c语言进阶(2)
关键字
sizeof
sizeof是函数吗?不是,它是关键字或操作符。

上面三种是正确的。
并且我们有一个想法,为什么要有数据类型呢?直接丢给变量一整块空间让他使用不好吗。答案当然是不好,这样会导致空间浪费。本质是对内存进行合理划分。
类型在c语言中为什么有这么多种?因为应用场景不同,解决应用场景应对方式不同,需要空间的大小也不同。
sizeof不仅可以求内置类型,还能够求自定义类型。
unsigned signed
整型的储存
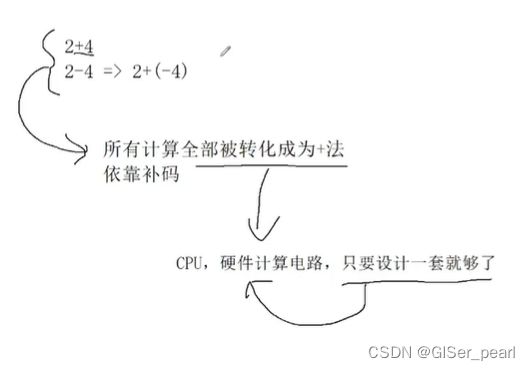
任何数据在计算机当中都必须被转化为11二进制,但这又是为什么呢?因为计算机只认识0和1。符号位(0表示正数,1表示负数)+数据位。有符号数且为正数。则原码=反码=补码。
如果是负数,原反补不相等。反码就是原码符号位不变,补码就是原码加一。那么,当补码加一的时候,符号位要不要参与运算呢?答案是要。
如果是无符号。没有符号位。
如果一直补码求原码呢?方法一:减一然后符号位不变,按位取反。
方法二:符号位不变,其他位直接按位取反。再加一。(推荐使用方法二)计算机硬件完成,只用一套系统就可以完成。![]()
补充二:整型存储的本质
下面这么定义是否正确呢?
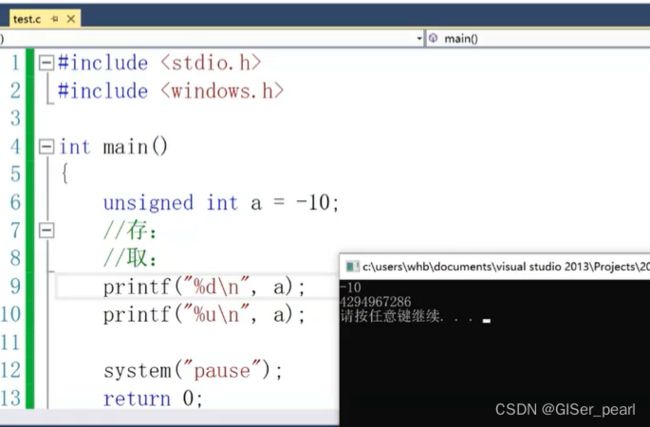
unsigned int a=10;
unsigned int b=-10;我们第一直觉往往认为这是错误的。但是,在编译器上运行的时候并没有报错。
先有空间,再有内容 。 现将内容全部转化为二进制。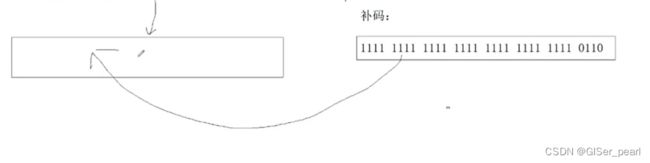
整型存储的时候,空间是不关注内容的。将数据保存在空间里时,数据已经被转化为二进制。
那么这里的变量什么时候起效果?单纯的数据是没有意义的,数字必须带上类型才有意义,是在读取的时候具有意义。 
因为这是个无符号整数,所以不用看符号位。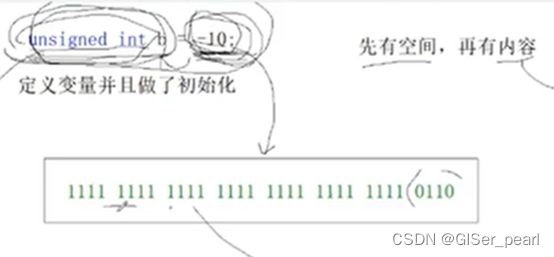
其次,这个数据的原码反码补码相等。直接转成十进制 。
如果变为signed int a,存的过程和取的过程是怎么样的呢?
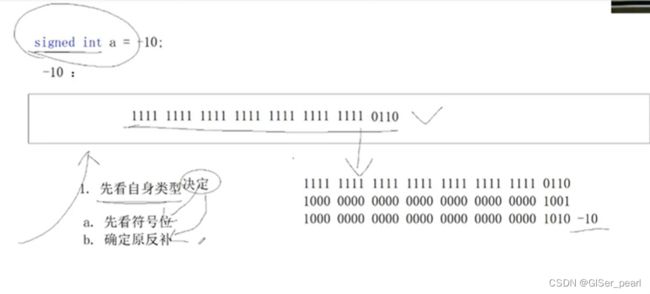
这是一个负数,确定该二进制是补码。 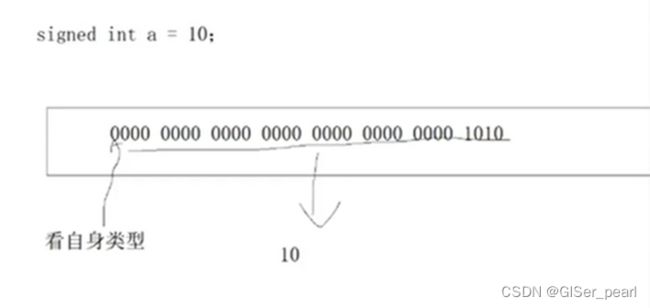
二进制快速转化 :
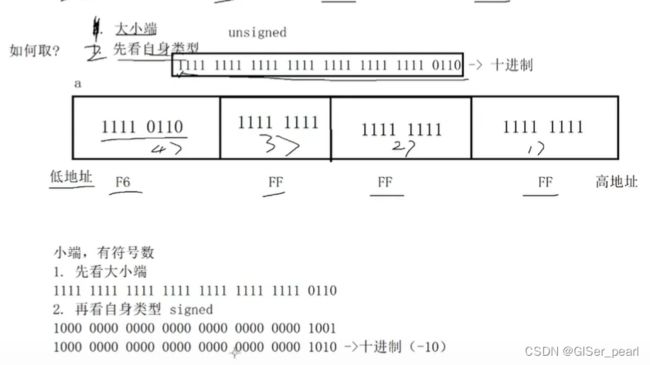
大小端

 他们两个对应的二进制序列在内存中是完全一样的,而值不同,是因为对其解释不同
他们两个对应的二进制序列在内存中是完全一样的,而值不同,是因为对其解释不同
取:一定要看对应的数据变量的类型
如何理解大小端:
基本概念:
如何取?无论如何放,只要取的规则相同,都可以。内存硬件厂商决定。
由此产生了两种解决方案:大小端。

大小端存储方案,本质上是数据和空间按字节为单位的一种映射关系


那么这里,为什么出现了第九个比特位呢?十进制转二进制是一种计算,计算的过程需要软硬件参与。可以出现第九个比特位。
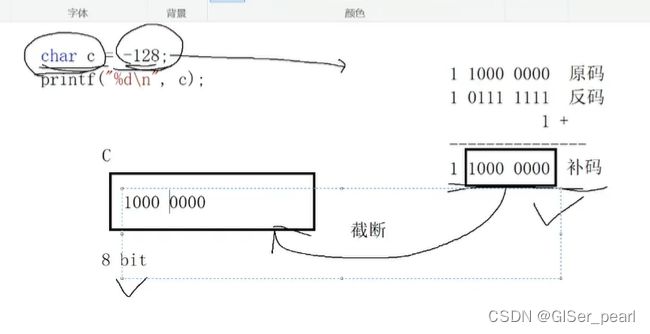
截断是不是发生了错误?是的。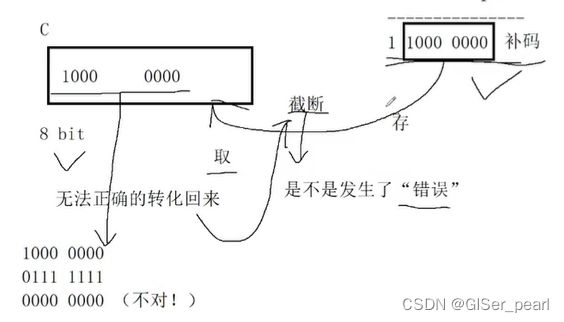
半计算半规定的一种方式。

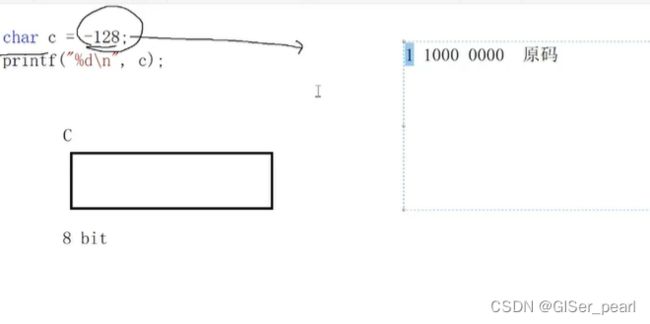
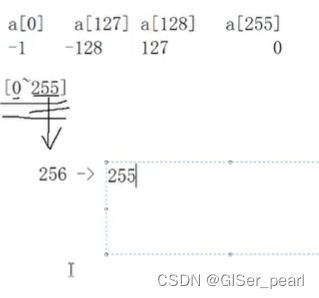
-128在存入过程当中半计算,半截断。

\0的字面值本身就是0,他只不过是char类型的一种表示。

\0以整形输出,结果就是0。而真正的字符0其实并不是0,而是48。‘\0'代表的是字符,被设置为0值。char c=0这样写是没有问题的,但是不便于用户理解。
那么,我们就理解了,对于多少位,应该是这样一个范围:
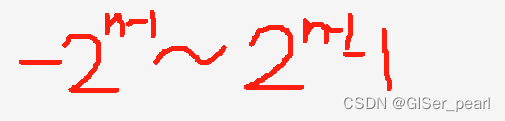
那么,就让我们根据一些练习题练习一下,看看是否掌握了吧

int i=-20,等于2的4次方+2的2次方,因为都是4个字节,所以都是32个比特位。
原码:1000 0000 0000 0000 0000 0000 0001 0100
反码:1111 1111 1111 1111 1111 1111 1110 1011
补码:1111 1111 1111 1111 1111 1111 1110 1100
unsigned int j=10 等于2的3次方+2的1次方
0000 0000 0000 0000 0000 0000 0000 1010
+ 1111 1111 1111 1111 1111 1111 1110 1100
1111 1111 1111 1111 1111 1111 1111 0110
二进制序列如何被解释,取决于其类型。
bool类型
写上大写之后
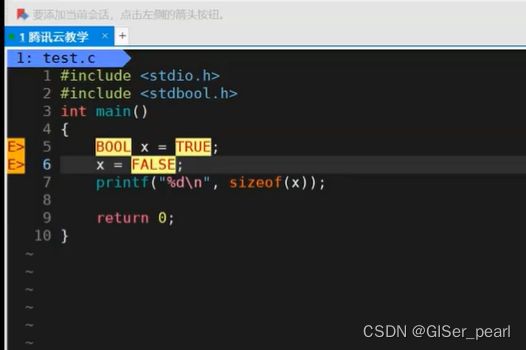
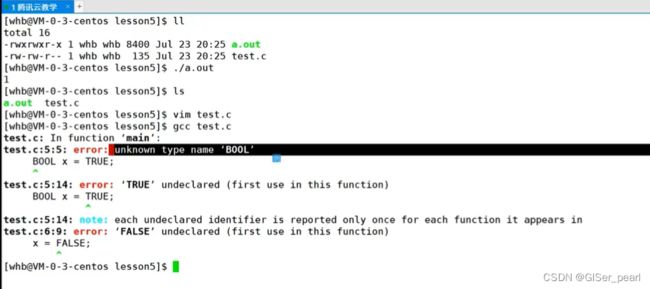
并不认识bool类型了。在windows中,可以编过,但是在Linux当中,却不行了。所以c99当中的bool类型可移植性较好。
运行下面这个程序:

我们会发现输出结果是1 2 3。 第一种比较方法不推荐,因为我们会误认为是整数比较。第二种方法也不推荐,false只有C99支持。更推荐第三种写法,写执行括号中的函数或者表达式,得到的都是true或者false,得到的都是逻辑结果,flag本身就是逻辑结果, 先执行判定功能,再执行分支功能。

变量的命名规则
规则一:见名知意
规则二:
规则三: 规则四:尽量避免在变量中使用数字
规则四:尽量避免在变量中使用数字
规则五:(少用)

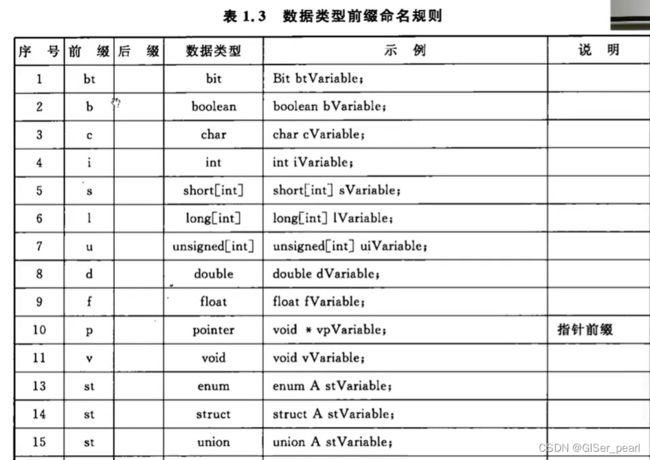

规则十三:
 规则十六:
规则十六:
浮点类型
小数默认是以double类型存储的。浮点数在类型中的存储,不是我们所想的是完整存储的,在十进制转化为二进制,是有精度损失的。但也并不意味着小数位一定会减少,也有可能会增多。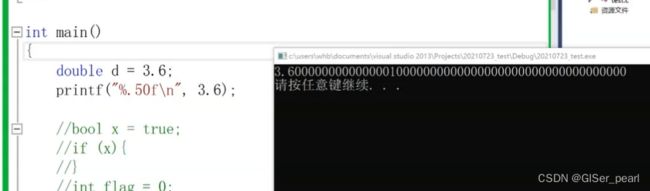
这样结果后多了一个1,说明精度丢失。
我们运行这个程序,按照常理来说,结果是0.1和0.1:

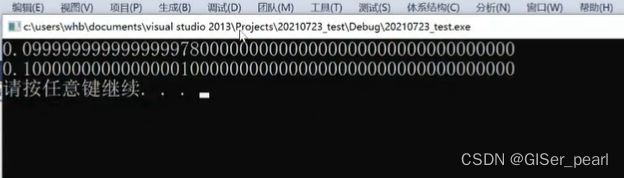
理论上0.1与x-0.9应该相等,但是却并不相等,发生了精度损失:
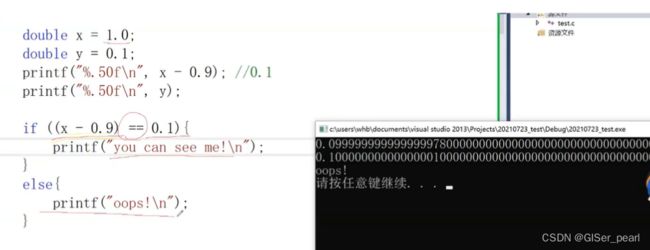 结论:浮点数不能使用==比较。
结论:浮点数不能使用==比较。
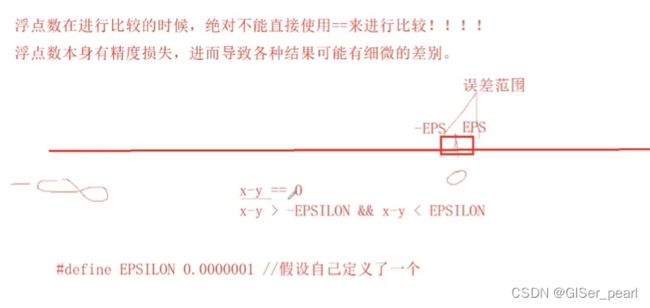
在误差范围之内,x和y可以认为是相等的。
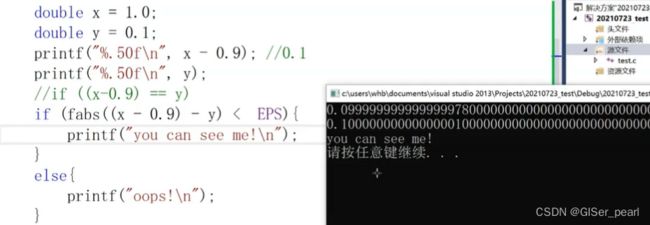 我们也可以使用DBL-EPSILON进行比较,此时需要加上头文件
我们也可以使用DBL-EPSILON进行比较,此时需要加上头文件
如果是下面这样一个范围,就可以证明x和y是相等的。这里的精度有两种定义方式,一种是使用系统自带的,一种是自定义。
浮点值的比较
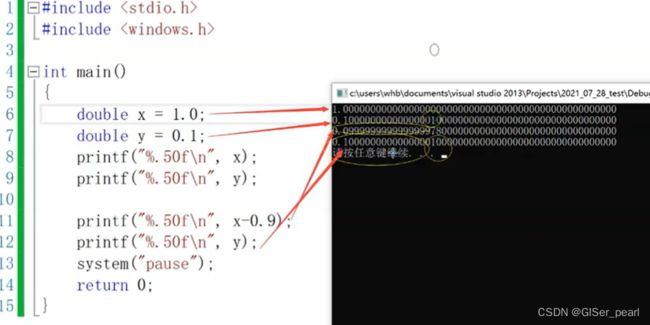
由此说明两个浮点数是不能直接由两个双等号直接比较的。当我们设置精度小于时自定义最小精度或系统最小精度可以运行:
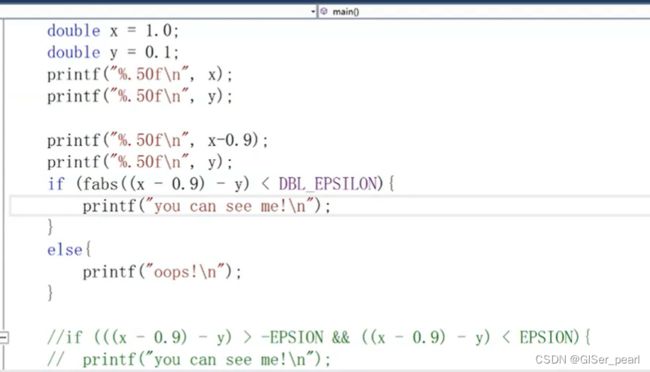 那么,在精度比较的时候,要不要相等呢?不能相等,因为这个值是使不等于精度的最小值。
那么,在精度比较的时候,要不要相等呢?不能相等,因为这个值是使不等于精度的最小值。

强制类型转化并不改变数据二进制的值,只改变我们如何去解释这个值(类型
真实的转化会改变内存当中的数据。如果写作(NULL==p)是更好的,因为一旦少写一个等号,编译器就会报错。
else中采用就近原则,下面这个代码啥也打印不出来:

这个代码会打印hello 世界!

如果采用花括号,就是如下的形式:

在如下这个语句中,可以打印出hello world:
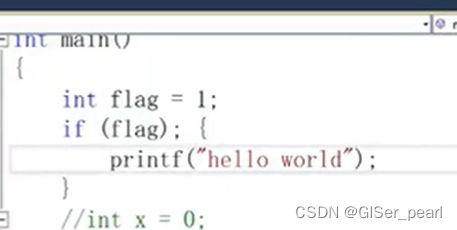
在这个代码中,分号和if匹配了,所以printf这个语句总是会执行的。
swtich既没有判断功能,也没有分支功能,它是拿着输入的值一次匹配。

下篇主要介绍关键字,敬请期待!