SAP ABAP面向对象程序设计 1, 2 章
1.1 ABAP的特点
静态语言,强类型。
1.2 ABAP开发基础
在传统的ABAP开发中,最为常见的工作有以下几类:.
·报表开发,如ALV、LIST开发等。
·屏幕开发,如Dynpro开发等。
·单据打印,如SmartForms、Form、Adobe Form开发等。
·数据上载,如CATT、BDC开发等。
·数据接口,如IDOC、Proxy开发等。
·增强的应用,主要是对SAP标准流程进行一定的修改和定制化开发,比如User Exit、BAdI等。
·SAP Workflow(工作流)开发,定义特定的客户业务流程。
在S/4HANA平台上,还有其他开发业务,如HANA SQL Script存储过程的开发、SAPGateway OData的配置开发、CDS View的开发等。
1.2.1 ABAP SAP GUI

SE38, SE11, SE37, SE41,SE51,SE25, SE80
1.2.2 ABAP开发环境的设置
ADT是使用eclipse来进行开发。 先要有eclipse,后续操作参照SAP的文档来进行安装。
1.2.3 ABAP的语法结构
每条ABAP语句均以关键字开头,以实心句号(.)结束
ABAP的格式不是语法检查的一部分,缩进和排列没有严格要求,SE80中可以使用“Pretty Printer”(快捷键Shift+F1)来进行格式排版。
ABAP一行中可以编写多条语句,也可以一条语句跨几行。语句中的关键字和变量等必须用空格分开
1.2.4 ABAP的语法帮助
在SAP的编辑器SE80、SE38等环境中,选中SAP的关键字点击F1按钮,SAP会自动搜索并弹出ABAP帮助文档
·{}内是必选的内容。
·[]中是可选的内容。
·|是其左右的表达二选一。
·( )不是表达式,而是内容的一个部分,如长度表达式,动态变量也要用括弧括起来。
·<>也不是表达式,是内容的一个部分,如字段符号Field-Symbol。
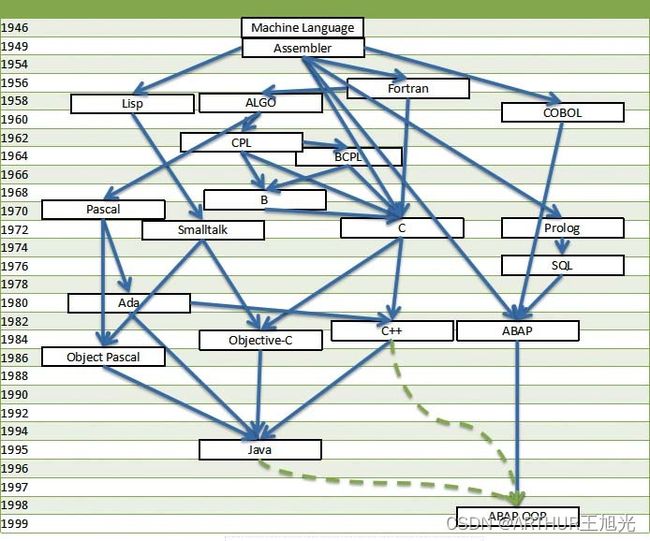
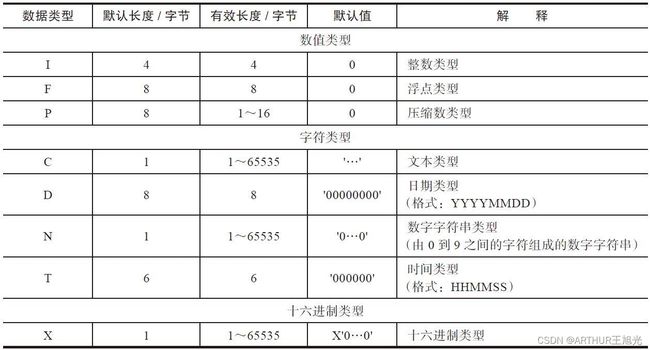
1.3ABAP数据类型
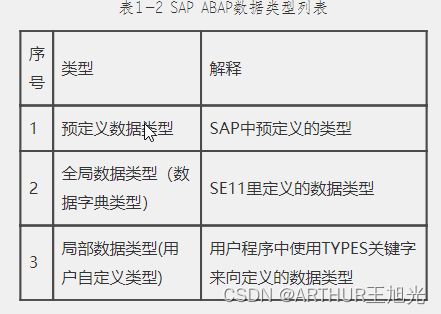
1.3.1 预定义数据类型

 1.3.2全局数据类型(数据字典类型)
1.3.2全局数据类型(数据字典类型)

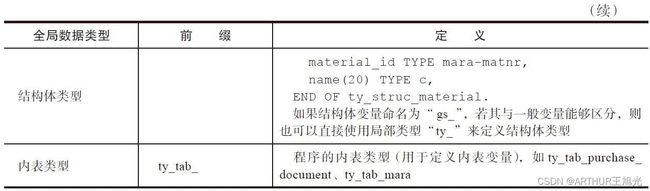
1.3.3 局部数据类型(用户自定义类型)
DATA、TYPES和TYPE的区别
DATA用来直接声明实际的变量,可以指定变量类型是预定义类型或者自定义类型。
TYPES用来自定义某种类型,定义的是类型而不是变量,需要再使用DATA语句来实例化变量。
TYPE用来指定类型的,当TYPE和DATA关键字一起使用时,则是用于定义变量的类型。当TYPE和TYPES关键字一起使用时,则是用于定义自定义类型。
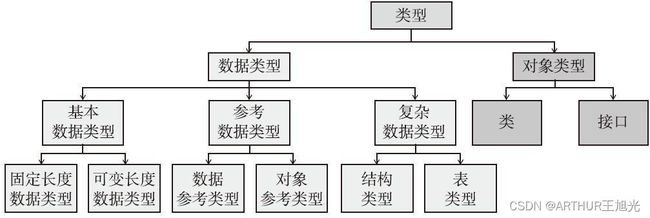
1.3.4 按结构区分的数据类型
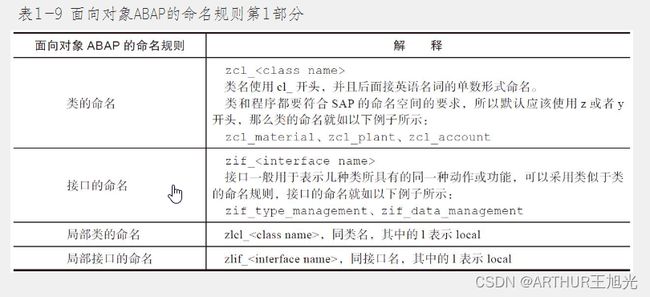
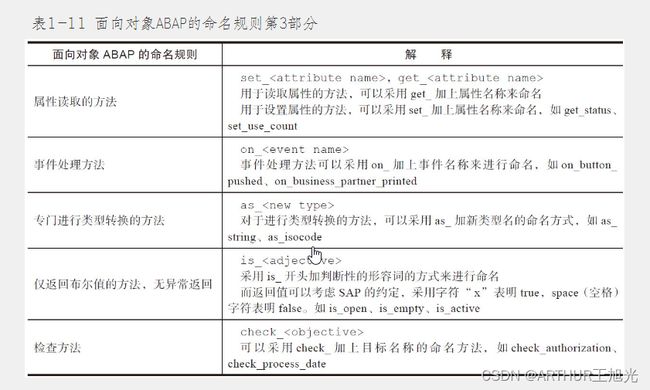
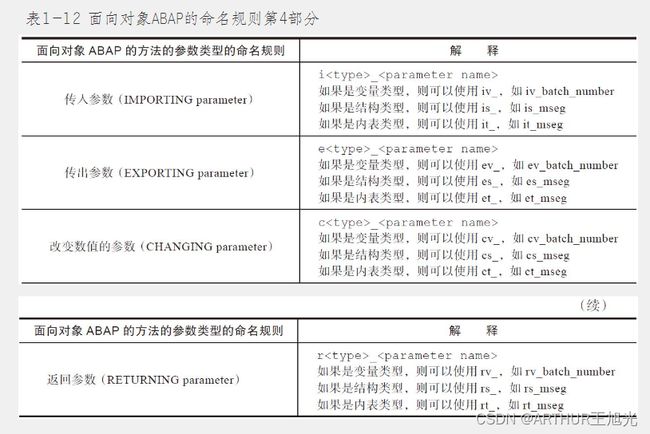
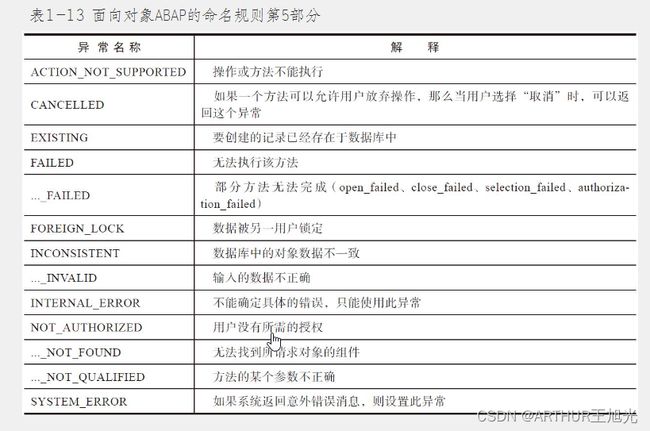
1.4 ABAP数据命名规则
1)使用英语术语作为变量的基本组成单位,而不是其他语言。
2)可以采用多个词汇复合的名称,用下划线(_)对命名进行分隔,如cl_company_code、get_inspection_result,而不是cl_companycode和getinspectionresult或者get-inspec-tion_result,长度不能超过SAP规定的30位。
3)代码格式可以考虑SAP的关键字大写,而其他变量和参数一律小写(可以通过设定编辑器属性来实现,以便于阅读)。
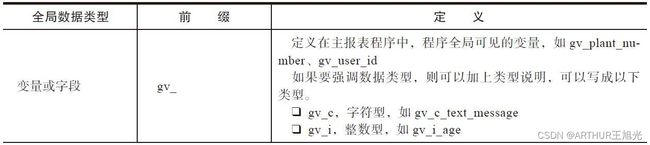
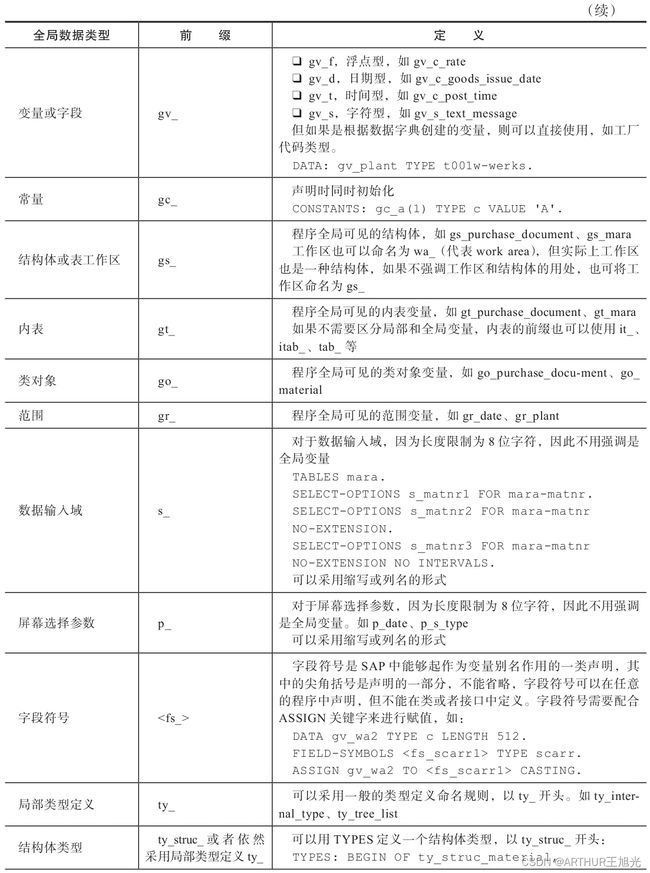
4)命名可以体现出作用域、变量类型、数据类型和变量含义,如“gvd_inspection_date”,其中的gvd,g表示Global,是指全局变量、v表示Variable,是指一般变量类型、d表示Date,是指数据类型为日期类型;inspection_date表示变量的含义是测试日期,命名中“d”是可选的,因为很多时候变量的含义已经代表了数据的类型,该变量也可以定义为“gv_inspection_date”。
5)对于SAP数据表的表列名或数据类型名,可以采用英文术语,而不是表的列名,比如局部变量“工厂号码”,可以使用lv_plant,而不是lv_werks;类属性“公司代码”采用mv_company_code而不是mv_bukrs。SAP表的列名源于德语的缩写(如刚才的werks和bukrs在德语中代表工厂和公司代码)。如果程序统一要求全部使用表列名,则也符合一贯制(如命名为lv_werks),但实际上除了工厂(werks)、公司代码(bukrs)、物料号码(matnr)等常用的一些列名,大多数的列名都是我们不熟悉的。并且鉴于德语的使用没有英语普遍(SAP系统源代码中的德语注释也常常被开发者抱怨),为了便于维护,一般还是建议采用英语作为变量,指向的数据类型则可以是列名,而不用再定义自己的变量类型(如“DATAgv_plant TYPE t001w-werks.”)。
6)如果是内表变量,并且指向的是具体的数据表,则可以考虑使用现有的数据表名(德语的缩写),比如使用全局内表名gt_ekpo(ekpo代表purchasing documentitem)或者采用局部内表名lt_mara(mara代表general material data),如果内表的列只是引用了SAP数据表的一部分或者内表定义的列来自于多个SAP的数据库表,我们可以用该内表变量定义的目的来命名该内表,如使用英语描述gt_stock_material_status(库存物料的状态)。
7)对于方法,应采用简明的命名规则,用于阐述作用或动作,而不是实现的细节,如采用print_order_detail(打印订单细节),而不是采用get_order_detail_and_print_to_spool(获得订单的详细数据并且打印到输出缓存)。
ABAP全局变量命名规则
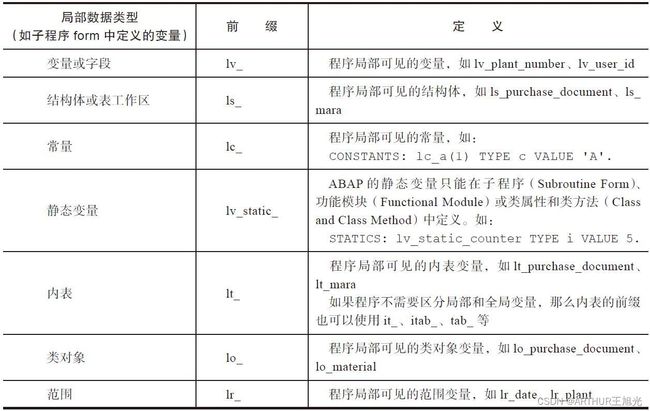
局部变量命名规则
1.4.3 面向对象变量的命名规则

第2章
ABAP语言关键知识点
2.1 ABAP的变量
2.1.1 变量的分类
BAP的变量可以分为普通变量、常量、静态变量三种类型,具体如下。
1.普通变量
ABAP中对变量的定义采用关键字DATA进行声明,采用关键字TYPE指定数据类型
普通变量的定义一般要遵循如下规则。
1)变量要遵循命名规则,分清作用域和变量类型。
2)ABAP中的变量必须先声明后使用,声明可以初始化值,但一般不必要在声明时就进行初始化。
3)对于变量每次只能赋一个值,但赋值次数不受限制,变量赋值时要注意类型的匹配和转换问题。
4)在同一个作用域中不能重复定义同名的变量
5)主程序和子程序的作用域不同,因此可以定义同名的变量,但这样会造成不可预知的错误,应采用正确的命名规则来避免出现这样的定义,如主程序可以使用全局命名规则“gv_”,子程序采用局部变量命名“lv_”。
6)程序的全局数据定义要集中放在一个include(包含程序)中,避免分散定义。
7)不要在循环中定义变量并初始化值,如果是全局变量,那么该初始化的值并不是随着循环每次都初始化的,如果一定要定义变量,那么请及时清理或修改变量的值。
2.常量
常量是指在程序运行过程中,其值不能发生改变的一种变量。ABAP中需要通过关键字CONSTA-NTS来声明定义常量。
3 静态变量
静态变量是指计算机程序中这样一类变量:在程序执行前系统就为其分配了存储空间,而在程序运行时不再改变其分配空间的一类变量。静态变量的值可以改变,但存储空间不变。
使用关键字STATICS在当前程序中声明静态变量,程序结束后将自动释放内存。
静态(局部)变量和普通局部变量的区别是生存周期不同,因为静态变量的存储方式能够保证静态变量一旦声明,它的生存期就能扩展到整个程序运行期间,其生命周期相当于全局变量。
静态局部变量只能被初始化一次,静态变量下一次的计算是依据上一次的结果值进行的。子程序中的静态局部变量可以保持上一次的赋值,但不能全局调用,其仅仅对声明自己的子程序负责,也只能在声明自己的子程序中被修改,这样就保证了数据的安全性。
子程序中的普通局部变量r每次调用子程序都会被重新初始化,不能保存上一次的值,仅能在子程序内部逻辑中使用。
全局变量gv_counter则可以全局保持上一次的值,并能全局调用,但任何子程序或者语句都能修改全局变量的值,误操作的概率较高。
静态(局部)变量具有以下特点。
1)有固定的使用范围,保证变量自身仅仅对定义自己的子程序或者功能模块负责,不会被其他子程序误调用。
2)有全局变量的生存周期,不会因为子程序调用完成而丢失了计算值。
静态变量后续会引出静态定义,静态定义在面向对象中有很大的作用,如类的静态属性、类的静态方法,它们也是一些设计模式中必须要用到的元素。
2.1.2 采用LIKE定义变量
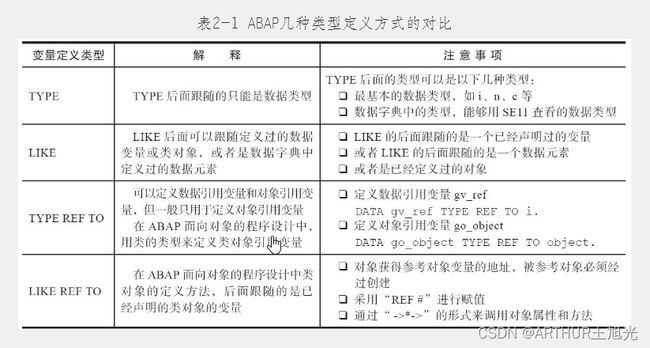
TYPE与LIKE的区别具体如下。
1)TYPE后面要跟随的是一个类型,TYPE后面可以接通用类型data,但不能接类的对象。
2)LIKE后面要跟随的是一个已经定义过了的变量或者对象,或者是数据字典中已经定义过了的数据元素。当需要声明一个新的数据变量或对象变量,且其与已经定义过了的变量或者对象具有同样类型时,才使用LIKE。
2.1.3 采用REF TO定义变量
TYPE REF TO定义一般用于对象的定义,而较少用作普通变量的定义,因为要使用数据引用变量,只能用“gv_ref->*”这种特殊引用形式(因为数据引用变量自身没有属性,所以用“*”来代表数据变量里面所有的内容),这也是我们一般不使用数据引用变量的原因。
对于对象变量go_object,还可以使用LIKE REF TO参考已经创建的对象,以创建新的对象变量go_object_l,需要采用“REF#”进行赋值,并通过“->*->”的形式来调用对象的属性和方法
2.1.4 变量的赋值
变量的赋值可以采用以下几种方式。
·用等于号(=)赋值(最为通用的赋值方式,可以为所有类型的数值变量赋值,可以为对象变量赋值)。
·用MOVE TO赋值(可以为所有类型的数值变量赋值,可以为对象变量赋值)。
·用WRITE TO赋值(不能为对象变量赋值,赋值双方变量的类型一定是以下几种类型之一:C、N、D、T。
·用MOVE-CORRESPONDING TO赋值(只对结构体或者内表起作用,如果不是结构体或内表,会返回错误“"LO_CLASS_LOCAL"is not a structure or an internal table.”)。
2.1.5 变量的动态传入
ABAP中使用括号运算符,形如(variable),也就是将变量用括号“()”括起来来动态分配变量,具体应用则有以下几种方式。
·分配变量到变量,如“WRITE(variable_name)TO variable.”。
·分配变量到字段符号,如“ASSIGN(variable_name)TO.”。
·采用SAP关键字SUBMIT(program_name)动态调用程序。
·采用SAP关键字CALL METHOD(meth_name)动态调用程序。
·采用SAP关键字CREATE OBJECT lo_product TYPE(lv_type_name)动态创建类对象实例。
2.2 内表
2.2.1 内表的定义和分类
1)当我们要从SAP的一个或多个系统表中读取较多的数据到ABAP程序中进行查询或匹配时,我们会先定义好内表,然后用SQL语句将这些数据一次性读取到内表中,而不是为每条记录单独调用SQL查询语句以查询数据库。
2)当程序中需要对数据进行计算和匹配时,一般都是采用内表来保存数据或计算结果,并且还可以调用内表的很多专用操作,以提高效率和正确性。
3)ABAP内置了大量的功能模块,BAPI和类方法都是以内表作为传输容器的。
在面向对象的ABAP中,自带表头的内表声明已经不再受支持了。
可以自动声明表头的初始化表的OCCURS关键字在面向对象的ABAP中也不再受支持了。


2.2.2 内表的操作
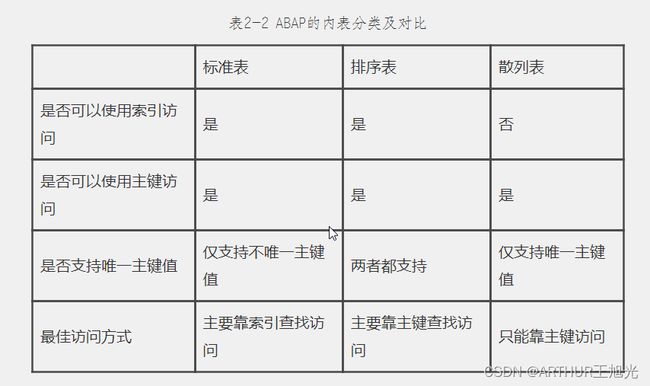
·标准表
标准表是一种索引表(Index Table)可以不指定KEY(即没有主键),或者指定不唯一的主键(NON-UNIQUE KEY),但不能指定唯一的主键(UNIQUE KEY)。
可以使用索引(INDEX)和主键(KEY)或者字段来查询标准表,但最常用的方式是用索引访问表。
标准表的特点是填充表的速度较快。若需要经常使用索引访问表,就选择标准表,标准表也是最常用的内表。
·排序表
排序表也是一种索引表,其与标准表的区别是排序表是按主键自动进行排序的,而标准表只能采用SORT来进行排序。
必须指定KEY作为排序参考字段,主键(Key)可以是唯一的或者是不唯一的。
排序表可以使用INDEX或KEY来查询。
排序表已经按照KEY排序,因此不可以再排序,如果需要经常使用键来访问数据,或者希望数据能够自动排序,就用排序表。
排序表可以采用二分查找(BINARY SEARCH)方法。
·散列表
与标准表和排序表不同,散列表不是一种索引表,散列表内部的标识记录的散列值是根据散列算法计算得出的,散列表可以提供快速的插入和查找操作。
散列表必须指定KEY,并且是UNIQUE KEY,不可以使用索引(INDEX)查询,只能使用主键(Key)查询。
查询散列表耗费的时间与表的记录数量无关,如果记录量非常大并且需要用主键访问,就可以考虑使用散列表。
1.标准表的创建
2.标准表的插入
1)用INSERT语句将结构体变量数据插入内表的最末尾一行。
关键字INSERT可以将单行加入内表中。如果内表设定了唯一的主键(UNIQUEKEY),那么当主键重复时,会返回系统号码“SY-SUBRC=4”,而不是系统崩溃;如果插入成功,则返回系统号码“SY-SUBRC=0”。
2)用APPEND将数据插入内表的最末尾一行,代码如下:
用INSERT向UNIQUE的排序表或散列表中插入重复的数据时,是不会抛出异常的,只是数据不能被添加入内表而已。
而采用APPEND插入重复的数据时,操作会抛出异常。
3)用“INSERT LINES OF”语句可以追加多条数据,可以将一个内表的数据追加到另外一个同结构的内表中
3.标准表的修改
1)采用MODIFY来修改内表中的一条记录
2)采用MODIFY TABLE FROM TRANSPORTING语句,来修改内表中的一条记录的指定字段。
3)采用MODIFY和条件语句WHERE修改内表中的多条记录(可指定修改字段)。
4.标准表的删除
1)采用“DELETE TABLE FROM{work area}”语句删除由工作区结构体指定的一条记录
2)采用“DELETE TABLE WHERE WITH TABLE KEY”语句,根据主键值删除指定的一条记录(只能用主键来指定记录,不可以用非主键来指定)。
3)用“ADJACENT DUPLICATE”语句删除重复记录,
4)采用DELETE WHERE语句,根据字段值按条件删除多条记录。
5.标准表的查询
1)按索引读取内表的一条记录
READ TABLE gt_flight INDEX 2 INTO gs_flight.
2)按主键值读取内表的一条记录。
DATA gv_flight_key1(40) TYPE c.
gv_flight_key1 = 'airline_id'.
READ TABLE gt_flight WITH TABLE KEY (gv_flight_key1) = 3 INTO gs_flight.
3)按字段值读取内表的一条记录。
READ TABLE gt_flight WITH KEY airline_id = 3 airline_name = 'Lufthansa' INTO gs_flight.
4)使用二分查找法读取内表的一条记录。
CLEAR gs_flight.READ TABLE gt_flight
WITH KEY airline_name = 'Alaska Airlines' flight_number = 920
INTO gs_flight BINARY SEARCH.
5) 通过secondary key 来提高查询性能
于大于50条记录的内表的查询,也可以使用辅助表键(Secondary Key)来提高查询性能,辅助表键是指在ABAP内表中对主键以外的键进行的索引排序,在定义和查询时使用关键字“WITH KEY key_nameCOMPONENTS”来定义索引和查询条件,可以在多次查询同一个内表时极大地提高查询速度。定义和查询内表的代码如下:
" 34)定义结构体类型,这就是内表的每一行的基本类型
TYPES: BEGIN OF ty_flight,
airline_id TYPE i,
airline_name TYPE scarr-carrname,
plane_type TYPE i,
END OF ty_flight."
35)带有Secondary Key SK 的内表的创建
DATA: gt_sflights_sk TYPE SORTED TABLE OF ty_flight
WITH UNIQUE KEY airline_id
WITH NON-UNIQUE SORTED KEY sk
COMPONENTS airline_name plane_type.
" 36)依照结构体类型,定义结构体工作区变量
DATA gs_sflights_sk TYPE ty_flight."
37)对内表采用Secondary Key来进行查询
READ TABLE gt_sflights_sk INTO gs_sflights_sk
WITH KEY sk COMPONENTS airline_name = 'Air Canada'
plane_type = 300.6.标准表的清空
(1)CLEAR的用法
(2)REFRESH的用法
(3)FREE的用法
delete 不会清除内存使用空间。
7.内表的赋值
1) move ... to ...
·MOVE gt_tab_source TO gt_tab_target.
·MOVE gt_flight_source[]TO gt_flight_target[].
2) move-corresponding ... to ...
MOVE-CORRESPONDING gt_flight_source TO gt_flight_source_detail.