间的报文丢失了,然后重传300-499就可以了。后面的700-899片段丢失后的处理方式类似。
在wireshark中可以看出sack的内容:
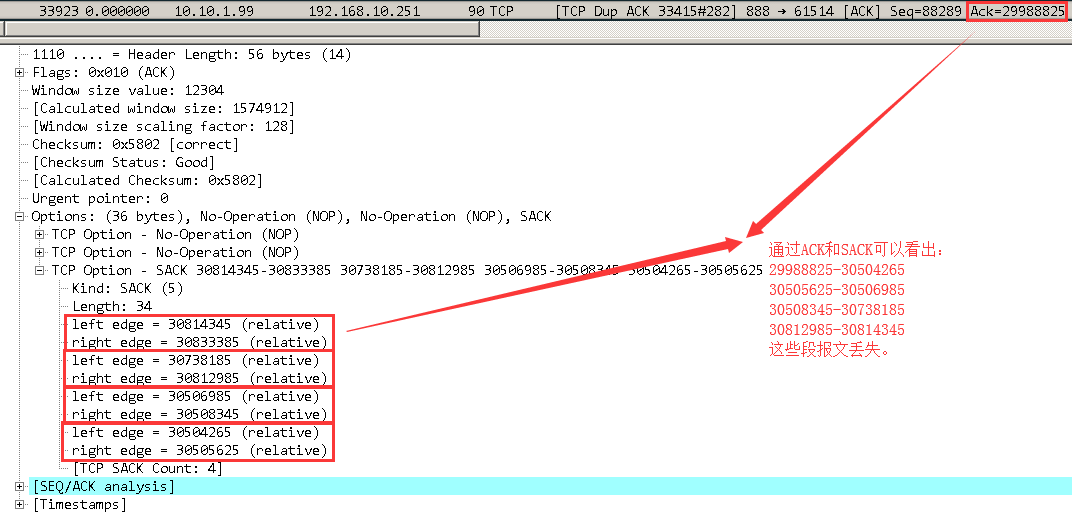
在没有开始sack的情况下,如果其中一个报文丢失,在触发三次Dup ACk后的快速重传后,会把这个丢失的报文后面已经发送的所有报文都重新再发送一次,这样一来效率自然就会底下,在重传多的网络中开启SACK和没开启SACK的速率要差很多倍。可以通过TCP的三次握手来判断是否支持SACK:
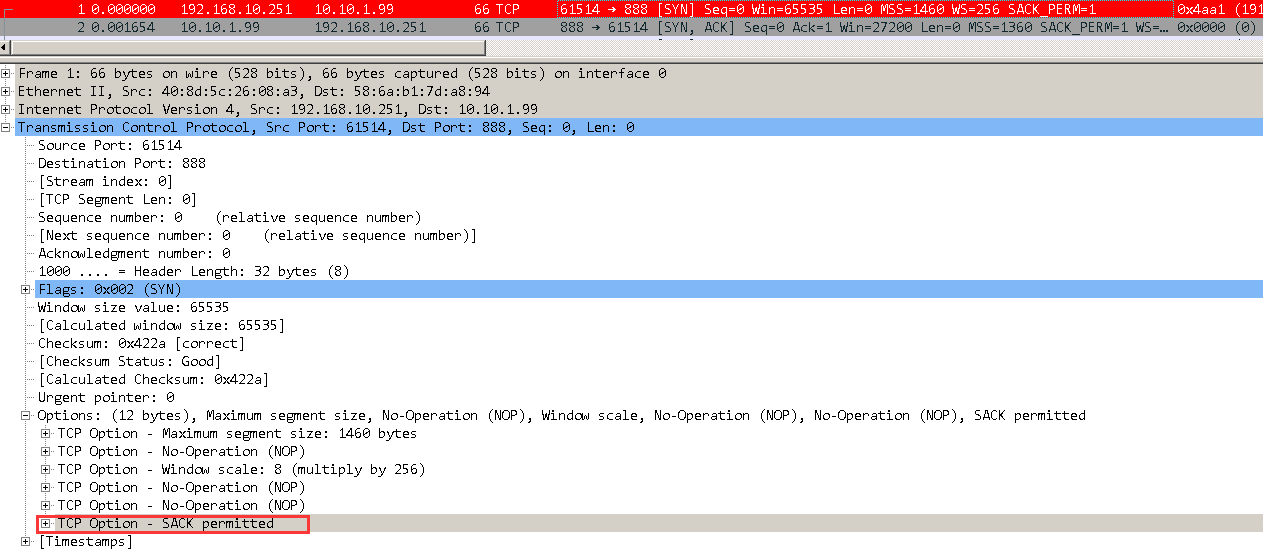
需要注意,SACK功能需要两边都支持,也就是三次握手中的SYN和SYN+ACK的报文都必须在option选项中允许。
开启SACK方法:
linux:
sysctl -w net.ipv4.tcp_sack=1
查看是否生效:sysctl -a|grep tcp_sack
windows:
注册表
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\Tcpip\Parameters\SackOpts 值修改成1
需要重启。
四、接收方窗口RWND太小
前面也提到了RWND是决定接收方的可接收的数据窗口大小,在一个带宽以及网络质量都正常的环境下,如果RWND因为某些限制一直提不上去,那么本着传输速率取RWND和CWND中小的那一个原则,CWND配置的再大也无济于事。
在TCP三次握手的过程中会交互一个叫 window scale 的选项,其作用为扩大RWND的因子,比如客户端告诉服务器自己的WS是8,那么后续接收端在回复ACK报文的时候携带的window大小就要 *8处理。在wireshark中显示出来的window是已经自动计算过后的,比如:

这个win=31872就是已经计算过后的RWND的值,因为需要WS的参与,所以在进行抓包操作的时候必须要把TCP的三次握手捕获到,否则wireshark无法得知WS,也就没办法正确的计算出RWND,会导致在很多报文显示和识别方面出错:
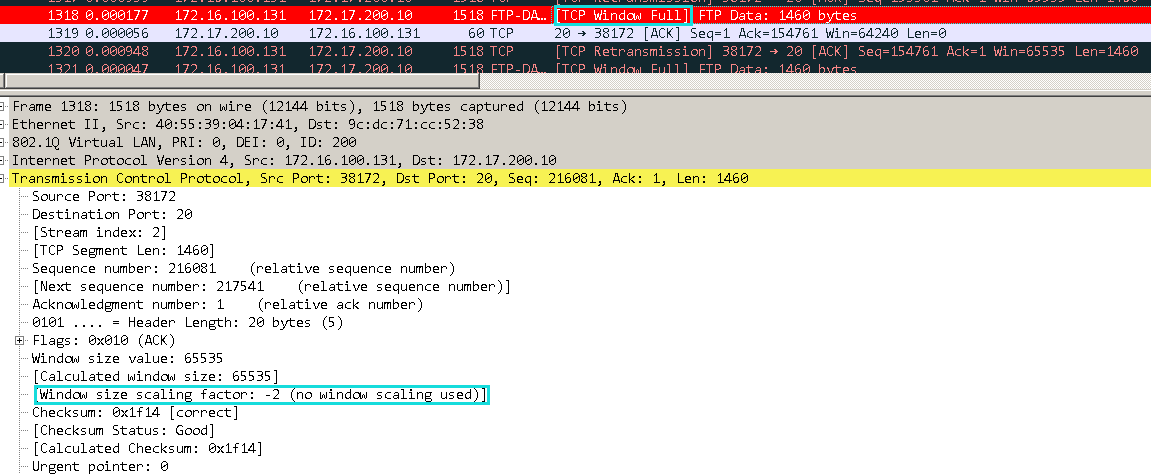
样例中因为没有捕获到TCP三次握手,window scale的值只能重置成未知的负数,window size也就只能自动变成最大的65535。此时这个报文被wireshark显示为window FULL,但实际上可能并非如此,只是因为wireshark没办法计算真实的window而已。
RWND同样是一个从较小的值慢慢增大到最大值的过程,具体是否变化还得看发送方发送数据的频率和自己这边应用层处理数据的频率,通过接收方的ACK报文中总是能看到当前的RWND大小。当RWND被占满且应用层一直没来及取数据的时候,接收方或者发送方告知RWND已满,此时发送方会停止发送,然后定期通过keeplive报文来探测接收方的RWND情况,当RWND腾出空间会通告给发送方 window update报文来更新窗口。
Linux和windows上修改RWND的方式在之前就已经有说明,还需要注意一点:linux上window scale功能如果被关闭了,那么修改RWND是没有作用的,linux上可以通过:
cat /proc/sys/net/ipv4/tcp_window_scaling 来查看是否开启WS,在没开启WS的情况下,RWND总是使用65535大小。
比如下面这个例子,我用公司的0.70 FTP上传文件的时候速度很慢只有600KB/s,抓了个包:

服务器通告自己的WS只有1,势必会造成RWND很小,事实也证明了我的猜测,在后续的报文里就看到了一堆的 TCP Window FULL的提示,也就是因为这个,发送方的发送数据速率受限。
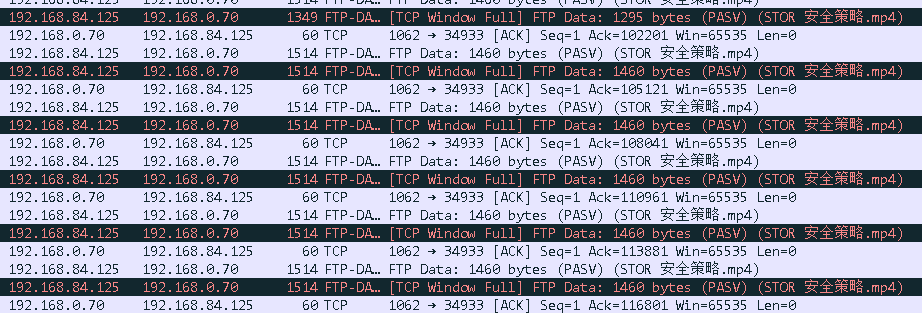
关于RWND的窗口被耗尽的提示在wireshark中有两种:
- TCP window FULL,是发送方在发送报文的时候,发现自己已经发出去的没有被ACK确认的报文总大小已经超过了接收方宣称的window值;此时发送方只能等待接收方的新的ACK,才能继续发送报文。
- TCP zero window,是接收方自己发送的,表明自己的window已经被占满无法接受更多的数据,只能等待应用来把数据取走;此时发送方只能等待 window update 消息才能继续发送报文。
要处理的方法很简单,增加WS的值即可:
Linux:
sysctl -w net.ipv4.tcp_adv_win_scale=3
Windows的没找到
顺便按照之前提供的公式计算一下公式的正确性:
通过wireshark的RTT计算图表可以看出RTT延迟大约是100ms
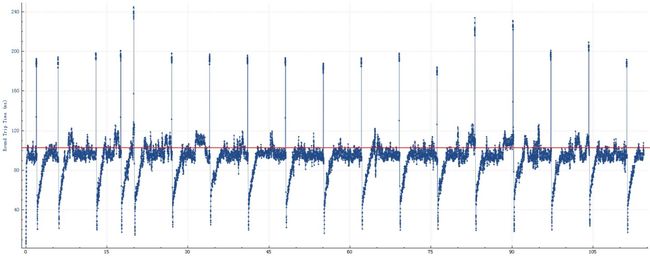
RWND即BDP为65535,可得结果:
[Throughput in bits per second] = [TCP Window Size in bits] / [Latency in seconds]
[Throughput in bits per second] = 65535 bytes / 0.1 s ≈ 600 KB
五、老生常谈的纳格算法和延迟确认共存的延迟
简单的介绍一下纳格(nagle)算法和延迟确认的作用:
nagle算法:是为了减少网络中的小包,把多个小包拼凑在一起发送。主要是在早期的带宽捉急的时代发明被使用的。在任意时刻,最多只能有一个未被ACK确认的小包,如果已经有一个小包没有被ACK,那么后续应用程序发送到缓冲区的小包只能等待前面一个小包被ACK以后才能继续发送。
延迟确认:为了让ack报文可以被数据传输捎带过去。比如客户端给服务器上传文件,此时服务器扮演的是数据的接收方要回应ACK,如果此时服务器要回显上传的状态,那么肯定也会回送数据给客户端,此时ACK报文就可以和这些回送的数据一起发送。这样就实现了避免纯ACK报文占用网络,要知道纯ACK报文没有一个字节的数据却要被填充成64字节发送到网络上就是一种浪费带宽的行为。
都是为了节省带宽,初衷都是善良的,但是当他们结合在一起使用的时候就可能捅娄子了,用一张图来说明一下问题的所在:

(图里面我写了其他的一些术语,这些都是一些操作不同操作系统的实现细节,不用过多的关注,只要知道有这么一回事就行了。)
再通过实际遇到的问题来看下。前几天正好遇到了一个的问题,用户反馈不通过直接下载可以达到6MB/s,通过 下载速度只有250KB/s。我本地搭建环境测试通过 下载速度会慢1倍作用,这个结果是可以接受的毕竟涉及到封装之类的操作,但是结果和客户的反馈差距很大。于是就在用户的客户机上抓了份包,结果接看到了这节讨论的延迟ACK的问题:
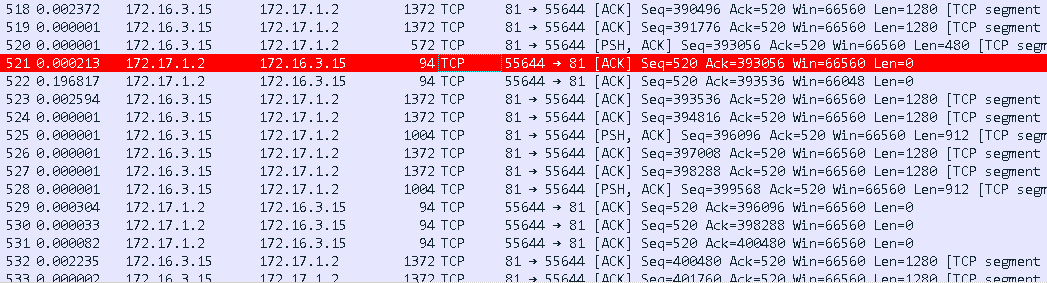
# 518、#519、#520 是一个完整的TCP报文分成了三个分段,其中#518和#519是根据MSS最大值来切分的而#520是剩余的小片。客户端 172.17.1.2在收到#518和#519以后满足了FULL size立马回应了ACK,通过#521的Ack=393056等于#519的seq 391776 + len 1280可以看出#521回应的是#519。
接下来#522回应的就是#520了,看似一切都很正常,但是查看#522和#521之间的时间就发现期间间隔了200ms,这就是问题的根本原因所在了。通过wireshark统计一下这样的情况存在多少(时间序列 tcptrace 图表):
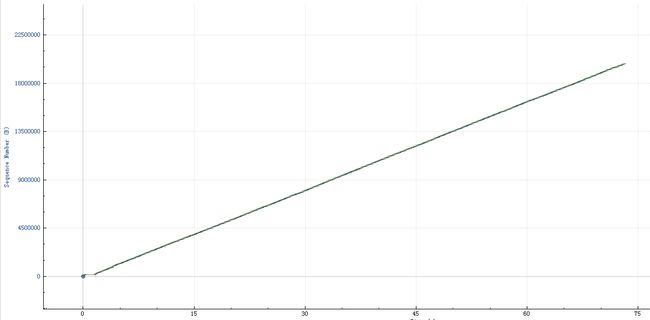
这么乍一看还挺正常,tcp的sequence增长很匀称,没啥毛病,但是一放大,哼哼问题就暴露出来了:

延迟ack啊,你是那么多那么的多,速度怎么能快起来嘛!知道了问题和延迟ack有关,那就容易了,关闭就可以了。
关于nagle的例子我实际中没有遇到,以后遇到了再补上吧。
关闭延迟ack和nagle的方法:
Windows:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\Tcpip\Parameters\Interfaces\{对应的网卡UUID}
新建DWORD 把TcpAckFrequency(delay ack) 和 TCPNoDelay (nagle算法)的值都为1,然后重启。
Linux:
Linux里面处理没有像windows那么直接,linux要关闭nagle算法需要在程序代码里修改setsocketopt的选项,把TCP_NODELAY(nagle)激活,以及TCP_QUICKACK用来关闭delay ack。这些操作在我们平时处理客户的应用问题面前就没办法实际去操作了,不过linux还有其他方式可以起到类似的效果:
echo 1 > /proc/sys/net/ipv4/tcp_low_latency # 牺牲高吞吐来降低延迟。
话说回来,上面那个延迟ACK的截图里面还有一些内容要补充一下,#520的572字节的报文此时被认为是一个小包所以ACK被延迟了,然而同样方式分段的1004就没有被延迟ACK,说明此时系统认为1004不是一个小包,或者解释成截图下方的发送方连续的6个报文,每两个报文就能完成一次FULL size所以能成功的回复ACK。具体是什么情况就可能得去看算法实现了。
还有一点比较奇怪的,通过wireshark可以看到发送方在接受到#520的ACK之后会立马再继续发送数据,也就是此时发送方并不是休息状态而是有数据已经到缓冲区了,没有立即发出的话按照网上介绍的资料:
- 发送方的CWND已经耗尽只能等待ACK以后才有新的空间发送报文;
- 接收方的RWND已经耗尽,只能等应用层来取;
- 之前还有未被确认的小包,但是看后续发出的#523的报文并不是小包。
所以,这块也是一直没想通的,可能还是某些细节没掌握到吧,但归根到底还是延迟ack在捣鬼。