【深度学习:数据增强 】提高标记数据质量的 5 种方法

【深度学习:数据增强 】提高标记数据质量的 5 种方法
-
- 计算机视觉中常见的数据错误和质量问题?
- 为什么需要提高数据集的质量?
- 提高标记数据质量的五种方法
-
- 使用复杂的本体结构作为标签
- 人工智能辅助标签
- 识别标签错误的数据
- 改进注释者管理
计算机视觉模型的复杂性、准确性、速度和计算能力每天都在进步。机器学习团队正在训练计算机视觉模型以更有效地解决问题,这使得标记数据的质量比以往任何时候都更加重要。
质量差的标记数据,或者基于图像或视频的数据集中的错误和错误可能会给机器学习团队带来巨大的问题。无论需要解决哪个部门或问题,如果计算机视觉算法无法获得所需数据的质量和数量,它们就无法产生组织所需的结果。
在本文中,我们将仔细研究标记数据中的常见错误和质量问题、组织需要提高数据集质量的原因以及实现这一目标的五种方法。
计算机视觉中常见的数据错误和质量问题?
数据科学家花费大量时间(很多人会说太多时间)调试数据并调整数据集中的标签以提高模型性能。或者,如果已应用的标签不符合要求的标准,则部分数据集需要返回注释器重新标记。
尽管有注释自动化和人工智能辅助标记工具和软件,但减少数据集中的错误和提高质量仍然是一项耗时的工作。通常,这是手动完成的,或者尽可能接近手动完成。然而,当数据集中有数千张图像和视频时,筛选每一张图像和视频来检查质量和准确性就变得不可能了。
正如我们在本文中所述,计算机视觉数据集中出现错误和质量问题的三大原因是:
- 标签不准确;
- 图像标签错误;
- 缺少标签(未标记的数据);
- 数据和相应标签不平衡(例如同一事物的图像太多),导致数据偏差或数据不足来解释边缘情况。
根据视频或图像注释工作的质量、所使用的人工智能支持的注释工具以及质量控制流程,您最终可能会在整个数据集中遇到所有三个问题。
不准确的标签会导致算法难以正确识别图像和视频中的对象。常见的示例包括松散的边界框或多边形、不覆盖对象的标签或与同一图像或帧中的其他对象重叠的标签。
将错误的标签应用于对象也会导致问题。例如,一旦将数据集输入计算机视觉模型,将“猫”标记为“狗”就会产生不准确的预测。麻省理工学院的研究表明,在最佳实践数据集中,3.4% 的标签是错误的。这意味着,大多数组织使用的数据集中存在更多不准确标签的可能性更大。
真实数据集中缺失的标签也会导致计算机视觉模型产生错误的预测和结果。
当然,标注工作的目标应该是为图像和视频数据集提供最好、最准确的标签和标注。根据相关用例和您要解决的问题。
为什么需要提高数据集的质量?
提高输入机器学习或计算机视觉模型的数据集的质量是一项持续的任务。质量始终可以提高。对数据集中标签的注释和质量所做的每一项更改都应该对计算机视觉项目的结果产生相应的改进。
例如,当您第一次为算法模型提供训练数据集时,您可能会获得 70% 的准确度分数。要使生产模型达到 90% 以上甚至 99%,需要评估和提高标签和注释的质量。
以下是您需要从数据集中获得的内容,该数据集应能产生您正在寻找的结果:
- 准确标记和注释图像和视频中的对象;
- 不缺少任何标签的数据;
- 包括涵盖数据异常值和每种边缘情况的标签和注释;
- 均衡的数据,涵盖部署环境中图像和视频的分布,例如不同的光照条件、一天中的时间、季节等);
- 持续的数据反馈循环,使数据漂移问题减少,质量不断提高,偏差减少,准确性提高,确保模型能够投入生产。
现在让我们考虑提高标记数据质量的五种方法。
提高标记数据质量的五种方法
使用复杂的本体结构作为标签
由于项目的标签过程,机器学习模型需要高质量的数据注释和标签。实现您想要的结果通常涉及为您的标签使用复杂的本体结构,前提是这是所需要的 - 而不仅仅是为了它。
简化的本体结构对于计算机视觉模型没有多大帮助。然而,当您使用更复杂的本体结构进行数据注释标记过程时,更容易准确地分类、标记和概述图像和视频中的对象之间的关系。
通过通过本体结构应用图像和视频中的对象的清晰定义,实施数据注释标记过程的人员可以生成更准确的标签。反过来,这可以为生产就绪的计算机视觉模型带来更好、更准确的结果。
人工智能辅助标签
完全手动的数据标记过程是一项耗时且费力的任务。它可能会导致注释者犯错误、精疲力竭(尤其是当他们一遍又一遍地应用相同的标签时)以及质量下降。
加快标记和注释数据集所需时间的最佳方法之一是使用人工智能(AI 辅助)标记工具。人工智能辅助标记,例如在数据注释过程中使用自动化工作流程工具,是创建训练数据集不可或缺的一部分。
人工智能辅助标签工具有各种形状和大小。从开箱即用的开源软件,到专有的、高级的、基于人工智能的工具,以及介于两者之间的一切。人工智能解决方案可以节省时间和金钱。使用人工智能辅助工具可以提高效率和质量,更一致地生成高质量数据集,减少错误并提高准确性。
其中一个工具是 Encord 的微模型,它是“针对特定任务或特定数据进行过度训练的注释特定模型”。 Encord 还附带了广泛的人工智能辅助标签工具和解决方案,我们将在本文末尾更详细地介绍这些工具和解决方案。
识别标签错误的数据
标签错误、标签错误或标签缺失的数据总会给计算机视觉模型带来问题。
避免这些问题的最佳方法是确保在数据注释过程中准确应用标签。然而,我们知道这并不总是可能的。错误会发生。特别是当外包注释者团队正在标记数以万计的图像或视频时。
并非每个注释者每天都能完美完成工作。有些会比其他更好。即使注释者可以使用人工智能辅助标记工具,质量也会有所不同。
因此,为了确保您的项目获得尽可能最高质量的注释和标签数据集,您需要实施专家评审工作流程和质量保证系统。
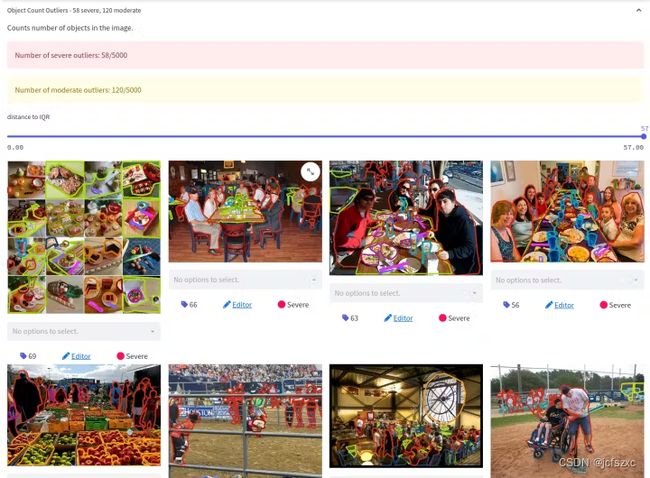
确保标签和数据质量的另一种方法是使用 Encord Active,这是一个开源主动学习框架,可以识别错误和标签不良的数据。一旦识别出错误和标签错误的图像和视频,可以将相关图像或视频(或整个数据集)发回重新注释,或者您的机器学习团队可以在将数据集引入计算机视觉之前进行必要的更改模型。
改进注释者管理
减少数据管道质量保证端的错误数量涉及改进整个项目的注释器管理。
即使您与另一个国家/地区的外包团队合作,距离、语言障碍和时区也不会对您的项目产生负面影响。管理流程不善将产生数据集质量较差的结果。
项目负责人需要持续了解输入、输出以及注释团队中个人的表现。您需要评估注释工作中的数据注释和标签的质量,以便您可以了解谁实现了关键绩效指标 (KPI),谁没有实现。
借助正确的人工智能辅助数据标记工具,您应该拥有触手可及的项目仪表板。这不仅应该提供访问控制,而且应该让您清楚地了解注释工作的进展情况,以便可以在项目期间进行更改。这样,应该更容易判断来自注释团队的标签和注释的质量,以确保尽可能高的质量和准确性。