Kafka-服务端-日志存储
基本概念
首先需要了解的是,Kafka使用日志文件的方式保存生产者发送的消息。每条消息都有一个offset值来表示它在分区中的偏移量,这个offset值是逻辑值,并不是消息实际存放的物理地址。
offset值类似于数据库表中的主键,主键唯一确定了数据库表中的一条记录,offset唯一确定了分区中的一条消息。Kafka存储机制在逻辑上如图所示。
 为了提高写入的性能,同一个分区中的消息是顺序写入的,这就避免了随机写入带来的性能问题。
为了提高写入的性能,同一个分区中的消息是顺序写入的,这就避免了随机写入带来的性能问题。
一个Topic可以划分成多个f分区,而每个分区又有多个副本。当一个分区的副本(无论是Leader副本还是Follower副本)被划分到某个Broker上时,Kafka就要在此Broker上为此分区建立相应的Log,而生产者发送的消息会存储在Log中,供消费者拉取后消费。
Kafka中存储的一般都是海量消息数据,为了避免日志文件太大,Log并不是直接对应于磁盘上的一个日志文件,而是对应磁盘上的一个目录,这个目录的命名规则是
Kafka通过分段的方式将Log分为多个LogSegment,LogSegment是一个逻辑上的概念,一个LogSegment对应磁盘上的一个日志文件和一个索引文件,其中日志文件用于记录消息,索引文件中保存了消息的索引。
随着消息的不断写入,日志文件的大小到达一个阈值时,就创建新的日志文件和索引文件继续写入后续的消息和索引信息。
日志文件的文件名的命名规则是[baseOffset].log,baseOffset是日志文件中第一条消息的offset。

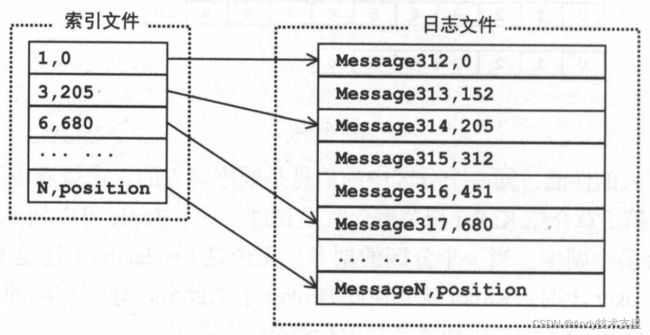
为了提高查询消息的效率,每个日志文件都对应一个索引文件,这个索引文件并没有为每条消息都建立索引项,而是使用稀疏索引方式为日志文件中的部分消息建立了索引。
图展示了索引文件与日志文件之间的对应关系。
FileMessageSet
在Kafka中使用FileMessageSet管理上文介绍的日志文件,它对应磁盘上的一个真正的日志文件。
FileMessageSet继承了MessageSet抽象类,如图所示。

MessageSet中保存的数据格式分为三部分,如图所示:8字节的offset值,4字节的size表示message data大小,这两部分组合成为LogOverhead,message data部分保存了消息的数据,逻辑上对应一个Message对象。
Kafka使用Message类表示消息,Message使用ByteBuffer保存数据,其格式及各个部分的含义如图所示。

- CRC32:4个字节,消息的校验码。
- magic:1字节,魔数标识,与消息格式有关,取值为0或1。当magic为0时,消息的offset使用绝对offset且消息格式中没有timestamp部分;当magic为1时,消息的offset使用相对offset且消息格式中存在timestamp部分。所以,magic值不同,消息的长度是不同的。
- attributes:1字节,消息的属性。其中第0~2位的组合表示消息使用的压缩类型,0表示无压缩,1表示gzip压缩,2表示snappy压缩,3表示lz4压缩。第3位表示时间戳类型,0表示创建时间,1表示追加时间。
- timestamp:时间戳,其含义由attribute的第3位确定。
- key length:消息key的长度。
- key:消息的key。
- value length:消息的value长度。
- value:消息的value。
MessageSet抽象类中定义了两个比较关键的方法;
//将当前MessageSet中的消息写入到Channe1中
def writeTo(channel:GatheringByteChannel,offset:Long,maxsize:Int):Int
//提供迭代器,顺序读取MessageSet中的消息
def iterator:Iterator[MessageAndoffset]
这两个方法说明MessageSet具有顺序写入消息和顺序读取的特性。
在后面对FileMessageSet和ByteBufferMessageSet的介绍过程中会介绍这两个方法的实现。
了解了MessageSet抽象类以及其中保存消息的格式,我们开始分析FileMessageSet实现类。FileMessageSet的核心字段如下所述。
- file:java.io.File类型,指向磁盘上对应的日志文件。
- channel:FileChannel类型,用于读写对应的日志文件。
- start和end:FileMessageSet对象除了表示一个完整的日志文件,还可以表示日志文件分片(Slice),start和end表示分片的起始位置和结束位置。
- isSlice:Boolean类型,表示当前FileMessageSet是否为日志文件的分片。
- _size:FileMessageSet大小,单位是字节。如果FileMessageSet是日志文件的分片,则表示分片大小(即end-start的值);如果不是分片,则表示整个日志文件的大小。注意,因为可能有多个Handler线程并发向同一个分区写入消息,所有_size是AtomicInteger类型。
在FileMessageSet中有多个重载的构造方法,这里选择一个比较重要的方法进行介绍。
此构造方法会创建一个非分片的FileMessageSet对象。在Window NTFS文件系统以及老版本的Linux文件系统上,进行文件的预分配会提高后续写操作的性能,为此FileMessageSet提供了preallocate的选项,决定是否开启预分配的功能。
我们也可以通过FileMessageSet构造函数的mutable参数决定是否创建只读的FileMessageSet。
ByteBufferMessageSet
MessageSet的另一个子类是ByteBufferMessageSet,FileMessageSet.append方法的参数就是此类的对象。
为什么必须append方法的参数是ByteBufferMessageSet,而不是直接使用ByteBuffer呢?
向MemoryRecords写入消息时,可以使用Compressor对消息批量进行压缩,然后将压缩后的消息发送给服务端。
在有些设计中,将每个请求的负载单独压缩后再进行传输,这种设计虽然可以减小传输的数据量,但是存在一个小问题,我们常见压缩算法是数据量越大压缩率越高,一般情况下每个请求的负载不会特别大,这就导致压缩率比较低。
Kafka实现的压缩方式是将多个消息一起进行压缩,这样就可以保证较高的压缩率。
而且在一般情况下,生产者发送的压缩数据在服务端也是以保持压缩状态进行存储的,消费者从服务端获取的也是压缩消息,消费者在处理消息之前才会解压消息,这也就实现了“端到端的压缩”。
压缩后的消息格式与非压缩的消息格式类似,但是分为两层,如图所示。

迭代压缩消息
上文提到,消费者获取的压缩消息格式与生产者发送出去的格式应该一模一样。
Fetcher.parseFetchedData()方法解析CompleteFetch时,对MemoryRecords进行迭代。
下面来看看MemoryRecords的迭代器的相关实现,其中就涉及与压缩消息相关的实现。
MemoryRecords的迭代器是其静态内部类RecordsIterator,它继承了Abstractlterator抽象类。AbstractIterator实现了Iterator接口,它对Iterator进行了实现和简化。
AbstractIterator只暴露了一个makeNext抽象方法供子类实现,此方法主要负责用于创建下一个迭代项。
这样,开发人员就不用了解Iterator接口的实现细节了,只关注如何创建下一迭代项即可。
Abstractlterator中使用next字段指向迭代的下一项,使用state字段标识当前迭代器的状态,state字段是State枚举类型,其取值和含义如下所述。
- READY:迭代器已经准备好迭代下一项。
- NOT_READY:迭代器未准备好迭代下一项,需要调用maybeComputeNext)。
- DONE:当前迭代已经结束。
- FAILED:当前迭代器在迭代过程中出现异常。
为了同时能够处理压缩消息和非压缩消息,MemoryRecords.RecordsIterator分为两层迭代,使用shallow参数标区分。
当shallow为true时,认为消息是非压缩消息,只迭代当前这一层消息,为方便描述,我们称之为“浅层迭代”(shallow iteration);当shallow为false时,不只迭代当前层消息,还会创建Inner Iterator(也是MemoryRecords.RecordsIterator对象)迭代嵌套的压缩消息,我们称之为“深层迭代”(deep iteration)。
OffsetIndex
为了提高查找消息的性能,从Kafka 0.8版本开始,为每个日志文件添加了对应的索引文件。
Offsetlndex对象对应管理磁盘上的一个索引文件,与FileMessageSet共同构成一个LogSegment对象。
首先来介绍索引文件中索引项的格式:每个索引项为8字节,分为两部分,第一部分是相对offset,占4个字节;
第二部分是物理地址,也就是其索引消息在日志文件中对应的position位置,占4个字节。这样就实现了offset与物理地址之间的映射。
相对offset表示的是消息相对于baseOffset的偏移量。例如,分段后的一个日志文件的baseOffset是20,当然,它的文件名就是20.log,那么offset为23的Message在索引文件中的相对offset就是23-20=3。消息的offset是Long类型,4个字节可能无法直接存储消息的offset,所以使用相对offset,这样可以减小索引文件占用的空间。
Kafka使用稀疏索引的方式构造消息的索引,它不保证每个消息在索引文件中都有对应的索引项,这算是磁盘空间、内存空间、查找时间等多方面的折中。
不断减小索引文件大小的目的是为了将索引文件映射到内存,在OffsetIndex中会使用MappedByteBuffer将索引文件映射到内存中。
LogSegment
为了防止Log文件过大,将Log切分成多个日志文件,每个日志文件对应一个LogSegment。
在LogSegment中封装了一个FileMessageSet和一个OffsetIndex对象,提供日志文件和索引文件的读写功能以及其他辅助功能。
下面先来看LogSegment的核心字段。
- log:用于操作对应日志文件的FileMessageSet对象。
- index:用于操作对应索引文件的OffsetIndex对象。
- baseOffset:LogSegment中第一条消息的offset值。
- indexIntervalBytes:索引项之间间隔的最小字节数。
- bytesSinceLastIndexEntry:记录自从上次添加索引项之后,在日志文件中累计加入的Message集合的字节数,用于判断下次索引项添加的时机。
- created:标识LogSegment对象创建时间,当调用truncateTo()方法将整个日志文件清空时,会将此字段重置为当前时间。
LogSegment中还有一个值得注意的方法是recover()方法,其主要功能是根据日志文件重建索引文件,同时验证日志文件中消息的合法性。
在重建索引文件过程中,如果遇到了压缩消息需要进行解压,主要原因是因为索引项中保存的相对offset是第一条消息的offset,而外层消息的offset是压缩消息集合中的最后一条消息的offset。
Log
Log是对多个LogSegment对象的顺序组合,形成一个逻辑的日志。
为了实现快速定位LogSegment,Log使用跳表(SkipList)对LogSegment进行管理。
跳表是一种随机化的数据结构,它的查找效率和红黑树差不多,但是插入/删除操作却比红黑树简单很多。目前在Redis等开源软件中都能看到它的身影,在JDK中也提供了跳表的实现——ConcurrentSkipListMap,而且ConcurrentSkipListMap还是一个线程安全的实现。
在Log中,将每个LogSegment的baseOffset作为key,LogSegment对象作为value,放入segments这个跳表中管理,如图所示。
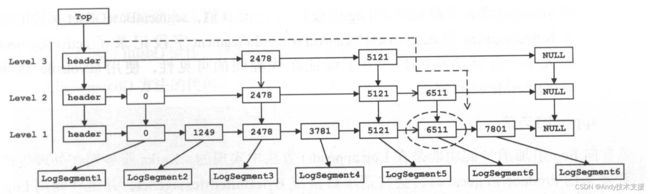
们现在要查找offset大于6570的消息,可以首先通过segments快速定位到消息所在的LogSegment对象,定位过程如图中的虚线所示。之后使用前面介绍的LogSegment.read方法,先按照OffsetIndex进行索引,然后从日志文件中进行读取。
向Log中追加消息时是顺序写入的,那么只有最后一个LogSegment能够进行写入操作,在其之前的所有LogSegment都不能写入数据。
最后一个LogSegment使用Log.activeSegment方法获取,即segments集合中最后一个元素,为了描述方便,我们将此Segment对象称为“activeSegment”。
随着数据的不断写入,当activeSegment的日志文件大小到达一定阈值时,就需要创建新的activeSegment,之后追加的消息将写入新的activeSegment。
介绍完了Log的基本原理后,来看一下Log类中的关键字段。
- dir:Log对应的磁盘目录,此目录下存放了每个LogSegment对应的日志文件和索引文件。
- lock:可能存在多个Handler线程并发向同一个Log追加消息,所以对Log的修改操作需要进行同步。
- segments:用于管理LogSegment集合的跳表。
- config:Log相关的配置信息。
- recoveryPoint:指定恢复操作的起始offset,recoveryPoint之前的Message已经刷新到磁盘上持久存储,而其后的消息则不一定,出现宕机时可能会丢失。所以只需要恢复recoveryPoint之后的消息即可。
- nextOffsetMetadata:LogOffsetMetadata对象。主要用于产生分配给消息的offset,同时也是当前副本的LEO(LogEndOffset)。
最后来看flush方法的原理,如图所示,fush方法会将recoverPoint~LEO之间的消息数据刷新到磁盘上,并修改recoverPoint值。