Python全国计算机二级考试基本操作题
适用于2023年9月>

1.

# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
import ______
txt = input("请输入一段中文文本:")
______
print("{:.1f}".format(len(txt)/len(ls)))
考点:jieba库
函数 含义
jieba.lcut(s) 精确模式,返回一个列表类型的值
import jieba # 按题目提示需要引入jieba库
txt = input("请输入一段中文文本:")
ls = jieba.lcut(txt) # 根据下文推导得到变量名ls;使用jieba库的lcut函数对文本内容进行拆分并存储为列表,以便下文len函数对列表元素进行统计
print("{:.1f}".format(len(txt)/len(ls)))
______________________________________________________
=============== RESTART: D:\NCRE_KSWJJ\6668999999010101\PY102.py ===============
请输入一段中文文本:吃葡萄不吐葡萄皮
Building prefix dict from the default dictionary ...
Dumping model to file cache C:\Users\admin\AppData\Local\Temp\jieba.cache
Loading model cost 0.718 seconds.
Prefix dict has been built successfully.
1.6
扩展:jieba库有什么用?
jieba 是一个流行的中文分词工具,用于将连续的汉字文本切分成有意义的词语或词组。它主要用于自然语言处理(NLP)和文本分析领域,具体用途包括:
- 中文文本分词:jieba 可以将中文文本切分成词语,有助于文本处理、分析和理解。
- 中文搜索引擎: 在搜索引擎中,jieba 用于将用户输入的查询字符串分词,以便更好地匹配文档中的关键词。
- 文本挖掘和分析: 在文本挖掘和情感分析等任务中,jieba 可以帮助将文本分割成词语,从而更容易提取信息和特征。
- 自然语言处理(NLP): 在构建中文自然语言处理应用程序时,分词是一个重要的预处理步骤,jieba 提供了方便的工具来执行此操作。
- 关键词提取:jieba 也可以用于提取文本中的关键词,有助于了解文档的主题和内容。
- 文本分类: 在文本分类任务中,jieba 可以用于将文本分成词语,并为每个词语分配权重,以便训练和评估分类模型。
2.

考点:format格式化输出
- eval( )函数:eval()可以将input函数输入的数字字符串信息转换为int类型的值
- 填充内容–> 格式化输出

- Unicode编码转换
chr( )函数可以将普通字符转换为Unicode编码字符
- 字符串拼接:
**+**
# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
n = eval(input("请输入一个数字:"))
print("{______}".format(______))
n = eval(input("请输入一个数字:")) # eval()可以将input函数输入的数字字符串信息转换为int类型的值
print("{:+^11}".format(chr(n-1)+chr(n)+chr(n+1))) # 加号填充,内容居中,宽度11--> :+^11
# n-1、n、n+1使用chr()函数转换为Unicode编码字符;题目示例输出无空格,所以使用加号拼接字符串
————————————————————————————————————————————————————————————
请输入一个数字:9802
++++♉♊♋++++
3.

考点:format格式化输出

# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
n = eval(input("请输入正整数:"))
print("{______}".format(n))
n = eval(input("请输入正整数:"))
print("{:->20,}".format(n)) # 减号填充,右对齐,宽度20,千分位符--> :->20,
_________________________________
请输入正整数:1234
---------------1,234
4.

考点:
- jieba库的
**lcut( )**函数输出的值为列表类型- 列表的切片:
**list[起始,结束,步长]**(步长为n时,每次跳过n-1个元素,取下一个;步长为负数表示反向取,结尾处从-1开始)- print( )函数使用
**end=' '**参数取消折行
# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
import jieba
txt = input("请输入一段中文文本:")
______
for i in ls[::-1]:
______
import jieba
txt = input("请输入一段中文文本:")
ls = jieba.lcut(txt) # 据下文for循环推理得出变量名ls;据题意知需要将用户输入的txt内容倒序输出,下文提示使用列表切片的形式遍历列表内容,故ls存储的值类型应为列表,程序开头引入了一个jieba库,该库中lcut可将字符串逐个输出存储到列表中
for i in ls[::-1]:
print(i,end='') # 题目示例显示,输出信息不折行
________________________________________
请输入一段中文文本:我爱妈妈
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\admin\AppData\Local\Temp\jieba.cache
Loading model cost 0.570 seconds.
Prefix dict has been built successfully.
妈妈爱我
5.

考点:
- random库

- sample( )函数的使用
# 请在...处使用一行或多行代码替换
# 请在______处使用一行代码替换
#
# 注意:请不要修改其他已给出代码
import ______
brandlist = ['华为','苹果','诺基亚','OPPO','小米']
random.seed(0)
......
print(name)
import random # 随机函数来自于random库;也可根据下文.seed()方法推出random库
brandlist = ['华为','苹果','诺基亚','OPPO','小米']
random.seed(0)
name = random.sample(brandlist,1) # 跟据下文可知变量名name,题目要求随机选择一个手机品牌(列表元素)进行输出,故使用sample()函数,传入列表和每次获取的数量
print(name)
_____________________________________________________________
['OPPO']
6.

考点:
- 统计字符串、列表等序列类型的长度:
**len( )**- jieba库字符串切词:
**jieba.lcut()**- format格式化输出(传参形式):
**"XXX{}".format(参数)**
# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
import jieba
s = input("请输入一个字符串")
n = ______
m = ______
print("中文字符数为{},中文词语数为{}。".format(n, m))
import jieba
s = input("请输入一个字符串")
n = len(s) # 据下文推出n的值为中文字符数,使用len()函数直接计算即可
m = len(jieba.lcut(s)) # 据下文推出M值为中文次元数,使用jieba库中lcut()函数对用户输入值进行切词,结果存入列表中,最后使用len()函数计算元素数量即可
print("中文字符数为{},中文词语数为{}。".format(n, m))
____________________________________________________________
请输入一个字符串俄罗斯举办世界杯
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\admin\AppData\Local\Temp\jieba.cache
Loading model cost 0.591 seconds.
Prefix dict has been built successfully.
中文字符数为8,中文词语数为3。
7.

考点:
**split()**函数将字符串按空格分割存入列表- 两点间距离计算公式
- 幂的计算
**pow(底数,指数)**** **
# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
ntxt = input("请输入4个数字(空格分隔):")
______
x0 = eval(nls[0])
y0 = eval(nls[1])
x1 = eval(nls[2])
y1 = eval(nls[3])
r = pow(pow(x1-x0, 2) + pow(y1-y0, 2), ______)
print("{:.2f}".format(r))
ntxt = input("请输入4个数字(空格分隔):")
nls = ntxt.split() # 据下文知变量名nls,下文对其进行切片操作,故使用split()方法对用户输入的字符串按空格分割输出列表
x0 = eval(nls[0])
y0 = eval(nls[1])
x1 = eval(nls[2])
y1 = eval(nls[3])
r = pow(pow(x1-x0, 2) + pow(y1-y0, 2), 0.5) # 据两点间距离公式得出,此处需要对其进行开根号(1/2次方->0.5)
print("{:.2f}".format(r))
_______________________________________________________
请输入4个数字(空格分隔):0 1 3 5
5.00
8.

考点:格式化输出->内容填充

# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
s = input("请输入一个字符串:")
print("{______}".format(s))
s = input("请输入一个字符串:")
print("{:=^20}".format(s))
_________________________________
请输入一个字符串:PYTHON
=======PYTHON=======
9.

考点:
- 考察if-elif-else语句执行逻辑流程
- 条件表达式的应用
# 请在...处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
n = eval(input("请输入数量:"))
......
print("总额为:",cost)
# 请在...处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
n = eval(input("请输入数量:"))
if n == 1:
cost = 160
elif n <= 4:
cost = 160 * n * 0.9
elif n <= 9:
cost = 160 *n * 0.8
else:
cost = 160 * n * 0.7
print("总额为:",cost)
_______________________________________________
请输入数量:1
总额为: 160
10.

考点:
- python多重赋值(拆包)语法:
**x,y = 0,1**- **斐波那契数列:第一个值+第二个值=第三个值 **
**x = 0 , y = 1 --> x = y , y = x+y --> ...**
- While循环条件
# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
a, b = 0, 1
while ______:
print(a, end=',')
a, b = ______
a, b = 0, 1
while a <= 100: # 据题意设置循环条件
print(a, end=',')
a, b = b,a+b # 根据斐波那契数列公式计算推导式
_____________________________________________
0,1,1,2,3,5,8,13,21,34,55,89,
11.

# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
a = [3,6,9]
b = eval(input()) #例如:[1,2,3]
j=1
for i in range(len(__(1)____)):
b._____(2)_____
j+= __(3)______
print(b)
a = [3,6,9]
b = eval(input())
j=1
for i in range(len(a)): # len(b) --> 3
b.insert(j,a[i])
j+= 2
print(b)
____________________________________________________
[1, 3, 2, 6, 3, 9]
12.

考点:
- 遍历列表从第0位开始
**range()**用于生成序列
# 请在______处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
a = [3,6,9]
b = eval(input()) # 例如[1,2,3]
______
for i in ______:
s += a[i]*b[i]
print(s)
a = [3,6,9]
b = eval(input()) # 例如[1,2,3]
s = 0 # 据下文得出变量名s;程序需要对列表进行遍历,从0开始
for i in range(3):
s += a[i]*b[i]
print(s)
_________________________________________________
[1,2,3]
42
13.

考点:random库
- 随机数种子:
**random.seed()**- 指定范围随机数:
**random.randint(X,Y)**

# 请在______处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
import random
______
for i in range(______):
print(______, end=",")
import random
random.seed(123)
for i in range(10):
print(random.randint(1,999), end=",")
_______________________________________________________
54,275,90,788,418,273,111,859,923,896,
14.

考点:格式化输出 --> 内容填充

# 请在______处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
n = eval(input("请输入正整数:"))
print("{______}.format(n)")
n = eval(input("请输入正整数:"))
print("{:*>15}".format(n))
__________________________________________
请输入正整数:1234
***********1234
15.

考点:列表的切片:
**list[end]**``**list[start,end]**``**list[start,end,step]**
# 请在______处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
a = [3,6,9]
b = eval(input()) # 例如:[1,2,3]
c = []
for i in range(______):
c.append(______)
print(c)
a = [3,6,9]
b = eval(input()) # 例如:[1,2,3]
c = []
for i in range(3): # 遍历数为元素数量
c.append(a[i]+b[i]) # 需要计算每次遍历得到的两个列表的同一索引对应的元素值,结果存入c列表
print(c)
____________________________________________________
[1,2,3]
[4, 8, 12]
16.

考点:random库
- 随机数种子:
**random.seed(x)**- 生成指定范围的随机数:
**random.randint(x,y)**- a += b --> a = a + b
- 平方运算:
**pow(底数 , 指数)**

# 请在______处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
import random
______
s = 0
for i in range(5):
n = random.randint(_____)
s = ______
print(s)
import random
random.seed(0)
s = 0
for i in range(5):
n = random.randint(1,97)
s = s + pow(n,2)
print(s)
____________________________________
10964
17.

考点:格式化输出 --> 填充内容

# 请在______处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
n = eval(input("请输入正整数:"))
print("{_____}".format(n))
n = eval(input("请输入正整数:"))
print("{:=^14}".format(n))
____________________________________
请输入正整数:1234
=====1234=====
18.

考点:列表方法
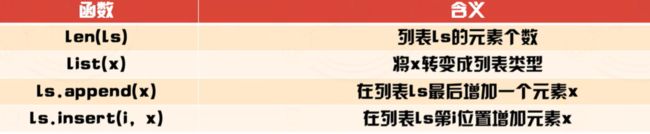
# 请在______处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
a = [3,6,9]
b = eval(input()) # 例如:[1,2,3]
j = 1
for i in range(len(______))
b.______
j += ______
print(b)
a = [3,6,9]
b = eval(input()) # 例如:[1,2,3]
j = 1
for i in range(len(a)): # 循环次数为列表元素数
b.insert(j,a[i]) # insert(下标,元素) 将列表a的元素依次插入到列表b的1、3、5下标处
j += 2 # 使用j作为下标索引,要将列表a的元素依次插入到列表b的1、3、5下标处,故+=2
print(b)
____________________________________
[1,2,3]
[1, 3, 2, 6, 3, 9]
19.

考点:random库
- 随机数种子
**random.seed(X)**- 指定范围的随机数
**random.randint(x,y)**
# 请在______处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
import random
......
s = 0
......
print(s)
import random
random.seed(100) # 随机数种子
s = 0
for i in range(3): # 遍历三次得到3个随机数
s += pow(random.randint(1,9),3) # 累加得到立方和
print(s)
_______________________________
1051
20.

考点:
- 格式化输出(内容填充)

**eval()**格式转换
# 请完善如下代码
s = input()
print("{______}".format(______))
s = input()
print("{:=>25,}".format(eval(s)))
_________________________________
1234
====================1,234
21.

考点:
- 字符串切片
**str[start : end : step]**``**str[::-1]**- 字符统计
**len()**- 输出不换行
**print(... , end=' ')**
# 请完善如下代码
s = input()
print(______)
print(______)
s = input()
print(s[::-1],end='')
print(len(s))
_________________________
1234abc
cba4321
7
22.

考点:
- 等差数列第n项值计算公式:
**a**n = a1 + **(n-1) * d**->**a**n** = 首项 + 差值 * 第n项**- 字符转换函数
**eval()**- 列表追加函数
**append()**
# 请完善如下代码
a, b, c = ______
ls = []
for i in range(c):
ls.______
print(ls)
a, b, c = eval(input())
ls = []
for i in range(c):
ls.append(a+b*i)
print(ls)
23.

考点:
- 格式化输出 (内容填充)
**eval()**数据类型转换- 转义字符
**\**

# 完善如下代码
s = input()
print("{______}".format(______))
s = input()
print("{:\"^30x}".format(eval(s)))
______________________________________
1234
"""""""""""""4d2""""""""""""""
24.

n = input()
s = "〇一二三四五六七八九"
for o in "0123456789":
______
print(n)
n = input()
s = "〇一二三四五六七八九"
for c in "0123456789": # 字符串遍历
n = n.replace(c, s[int(c)]) # replace(old,new)
print(n)
_______________________________
123
一二三
25.

考点:
- 等比数列通项公式:
**第n项 = 首项 * (公比**(n-1))**- 列表元素追加:
**.append()****.join()**方法只能用于字符串类型;使用**str()**转换数据类型为字符串
a, b , c = ______
ls = []
for i in range(c):
______
print(",".join(ls))
a, b , c = eval(input()) # 获取用户输入值,并进行格式转换
ls = []
for i in range(c):
ls.append(str(a*(b**i))) # 根据题意,需要将等比数列值追加到列表ls中;下文使用.join()方法,故需要将等比数列值转换为字符串类型
print(",".join(ls))
______________________________
1,2,3
1,2,4
26.

考点:字符串方法
- 将字符串按照指定字符分割,并存入列表:
**ste.split()**- format格式化输出:
**print('{}'.format())**- 输出不换行:
**print(... , end=' ')**

num = imput().______
for i in num:
print(______)
num = input().split(",") # 将用户输入的值按逗号分隔,存入列表
for i in num: # 遍历该列表
print('{:>10}'.format(i),end='') # 格式化输出,不换行
_______________________________________________________________
23,42,543,56,71
23 42 543 56 71
27.

scale = 0.0001
def calv(base, day):
val = base * pow(______)
return val
print('5年后的成就值是{}'.format(int(calv(1, 5*365))))
year = 1
while calv(1, ______) < 100:
year += 1
print('{}年后成就值是'.format(year))
# 平均工作时间是每天8h
# 某程序员平均每天工作8+3=11h 成就值=1
# 1h -> 0.01%
# 5Y -> 5*365*24h --> *0.0001
# ?Y --> 100%
scale = 0.0001 # 成就值增量-->0.01%
def calv(base, day):
val = base * pow((1+scale),day*11)
return val
print('5年后的成就值是{}'.format(int(calv(1, 5*365)))) # base:1 --> 当下成就值
year = 1
while calv(1, year*356) < 100:
year += 1
print('{}年后成就值是'.format(year))
_______________________________
5年后的成就值是7
12年后成就值是
28.

考点:
**type()**打印变量数据类型**int**整数型数据类型- 逻辑与:
**and**(同真则真,一假则假)- 赋值
**=**,等于**==**- 正整数判断条件:
**n > 0**and**n % 1 == 0**- while终止关键字:
**break**
while True:
try:
a = eval(input('请输入一个正整数:'))
if a > 0 and ________
print(a)
________
else:
print("请输入正整数")
except:
print("请输入正整数")
while True:
try:
a = eval(input('请输入一个正整数:'))
if a > 0 and type(a) == int:
print(a)
break
else:
print("请输入正整数")
except:
print("请输入正整数")
________________________________
请输入一个正整数:3.3
请输入正整数
请输入一个正整数:357
357
while True:
try:
a = eval(input('请输入一个正整数:'))
if a > 0 and a % 1 == 0:
print(a)
break
else:
print("请输入正整数")
except:
print("请输入正整数")
________________________________
请输入一个正整数:3.3
请输入正整数
请输入一个正整数:357
357
29.

考点:
**range(start , end)**取值区间为左开右闭区间**(start , end]**- 使用
**eval()**函数去除**input()**产生的引号,保留用户原始数据类型- format格式化输出使用
**{}**展位后进行传参- format格式化输出内容填充:
**{:填充符 对齐 宽度 千分位}**- 将指定内容输出n次:
**"..."*n**
n = input('请输入一个正整数:')
for i in range(______):
print('______'.format(i,_____))
n = input('请输入一个正整数:')
for i in range(1,eval(n)+1): # 遍历时i是从0开始取值的,故需要设置起始值为1;结束值+1确保用户输入的值能被遍历到
print('{:02} {}'.format(i,'>'*i)) # 使用{}传参
________________________________________
请输入一个正整数:3
01 >
02 >>
03 >>>
30.

考点:
- 变量拆包:
**x, y = 0, 1**- 格式化输出:
**print("...{}...".format(传入值))**
ns = input("请输入一串数据:")
dnum,dchr = ________
for i in ns:
if i.isnumeric():
dnum += ________
elif i.isalpha():
dchr += ________
else:
pass
print('数字个数:{},字母个数:{}'.format(______))
ns = input("请输入一串数据:")
dnum, dchr = 0,0 # 数据初始值为0
for i in ns:
if i.isnumeric(): # 判断是否为数字
dnum += 1 # 是数字就自增1
elif i.isalpha(): # 判断是否为字母
dchr += 1 # 是字母就自增1
else:
pass
print('数字个数:{},字母个数:{}'.format(dnum,dchr)) # 格式化输出
___________________________________________________________
请输入一串数据:fda243fdw3
数字个数:4,字母个数:6
31.

考点
- 初始化变量
- 列表切片
std = [['张三',90,87,95],['李四',83,80,87],['王五',73,57,55]]
modl = "亲爱的{},你的考试成绩是:英语{},数学{},Python语言{},总成绩{}。特此通知!"
for st in std:
cnt = _______
for i in range(______):
cnt += ______
print(modl.format(st[0],st[1],st[2],st[3],cnt))
std = [['张三',90,87,95],['李四',83,80,87],['王五',73,57,55]]
modl = "亲爱的{},你的考试成绩是:英语{},数学{},Python语言{},总成绩{}。特此通知!"
for st in std:
cnt = 0 # 初始化变量
for i in range(1,len(st)):
cnt += st[i] # 各科成绩累加st[1]+st[2]+st[3]
print(modl.format(st[0],st[1],st[2],st[3],cnt))
_______________________________________________________________________________________________
亲爱的张三,你的考试成绩是:英语90,数学87,Python语言95,总成绩272。特此通知!
亲爱的李四,你的考试成绩是:英语83,数学80,Python语言87,总成绩250。特此通知!
亲爱的王五,你的考试成绩是:英语73,数学57,Python语言55,总成绩185。特此通知!
32.

考点:
- 变量初始化
- 数据类型转换
- 格式化输出内容填充:
**{:填充符 对齐 宽度 千分位}**
s = input("请输入一个正整数:")
________
for c in s:
cs += ________
print('{______}'.format(cs))
s = input("请输入一个正整数:")
cs = 0 # 初始化变量
for c in s:
cs += int(c) # 将遍历的内容(每一位数)累加
print('{:=^25}'.format(cs))
__________________________________
请输入一个正整数:1357
===========16============
33.

考点:
中文字的Unicode编码范围:**'\u4e00' <= char <= '\u9fff'**
s = input("请输入中文和字母组合:")
_______
for c in s:
if _______:
count += 1
print(count)
s = input("请输入中文和字母组合:")
count = 0
for c in s:
if '\u4e00' <= c <= '\u9fff':
count += 1
print(count)
__________________________________________
请输入中文和字母组合:world世界peace和平
4
34.

考点:
将字符串按照指定字符分割,并存入列表:**str.split()**
s = input("请输入一组数据:")
ls = ______
lt = []
for i in ls:
lt.append(______)
print(max(lt))
s = input("请输入一组数据:")
ls = s.strip(',') # 将用户输入的内容按逗号分割并存入列表
lt = []
for i in ls:
lt.append(eval(i)) # 将遍历内容追加至列表
print(max(lt))
_______________________________
请输入一组数据:1,3,5,7,9,7,5,3,1
9
35.

考点
- 终止循环
**break**- 格式化输出
**print('{:字符 对齐 宽度 千分位}'.format(...))**
s = input("请输入一个小数:")
s = s[::-1]
______
for c in s:
if c == '.':
______
cs += eval(c)
print('{______}'.format(cs))
s = input("请输入一个小数:")
s = s[::-1] # 倒序
cs = 0 # 初始化变量
for c in s: # 遍历
if c == '.': # 遇到小数点终止循环
break
cs += eval(c)
print('{:*>10}'.format(cs))
______________________________________
请输入一个小数:1234.5678
********26
36.

import time
t = input("请输入一个浮点数时间信息:")
s = time.ctime(______)
ls = s.split()
print(______)
import time
t = input("请输入一个浮点数时间信息:")
s = time.ctime(eval(t)) # 需要将用户输入的浮点数按原格式返回 --> Wed Feb 21 10:47:11 2018
ls = s.split(' ') # 将时间信息按空格分割
print(ls[3].split(':')[0]) # ls[3] --> 10:47:11 再按冒号分割一次取出小时 split(':')[0] --> 10
# print(ls[3][0:2]) # 也可以使用切片直接取出
__________________________________________________
请输入一个浮点数时间信息:1519181231.0
10
37.

import random
s = input("请输入随机数种子:")
ls = []
for i in range(26):
ls.append(chr(ord('a')+i))
for i in range(10):
ls.append(chr(______))
random.seed(______)
for i in range(10):
for j in range(8):
print(______,end='')
print()
import random
s = input("请输入随机数种子:")
ls = [] # 最终会得到25+10=35个元素
for i in range(26): # a-z --> 遍历25次
ls.append(chr(ord('a')+i))
for i in range(10): # 0-9 --> 遍历10次
ls.append(chr(ord('0')+i))
random.seed(eval(s))
for i in range(10):
for j in range(8): # 从ls中取随机索引处的字符输出
print(ls[random.randint(0,35)],end='')
print()
______________________________________________________________
请输入随机数种子:125
potlwjta
ej460gqs
k5l5jdr8
1blked1f
y37c4mhx
1oa18pv5
pz6r37t7
xegd1ql3
l2w0ksh6
pxuybhp9
38.

ls = eval(input())
s = ""
for item in ls:
if ______ == type("香山"):
s += ______
print(s)
ls = eval(input())
s = ""
for item in ls:
if type(item) == type("香山"):
s += item
print(s)
_____________________________________
[123,'Python',98,'等级考试']
Python等级考试
39.

import random
random.seed(25)
n = ______
for m in range(1,7):
x = eval(input("请输入猜测数字:"))
if x == n:
print("恭喜你,猜对了")
break
elif ______:
print("大了,再试试")
else:
print("小了,再试试")
if ______:
print("谢谢,请休息后再猜")
import random
random.seed(25)
n = random.randint(1,100)
for m in range(1,7):
x = eval(input("请输入猜测数字:"))
if x == n:
print("恭喜你,猜对了")
break
elif x > n:
print("大了,再试试")
else:
print("小了,再试试")
if m == 6:
print("谢谢,请休息后再猜")
___________________________________________
请输入猜测数字:80
大了,再试试
请输入猜测数字:60
大了,再试试
请输入猜测数字:30
小了,再试试
请输入猜测数字:20
小了,再试试
请输入猜测数字:40
小了,再试试
请输入猜测数字:50
大了,再试试
谢谢,请休息后再猜
40.

考点:
- 函数调用
- 奇偶判断
def f(n):
______
if ______:
for i in range(1,n+1,2):
s += 1/i
else:
for i in range(2,n+2n,2):
s += 1/i
return s
n = int(input())
print(______)
def f(n):
s = 0 # 下文使用变量s未初始化
if n % 2 != 0: # 判断是否为奇数 n%2==1
for i in range(1,n+1,2):
s += 1/i
else:
for i in range(2,n+1,2):
s += 1/i
return s
n = int(input())
print(f(n)) # 函数调用才能输出
________________________________________
4
0.75
41.

n = eval(input("请输入一个整数:"))
for i in range(1,n):
for j in range(1,n):
if ______:
______
print()
n = eval(input("请输入一个整数:")) # 8
for i in range(1,n): # (1,8) -> 1,2,3,4,5,6,7
for j in range(1,n): # (1,8) -> 1,2,3,4,5,6,7
if i <= j < n:
print(j,end='')
print()
_________________________________
请输入一个整数:8
1234567
234567
34567
4567
567
67
7
42.

考点:
- 小写转大写:
**.upper()**- 切片倒序输出:
**[::-1]**
s = input("请输入5个小写字母:")
______
print(','.join(______))
s = input("请输入5个小写字母:")
s = s.upper()
print(','.join(s[::-1]))
__________________________________________
请输入5个小写字母:abcdefg
G,F,E,D,C,B,A
43.

import random
______
random.seed(100)
for i in range(1,10):
if i < 10:
print(_______)
else:
print(random.randint(1,n))
import random
n = eval(input())
random.seed(100)
for i in range(1,10):
if i < 10:
print(random.randint(1,n),end=",")
else:
print(random.randint(1,n))
_________________________________________
900
150,471,466,790,179,723,403,750,359,
44.

考点:
- 格式化输出:
**print("...{}...".format(...))**- 内容填充:
**{:填充 对齐 宽度 千分位 .精度 类型}**
a = input("请输入符号:")
s = "PTYHON"
print("{______}".format(______))
a = input("请输入符号:")
s = "PTYHON"
print("{:{}^30}".format(s,a))
________________________________________
请输入符号:#
############PTYHON############
45.

考点:
- 判断是否为数字:
**.isdigit()**- 字符串按某字符分割输出列表:
**.split("字符")**- 字符串去除两边空格:
**.strip("")**
myinput = input("请输入:")
ls = ______
s = 0
for c in ls:
if c.strip("").isdigit():
______
print("数字和是:"+ str(s))
myinput = input("请输入:")
ls = myinput.split(",") # 先将用户输入的字符串按逗号分隔存入列表
s = 0
for c in ls:
if c.strip("").isdigit(): # 判断是否是数字
s += eval(c) # 判断为True就累加
print("数字和是:"+ str(s))
————————————————————————————————————————————————————
请输入:1,海淀区,ab,56,3,中关村
数字和是:60
46.

考点:
- 打开文件:
**open('Path','Module')**- 判断某个序列中是否存在某些值:
**in**** ****not in**
__________
ls = []
for line in f:
for c in line:
if __________:
ls.append(c)
f.close()
print(len(ls))
f = open('data.txt','r') # 以只读形式打开文件
ls = [] # 列表元素为文件内容中每个不同的文字
for line in f: # 遍历文件中每一行line
for c in line: # 遍历该行中的每个字c
if c not in ls: # 判断该字c是否存在列表ls中,将列表中没有的字追加进去
ls.append(c)
f.close()
print(len(ls)) # 计算列表长度等于输出不同汉字的数量
47.

考点:
- format格式化:
**{:填充 对齐 宽度 千分位 .精度 类型}**- 浮点数保留小数点后需要在末尾加f
f = eval(input("请输入一个浮点数:"))
print("浮点数是:{________}".format(f))
f = eval(input("请输入一个浮点数:"))
print("浮点数是:{:>10.2f}".format(f))
_____________________________
请输入一个浮点数:2.4
浮点数是: 2.40
_____________________________
请输入一个浮点数:5.98320
浮点数是: 5.98
48.

考点:
**rang(start, end, step)**- 小写字母:
**char(97) --> a**
h, w = eval(input("请输入起始英文字母的序号和连续输出的个数,逗号隔开:"))
cstr = ''
for i in range(______)
c = ______
cstr += c
print(cstr)
h, w = eval(input("请输入起始英文字母的序号和连续输出的个数,逗号隔开:"))
cstr = ''
for i in range(w):
c = chr(97+i)
cstr += c
print(cstr)
________________________
请输入起始英文字母的序号和连续输出的个数,逗号隔开:0,3
abc
49.

考点:
- 去除字符串两端的引号
**eval()**- 将字符串按某符号分割输出列表
**.split('char')**- 序列切片
import random as r
r.seed(1)
s = input("请输入三个整数 n,m,k:")
slist = s.split(",")
.....
import random as r
r.seed(1)
s = input("请输入三个整数 n,m,k:")
slist = s.split(",")
for i in range(eval(slist[0])):
print(r.randint(eval(slist[2]),eval(slist[1])))
_______________________________________________________________
请输入三个整数 n,m,k:4,26,10
14
12
18
13
50.

# 请在______处使用一行或多行代码替换
#
# 注意:请不要修改其他已给出代码
import turtle
turtle.pensize(2)
d = 0
for i in range(1, ______(1)________):
______(2)________
d += ______(3)________
turtle.seth(d)
51.

周杰伦
张艺兴
鹿晗
黄晓明
迪丽热巴
孙俪
杨幂
鹿晗
鹿晗
鹿晗
孙俪
杨幂
孙俪
杨幂
迪丽热巴
孙俪
杨幂
鹿晗
鹿晗
鹿晗
孙俪
杨幂
孙俪
迪丽热巴
孙俪 杨幂
杨幂
鹿晗
鹿晗
鹿晗
孙俪
杨幂
孙俪
孙俪
孙俪
孙俪
孙俪 杨幂
# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
f = open("vote.txt")
names = f.readlines()
f.close()
n = 0
for name in _______(1)_________:
num = _______(2)_________
if _______(3)________:
n+=__(4)____
print("有效票{}张".format(n))
# 请在______处使用一行代码或表达式替换
#
# 注意:请不要修改其他已给出代码
f = open("vote.txt")
names = f.readlines()
f.close()
D = {}
for name in _______(1)_________:
if len(_____(2)______)==1:
D[name[:-1]]=_______(3)_________ + 1
l = list(D.items())
l.sort(key=lambda s:s[1],_______(4)_________)
name = l[0][0]
score = l[0][1]
print("最具人气明星为:{},票数为:{}".format(name,score))
52.

人工智能、机器学习和深度学习之间的区别和联系
有人说,人工智能(AI)是未来,人工智能是科幻,人工智能也是我们日常生活中的一部分。这些评价可以说都是正确的,就看你指的是哪一种人工智能。
今年早些时候,Google DeepMind的AlphaGo打败了韩国的围棋大师李世乭九段。在媒体描述DeepMind胜利的时候,将人工智能(AI)、机器学习(machine learning)和深度学习(deep learning)都用上了。这三者在AlphaGo击败李世乭的过程中都起了作用,但它们说的并不是一回事。
今天我们就用最简单的方法——同心圆,可视化地展现出它们三者的关系和应用。
人工智能、机器学习和深度学习之间的区别和联系
如上图,人工智能是最早出现的,也是最大、最外侧的同心圆;其次是机器学习,稍晚一点;最内侧,是深度学习,当今人工智能大爆炸的核心驱动。
五十年代,人工智能曾一度被极为看好。之后,人工智能的一些较小的子集发展了起来。先是机器学习,然后是深度学习。深度学习又是机器学习的子集。深度学习造成了前所未有的巨大的影响。
| 从概念的提出到走向繁荣
1956年,几个计算机科学家相聚在达特茅斯会议(Dartmouth Conferences),提出了“人工智能”的概念。其后,人工智能就一直萦绕于人们的脑海之中,并在科研实验室中慢慢孵化。之后的几十年,人工智能一直在两极反转,或被称作人类文明耀眼未来的预言;或者被当成技术疯子的狂想扔到垃圾堆里。坦白说,直到2012年之前,这两种声音还在同时存在。
过去几年,尤其是2015年以来,人工智能开始大爆发。很大一部分是由于GPU的广泛应用,使得并行计算变得更快、更便宜、更有效。当然,无限拓展的存储能力和骤然爆发的数据洪流(大数据)的组合拳,也使得图像数据、文本数据、交易数据、映射数据全面海量爆发。
让我们慢慢梳理一下计算机科学家们是如何将人工智能从最早的一点点苗头,发展到能够支撑那些每天被数亿用户使用的应用的。
| 人工智能(Artificial Intelligence)——为机器赋予人的智能
人工智能、机器学习和深度学习之间的区别和联系
早在1956年夏天那次会议,人工智能的先驱们就梦想着用当时刚刚出现的计算机来构造复杂的、拥有与人类智慧同样本质特性的机器。这就是我们现在所说的“强人工智能”(General AI)。这个无所不能的机器,它有着我们所有的感知(甚至比人更多),我们所有的理性,可以像我们一样思考。
人们在电影里也总是看到这样的机器:友好的,像星球大战中的C-3PO;邪恶的,如终结者。强人工智能现在还只存在于电影和科幻小说中,原因不难理解,我们还没法实现它们,至少目前还不行。
我们目前能实现的,一般被称为“弱人工智能”(Narrow AI)。弱人工智能是能够与人一样,甚至比人更好地执行特定任务的技术。例如,Pinterest上的图像分类;或者Facebook的人脸识别。
这些是弱人工智能在实践中的例子。这些技术实现的是人类智能的一些具体的局部。但它们是如何实现的?这种智能是从何而来?这就带我们来到同心圆的里面一层,机器学习。
# 请在...处使用多行代码替换
#
# 注意:其他已给出代码仅作为提示,可以修改
... #此处可多行
f = open('out1.txt','w')
... #此处可用多行
f.close()
# 请在...处使用多行代码替换
#
# 注意:其他已给出代码仅作为提示,可以修改
... # 此处可多行
d = {}
... # 此处可多行
ls = list(d.items())
ls.sort(key=lambda x:x[1], reverse=True) # 此行可以按照词频由高到低排序
... # 此处可多行