数据结构:链表(一)单向链表的实现及应用
目录
一、链表的分类
二、无头单向非循环链表
三、链表的实现
3.1链表的创建
3.2动态申请一个结点
3.3单链表打印
3.4单链表尾插(及传参二级指针的原因)
3.5单链表头插
3.6单链表的尾删
3.7单链表头删
3.8单链表查找
3.9.1单链表指定位置插入
3.9.2单链表指定位置后插入
四、单链表拓展
一、链表的分类
实际中链表的结构非常的多样,以下的情况组合起来就有8种链表结构。

2.带头链表或不带头
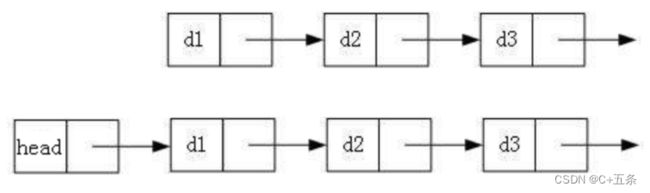
3.循环或非循环
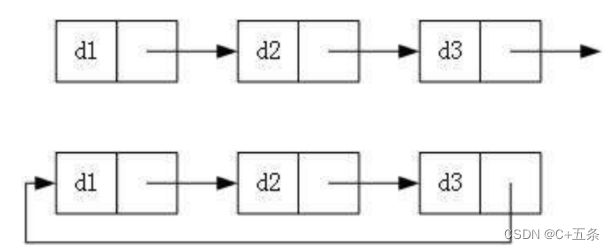
虽然链表的种类非常的繁多,但在日常实际使用时,我们最常使用的还是无头单向链表和带头循环双向链表这两种结构:
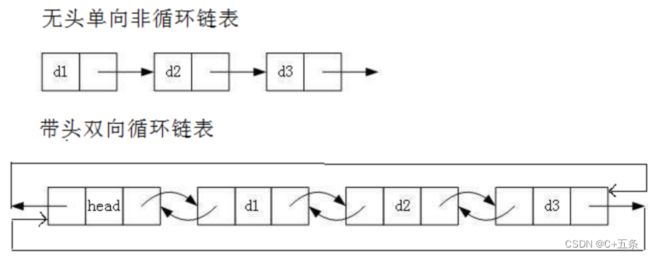
而作为数据结构章节的开篇,本文主要围绕更易理解和上手实现的无头单向非循环链表进行叙述和详解。
二、无头单向非循环链表
//plist是链表第一个元素的地址
// 1、无头+单向+非循环链表增删查改实现
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data;
struct SListNode* next;
}SListNode;
// 动态申请一个结点
SListNode* BuySListNode(SLTDateType x);
// 单链表打印
void SListPrint(SListNode* plist);
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x);
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x);
// 单链表的尾删
void SListPopBack(SListNode** pplist);
// 单链表头删
void SListPopFront(SListNode** pplist);
// 单链表查找
SListNode* SListFind(SListNode* plist, SLTDateType x);
//单链表在pos位置之前插入
void SListInsert(SListNode** pphead, SListNode* pos, SLTDataType x)
// 单链表删除pos位置之后的值
void SListInsertAfter(SListNode* pos, SLTDateType x);
// 分析思考为什么不删除pos位置?
void SListEraseAfter(SListNode* pos);三、链表的实现
3.1链表的创建
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType data;
struct SListNode* next;
}SListNode;在进行链表功能的实现之前,先要创建链表的元素和类型,一般我们以结构体的形式进行创建,第一步先创建一个结构体struct SListNode,并在结构体创建之后对其类型重命名为SListNode,结构体成员有两个。
第一个是整形int data ,第二个是结构体指针类型struct SListNode* next。这里特别强调一个注意点,为什么在定义结构体指针类型时要使用struct SListNode*而不是直接使用SListNode*,因为编译器在对代码进行预编译时,到这一行时还未对结构体类型进行重命名,也就是说重命名在结构体成员创建之后。所以如果直接用SListNode*去创建结构体指针的话,此时编译器此时是无法识别从而会进行报错处理的。
3.2动态申请一个结点
SListNode* BuySListNode(SLTDataType x)
{
SListNode* newnode = (SListNode*)malloc(sizeof(SListNode));
if (newnode == NULL)
{
perror("malloc fail");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}定义一个函数为SListNode* BuySListNode(SLTDataType x) ;参数为x,x就是创建新的结构体变量中的data,所以要在进入函数之前就要将data的值进行传参。
使用malloc开辟一个SListNode*类型的变量名为newnode,进入函数内部后进行判断,判断内存是否开辟成功(注:虽然在现在的电脑配置和环境下几乎不存在内存开辟失败,但作为一名合格的程序员,应当考虑全面,以防万一)。如果没有开辟成功,使用perror打印错误信息并且exit。
如果开辟成功就对newnode的成员进行赋值,将x的值赋给data,将next先滞空。next起到链接的作用,就像铁链一样,用来链接下一个结构体变量。最后将newnode返回。
3.3单链表打印
void SListPrint(SListNode* phead)
{
SListNode* cur = phead;
//while (cur != NULL)
while (cur)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
定义一个函数为void SListPrint(SListNode* phead);参数为结构体指针。单链表打印函数接收到phead后从phead开始往后依次打印。注意,因为现在进行的是无头单向链表的实现,所以此处的phead不是哨兵位(是指专门用来存放链表第一个变量的地址而专门创建的),此处的phead是直接指向链表的第一个元素的,phead就是第一个元素的地址。然后将phead的值赋给cur。
接下来走while循环,直到将链表中的所有元素都遍历一遍,cur变成NULL以后再停止。进入循环内部,对每一个元素的data进行打印(注意:例子中创建的结构体SLTNode虽然有两个成员,但存放数据的还是data,data是有效位,而next是用来找到下一个元素的)。
然后就取出cur所指向的结构体变量中所存放的next也就是下一个元素的地址,再将它重新赋值给cur,从而让cur向后移动找到下一个元素。
3.4单链表尾插(及传参二级指针的原因)
//void SListPushBack(SListNode** pplist, SLTDateType x);//头文件
void SListPushBack(SListNode** pphead, SLTDataType x)
{
SListNode* newnode = BuySListNode(x);
if (*pphead == NULL)
{
// 改变的结构体的指针,所以要用二级指针
*pphead = newnode;
}
else
{
SListNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
// 改变的结构体,用结构体的指针即可
tail->next = newnode;
}
}定义一个函数为void SListPushBack(SListNode** pphead, SLTDataType x);参数为一个为二级指针**phead,一个为int类型的数据,设置二级指针而不是一级指针的原因在于因为此次我们构建的链表是无头的也就是没有哨兵位的,所以不排除链表为空的这种特殊情况出现,而如果实参pplist为NULL那么就无法对其进行访问,空指针是无法进行访问的,所以只能改变pplist的实际指向,而pplist本身作为一个一级指针想要修改就只能使用二级指针。具体原因如下:如果使用一级指针把刚开辟的newnode的地址给phead,是无法改变原来的值的,为此博主在编写代码时特意将形参与实参分开命名以作区分。我们对比一下上面的头文件,头文件中写的是pplist,而接收时使用了pphead,pphead作为尾插函数接收参数而创建的临时变量,开辟的空间是在栈区上的(具体可查看:函数栈帧的创建与销毁),也叫形参(临时变量),而形参是实参(被穿过来的参数的真身)的临时拷贝,当尾插函数编译结束以后,其创建的变量都会被pop掉,所以pphead也会被pop掉,所以将newnode赋值给pphead没有任何意义。函数想要改变实参就必须通过指针来访问修改。同样,pphead作为一级指针,想要修改一级指针的值就得使用指向一级指针的指针,也就是二级指针。
进入函数内部,如果链表是空链表,那么就对pphead进行解引用操作,将刚刚malloc的newnode的值(也就是刚malloc出的结构体的地址)赋给*pphead(将pphead进行解引用操作相当于直接改变pphead中存贮的地址也就是pplist的地址,使其不再是空指针)。
如果不是空链表就创建一个临时变量tail将pphead的值保存一下,然后用tail往后进行遍历,从第一个元素开始找尾巴,如果元素中的next不为空说明它后面还有元素,就取出next中所存储的地址赋给tail让tail继续往下遍历,直到找到next中存储NULL的那个元素,也就是链表的尾巴,停止遍历。此时tail中存储的地址就是最后一个元素的地址,然后将刚malloc的newnode的地址赋给tail中的next,此时就完成了单向无头链表的尾插。注意:不能直接使用*pphead进行遍历,因为在找尾巴时要进行遍历,使用pphead一个一个往下走pphead的值也是一直在变化的,等*pphead找到尾巴并改了之后,会出现一个现象:头找不到了,不光是头,是除了刚开辟的尾巴其他元素都找不到了,找不到这些元素,malloc的空间也就无法释放,这时就会发生严重的数据丢失和内存泄漏。
3.5单链表头插
void SListPushFront(SListNode** pphead, SLTDataType x)
{
SListNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}定义一个函数为void SListPushFront(SListNode** pphead, SLTDataType x);参数为一个为二级指针**phead,一个为int类型的数据。相比于尾插,头插在单链表中就简单很多,因为头插需要改变pphead的实际值,也就是plist,所以也是需要用到二级指针,malloc出一个newnode,因为是头插,所以新插入的元素就要取代之前的元素成为新的头,而原来的头就变成了链表中的第二个元素,所以将原本的*pphead给newnode的next,将newnode的值给*pphead,此时newnode就变成了新头,头插完毕。
3.6单链表的尾删
void SListPopBack(SListNode** pphead)
{
// 1、空
assert(*pphead);
// 2、一个节点
// 3、一个以上节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SListNode* tail = *pphead;
while (tail->next->next)
{
tail = tail->next;
}
free(tail->next);
tail->next = NULL;
}
}定义一个函数为void SListPopBack(SListNode** pphead);参数为一个二级指针。
尾删分为三种情况:1.链表为空没有任何元素 2.链表只有一个元素 3.链表有两个及以上的元素
1.首先判断*pphead是否为NULL,如果为NULL说明链表中连根毛都没有,没法进行删除。
2.如果链表中只有一个元素,那么*pphead指向的next应该是NULL,此时只需要直接将其free掉就好,此时就需要使用到二级指针,与尾插同理,传一级指针最后free掉的也只是栈区上的临时变量,想要改变实际值plist就得使用二级指针来改变plist这个一级指针。
3.如果链表有两个及以上的元素,那么就创建一个变量cur进入while循环找尾,这里使用了两层的查找,tail->next是判断该元素是否为尾元素,而tail->next->next就是判断tail后面的那一个元素是否为尾元素,为什么不直接找到尾元素然后直接free呢?如果直接free掉尾元素,那么free完成后上一个元素的next还是一个指针,而其指向的空间是已经被free掉的尾元素,此时编译器就会报错,所以尾删完成之后,必须把上一个元素的next改为NULL,所以使用tail->next->next找到为尾巴以后直接将next中存放的尾元素free,然后将next改为NULL。此时尾删才算完美结束。
3.7单链表头删
void SListPopFront(SListNode** pphead)
{
// 空
assert(*pphead);
// 非空
SListNode* newhead = (*pphead)->next;
free(*pphead);
*pphead = newhead;
}定义一个函数为void SListPopFront(SListNode** pphead);参数为二级指针。
和头插尾插一样,头删也比尾删要简单。同样要先assert断言链表是否为空链表,如果不是空链表,只需要创建一个结构体指针将现在的头一个元素的next指向的第二个元素的地址保存下来,然后将头元素free掉,注意此时被删除的头元素不需要再另外滞空成NULL,尾删滞空是因为最后一个元素的next应该是NULL,而头删虽然也是删,但是实际意义上是把*pphead也就是plist所指向的空间给换成原来第二个元素的,而不是直接扔掉了,所以不需要NULL,直接将newhead中保存的原本第二个元素的地址赋给*pphead就可以了。
3.8单链表查找
SListNode* SListFind(SListNode* phead, SLTDataType x)
{
SListNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}定义一个函数为SListNode* SListFind(SListNode* phead, SLTDataType x);参数为一个二级指针一个int型。
将链表的头指针传过来,将要查找的数字x传过来,创建一个cur的指针变量拷贝phead的地址,这里我们就不需要二级指针了,因为查找只遍历不修改。while循环遍历cur中的data是否与x的值相等,如果相等就返回cur,如果不相等就走下一个。如果直到最后都没有找到就返回NULL。
3.9.1单链表指定位置插入
void SListInsert(SListNode** pphead, SListNode* pos, SLTDataType x)
{
assert(*pphead);
assert(pos);
if (pos == *pphead)
{
SListPushFront(pphead, x);
}
else
{
SListNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
SListNode* newnode = BuySListNode(x);
prev->next = newnode;
newnode->next = pos;
}
}定义一个函数void SListInsert(SListNode** pphead, SListNode* pos, SLTDataType x);参数为一个二级指针,一个一级指针,一个int型。
进入函数内部先assert进行断言,判断*pphead和pos是否为空,如果pos就是*pphead,那么在pos之前插入就等于是头插,直接复用之前已经写好的头插函数。
如果不是第一个,就定义一个变量prev将*pphead的值赋给它,然后进行遍历,在链表中查找pos,当查找到next中存放的是pos地址的元素后,复用BuySListNode(x),malloc一个空间。因为是在pos之前插入,所以newnode将会变成原本pos前一个元素的下一个元素。所以将原本pos前一个的next改成newnode的值。然后将pos的值放到newnode的next中。
3.9.2单链表指定位置后插入
void SListInsertAfter(SListNode* pos, SLTDataType x)
{
assert(pos);
SListNode* newnode = BuySListNode(x);
SListNode* posnext =pos->next;
pos->next = newnode;
newnode->next = posnext;
}
相比于在pos之前插入,在之后插入就显得及其简单,因为在pos前插入需要遍历找pos的前一个元素,然后吧前一个元素的next改了。而后插就直接动pos的next,将新开辟的元素存放在pos的next中然后将newnode的next指向原本pos的next。
四、单链表拓展
无头单向非循环链表的大致功能实现就如上所示,其实单链表在日常代码实现中使用起来是比较不方便的,但站在深度理解和学习链表过程来看,对单链表的熟练掌握和应用是不可或缺的。以下是基于单链表的两个扩展功能实现,在上面功能的基础上多增加了一些条件,也是很简单,基本思路大相径庭,大家可以根据个人需求来进行复现或学习理解。
// 删除pos位置
void SLTErase(SListNode** pphead, SListNode* pos)
{
assert(pphead);
assert(pos);
if (pos == *pphead)
{
SListPopFront(pphead);
}
else
{
SListNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
//pos = NULL;
}
}// 删除pos的后一个位置
void SLTEraseAfter(SListNode* pos)
{
assert(pos);
// 检查pos是否是尾节点
assert(pos->next);
SListNode* posNext = pos->next;
pos->next = posNext->next;
free(posNext);
posNext = NULL;
}本章内容就到此结束了,每一篇文章都是博主的精心打磨,耐心编排。更多好文关注博主CSDN。一键三连不迷路。