论文推荐 | 借助大语言模型GPT-4辅助恶意代码动态分析
2023年是大语言模型发展的元年,许多大语言模型崭露头角,以ChatGPT为首的生成式对话模型已然成为人工智能领域的研究热点,引领着自然语言处理技术不断发展。得益于大语言模型在多项语言任务和实际应用上取得的显著成果,现如今,各个领域都在积极投入资源和努力,共同推动大模型的建设和发展。这篇文章将介绍由广东省智能信息处理重点实验室发布的一项研究成果——借助大语言模型GPT-4辅助恶意代码动态分析。该研究首次将大语言模型和提示工程技术应用于恶意代码检测,并且相较于以往工作,该研究所提方法在多个检测指标上都有着显著提升。
原文作者:Pei Yan, Shunquan Tan, Miaohui Wang, Jiwu Huang
原文标题:Prompt Engineering-assisted Malware Dynamic Analysis Using GPT-4
原文链接: https://arxiv.org/pdf/2312.08317.pdf
下载地址: https://github.com/yan-scnu/Prompted_Dynamic_Detection
投稿作者: 严沛
作者单位: 广东省智能信息处理重点实验室
该系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。这篇文章来源于广东省智能信息处理重点实验室团队及严沛老师的投稿(原创),推荐大家去阅读和学习,在此表示感谢。同时,欢迎大家给我留言评论以及投稿,学术路上期待与您前行,加油~

文章目录
- 摘要
- 1.简介
- 2 研究方法
- 3.实验
-
- 3.1 实验环境与数据集
- 3.2 检测性能对比实验
- 3.3 泛化性能对比实验
- 3.4 表征质量实验
- 4.总结
摘要
动态分析方法可以有效识别加壳、包装和混淆的恶意代码,阻止它们入侵计算机。API序列作为一种重要的恶意代码动态行为信息,已逐渐成为动态分析方法的重要特征。尽管目前许多基于API序列的深度学习检测模型被提出,但这些模型普遍存在以下问题:
- ①生成的 API 调用表征质量有限;
- ②无法生成未知 API 调用的表征;
- ③难以应对API调用概念漂移现象,这些都会影响模型的检测性能和泛化能力。
为了解决这些问题,本文引入GPT-4的提示工程辅助恶意代码动态分析。在所提方法中,我们使用GPT-4为API序列中的每个API调用生成解释文本,再使用预训练模型BERT获取解释文本的表征,进而得到API序列的表征。所提方法理论上能够为所有API调用生成表征,并且生成过程不需要依赖额外的数据集进行训练。此外,本文设计了基于CNN的检测网络从表征中进一步提取和学习特征。本文使用五个基准数据集来验证所提出模型的性能。实验结果表明,所提出的检测模型比目前主流的模型有着更好的检测性能,并且在跨数据库实验和小样本学习实验中也展现出很好的效果,充分验证了其优越的泛化性能。
1.简介
动态检测方法是一种根据恶意代码在运行过程中的动态行为特征进行检测的方法:将代码放进沙箱中运行,沙箱会记录下代码在运行过程中的行为特征,再通过行为特征判断该代码是否为恶意代码。API序列是一种最重要、最常用的动态行为特征,记录代码在运行过程中依次调用的API。为方便表示,我们将API序列中的每个元素称之为API调用。因为API序列和自然文本存在较高的相似性,因此目前主流的恶意代码检测方法都有借鉴自然语言处理领域相关模型。随着深度学习技术被广泛且成熟地应用于自然语言处理任务,部分研究者尝试将基于深度学习的文本分类模型应用于API序列分类任务,他们所提模型也普遍表现出更好的检测性能。最近,大语言模型凭借着强大的语言理解和语言生成能力成为了当前NLP领域的研究热点,其他领域也在尝试集成大语言模型来解决相关问题。在恶意代码检测领域,部分研究团队也在探索如何将大语言模型和恶意代码检测相结合,一些结合后的模型被相继提出,但整体而言,现有模型的检测性能往往欠佳。此外,目前基于API序列的检测模型还普遍存在以下问题:
- 由模型生成的API序列表征质量不高
- 模型的泛化性能较弱
- 模型难以应对API序列概念漂移现象
为了解决上述问题,本文提出了一种借助GPT-4提示工程辅助恶意代码检测的方法。本文先使用GPT-4为API调用生成解释文本,再使用大规模预训练模型为解释文本生成表征,通过这种方法可以间接得到API序列的表征,接着再设计相应的深度神经网络模块进行学习和分类。
本文的主要贡献如下:
- 据我们所知,我们是第一个使用大语言模型和提示工程技术来做恶意代码分析的团队。
- 本文借助GPT-4提示内容生成API序列表征,理论上可以为所有API序列生成表征,且生成的表征质量更高。
- 相较于主流方法而言,所提模型有更好的检测性能和泛化性能,也能在一定程度上缓解概念漂移现象对检测效果的影响。
2 研究方法
(1) 模型架构
在本研究中,我们使用GPT-4为API调用生成解释文本。得益于在大规模语料库上进行训练,GPT-4可以通过提示工程对 API 调用相关知识进行概括和重述。在提示工程中,我们可以通过对提示文本进行设计,引导GPT-4生成更高质量的解释文本。 在得到解释文本后,我们使用预训练模型BERT来为解释文本生成表征,之后将每个API调用的解释文本的表征拼接起来,得到整个 API 序列的表征。随后部署深度神经网络从这些表征中提取特征并进行学习,最后通过带有softmax函数的全连接层连接到各个恶意代码类别。 所提模型的总体架构如图所示。

(2) 表征生成
-
我们定义了映射关系 P r o m p t Prompt Prompt ,为每个API调用生成解释文本。我们将长度为 n n n 的API序列 s s s 定义为:
s = [ α 1 , . . . , α n ] s=[\alpha_1,...,\alpha_n] s=[α1,...,αn]
其中 α i \alpha_i αi 表示第 i i i 个API调用。在提示工程的辅助下,每个API调用都生成对应的解释本文。
我们将解释文本记为 e i e_i ei 。
[ e 1 , . . . , e n ] = [ P r o m p t ( α 1 ) , . . . , P r o m p t ( α n ) ] [e_1,...,e_n]=[Prompt(\alpha_1),...,Prompt(\alpha_n)] [e1,...,en]=[Prompt(α1),...,Prompt(αn)] -
然而在实际操作过程中,如果对每个样本中的所有的API调用都进行一次文本生成操作,会消耗大量的GPT-4使用资源。为此,我们构建了API调用词表,即所有样本中API调用的集合。在得到词表后,我们为词表中的每个API调用生成对应的解释文本,后面每当遇到API调用时,我们都能从词表中找到其解释文本,极大地降低了GPT-4的资源使用。 对于每条解释文本,我们使用 W o r d P i e c e WordPiece WordPiece 分割方法对解释文本进行分割,公式如下所示。
[ C L S ] , ω 1 , . . . , ω n , [ S E P ] = W o r d P i e c e [CLS],\omega_1,...,\omega_n,[SEP]=WordPiece [CLS],ω1,...,ωn,[SEP]=WordPiece -
W o r d P i e c e WordPiece WordPiece 分词方法将一个单词分解为多个子单词或字符,在处理未知单词、罕见单词和复杂单词时比基于空格的分词方法更有效。我们使用 W o r d P i e c e WordPiece WordPiece 对解释文本进行分词和标记,得到标记序列(token sequence),然后通过定长操作将序列调整为相同的长度 m m m,即序列长度超过 m m m 的只保留前 m m m 个序列,未达到 m m m 的使用特殊标记 [ P A D ] [PAD] [PAD] 在序列末尾进行填充,直到填充后的序列达到长度 m m m。最后,我们在序列的开头和结尾加上 [ C L S ] [CLS] [CLS] 和 [ S E P ] [SEP] [SEP] 特殊标记,以满足BERT模型输入的需要。映射关系 E m b e d Embed Embed定义如下所示,生成序列中每个标记的向量表征。
e = E m b e d ( [ [ C L S ] , ω 1 , . . . , ω m , [ S E P ] ] ) = [ v C L S , v 1 , . . . , v m , v S E P ] \boldsymbol{e}=Embed([[CLS],\omega_1,...,\omega_m,[SEP]])=[v_{CLS},v_1,...,v_m,v_{SEP}] e=Embed([[CLS],ω1,...,ωm,[SEP]])=[vCLS,v1,...,vm,vSEP] -
我们使用预训练模型BERT为每个标记 ω j \omega_j ωj 生成表征向量 v j ( 1 ≤ j ≤ m ) v_j(1≤j≤ m) vj(1≤j≤m),因为BERT模型的表征维度为768,因此 v j ∈ R 768 v_j \in \mathbb{R}^{768} vj∈R768。 将所有的表征向量 v j v_j vj 进行拼接,得到一个API调用的表示矩阵 e k ( 1 ≤ k ≤ n ) ∈ R ( m + 2 ) × 768 \boldsymbol{e_k}(1≤k≤n) \in \mathbb{R}^{(m+2)×768} ek(1≤k≤n)∈R(m+2)×768。 在获得每个API调用的表征后,对API序列中每个API调用表征矩阵 e k \boldsymbol{e_k} ek进行拼接( C o n c a t Concat Concat),得到API序列的表征张量 E ∈ R n × ( m + 2 ) × 768 E \in\ \mathbb{R}^{n×(m+2)×768} E∈ Rn×(m+2)×768,计算过程如下式所示。
E = C o n c a t [ e 1 , . . . , e n ] E=Concat[\boldsymbol{e}_1,...,\boldsymbol{e}_n] E=Concat[e1,...,en]
(3) 表征学习
在三维张量表征中,每个嵌入通道对应一个表征矩阵,表征矩阵中的每个元素都与周围元素之间存在上下文关联性。具体而言,垂直相关性源于解释文本,水平相关性来自API序列。 因此,有必要设计一个用于表征调整和语义信息捕获模块。考虑到每个维度的表征反映了API调用的特征,并且跨维度表征的相关性不强,因此我们采用逐层卷积网络来微调每个维度的表征。此外,逐层卷积网络可以捕获表征矩阵中各元素的上下文关联性,也能够对表征矩阵的局部特征进行提取。
在对表征进行微调之后,我们参照TextCNN,使用具有不同内核大小的二维卷积块来生成各自的特征图,并执行最大池化和批量归一化操作。最大池化操作可以从每个特征图中选择最大值,从而使模型能够捕获每个特征图中的重要特征。考虑到特征图各维度统计特性不同,导致不同维度的最大池化结果存在较大差异,我们对最大池化层输出特征进行标准化,最后将输出的特征进行拼接,通过带有softmax函数的全连接层连接到各个分类类别。
(4) 质量表征
表征方法将API调用映射成固定长度的连续向量,我们可以通过这些向量计算每个API调用之间的相关性。API调用的相关性越高,他们表征向量的接近程度越高。TextCNN和BiLSTM都使用词嵌入层对API调用进行表征,表征以向量形式进行呈现;我们所提的表征生成方法使用一个矩阵对API调用进行表征。本文使用余弦相似度作为API调用相关性的度量指标,如果两个API调用的相关性越高,则它们表征的余弦相似度越接近于1。具体公式如下所示,其中 A \textbf{A} A 和 B \textbf{B} B 分别为两个不同的API调用的表征。
C o s i n e ( A , B ) = ∣ ∑ j = 1 n ( A i j ∗ B i j ) ∣ ∑ j = 1 n ( A i j 2 ) ∗ ∑ j = 1 n ( B i j 2 ) Cosine(\textbf{A},\textbf{B}) = \frac{| \sum_{j=1}^{n}(\textbf{A}_{ij} * \textbf{B}_{ij}) |}{\sqrt{\sum_{j=1}^{n}(\textbf{A}_{ij}^2)} * \sqrt{\sum_{j=1}^{n}(\textbf{B}_{ij}^2)}} Cosine(A,B)=∑j=1n(Aij2)∗∑j=1n(Bij2)∣∑j=1n(Aij∗Bij)∣
下图分别为TextCNN、BiLSTM和我们所提方法生成的表征关联热力图(训练数据集为Aliyun),从图中我们可以看出TextCNN和BiLSTM得到的API调用表征关联比较稀疏,关联矩阵中有约25%的元素为0,由于数据集的划分,部分在测试集中的API调用并没有出现在训练集中,导致模型无法学到未见过的API调用的表征,进而影响模型的检测性能和泛化性能。而我们所提的表征生成方法理论上可以为所有API调用生成表征,因此表征关联矩阵相对稠密,并且表征生成的过程不依赖额外的数据集进行训练,不存在因为数据集划分导致部分API调用缺失表征的问题,这也使得所提模型有更好的检测性能。

3.实验
3.1 实验环境与数据集
实验环境
- 本文中的所有实验均在Ubuntu20.04 上进行,使用RTX4090 GPU(显存24GB)。 使用Python 3.9和Pytorch 2.0构建实验模型。
数据集统计特性
- 所使用的数据集:Aliyun、Catak 、GraphMal、VirusShare 和 VirusSample。5个基准数据集的统计分析如下表所示:
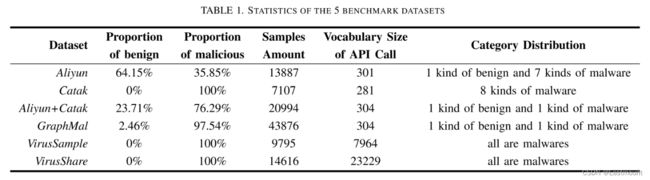
- Aliyun 数据集的恶意序列占比比较低,这可能会影响恶意序列的召回率。因此本文通过将Aliyun和Catak数据集合并得到Aliyun+Catak数据集。 本文也对上述5个数据集所包含的API调用种类进行研究,使用 I o U IoU IoU作为数据集相似性度量,计算不同数据集之间的API调用种类的差异,不同数据集之间的IoU值热力图如下图所示,如果两个数据集包含的API调用种类相近,则 I o U IoU IoU值接近于1,如果差别较大,则 I o U IoU IoU值接近于0。

- Aliyu、Catak 和 GraphMal 数据集之间存在显着的相似性,而这三个数据集与 VirusSample 和 VirusShare 数据集的相似度明显较低。根据数据集所包含API调用种类的相似性,本文定义了两个数据集的集合: D b a s e \mathcal{D}_{base} Dbase和 D l a r g e \mathcal{D}_{large} Dlarge。
D b a s e = { A l i y u n , C a t a k , G r a p h M a l } D l a r g e = { V i r u s S a m p l e , V i r u s S h a r e } \mathcal{D}_{base}= \lbrace Aliyun,Catak,GraphMal \rbrace \\ \mathcal{D}_{large}= \lbrace VirusSample,VirusShare \rbrace Dbase={Aliyun,Catak,GraphMal}Dlarge={VirusSample,VirusShare}
D l a r g e D_{large} Dlarge的词表远比 D b a s e D_{base} Dbase要大,并且 D l a r g e D_{large} Dlarge所包含的API调用更加复杂,且包含一些异常内容。
3.2 检测性能对比实验
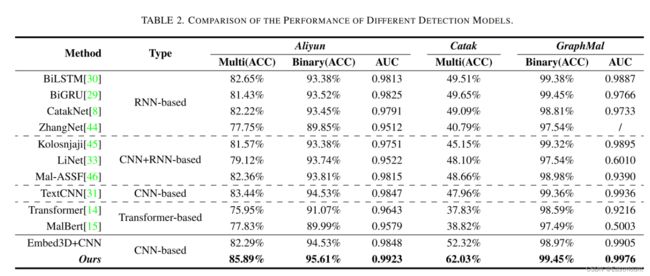
为了验证本文所提模型的性能,我们使用基于RNN的模型、基于CNN的模型、基于CNN+RNN的模型、基于Transformer的模型与其进行比较,并分别在Aliyun、Catak、GraphMal三个数据集上进行训练和验证。此外,为了验证所提表征方法的性能,本文做了消融实验。在保持表征学习模块不变的条件下,我们使用嵌入层创建API序列的表征矩阵,然后通过复制该矩阵来构造表征张量。该张量的形状与我们所提表征方法生成的张量形状相同,都是 ( ∈ R 100 ∗ 102 ∗ 768 ) ( \in R^{100*102*768}) (∈R100∗102∗768),该方法在表格中记为Embed3D+CNN。如下表所示,与目前主流方法相比,本文所提的模型在三个数据集上有着更好的检测性能。
3.3 泛化性能对比实验
为了验证所提模型的泛化性能,本文设计了两种类型的跨库实验:表征适应实验和领域适应实验。这两种实验都是使用不同的数据集分别进行训练和验证,区别在于训练和验证数据集包含API调用种类的差异。表征适应实验使用的训练和验证数据集的API调用种类差异小,比如训练集和验证集都在 D b a s e \mathcal{D}_{base} Dbase集合中;而领域适应实验使用的训练和验证数据集的API调用种类差异大,比如训练数据集在 D b a s e \mathcal{D}_{base} Dbase集合中,验证数据集在 D l a r g e \mathcal{D}_{large} Dlarge集合中,在这种情况下,验证集许多的API调用并没有出现在训练集中,这对检测模型的泛化能力提出了更高的要求。
- 表征适应实验
在该实验中,训练集和测试集之间的 API 调用词汇差异很小,但本文提出的方法生成的表示质量更高,关联更密集,稳定性更强。 因此,我们的方法的检测性能在跨数据库实验中优于其他方法,证实了模型的泛化性能。在以Aliyun为训练集、GraphMal为测试集的实验中,Aliyun中的恶意软件样本数量较少,导致恶意代码的召回率较低。 因此,我们引入了Catak数据集中的恶意代码样本,利用Aliyun和 Catak 的组合数据集进行训练,并在 GraphMal上验证训练后的模型。由实验结果可知,恶意代码的召回率和整体准确性均显着提高。

- 领域适应实验
在领域适应实验中,训练集和测试集的 API 调用存在显著差异,这种差异极大地增加了跨库实验的难度,目前主流的动态检测方法也难以克服这个问题。 然而,所提方法可以为训练过程中遇到的未见过的 API 调用生成解释性文本和相应的表示。 这一能力显着降低了表征缺失对模型预测效果的影响。 尽管在 D b a s e \mathcal{D}_{base} Dbase 上进行了训练,但所提出的方法在 D l a r g e \mathcal{D}_{large} Dlarge上表现出较高的检测性能,恶意软件的召回率接近100%。

3.4 表征质量实验
- 案例1:宽字符和窄字符方法
以一对API调用 H t t p S e n d R e q u e s t W \mathsf{HttpSendRequestW} HttpSendRequestW 和 H t t p S e n d R e q u e s t A \mathsf{HttpSendRequestA} HttpSendRequestA为例,在API调用名称上唯一的差别就是最后一个字母。以“A”为结尾的API调用表示处理窄字符(ANSI),以“W”为结尾的API调用表示处理宽字符(Unicode),除此之外,这两个API调用的含义完全相同,或者可以理解为同一API调用的两个不同版本。因此,这种功能相同的两个API调用在含义上非常相近,他们的余弦相似度值接近于1。部分例子如下表所示,相较于TextCNN和BiLSTM方法而言,所提方法能够较好地捕获功能相同的两个不同版本API调用的关联。

-
案例2:语义链分析法
根据API调用名称内容,生成API调用的四个属性:action、object、class、category,也就是API调用的语义链。如果两个API调用的语义链相同,则他们的含义相近,余弦距离相似度接近于1。四个属性完全相同时,对应于案例1的情况。考虑到object属性的区分度过强。我们围绕三个属性action、class、category进行分析,若两个API调用在这三个属性上都相同,则他们的余弦相似度接近于1。部分例子如下表所示,相较于TextCNN和BiLSTM方法而言,所提方法能够较好地捕获语义链相近的两个不同API调用的关联。
-
案例3:表征关联矩阵的统计分析
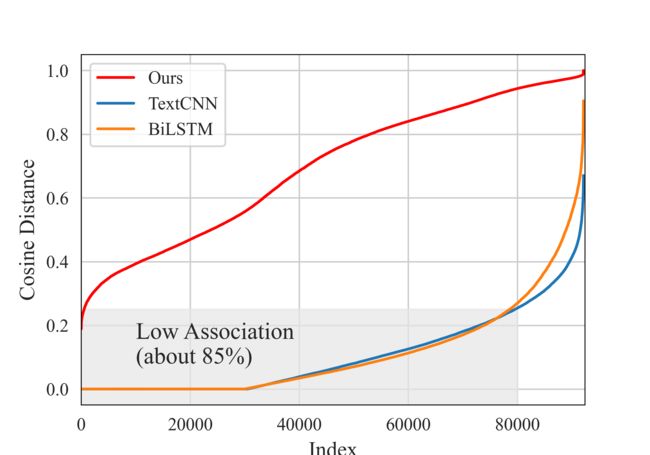
把表征关联矩阵展平,将数值从小到大进行排序,观察数值的整体分布(如下图所示)。对于所提方法,矩阵统计特性分布相对平衡。但对于TextCNN和BiLSTM,大部分API调用表征之间都呈现弱关联性,具体体现在表征矩阵中有85%的数值是在[-0.25,0.25]区间,有约1/3的数值为0值。如果表征层无法很好地捕获API调用之间的关联性,则会影响后续模块的训练效果。
4.总结
本文提出了一种借助GPT-4提示工程辅助恶意代码动态检测的方法。我们首先设计提示文本来引导GPT-4为API序列中的每个API调用生成解释文本,接着使用预训练模型BERT为每个解释文本生成表征,进而得到整个API序列的表征,之后使用CNN从表征中进一步提取和学习特征,并最终实现恶意代码的分类。在所提方法中,API序列表征生成不依赖与恶意代码数据集的训练,理论上可以为所用API序列生成表征,因此所提方法具备较强的泛化性能,也能更好地应对概念漂移现象。与目前的主流模型相比,我们所提模型在检测效果、泛化性能上都有着较大地提升。在未来工作中,我们将收集更大规模的恶意代码表征数据集,为构建专门面向恶意代码检测的大规模模型做必要准备。
这篇文章就写到这里,希望对您有所帮助,在此感谢严老师的投稿及创作,未来作者也将分享更多LLM和安全结合的文章,尤其是恶意代码。此外,请大家多多关注广东省智能信息处理重点实验室团队的成果,2024年继续加油!感恩遇见,不负青春。
(By:Eastmount 2024-01-21 周四夜于武汉 http://blog.csdn.net/eastmount/ )