Span-based Joint Entity and Relation Extraction with Transformer Pre-training

Abstract
本文介绍了一种基于span的联合实体和关系提取的注意力模型。主要贡献是在BERT嵌入上的轻量级推理,能够进行实体识别和过滤,以及使用本地化的,无标记的上下文表示的关系分类。
该模型使用强句内负样本进行训练,这些负样本在一次BERT中被有效的提取,这有助于对句子中的所有span进行搜索,在消融试验中,本文证明了预训练、负采样和局部环境的好处。
Instruction
利用transformer作为backbone,基于span的方法:任何标注子序列都构成一个潜在的实体,并且任何一对span之间都可能有关系。本文使用本地上下文表示,而不是用特定的标记,并在单一的BERT中抽取中抽取负面样本。来自同一句子的负面样本产生的训练高效并有效,而足够多数量的强负面样本似乎是关键。局部化的上下文表示对长句子有益。
model

1. 句子中所有span都被分类为实体类型,如三个example span ![]() (红色所示)。
(红色所示)。
2. 归类为非实体的span  被过滤。
被过滤。
3. 将所有剩余的成对实体(![]() )与它们的上下文(实体之间的span 黄色)组合到一起,并分类为关系。
)与它们的上下文(实体之间的span 黄色)组合到一起,并分类为关系。
span分类
将上下文通过BERT,通过span classifier 的向量有三部分:1)实体包含对的token向量(红色)2)宽度嵌入(蓝色)3)特殊标记CLS(绿色)。
宽度嵌入是在训练中学习到的嵌入矩阵,即实体的宽度为k+1,表示实
中包含k+1个token,那么实体的宽度嵌入![]() 就会表示为以k+1为下标。
就会表示为以k+1为下标。
首先选择一个span,然后使用max-pooling,将其与宽度嵌入拼接起来,如果span有三个向量,那么width embedding选择width embedding的第三个向量,而蓝色的width embedding是通过反向传播学到的。
输入到span classifier的最终向量最后经过一个softmax层得到最终的结果。
span filtering
将softmax分类后得到none类的过滤掉。并不对所有的实体和关系进行搜索,而是将实体和关系控制在10个token以内。
relation classification
关系分类器的输入包括两部分:两个候选实体(红色和蓝色的拼接);整个句子的表示c(CLS绿色)不太适合长句子对于多关系的表示,所以摒弃c。采用局部语义信息来进行关系分类,本文任务头实体的结束到尾实体的开始这一段的span看做关系(黄色),随着这样存在问题,但是效果较好。考虑到反向关系的存在,所以将关系分类的输入为:
![]()
![]()
通过sigmod设置阈值,当大于指定阈值的时候任务关系成立。
负采样
对于实体识别,采用一定量的随机不含实体的span作为负样本。
对于关系识别,采用一定量的真正的实体但是实体之间没有关系作为负样本。为什么要这样?
Result
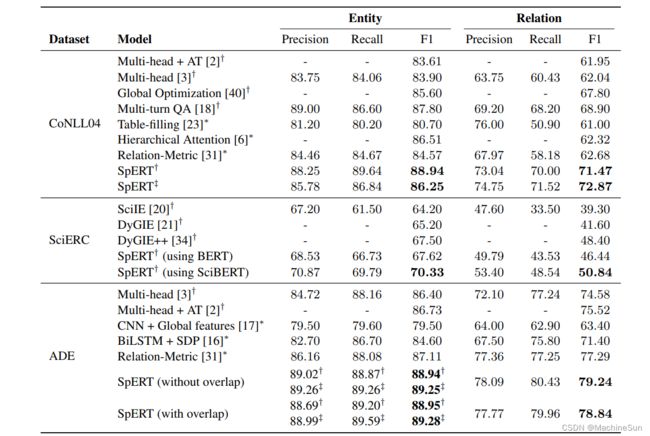
尽管在使用LSTM或注意机制检测长距离关系方面取得了进展,但随着context的增加而产生的噪声仍然是一个挑战。通过使用本地化上下文,即实体候选之间的上下文,关系分类器可以聚焦于通常对关系类型最具区别性的句子部分。为了评估这一效果,本文将本地化上下文与使用整个句子的另外两个上下文表示进行了比较:
full context:不是对实体候选之间的上下文执行最大池化,而是对句子中的所有标记执行最大池化。
CLS token:就像在实体量词(图1,绿色)中一样,我们使用一个特殊的量词令牌作为上下文,它能够关注整个句子。
在CoNLL04开发集(图3)上评估了这三个选项:当使用带有本地化上下文的SpERT时,该模型的F1得分达到71.0%,显著高于整个句子的最大池化(65.8%)和使用分类器标记(63.9%)。

图3还显示了关于语句长度的结果:本文将CoNLL04开发集分为四个不同的部分,即<20、20−34、35−50和>50标记的语句。
显然,本地化的语境对所有句子的长度都会产生类似或更好的结果,特别是对于非常长的句子:在这里,它达到了57.3%的F1得分,而当使用其他选项时,性能急剧下降到44.9/38.5%。

表4(中间)显示了一个具有多个实体的长句的例子:通过使用局部上下文,该模型正确地预测了三个定位关系,而依赖完整的上下文会导致许多错误的肯定关系,例如(“Jackson”,Located-in,“Colo”)。或(“怀俄语”,定位于“麦卡伦”)。这表明,将模型引导到输入句子的相关部分是至关重要的。
启示
1. 负采样为什么会提升性能?两个span之间的token作为关系,为什么?试验做的很好,但是没有把故事讲明白。
2. 计算每个token之间的span,这时间复杂度恐怕有点大啊!