数据的力量:生成式 AI 的差异化引擎

本文作者 王宇博
亚马逊云科技 大中华区开发者关系总监
数据是构建生成式 AI 的
重要差异化因素
生成式 AI 是当前备受关注的热门话题,其发展离不开数据、算法和算力的支持。当前,生成式 AI 正在逐渐向纵深发展,在市场上有许多大模型和应用,越来越多的行业和企业开始应用生成式 AI 技术构建行业应用,如医疗行业的疾病诊断、金融行业的风险防控等。
然而,在生成式 AI 走向行业的过程中,需要进行大量的精细化工作。数据是构建生成式 AI 的重要差异化因素。每个行业都有自己的核心数据,这些数据是构建与业务契合的生成式 AI 应用的核心优势。

数据是生成式 AI 的差异化因素
在构建面向特定行业和业务场景的生成式 AI 应用时,我们需要把通用大模型与行业数据、场景数据以及业务需求结合。大部分行业用户,其实没有必要从零开始构建大模型。他们可以利用现有的大模型,并结合自己的数据进行提示工程,模型微调等工作,快速推出具有行业价值的生成式 AI应用,从而加速生成式 AI 在行业的落地。当然,也有一些行业用户希望从零开始,使用专有数据开发自己的大模型,以满足独特的业务需求。
因此,数据对于生成式 AI 应用的重要性不可忽视。深入的了解数据和使用数据,可以帮助我们更好的构建适应特定行业和业务需求的生成式 AI 应用。
一个典型的应用是企业级对话式搜索。生成式 AI 可以通过整合各种来源的数据来显著增强企业环境中的对话式搜索。将企业数据源集成到生成式 AI 框架中,使系统能够访问和分析特定于企业的信息,例如数据库、内部文档和相关存储库。这确保了对话式搜索期间生成的响应不仅上下文准确,而且还利用了企业生态系统内最新、最相关的数据。通过利用这些结构化和非结构化数据源,生成式 AI 可以为用户提供更明智和定制的见解,促进企业工作流程中对话式搜索的无缝集成。这种方法不仅简化了信息检索,还使员工能够更有效地与组织知识进行交互,从而营造一个更加高效的工作环境。

这种案例还有很多。我们其实不难看出,高质量的数据是实现企业级生成式 AI 应用的关键。在亚马逊云科技的首席数据官 2024 年洞察中指出,企业在实现生成式 AI 潜力方面面临的首要挑战是数据质量。当然,其他因素也很重要,包括应用场景,安全隐私,团队技能等诸多方面。
《2024年洞察》
https://aws.amazon.com/cn/data/cdo-report/

亚马逊云科技为满足不同企业和开发者的多样化需求,特别推出了生成式 AI 堆栈。在当前市场环境中,越来越多的企业和开发者希望能够迅速上手,尝试不同的大模型在多样化应用场景中的部署和应用。生成式 AI 堆栈为实现这一目标提供了有效的解决方案。
该堆栈的独特之处在于,它为用户提供了一整套层级结构,使其能够在每个层次上通过数据构建和应用生成式 AI。无论是初学者还是经验丰富的开发者,都能够从中受益。通过该堆栈,用户能够更轻松地掌握生成式 AI 技术,从而加速其在业务和项目中的应用。
生成式 AI 堆栈的灵活性使其能够适应各种不同的业务需求。从基础的数据处理和模型训练,到更高级别的应用场景,该堆栈提供了全面的解决方案。用户可以根据自身需求选择堆栈的特定层次,从而更加精准地满足其在生成式 AI 领域的要求。
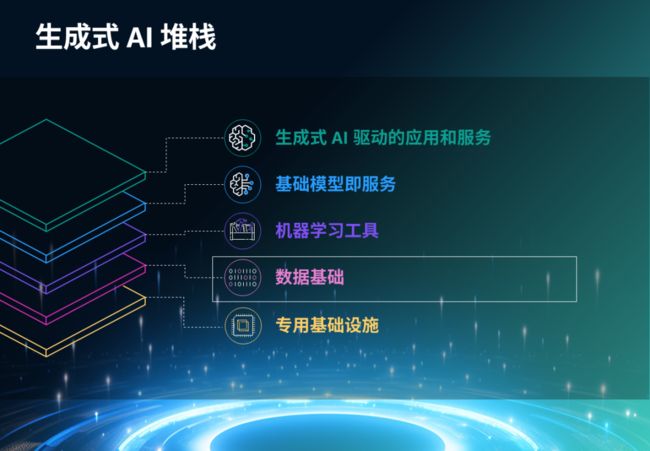
亚马逊云科技的生成式 AI 堆栈
企业和开发者可以通过多种方式,使用数据构建专用的生成式 AI 应用。
第一种是:使用大模型进行上下文学习,可以通过上下文提示工程或使用检索增强生成(RAG)技术,实现面向行业和用户的生成式 AI 应用。
第二种是:对大模型进行模型微调,通过一组指令或特定领域的数据对预训练的大模型进行训练和优化。
第三种是:从头开始构建专用大模型,使用企业特定数据集,从零开始构建大模型。
在后两种方式中,都会使用到 MLOps 技术和流程构建、监控和管理模型。如何选择更合适的构建方式,有许多因素需要考虑,包括复杂性,成本、数据管理规模等因素。

专用的生成式 AI 构建方式
模式一:上下文提示工程
我们先来看一下上下文提示工程。提示工程通过设计和编写提示文本,以引导大模型生成符合特定要求的输出。Zero-shot (零样本学习) 和 few-shot(小样本学习)是两种最基本的给大模型作提示的方法。

上下文提示工程架构的关键路径可概括如下:通过 API 获取最终用户的问题->检索任何可用的缓存数据->通过提示工程获取用户的上下文数据->获取对话历史记录或状态->将提示工程请求发送至大模型端点->从大模型端点检索答案->更新对话历史记录和状态->通过 API 将答案发送给最终用户。

在整个架构中,数据服务发挥着至关重要的作用,主要分为两个方面:首先,通过数据存储,我们能够有效地保存提示模板、示例以及会话的状态和历史记录。其次,针对上下文提示,我们会构建特定领域的数据集,以加速处理和响应的速度。这些数据集的应用能够更全面地理解上下文,从而生成更为准确的回答。这种数据驱动的方法不仅提高了系统性能,也为我们的模型提供了更深入的学习和理解机会。
模式二:检索增强生成
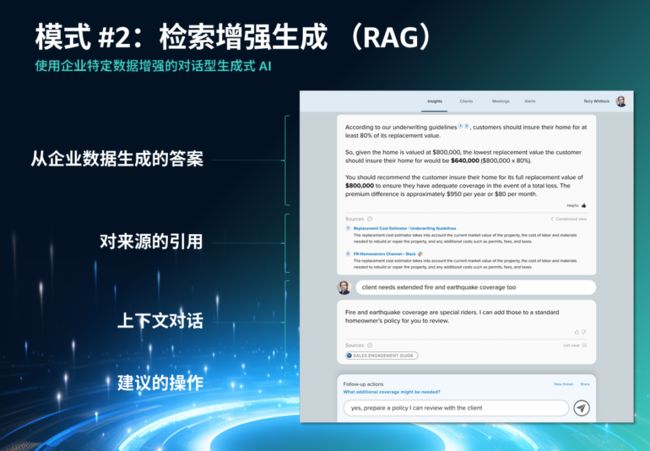
通用大型模型在处理专有且快速更新的数据时通常效果不佳。为解决这一问题,检索增强生成(RAG)技术被证明是一种有效的方法。RAG 通过融合检索模型和生成模型,显著提高了生成内容的相关性和质量,有效缓解了大型语言模型生成内容中可能出现的“幻觉”问题。
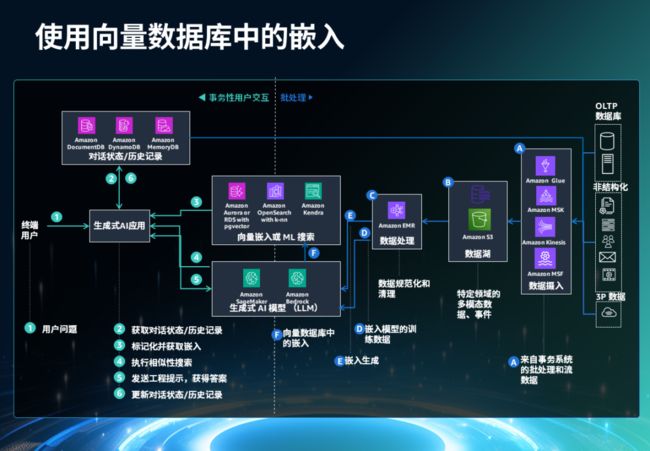
检索增强生成架构的关键路径大致如下:通过 API 获取最终用户问题->检索任何适用的缓存数据->获取对话历史记录或状态->使用嵌入端点进行输入标记化->使用来自向量数据库(RAG)的嵌入进行上下文化的输入->向 LLM 端点发送标记化提示->从 LLM 端点检索答案->更新对话历史记录和状态->通过 API 向最终用户发送答案。
在整个架构中,数据服务的作用有:
(1)从数据湖中检索特定于域的数据
(2)对数据集进行标记化,生成嵌入
(3)在向量数据库中存储/更新嵌入

亚马逊云科技针对向量数据库提供了一系列的选项:
1. 在 Aurora PostgreSQL 或 Amazon RDS for PostgreSQL 中使用 pgvector
Pgvector 是一个开源的、社区支持的 PostgreSQL 扩展,可在 Aurora PostgreSQL 和 Amazon RDS for PostgreSQL 中使用。该扩展通过引入名为 "vector" 的矢量数据类型、三个用于相似性搜索的查询运算符(欧氏距离、负内积和余弦距离)以及 ivfflat(具有存储向量的倒排文件)索引机制,扩展了 PostgreSQL,以执行更快的近似距离搜索。
2. 使用带有 k-NN 插件和 OpenSearch Serverless 的矢量引擎的 OpenSearch 服务
k-NN 插件通过引入自定义的 knn_vector 数据类型,扩展了开源的分布式搜索和分析套件 OpenSearch,使您能够在 OpenSearch 索引中存储嵌入。该插件还提供了三种执行 k- 最近邻相似性搜索的方法:近似 k-NN、脚本得分 k-NN(精确)以及 Painless 扩展(精确)。OpenSearch 包含了非度量空间库(NMSLIB)和 Facebook AI Research 的 FAISS 库。您可以使用不同的搜索算法来找到满足您需求的最佳算法。
3. 全托管的 Amazon Kendra
具有语义搜索功能,和常用数据源和文档格式的预构建连接器,能够根据元数据提高相关性。适合不想自己维护向量数据的企业和开发者。
模式三:微调模型

微调是指在已经经过预训练的大模型基础上,利用特定的数据集进行进一步训练,以使模型更好地适应特定任务或领域。并非所有问题都能够通过通用大模型解决,特别是涉及特定行业或企业的生成式人工智能应用。在这种情况下,使用特定数据集对大模型进行微调,以完成特定任务或回答特定问题等。在进行微调时,必须慎重选择适用的预训练模型、微调方法和数据集。
尽管相较于训练大模型,微调过程已经相当高效,但微调本身仍然需要充足的经验和技术,以及足够的算力、管理和开发成本。没有一种通用的大模型能够适应所有情境,因此微调成为在特定应用场景中提高性能和适应性的关键步骤。

微调模型的关键路径大致可分为两个主要部分。首先是与用户互动相关的操作:通过 API 获取最终用户的问题->检索可能存在的缓存数据->获取对话历史记录或状态->向 LLM 端点发送提示->从 LLM 端点检索答案->更新对话历史记录和状态->通过 API 向最终用户发送答案。其次是模型微调的过程:数据采集->存储至数据湖->进行特征工程->进行模型微调。
模式四:训练大模型

当涉及一些企业时,它们可能需要从零开始训练大模型,尽管这个过程相对费时费力,但却可能带来更好的效果。在这方面,亚马逊云科技提供的生成式 AI 堆栈,为大模型训练提供了全流程的支持。这一堆栈不仅仅包括训练所需的硬件基础设施,还提供了优秀的软件工具和框架,使企业能够更加轻松地进行大模型的构建和训练。
通过亚马逊云科技的生成式 AI 堆栈,企业可以充分利用云端强大的计算能力,快速高效地完成大模型的训练过程。这包括数据准备、模型架构设计、训练优化等方方面面。而且,这一堆栈还为企业提供了灵活的部署和管理选项,确保模型的集成和使用能够顺畅进行。
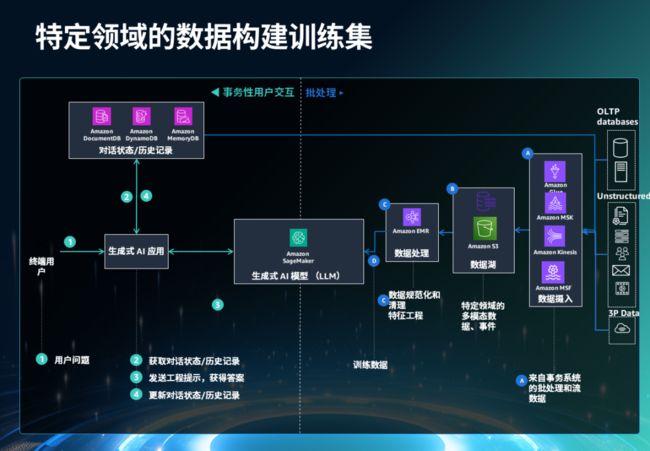
数据在生成式 AI 扮演着至关重要的角色。在最终用户的关键路径中,各种数据库发挥不同的作用。NoSQL 数据库负责处理对话状态和历史,向量数据库用于检索增强生成(RAG),事务性数据库用于处理上下文和个性化,而内存数据库则负责缓存。在后端,数据湖存储着领域特定的数据,数据流用于追踪随时间变化的数据,数据管道则执行模型微调、封闭域训练和嵌入生成等任务。数据治理方面涉及确保数据质量和隐私。
数据服务在生成式 AI 应用中的作用

为数据基础提供整套服务

亚马逊云科技提供了一套全面的工具,旨在满足不同规模、类型和用途的数据需求,以及满足众多使用者的多样性。从存储、查询和分析数据到实际应用中的生成式 AI,我们提供了端到端的数据解决方案。
数据湖中存储的信息可用于模型训练和微调。亚马逊云科技多年来一直在构建坚实的数据湖基础,通过服务如 Amazon S3、Amazon Glue 和 Amazon Lake Formation,支持摄取、存储和访问结构化和非结构化数据。其中,S3 作为高度耐用的服务,提供 99.999999999%(11个九)的数据保存可靠性,为全球范围内数百万应用程序存储数据,拥有超过 700,000 个运行在 S3 上的数据湖客户。
亚马逊云科技为生成式 AI 应用提供多种作为知识源的选择。例如,NoSQL 数据库存储对话状态和历史,事务性数据库存储上下文和客户信息。亚马逊云科技提供关系型和专用数据库,经过优化,以提供最佳性价比,同时 Amazon Kendra 则作为智能企业搜索服务,连接到多个结构化和非结构化内容存储库,为 LLMs 提供文档级的知识源。
生成式 AI 应用使用嵌入,即对文本、图像、视频和音频等数据进行的数值表示,捕捉语义含义,以满足用户查询的需求。向量数据库专为高效存储和检索嵌入而设计。亚马逊云科技提供对流行服务的向量数据库支持,包括 Amazon RDS、Amazon Aurora 和 Amazon OpenSearch Service(包括 Serverless)。数据仓库也可用于微调、RAG 以及需要实时运营数据的应用场景,如 Amazon Redshift,提供比其他云数据仓库高达 5 倍的性价比。最后,Amazon Bedrock 为基础模型提供私密定制,直接与 Amazon S3 集成。我们的目标是通过这些解决方案构建强大的数据战略,满足各行业和规模的需求。
生成式 AI 工作流中的数据安全

在生成式 AI 应用的落地过程中,安全和隐私也是一个非常重要的考虑因素,以下是生成式 AI 工作流中需要考虑的安全因素:
1、用户权限筛选:在向量数据存储中,需要根据用户权限进行筛选。这意味着只有经过授权的用户可以访问特定数据,以确保数据的安全性和隐私保护。
2、结构化数据请求的权限筛选:生成式 AI 应用可能接收来自用户的结构化数据请求。在处理这些请求时,需要考虑用户的权限,以确保只有符合权限要求的用户可以访问和操作相关数据。
3、大模型的评估与用户权限匹配:在生产大模型时,需要评估该模型是否符合用户的权限要求。这可以通过模型训练过程中的数据筛选和访问控制来实现,以确保生成式 AI 应用的输出结果与用户权限保持一致。
总结
整体来说,通过选择合适的应用场景、持续学习和实践,使生成式 AI 应用能够带来更多的创新和价值。让我们积极迎接生成式 AI 的未来,开启数据+生成式 AI 的探索之旅吧!

请持续关注亚马逊云开发者微信公众号,了解更多面向开发者的技术分享和云开发动态!
本篇作者

王宇博
亚马逊云科技大中华区开发者关系总监,致力于新一代信息技术与创新在开发者中的布道推广,以及开发者社区和生态体系的建设。他此前担任亚马逊云科技高级产品经理多年,负责云原生、大数据和机器学习等相关产品的业务和市场拓展。在加入亚马逊云科技之前,他曾在多家跨国企业担任产品、技术和管理等岗位,具有近 20年的 IT 行业经验与实践,同时在计算机视觉、模式识别等领域也有多年的科研经历。
星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!
