手把手教你学python第二十四讲(Pycharm和Scrapy的安装和使用)
可能有的小伙伴有多个版本的python,我是没有那么闲的,如果你们有如何处理多个版本的python这样的困惑,可以去看看http://bbs.fishc.com/thread-58701-1-1.html。
Pycharm

IDE是集成开发环境(IDE,Integrated Development Environment )的意思。
安装和配置的过程呢,参考一下https://blog.csdn.net/yctjin/article/details/70307933?locationNum=11&fps=1就可以了。网站里讲的很细,没有什么可以补充的。当然上面的是英文版,如果你想要个中文版,到https://blog.csdn.net/qq_36918815/article/details/79137021去下载完到前一个网站去配置就可以了。download位置你应该不会找不到。
一般我们都会习惯把背景设为黑的,如果你一开始错过了设置背景的颜色,那么还可以这样做。

如果你们选择了中文版的,那么设置空白符和字体的步骤如下,我是喜欢20号的,你们按照自己喜好来。

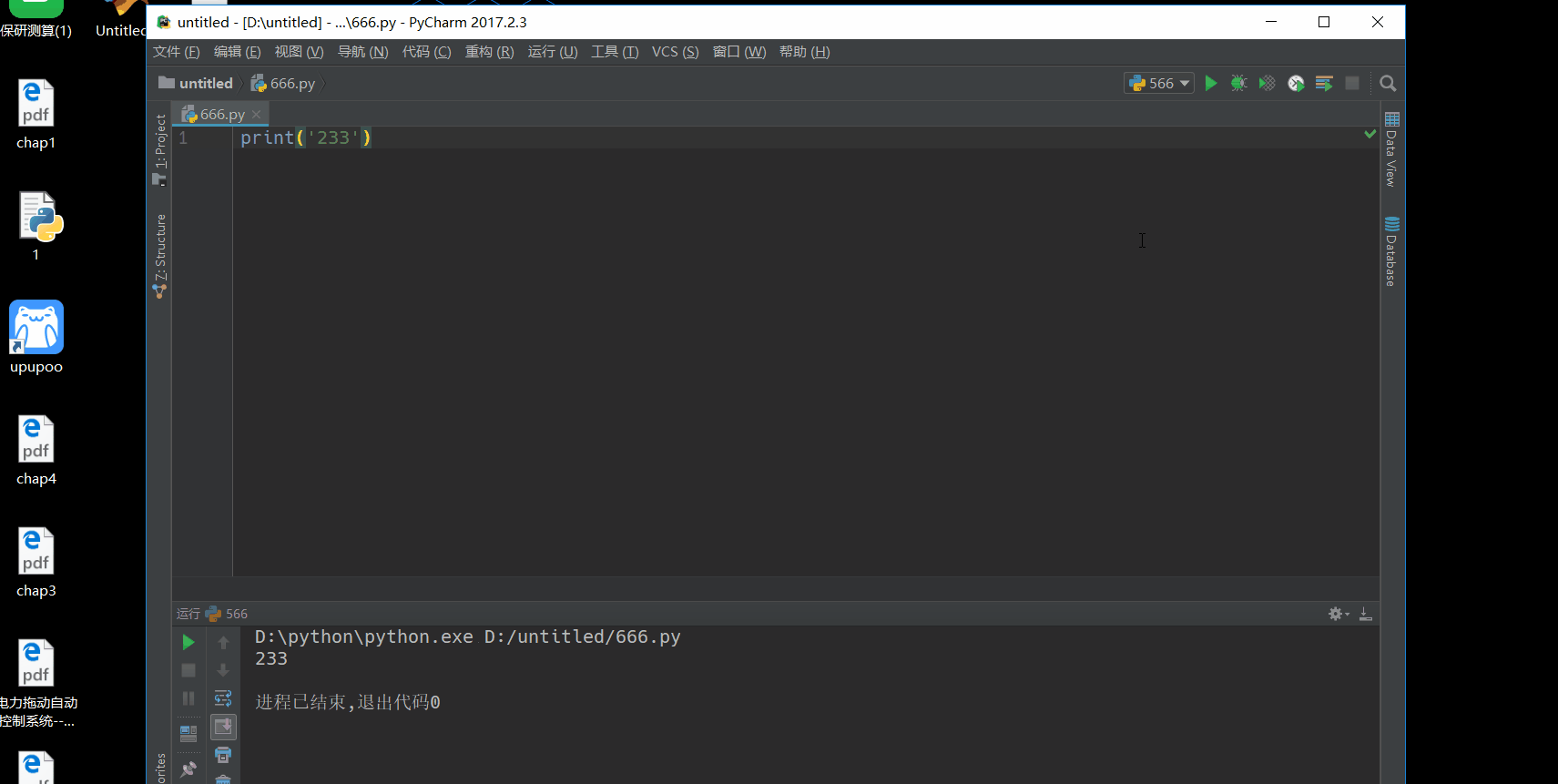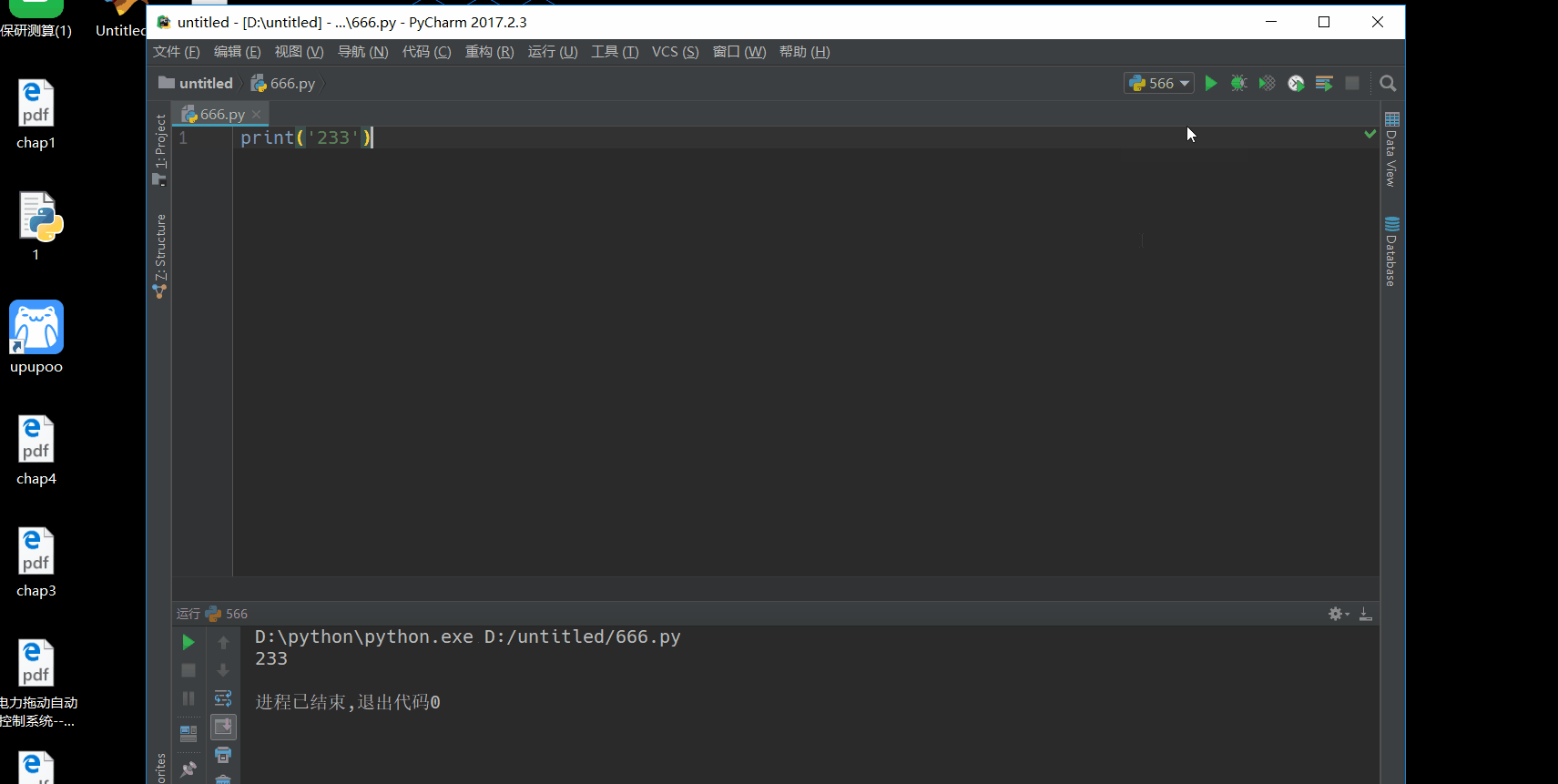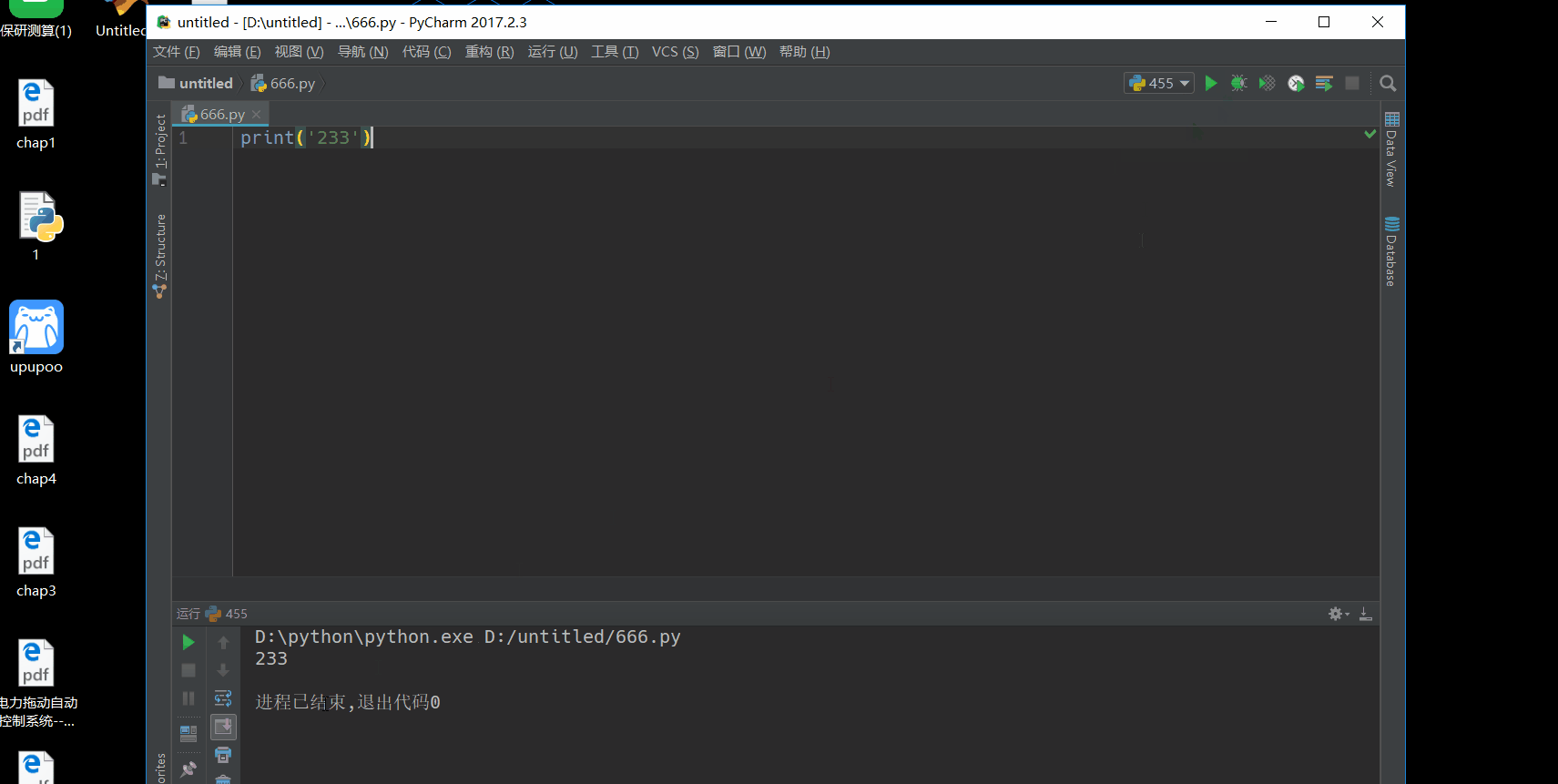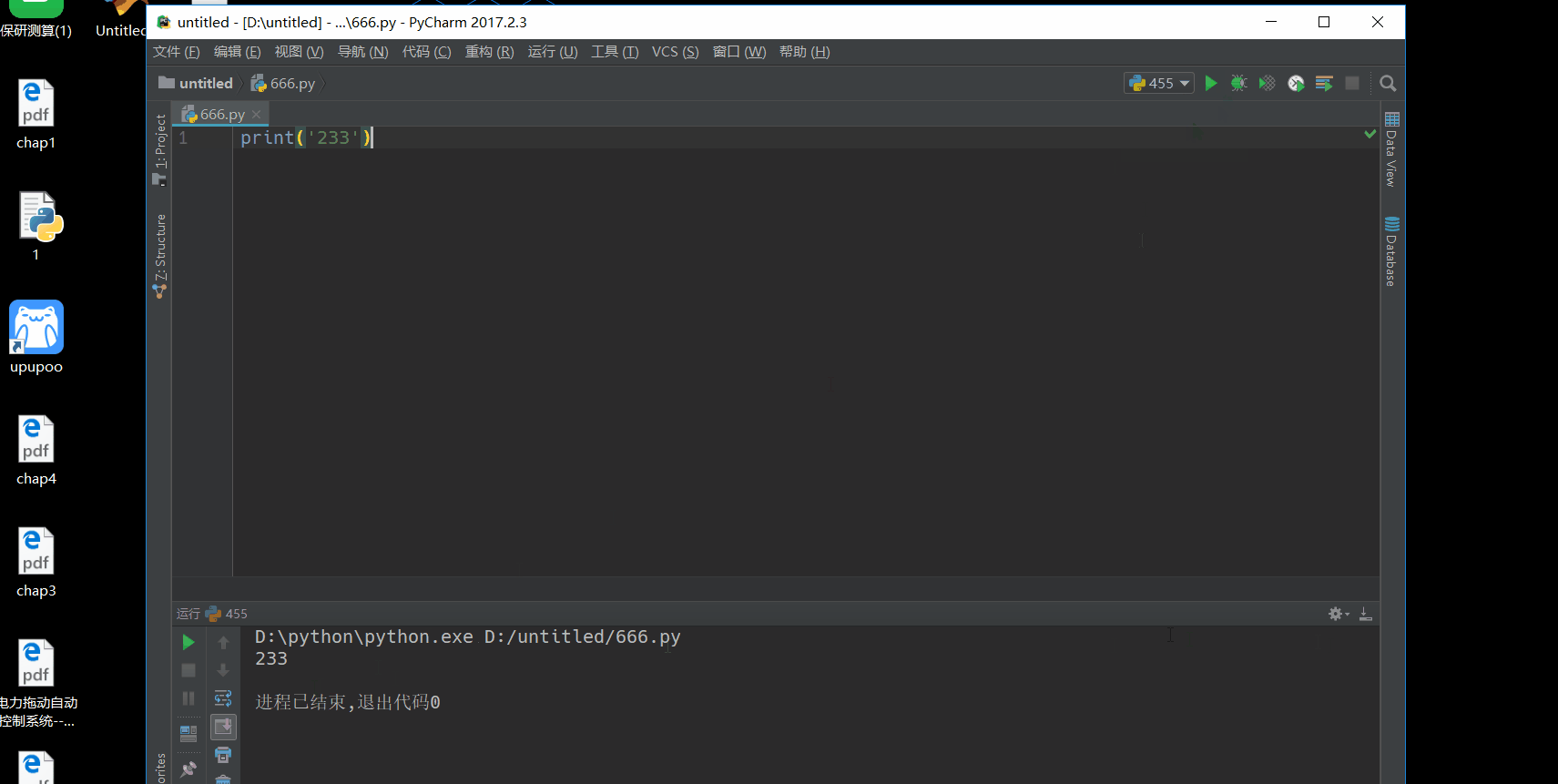
如何新建一个工程和python文件呢?要注意创建文件的时候是在左上角的工程那里右键的。
那么如何运行py文件呢?在下面你还看到左边是有行号的。
那个名称是可以随便取的。如果你以前已经添加过这个py文件,那么可以直接在下拉菜单里选,但是这个就要注意这个名称最好还是和py文件的名字一样。还记得上面我们的名称里填的就是455对吧。选455就会运行出上面的结果了。
下面呢简单说一下

控制台和ternminal。控制台就相当于IDLE,就是我们前面一直用的,ternminal就是DOS的命令行。

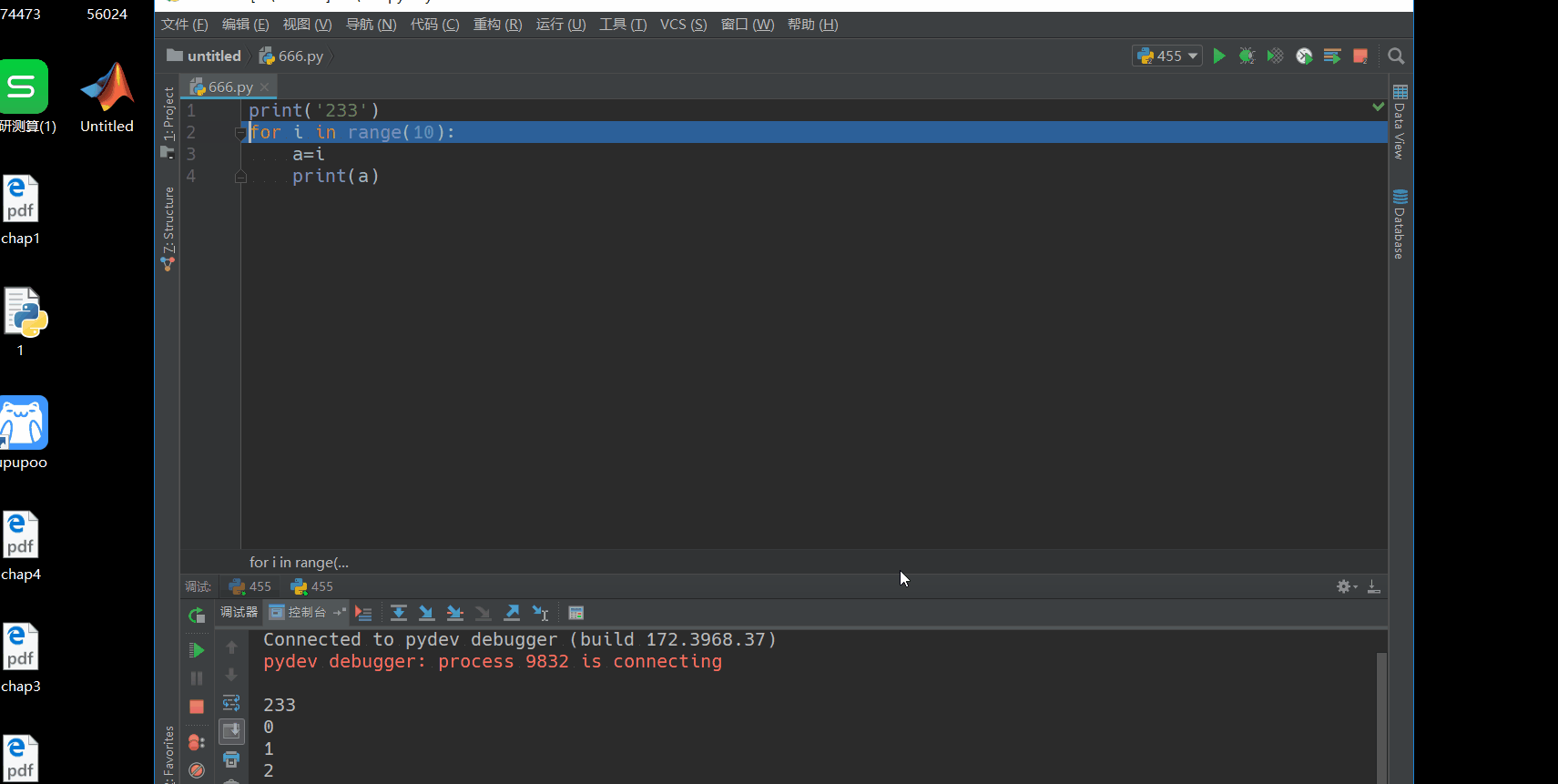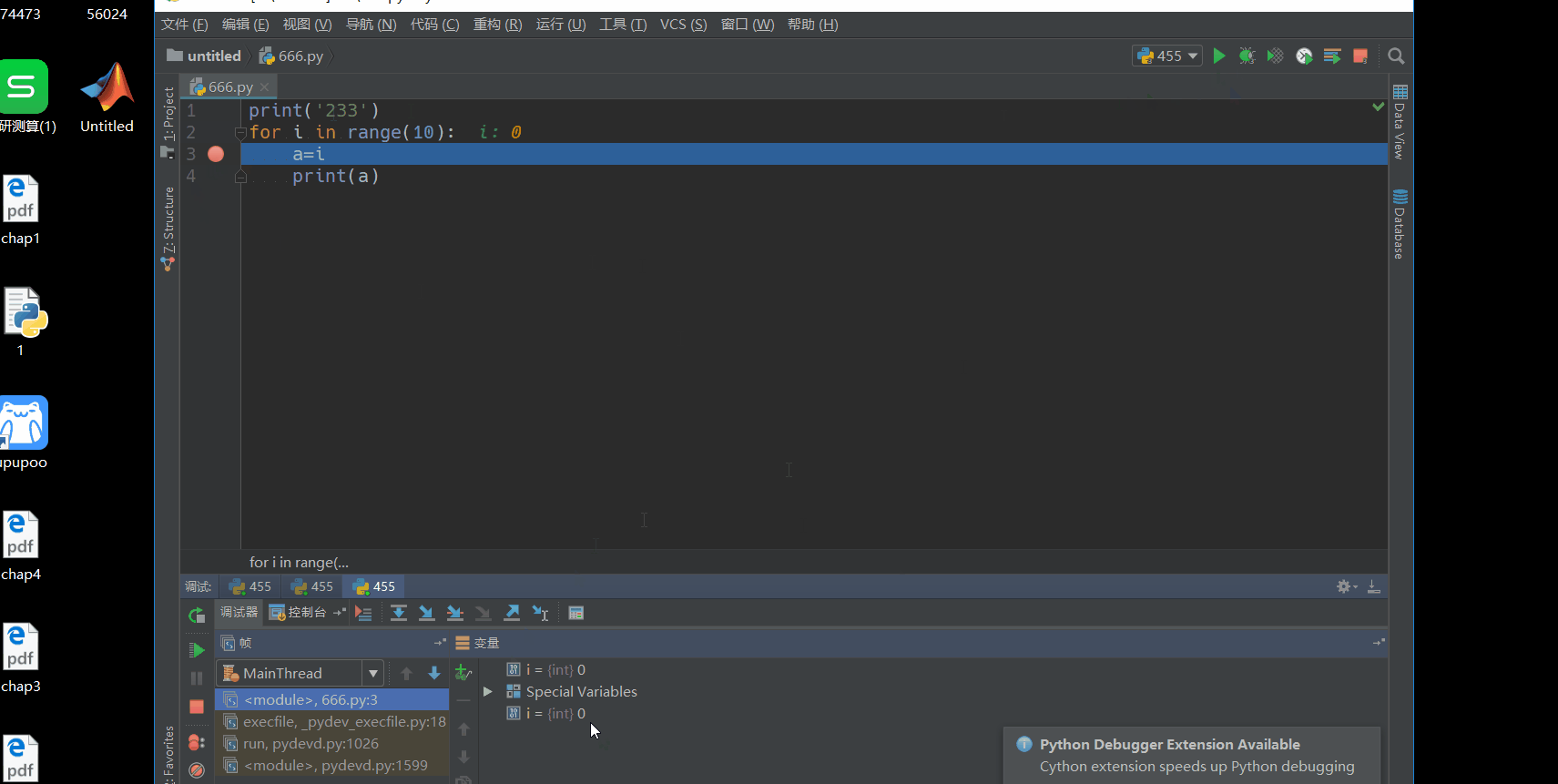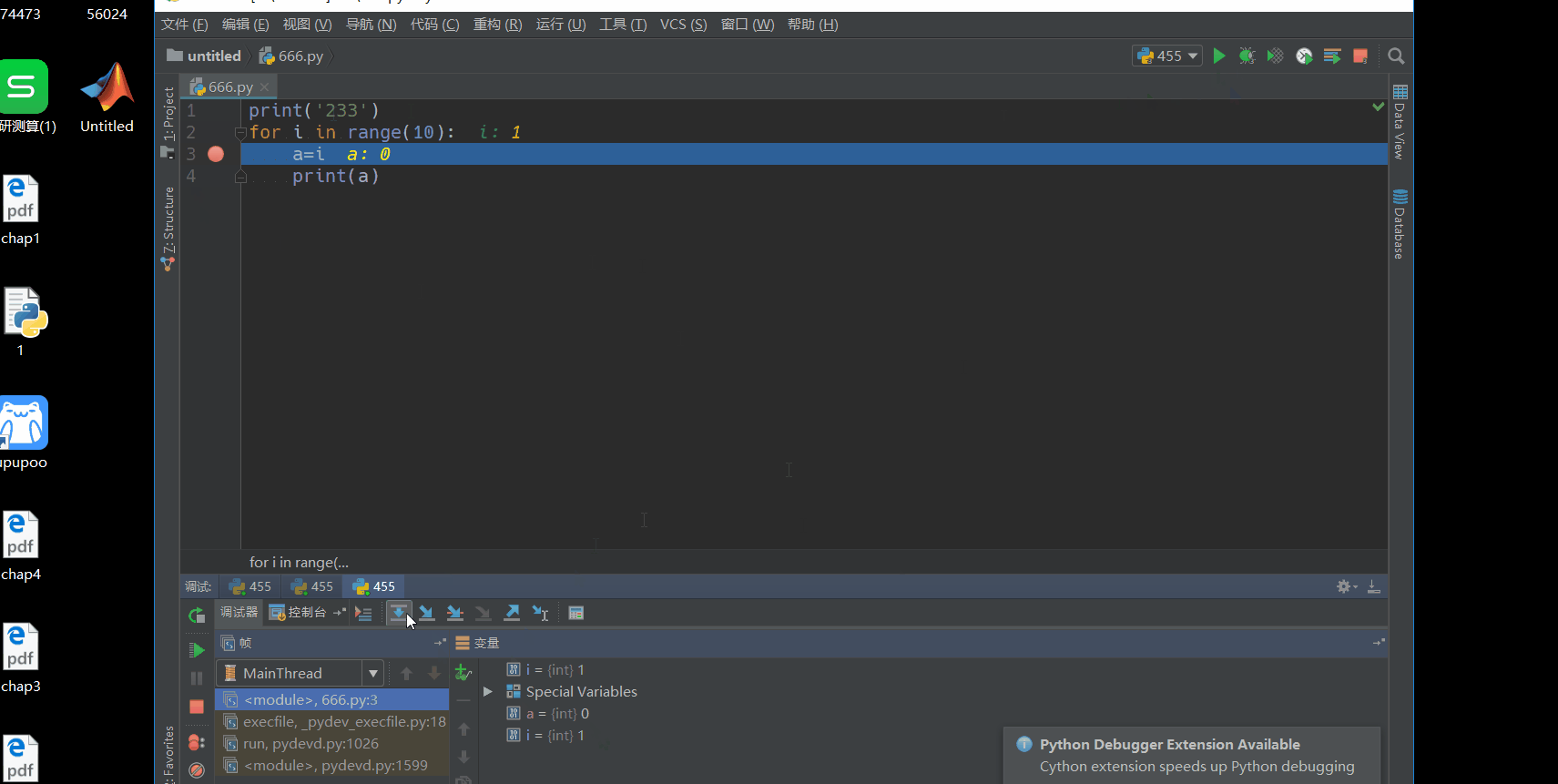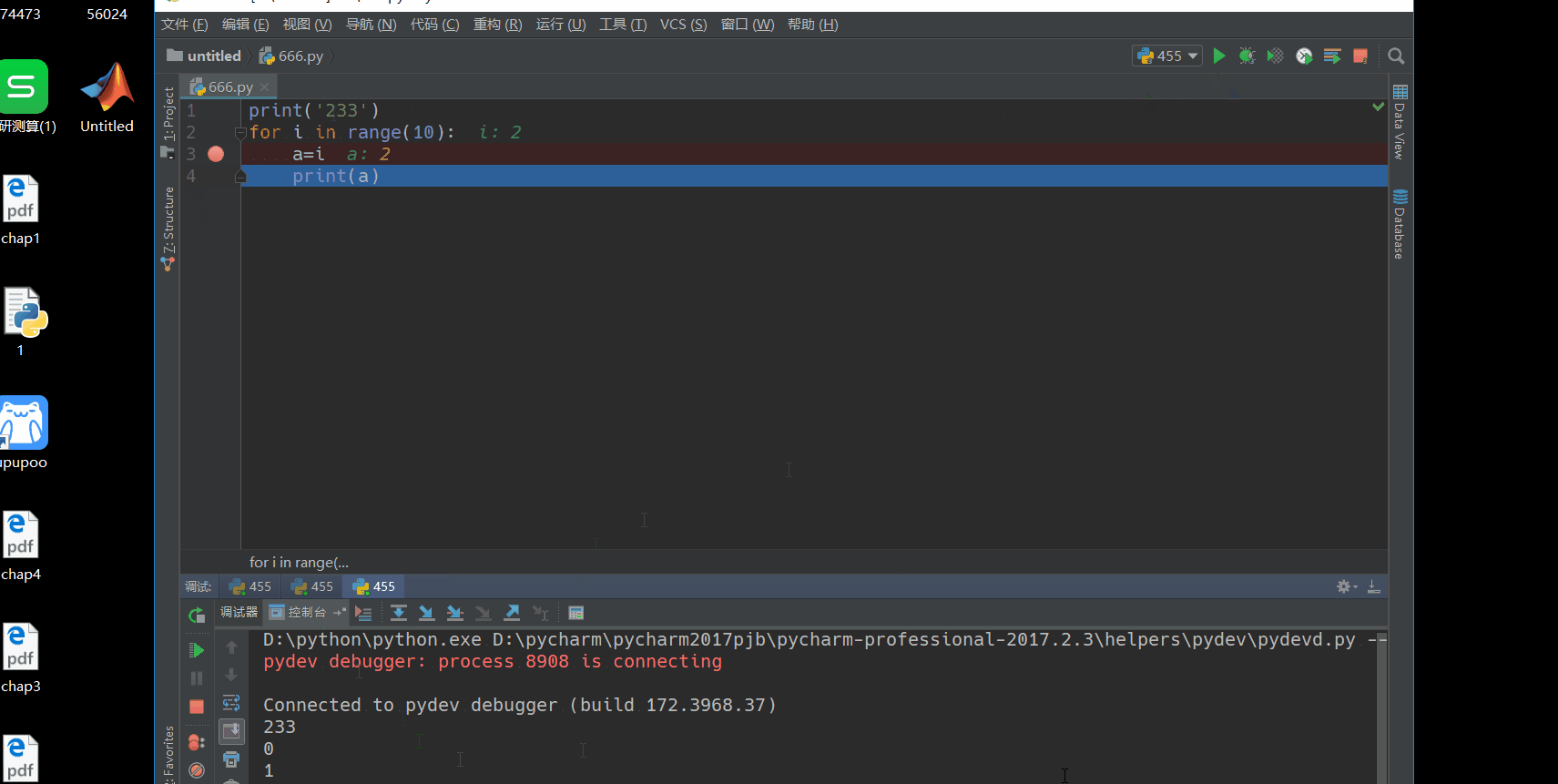
下面看一下pycharm的调试功能,用一个简单的循环语句来实现。调试需要设置断点,左击一下就会出现断点了。然后点运行右边的调试,就会运行到断点,可以看到第一次变量区是没有a的,说明a=i这一句没有被执行,然后点单步运行,就会看到i和a是会有变化的。
当然py的编辑器也不止一种,还有vscode,sublime等编辑器。可以参考https://www.cnblogs.com/sanzangTst/p/7282154.html。
Scrapy
scrapy的用处
安装scrapy还是不容易的,如果你直接pip install scrapy是会报错的,因为其实前面需要装lxml(已经装过)和twisted,但是。。。。。enmmm直接看看结果吧,都会出错的。
那么就得回到我们安装lxml时候的方法了,到https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted下载对应的whl,这个必须是对应的
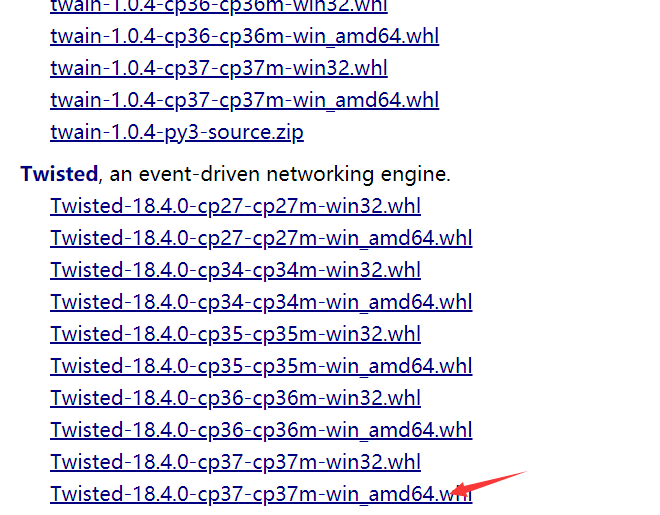
下载好之后,进入下载的文件夹,按住shift键,然后再空白处右键,按下面的操作。
安装在了这里
其实是没问题的,因为T不应该大写的。
下面安装scrapy。https://www.lfd.uci.edu/~gohlke/pythonlibs/#scrapy
一样的操作。最后仍然会有一个错误

那么其实呢scrapy前面需要安装的有这么多
亲测pywin32是可以直接pip install安装的。

但是其实你只要仔细看看就会发现远远不止的。下面每一个地方出现了collecting都是一个第三方的模块。那么可以自己去找在哪一个模块的地方被卡住了。
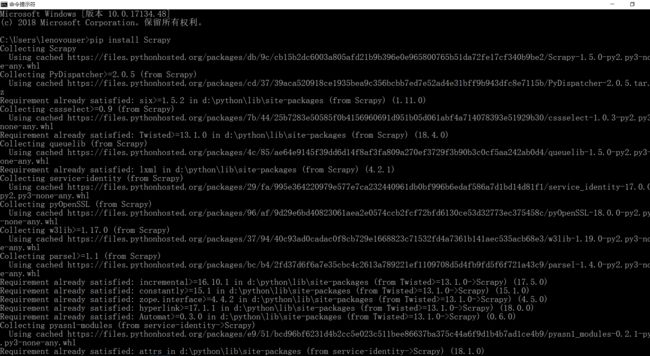
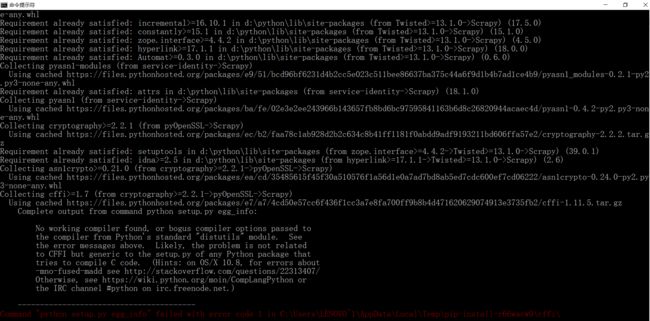
发现是cffi这个模块。那么我们到https://www.lfd.uci.edu/~gohlke/pythonlibs/#cffi去搞定这个东西。

然后又出现了茬子。enmmmmmm........好吧,我决定使用一种原始的方法。我们原来不用pip安装的一种方法。到后面的网址下载scrapy,https://scrapy.org/download/。然后解压,在设置了python环境变量的前提下,在cmd里把目录切换到scrapy的解压目录的setup.py所在的文件夹。然后输入python setup.py install即可成功安装了。安装的过程应该是下面这样子的。
是不是想打人呢?我这里只是为了提醒你们不要忘了这种原始的安装方式,只是多了几个dos命令就可以更稳妥的安装,这样的效率反而比pip快。
但是即便是这样,还是会有问题,因为如果安装成功的话,在命令行里直接打scrapy是会有反应的,具体会有什么反应,下面会看到。所以推荐的安装其实是直接下一个Anacoda,直接到官网下就行https://www.anaconda.com/download/。这里我先提醒一下Anocoda因为库很多嘛,还是很大的(2.81G),我是做项目要用很多科学包,如果你不想占用太大空间,我建议你下个python3.6直接安装scrapy试试,参考视频https://www.bilibili.com/video/av24028845/index_22.html?t=599。

windows直接安装麻烦就麻烦在依赖环境的安装,安装不全就会一直报错,前面我的依赖库其实是全的,但是还是不行,可能是因为python3.7测试版目前还是有点问题,或者是pyopenssl18.0版本的问题,总之就是python和依赖库版本的兼容问题。Anacoda默认的安装包就有很多https://baike.baidu.com/item/anaconda/20407441?fr=aladdin,这就让你安装scrapy变的简单了。当然安装完了之后还要有环境变量的配置。
这样配置完了以后电脑可能需要重启在命令行里输conda才会有反应。
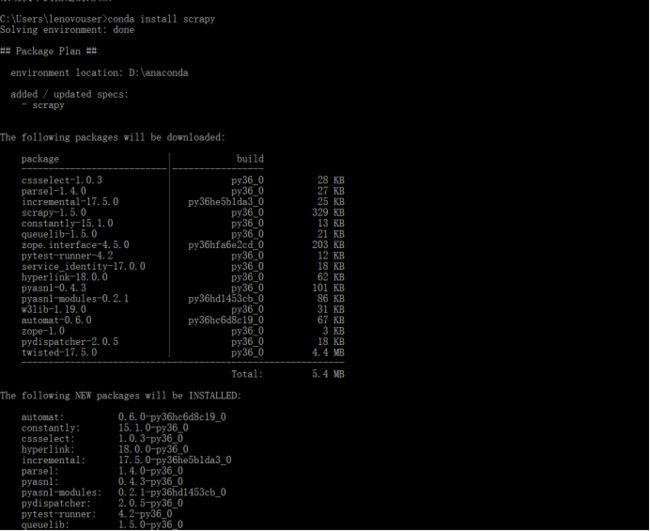
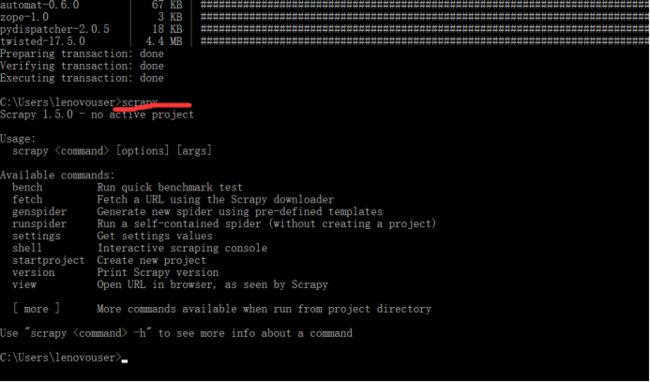
配置完了以后就可以用conda install scrapy直接安装,安装完成以后再命令行直接输入scrapy会有反应。

anaconda是没有直接下python的那个白色的IDLE的,但是也有编辑器,Spyder就是自带的一个编辑器,不过我还是选择pycharm。安装好了以后,下面来学习一下scrapy吧。有的小伙伴可能会说,我已经会了爬虫了,为什么还要学scrapy呢?这就好比田忌赛马,齐王的马质量都比田忌高,但是不懂得策略,所以最后输给了田忌,因为呢,学习scrapy框架还是很有必要的。

我们先来学习一个scrapy的组件机及其之间的交互,其中绿色的部分就是数据流,所谓数据流,按字面意思理解即可。
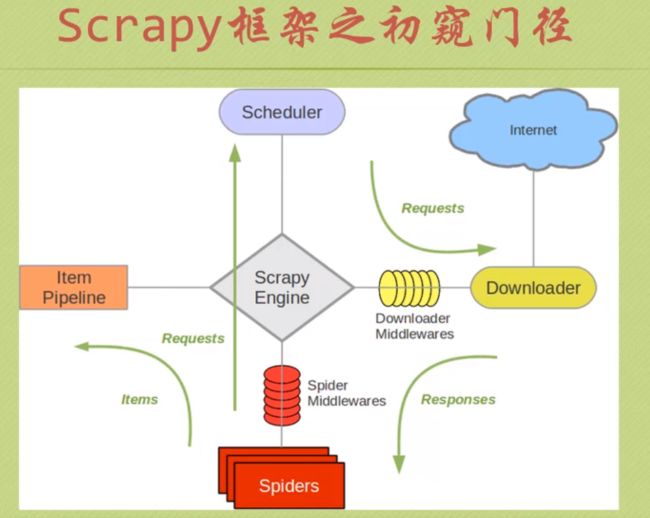
这里面有几个部件,Scrapy Engine是Scrapy的核心,就像汽车引擎是汽车最重要的部分,在图中可以看到,所有的数据流都经过它。Downloader是下载器,Spider就是爬虫咯,Scheduler就是调度器,Item Pipeline是容器传输,爬取网页的过程是这样的,spider经过引擎向调度器发送请求,然后经过调度(可能会有多线程的需求)再发送请求给下载器下载,然后将服务器返回的内容再给到爬虫,然后把items送到Item pipeline去处理。其中还有两个中间件,这里面是你可以自己扩充代码的,可以实现一些过滤信息的功能。下面就来实际操作一下。
第一步,创建一个scrapy的项目。
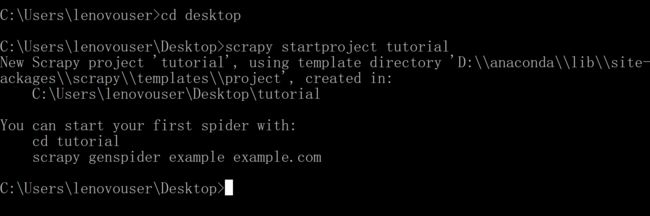
我上面创建的这个项目是在桌面,名字叫做tutorial。运行上面的命令就会看到下面的结果。
tutorial 的组成如下(这是比较老的版本了,新版本会多一些东西)

新版本的:
scrapy.cfg是一个配置文件,现在我们不需要动它。pycache可以参看https://blog.csdn.net/qq_21033779/article/details/78283796。tutorial文件夹里存的都是我们的代码,items是我们要定义的容器,参看第二步,还有pipelines就是item pipelines的代码,spider呢就是我们的爬虫了,middlewares里是中间件的代码,settings是一些设置。
第二步是定义item容器。

我们就先来定要爬取的内容,我们一般是到http://www.dmoztools.net/去找内容爬。我下面要爬的是http://www.dmoztools.net/Computers/Programming/Languages/Python/Resources/和http://www.dmoztools.net/Computers/Programming/Languages/Python/Books/里链接的标题,url和简介。

那么我们就要在items类里面定义这三个属性。这里说一下由于没有IDLE,打开是要用别的东西打开的,可以用pycharm,vscode或者Spyder,我是用了vscode,因为它比较快。
我们改了一下类的名字为dmoztools。至于后面为什么是scrapy.Field(),这牵扯到更为深入的内容,认为是一种固定格式就可以。
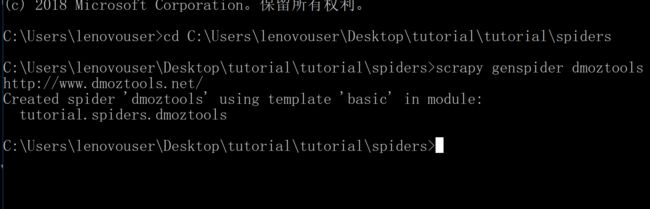
第三步:编写爬虫。

我们在spider文件夹下新建一个新的py文件,我先来演示,然后再解释。参考了http://www.scrapyd.cn/jiaocheng/148.html。
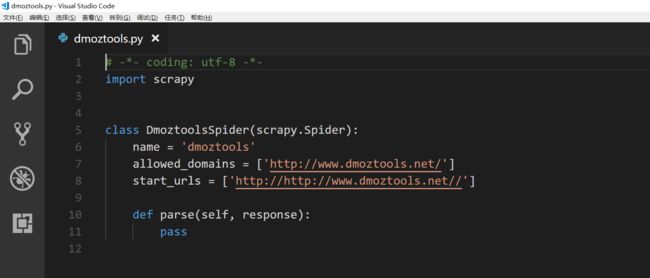
其中的name是唯一的爬虫的名字,allowed_domains是限定的网址,就是如果遇到超链接的时候,也不会跳到其它网址去,这是为了防止无限递归。start_urls就是开始爬取的网址,这里我们修改一下。
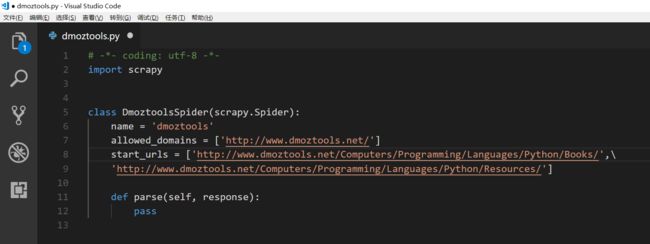
上面的代码所代表的过程是从Spider经过引擎向调度器发送requests的过程。下面的parse就是我们要分析的一个方法,它是接受从下载器发送过来的response的,并且进行分析处理,提取成为items也是在这一步完成的,提取完成的items送给items pipeline处理。下面我们会逐个尝试。先尝试下面的处理,保存到文件夹里:

在命令行里运行一下(注意先切到工程的目录下):
dmoztools就是我们上面写的爬虫类里面的name。
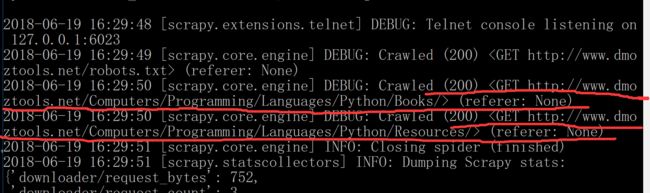
可以看到结果里有200的HTTP状态码,说明是成功的。并且在文件夹里已经生成了这两个文件,打开之后其实是那两个网站的代码。
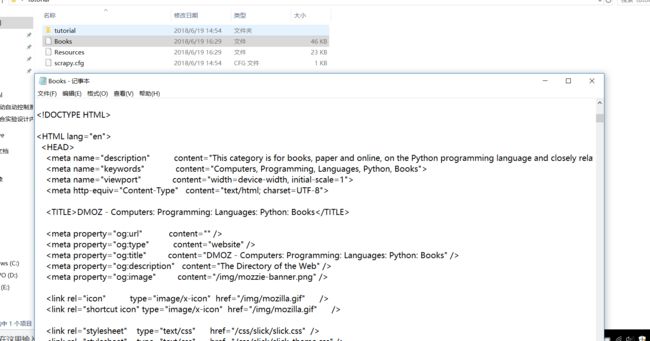
目前我们只是完成了爬的部分,还没有取出我们所想要的信息,取信息前面我们学过beautiful soup和re,但是在scrapy中其实用的是lxml。


学过beautifulsoup的可以很快的理解上面的内容,只是scrapy里的形式不一样而已。
我们先踩点。
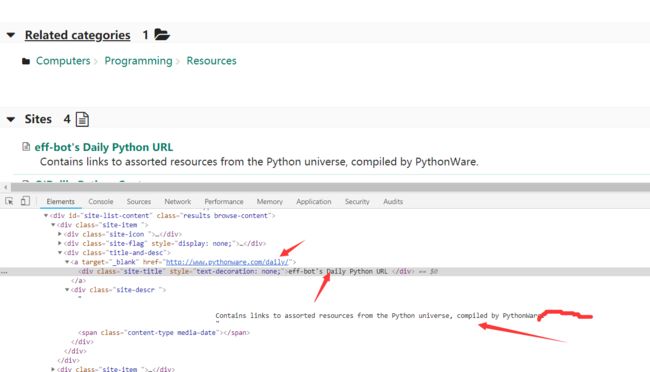
踩完点之后,我们先来试试是不是我们想要信息的唯一特征。怎么试呢?我们用scrapy shell去试。


下面先用xpath试一试。下面是xpath的一些格式,不过下面就会看到由于谷歌有一个copy xpath的功能,会给我们带来很多方便,这也是我在这里不用正则和前面的beautifulsoup的原因,当然你可以用正则表达式和bs4。

但是呢?用谷歌的copy xpath不是意味着就不用动脑子了。下面就会看到一系列的问题,如果你不动脑的话。
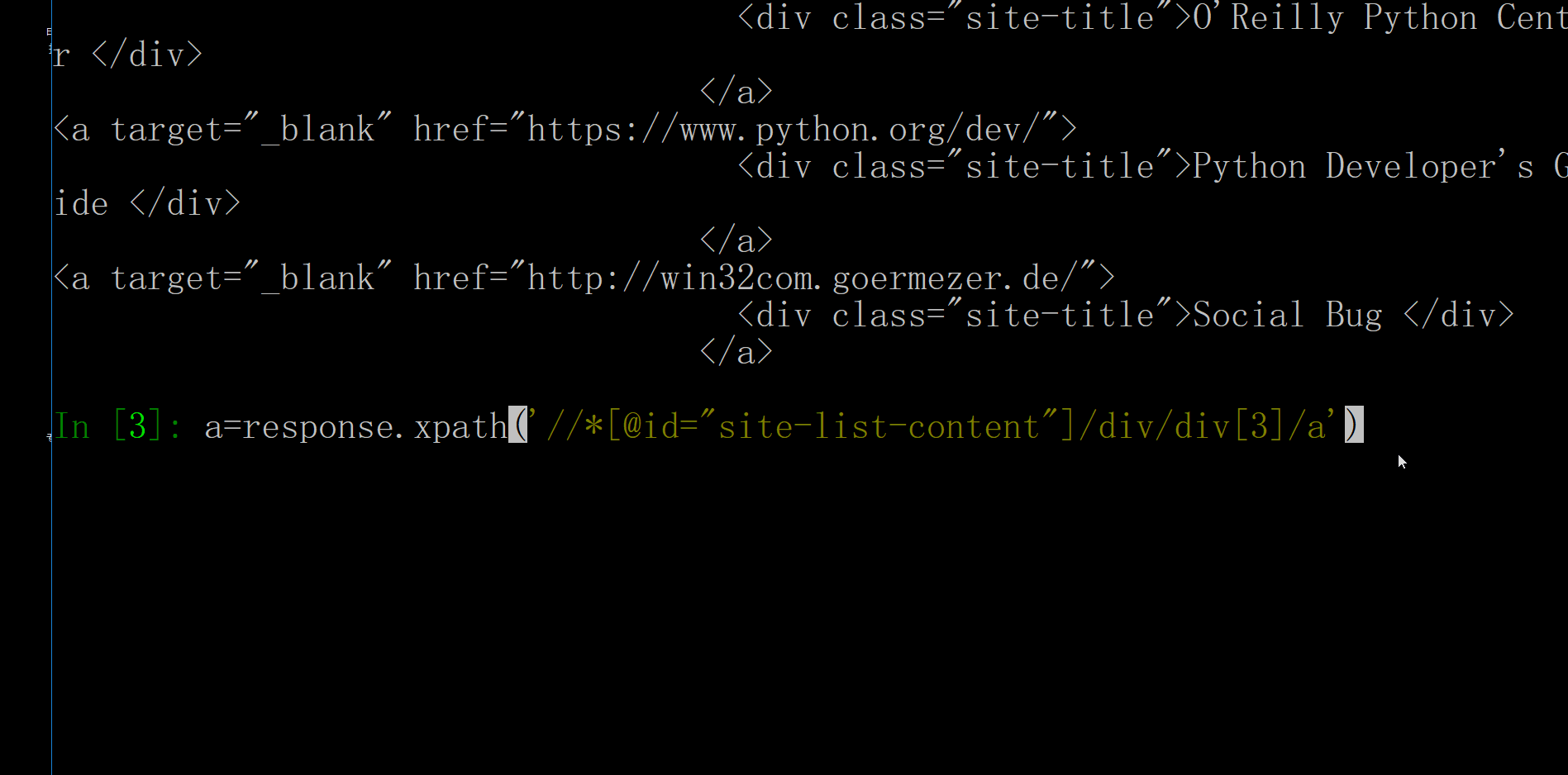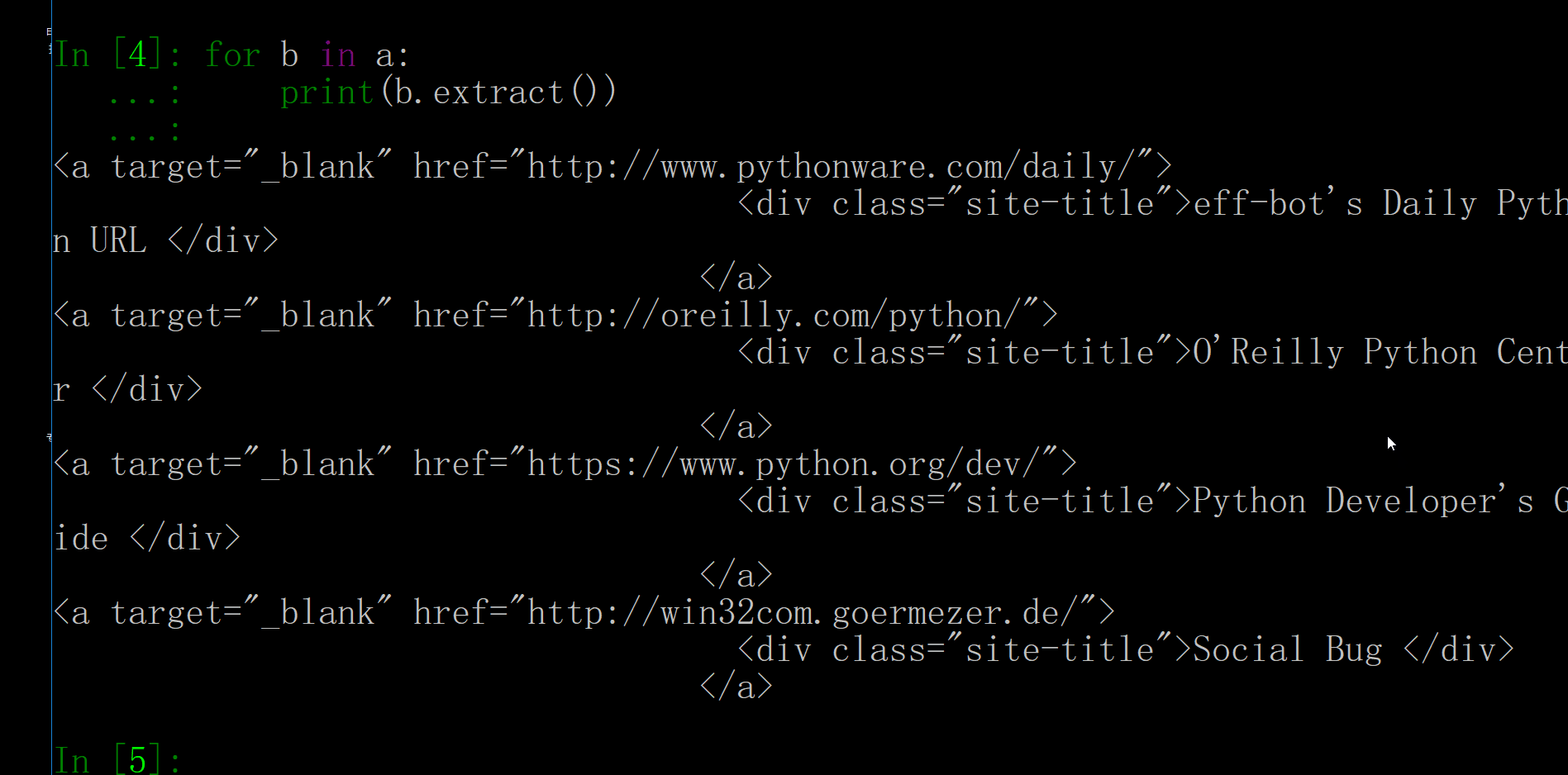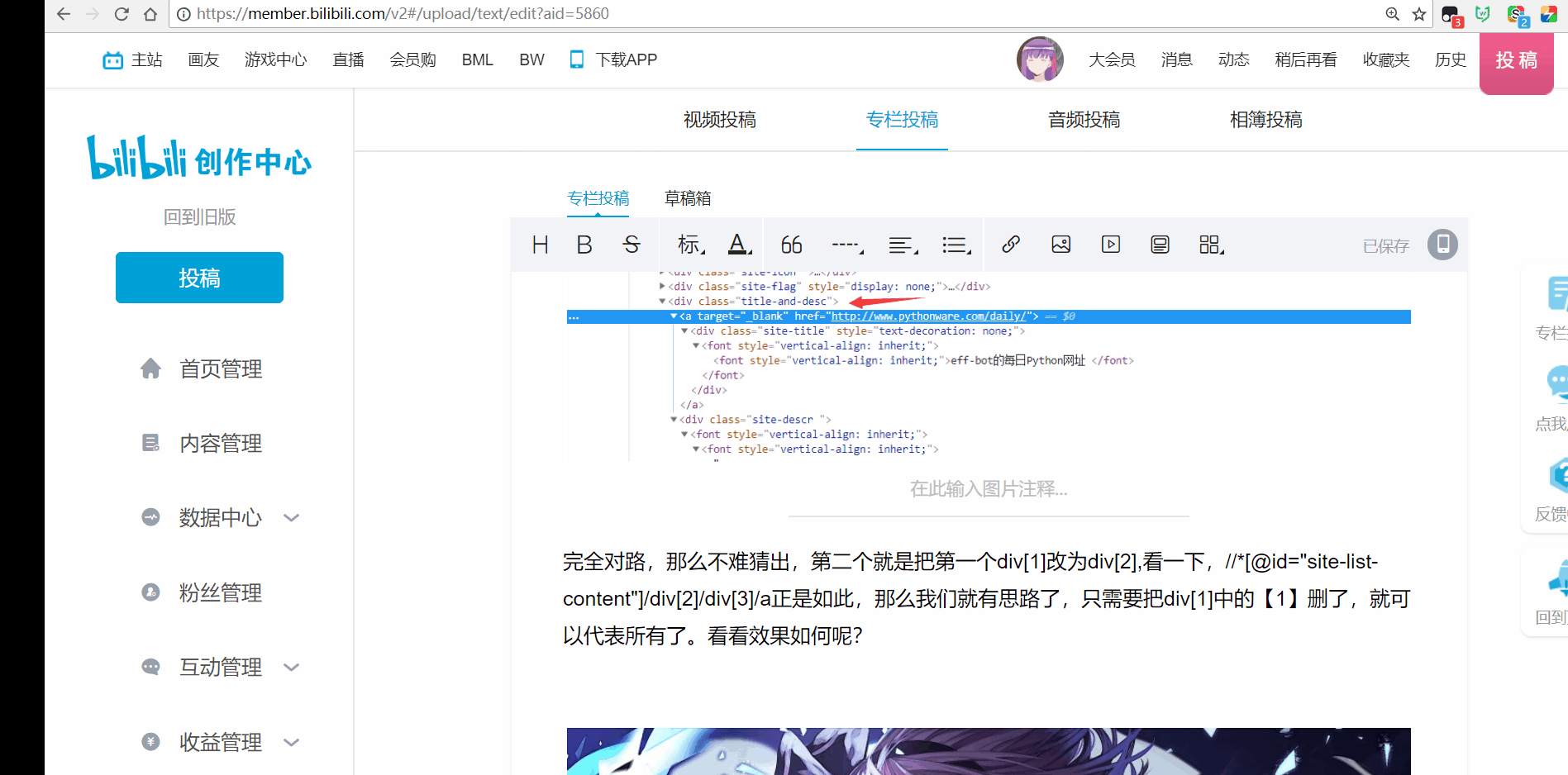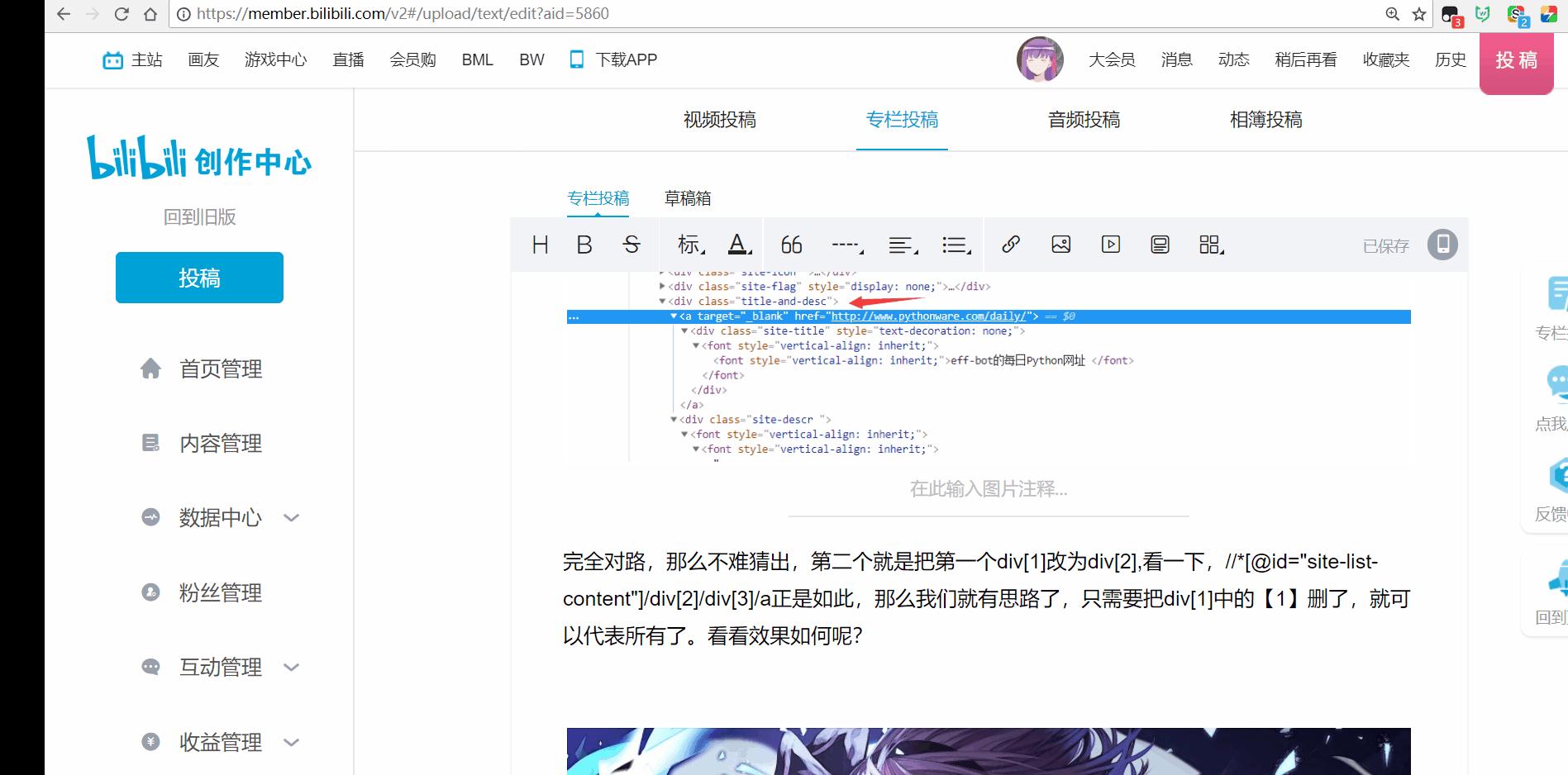
你会发现我上面那种直接拷贝的xpath只是针对某一个具体的链接,而不是一种通用的方法,你需要去自己找到一种通用的方法。还是要靠自己动一些脑子才可以。下面就来稍微看一下赋复制过来的xpath,第一个是//*[@id="site-list-content"]/div[1]/div[3]/a,其中*表示通配符,所有,[@id="site-list-content"]表示的是id这个属性是site-list-content"的类,合起来就是id属性是site-list-content"的所有类,div[1]表示的是第一个子标签,div[3]是第三个,/a是a标签,我们来具体看一下。
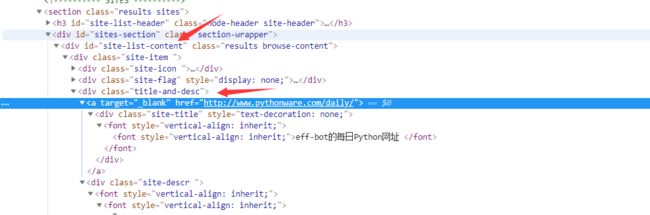
完全对路,那么不难猜出,第二个就是把第一个div[1]改为div[2],看一下,//*[@id="site-list-content"]/div[2]/div[3]/a正是如此,那么我们就有思路了,只需要把div[1]中的【1】删了,就可以代表所有了。看看效果如何呢?
嗯,事实证明效果可以。那么继续,
这里面的text()bs4差不多,@href就是选中href属性,并返回值。上面是懒人的办法,我们自己完全可以写出更高效的代码,我们完全可以直用一个循环。
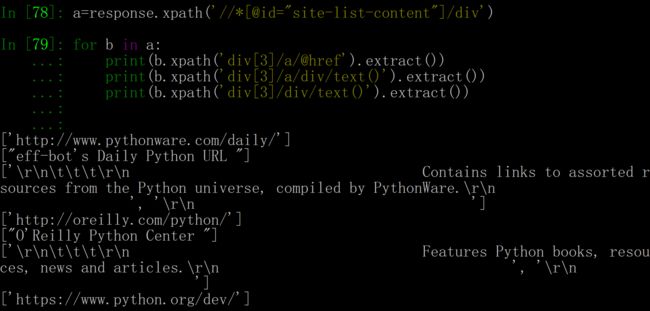

这里需要注意的是,b.xpath()括号里不需要以\\开头,不然你会把结果打四遍(形式不一样),总是是错的。下一步就是去spider里面修改代码,我下面修改代码直接把装进容器这一步也加进去了。在命令行里右键就是复制。

然后继续爬取,注意一定要切换到工程目录下或者直接在该目录下操作。
存储比较简单,
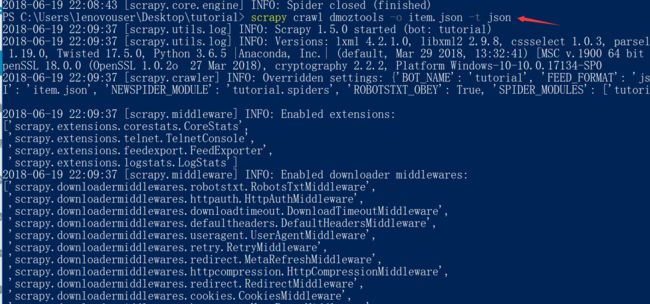
这里的-o代表输出,后面是文件名,-t是输出的格式,json是一种格式,以前我们是见过这种格式的。这一讲我们主要介绍了pycharm的配置和scrapy的简单案例。下一讲将会是tkinter。