Python实战:爬取哔哩哔哩网站“每周必看”栏目
从 2019 年 3 月第 1 期开始,哔哩哔哩官方每周会汇总一次本周必看视频,截止 2024 年 1 月 22 日,已经更新了 252 期。
今天,我们就爬取“每周必看”这个栏目的 252 期视频,获取视频名称、视频封面、up 主、播放量、弹幕量、点赞投币量等信息。
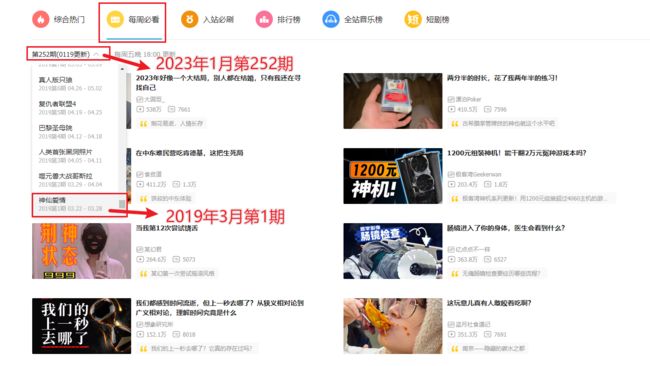
目标网址https://www.bilibili.com/v/popular/weekly?num=252
分析网页
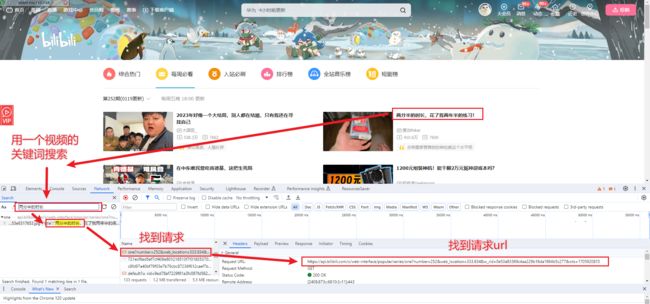
请求 url 为 https://api.bilibili.com/x/web-interface/popular/series/one?number=252
通过更改number参数,就可以构建每一期的视频列表 url
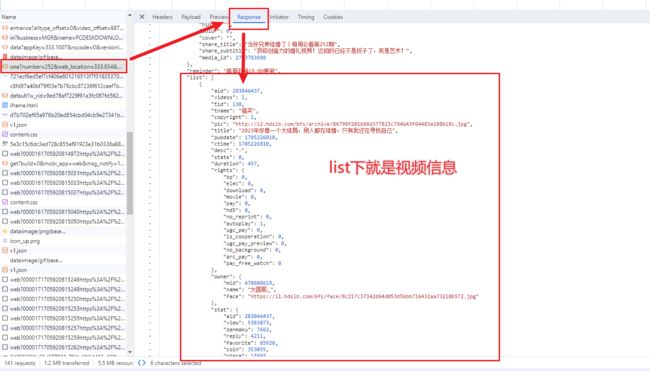
response 内就是每一期视频相关信息,包括视频名称、图片地址、播放量、点赞投币转发、up 主信息等内容。
开始爬取
因为更新到 252 期,建立一个 for 循环,从第 1 起爬到第 152 期。创建一个 DataFrame 类型的 content 对象,存放爬到的所有数据。
import requests
import pandas as pd
#
content = pd.DataFrame()
for num in range(1, 253):
url = f"https://api.bilibili.com/x/web-interface/popular/series/one?number={num}"
headers = {
"Cookie": "",
"User-Agent": ""
}
response_json = requests.get(url=url, headers=headers).json()
df = pd.json_normalize(response_json['data']['list'], errors='ignore')
df['num'] = num
content = pd.concat([content, df])
print("第", num, "期,本期", df.shape[0], "条,总计", content.shape[0], "条")
防止被检测到,每次循环设置一个睡眠等待时间
import time
time.sleep(3)
通过 252 次循环,就可以爬到所有的数据了,接下来对数据排列顺序进行调整,把我们想看数据排在前面,方便阅读。
重新排序
由于原始的字段排序比较乱,对数据列重新排序,将列的名称按需要进行手动排序,运行代码如下:
# 列重新排序
content = content.loc[:,
['num', 'owner.name', 'owner.mid', 'title', 'desc', 'dynamic', 'rcmd_reason', 'tname', 'tid',
'dimension.width', 'dimension.height', 'short_link_v2', 'stat.view', 'stat.vv', 'stat.danmaku',
'stat.reply', 'stat.like', 'stat.favorite', 'stat.coin', 'stat.share', 'aid', 'stat.aid',
'cid', 'bvid', 'videos', 'copyright', 'owner.face', 'pic', 'pubdate', 'ctime', 'state', 'duration',
'season_type', 'is_ogv', 'ogv_info', 'enable_vt', 'ai_rcmd', 'rights.bp', 'rights.elec', 'rights.download',
'rights.movie', 'rights.pay', 'rights.hd5', 'rights.no_reprint', 'rights.autoplay', 'rights.ugc_pay',
'rights.is_cooperation', 'rights.ugc_pay_preview', 'rights.no_background', 'rights.arc_pay',
'rights.pay_free_watch', 'stat.now_rank', 'stat.his_rank', 'stat.dislike', 'stat.vt', 'dimension.rotate',
'pub_location', 'season_id', 'mission_id', 'order_id', 'up_from_v2', 'first_frame', 'redirect_url',
'premiere.state', 'premiere.start_time', 'premiere.room_id']]
保存数据
将包含所有视频信息的 content 对象导出为一个 excel 文件,保存到本地。
正常情况下保存到 excel 文件都没问题,但是!这次遇到了不正常情况!没那么简单!
例如在第 143 期,由于字符串中含有特殊字符,导致保存环节报错,截图如下:

使用下面代码 pandas 写入 excel 时报错。
content.to_excel(f'小破站-每周必看-总252期-总计{content.shape[0]}条.xlsx', index=False)
由于含有不支持的字符会导致保存报错,需要再写入原文件前清除 openpyxl 不支持的字符。
参考 https://blog.csdn.net/koxb/article/details/131718681
from openpyxl.cell.cell import ILLEGAL_CHARACTERS_RE
# 写入原文件前清除openpyxl不支持的字符
for col in content.columns:
content[col] = content[col].apply(lambda x: ILLEGAL_CHARACTERS_RE.sub(r'', str(x) if not pd.isna(x) else ''))
with pd.ExcelWriter(f"小破站-每周必看-总252期-总计{content.shape[0]}条.xlsx", engine='openpyxl',
mode='w') as writer:
content.to_excel(writer, index=False)
print(f"保存完成!总计{content.shape[0]}条")
完整代码
终于!找到了 url,循环爬完了数据,也顺利保存到本地了。完整代码如下:
import requests
import pandas as pd
import time
from openpyxl.cell.cell import ILLEGAL_CHARACTERS_RE
# content存放爬到的所有数据。
content = pd.DataFrame()
for num in range(1, 253):
url = f"https://api.bilibili.com/x/web-interface/popular/series/one?number={num}"
headers = {
"Cookie": "", #切换自己的
"User-Agent": "" #切换自己的
}
response_json = requests.get(url=url, headers=headers).json()
df = pd.json_normalize(response_json['data']['list'], errors='ignore')
df['num'] = num
content = pd.concat([content, df])
print("第", num, "期,本期", df.shape[0], "条,总计", content.shape[0], "条")
time.sleep(3)
# 列重新排序
content = content.loc[:,
['num', 'owner.name', 'owner.mid', 'title', 'desc', 'dynamic', 'rcmd_reason', 'tname', 'tid',
'dimension.width', 'dimension.height', 'short_link_v2', 'stat.view', 'stat.vv', 'stat.danmaku',
'stat.reply', 'stat.like', 'stat.favorite', 'stat.coin', 'stat.share', 'aid', 'stat.aid',
'cid', 'bvid', 'videos', 'copyright', 'owner.face', 'pic', 'pubdate', 'ctime', 'state', 'duration',
'season_type', 'is_ogv', 'ogv_info', 'enable_vt', 'ai_rcmd', 'rights.bp', 'rights.elec', 'rights.download',
'rights.movie', 'rights.pay', 'rights.hd5', 'rights.no_reprint', 'rights.autoplay', 'rights.ugc_pay',
'rights.is_cooperation', 'rights.ugc_pay_preview', 'rights.no_background', 'rights.arc_pay',
'rights.pay_free_watch', 'stat.now_rank', 'stat.his_rank', 'stat.dislike', 'stat.vt', 'dimension.rotate',
'pub_location', 'season_id', 'mission_id', 'order_id', 'up_from_v2', 'first_frame', 'redirect_url',
'premiere.state', 'premiere.start_time', 'premiere.room_id']]
# 写入原文件前清除openpyxl不支持的字符
for col in content.columns:
content[col] = content[col].apply(lambda x: ILLEGAL_CHARACTERS_RE.sub(r'', str(x) if not pd.isna(x) else ''))
with pd.ExcelWriter(f"小破站-每周必看-总252期-总计{content.shape[0]}条.xlsx", engine='openpyxl',
mode='w') as writer:
content.to_excel(writer, index=False)
print(f"保存完成!总计{content.shape[0]}条")
pycharm 控制台输出如下,爬完 252 期,获取到 8697 条数据:

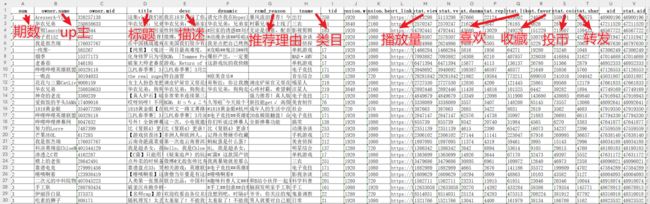
保存的 excel 表如下,数据维度还是很丰富的:
数据分析
哈哈,数据分析这一部分留着下一期再写。
之前一直用 pyecharts 库进行数据可视化,下期准备试试大名鼎鼎的 matplotlib 库。
总结
本次爬虫还是很简单的一个案例,但是在最后保存数据环节翻了船。
可以采用每爬一页数据就保存一个 excel 文件的方式,减少重复爬取一次的损失。
更好的方式是在进行数据保存之前,做一下数据处理,删除特殊字符。
本文首发在“程序员coding”公众号,欢迎关注与我一起交流学习。