2.机器学习-K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解
2️⃣机器学习-K最近邻(k-Nearest Neighbor,KNN)分类算法原理讲解
- 个人简介
- 一·算法概述
- 二·算法思想
-
-
- 2.1 KNN的优缺点
-
- 三·实例演示
-
-
- 3.1电影分类
- 3.2使用KNN算法预测 鸢(yuan)尾花 的种类
- 3.3 预测年收入是否大于50K美元
-
个人简介
️️个人主页:以山河作礼。
️️:Python领域新星创作者,CSDN实力新星认证,CSDN内容合伙人,阿里云社区专家博主,新星计划导师,在职数据分析师。
免费学习专栏:1. 《Python基础入门》——0基础入门
2.《Python网络爬虫》——从入门到精通
3.《Web全栈开发》——涵盖了前端、后端和数据库等多个领域悲索之人烈焰加身,堕落者不可饶恕。永恒燃烧的羽翼,带我脱离凡间的沉沦。
一·算法概述
K-最近邻算法(K-Nearest Neighbor,简称KNN)是一种基于实例学习的算法,可以应用于分类和回归任务。作为一种非参数算法,KNN不对数据分布做任何假设,而是直接使用数据中的最近K个邻居的标签来预测新数据点的标签。
在KNN算法中,每个数据点都可以表示为一个n维向量,其中n是特征的数量。对于一个新的数据点,KNN算法会计算它与每个训练数据点之间的距离,并选择最近的K个训练数据点。对于分类问题,KNN算法会将这K个训练数据点中出现最多的类别作为预测结果。而对于回归问题,KNN算法会将这K个训练数据点的输出值的平均值作为预测结果。
在KNN算法中,K的取值是一个超参数,需要根据数据集的特点和算法的性能进行选择。通常情况下,较小的K值可以使模型更复杂,更容易受到噪声的影响,而较大的K值可以使模型更简单、更稳定,但可能会导致模型的欠拟合。因此,选择合适的K值对于KNN算法的性能至关重要。

二·算法思想
KNN(K-最近邻)算法是一种基于实例的分类方法,通过计算不同特征值之间的距离来进行分类。
1️⃣其核心思想是:
如果一个样本在特征空间中的k个最邻近的样本中的大多数属于某一个类别,则该样本也划分为这个类别。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
2️⃣ KNN算法的主要步骤如下:
- 确定k值,即选取多少个最近邻居参与投票。
- 计算待分类样本与已知分类样本之间的距离,通常使用欧氏距离作为距离度量。
- 对距离进行排序,找出最近的k个邻居。
- 统计这k个邻居中各个类别的数量,将数量最多的类别作为待分类样本的类别。
3️⃣KNN算法涉及3个主要因素:
实例集、距离或相似的衡量、k的大小。实例集是指已知分类的样本集合;距离或相似的衡量是指计算样本之间距离的方法,如欧氏距离;k的大小是指选取多少个最近邻居参与投票,k值的选择会影响分类结果的准确性。
一个实例的最近邻是根据标准欧氏距离定义的。更精确地讲,把任意的实例x表示为下面的特征向量:
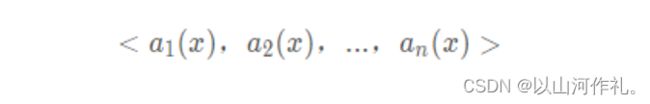
其中ar(x)表示实例x的第r个属性值。那么两个实例xi和xj间的距离定义为d(xi,xj),其中:


2.1 KNN的优缺点
1️⃣K-最近邻算法(KNN)的优点:
简单易懂:KNN算法的原理和实现都非常简单,容易理解和掌握。
非参数化:KNN是一种非参数化算法,不需要对数据分布做任何假设。
对异常值不敏感:KNN能够有效处理包含异常值的数据。
多用途:适用于分类和回归问题。
高维数据处理:可以处理高维特征空间的数据。
非线性问题处理:能够适应非线性的数据分布。
高度可解释性:结果直观,易于解释。
2️⃣KNN算法的缺点:
效率低:在大型数据集上计算距离时效率较低,尤其是在高维数据中。
对噪声敏感:训练数据中的噪声可能影响最近邻的选择,导致预测结果不准确。
K值选择:K值的选择对算法性能有很大影响,需要通过实验来确定最佳值。
距离度量:选择合适的距离度量方法对算法性能至关重要。
特征缩放敏感:需要对特征进行归一化或标准化,否则可能导致某些特征过于主导。
缺失值处理:处理缺失值较为困难,需要采取特定策略来应对。
解释性差:由于是基于实例的预测,相对于其他模型来说解释性较差。
三·实例演示
3.1电影分类
1.导入数据分析三剑客
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.导入KNN算法
# 谷歌的机器学习库
from sklearn.neighbors import KNeighborsClassifier
3.导入warnings模块,并设置警告过滤器为忽略所有警告
import warnings
warnings.filterwarnings(action='ignore')
4.使用电影数据
movies = pd.read_excel('../data/movies.xlsx',sheet_name=1)
movies

# 有标签的:有监督学习
# 训练数据
# x_train,y_train
# 测试数据
# x_test,y_test
# data : x特征数据
# target :y标签数据
data = movies[['武打镜头','接吻镜头']]
data # 二维
target = movies.分类情况
target # 一维

KNN模型
1.创建模型
# n_neighbors=5, k值 k = 5
# p = 2 距离算法,p=2表示欧氏距离 ,p = 1 表示曼哈顿距离
#
knn = KNeighborsClassifier(n_neighbors=5,p=2)
2.训练
knn.fit(data,target)
3.预测
# 自己提供测试数据,训练数据和测试数据列得相同,行可以不同
x_test=np.array([[20,1],[0,20],[10,10],[33,2],[2,13]])
x_test = pd.DataFrame(x_test,columns= data.columns)
y_test = np.array(['动作片','爱情片','爱情片','动作片','爱情片'])
y_pred = knn.predict(x_test)
y_pred
![]()
4.得分 ,准确率

3.2使用KNN算法预测 鸢(yuan)尾花 的种类

1.导入数据分析三剑客
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.导入KNN算法
# 谷歌的机器学习库
from sklearn.neighbors import KNeighborsClassifier
3.导入warnings模块,并设置警告过滤器为忽略所有警告
import warnings
warnings.filterwarnings(action='ignore')
4.得到鸢尾花数据
from sklearn.datasets import load_iris
# return_X_y=True 只返回data和target
# data,target = load_iris(return_X_y=True)
5.使用sklearn库中的load_iris()函数加载鸢尾花数据集,并将数据集分为数据(data)、目标(target)、目标名称(target_names)、特征名称(feature_names)四个部分。
iris = load_iris()
data = iris['data']
target = iris['target']
target_names = iris['target_names']
feature_names = iris['feature_names']
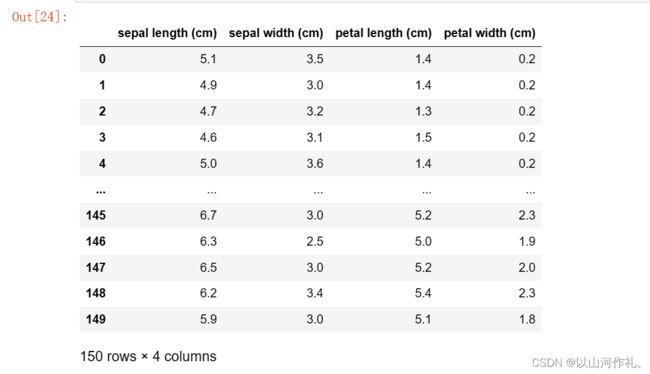
df = pd.DataFrame(data,columns=feature_names)
df
6.拆分数据集
把data和target取一部分作为测试数据,剩下的作为训练数据
从sklearn库的model_selection模块中导入train_test_split函数,该函数用于将数据集划分为训练集和测试集。
from sklearn.model_selection import train_test_split
# test_size
# 整数:测试数据的数量
# 小数:测试数据的占比,一般比较小,0.2,0.3
x_train, x_test, y_train, y_test = train_test_split(data,
target,
test_size=0.2)
x_train.shape, x_test.shape
# y_test 表示测试数据的真实结果
# y_pred:表示测试数据的预测结果
7.使用KNN算法
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
knn.score(x_test,y_test)
#0.33
#0.7以上:得分正常
#0.8以上:比较好
#0.9以上:非常好

3.3 预测年收入是否大于50K美元
1.导入数据分析三剑客
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.导入KNN算法
# 谷歌的机器学习库
from sklearn.neighbors import KNeighborsClassifier
3.导入warnings模块,并设置警告过滤器为忽略所有警告
import warnings
warnings.filterwarnings(action='ignore')
读取adults.csv文件,最后一列是年收入,并使用KNN算法训练模型,然后使用模型预测一个人的年收入是否大于50
```python
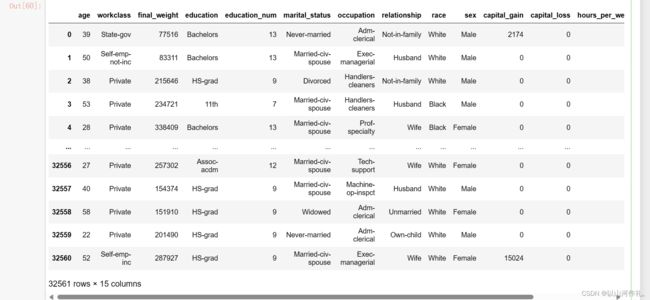
adults = pd.read_csv('../data/adults.csv')
adults
4.获取年龄age、教育程度education、职位workclass、每周工作时间hours_per_week 作为机器学习数据 获取薪水作为对应结果
data = adults[['age','education','workclass','hours_per_week']].copy()
target = adults['salary']
5.数据转换,将String/Object类型数据转换为int,用0,1,2,3…表示
使用factorize()函数
data['education'] = data['education'].factorize()[0]
data['workclass'] = data['workclass'].factorize()[0]
data

6.拆分数据集:训练数据和预测数据
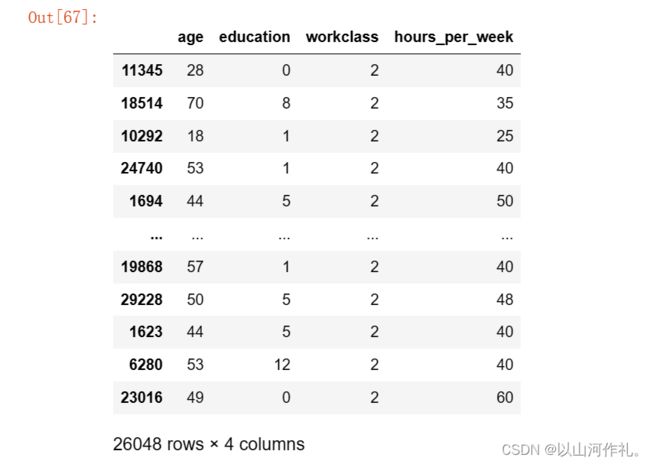
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.2)
x_train
7.使用KNN算法
knn = KNeighborsClassifier()
knn.fit(x_train,y_train)
knn.score(x_test,y_test)
