Kafka-服务端-DelayedOperationPurgatory
DelayedOperationPurgatory是一个相对独立的组件,它的主要功能是管理延迟操作。
DelayedOperationPurgatory的底层依赖于Kafka提供的时间轮实现。
我们可以使用JDK本身提供的java.util.Timer或是DelayQueue轻松实现定时任务的功能,为什么Kafka还要专门开发DelayedOperationPurgatory组件呢?这主要是因为像Kafka这种分布式系统的请求量巨大,性能要求也很高,JDK提供java.util.Timer和DelayedQueue底层实现使用的是堆这种数据结构,存取操作的复杂度都是O(nlog(n)),无法支持大量的定时任务。
在高性能的框架中,为了将定时任务的存取操作以及取消操作的时间复杂度降为O(1),一般会使用其他方式实现定时任务组件,例如,使用时间轮的方式。这种做法还是比较多见的,例如,ZooKeeper中使用“时间桶”的方式处理Session过期,Netty也提供了HashedWheelTimer这种时间轮的实现,Quartz框架中也有时间轮的身影。
TimingWheel
Kafka的时间轮实现是TimingWheel,它是一个存储定时任务的环形队列,底层使用数组实现,数组中的每个元素可以存放一个TimerTaskList对象。
TimerTaskList是环形双向链表,在其中的链表项TimerTaskEntry中封装了真正的定时任务TimerTask。
TimerTaskList使用expiration字段记录了整个TimerTaskList的超时时间。
TimerTaskEntry中的expirationMs字段记录了超时时间戳,timerTask字段指向了对应的TimerTask任务。TimeTask中的delayMs记录了任务的延迟时间,timerTaskEntry字段记录了对应的TimerTaskEntry对象。
这三个对象是TimingWheel实现的基础。
TimingWheel提供了层级时间轮的概念,如图所示。
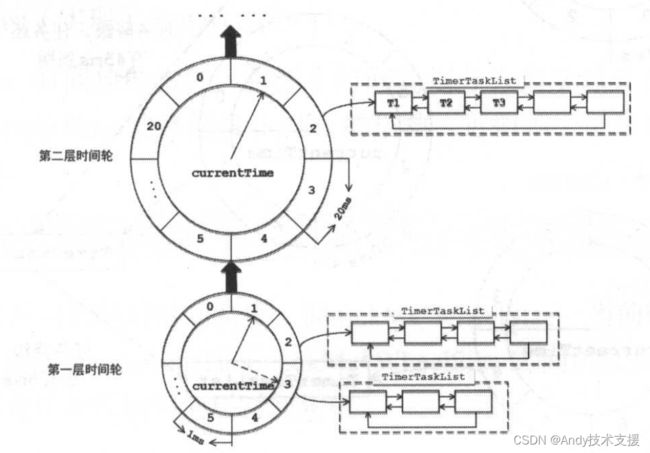
第一层时间轮的时间跨度比较小,而第二层时间轮的时间跨度比较大。存放在同一TimerTaskList中的TimerTask到期时间可能不同,但是都由一个时间格覆盖。
现假设图中第二层时间轮中编号为2的时间格保存的TimerTaskList到期时间为t,其中保存的任务的到期时间只能是[t~t+20ms]这个范围,例如T1的过期时间可以为t+10ms,任务T2的过期时间可以为t+15ms,T3的过期时间可以为t+12ms。
如果任务到期时间不在[t~t+20ms]这个时间段,则只能放到其他的时间格对应的TimerTaskList中保存。
当任务到期时间超出了当前时间轮所表示的时间范围时,会尝试添加到上层时间轮。依然以图为例,其中第一层时间轮的每个时间格是1ms,整个时间轮的跨度是20ms,其表针currentTime当前表示的时间ct,则该时间轮的跨度为[ct~ct+20ms],只有到期时间在这段范围内的任务才能添加到该时间轮中等待到期。
到期时间超出[ct~ct+20ms]这个时间范围的任务会尝试添加到其上级时间轮中,通过逐层向上尝试,最终找到合适的时间轮层级。
整个时间轮表示的时间跨度是不变的,随着表针currentTime的后移,当前时间轮能处理时间段也在不断后移,新来的TimerTaskEntry会复用原来已经到期的TimerTaskList。
如图所示,第一层时间轮的时间跨度始终为20ms,表针currentTime表示的时间随着时间的流逝不断后移,指向了第三个时间格,此时表针currentTime表示的时间为ct+3ms,整个时间轮表示的时间段是[ct+3ms~ct+23ms],但是该时间轮的时间跨度依然是20ms。
此时该时间轮中编号为2的时间格表示的时间范围不再是[ct+1ms ~ ct+2ms],而是[ct+22ms ~ ct+23ms]。
最后用一个示例详细介绍时间轮降级场景,如图所示。
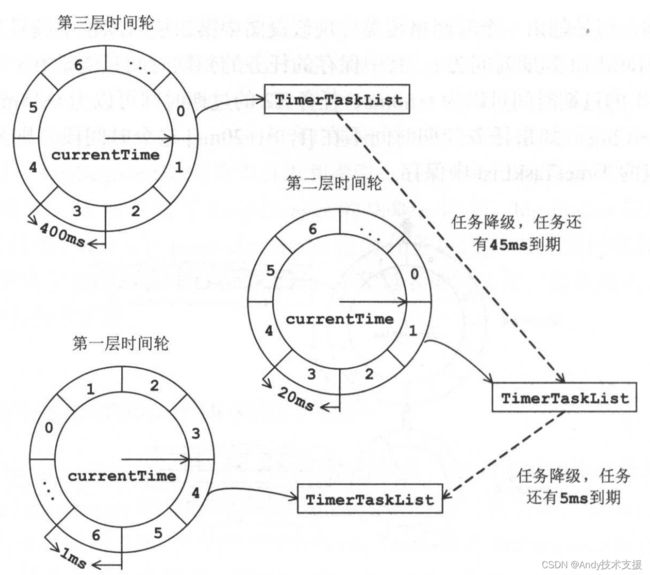
现在有一个任务是在445ms后执行,默认情况下,各个层级的时间轮的时间格个数为20,第一层时间轮每个时间格的跨度为1ms,整个时间轮的跨度为20ms,跨度不够。
第二层时间轮时间格的跨度为20ms,整个时间轮的跨度为400ms,跨度依然不够。
第三层时间轮时间格的跨度为400ms,整个时间轮的跨度为8000ms,跨度足够,此任务存放在第三层时间轮的第一个时间格对应的TimerTaskList中等待执行,此TimerTaskList到期时间是400ms。
随着时间的流逝,当此TimerTaskList到期时,距离该任务的到期时间还有45ms,不能执行任务。
我们将其重新提交到层级时间轮中,此时第一层时间轮跨度依然不够,但是第二层时间轮的跨度足够,该任务会被放到第二层时间轮第三个时间格中等待执行。
如此往复几次,高层时间轮的任务会慢慢移动到低层时间轮上,最终任务到期执行。
介绍完了时间轮的基本概念之后,下面开始分析TimingWheel的具体实现,其核心字段的含义如下所述。
-
buckets:Array.tabulate[TimerTaskList]类型,其每一个项都对应时间轮中的一个时间格,用于保存TimerTaskList的数组。在TimingWheel中,同一个TimerTaskList中的不同定时任务的到期时间可能不同,但是相差时间在一个时间格的范围内。
-
tickMs:当前时间轮中一个时间格表示的时间跨度。
-
wheelSize:当前时间轮的格数,也是buckets数组的大小。
-
taskCounter:各层级时间轮中任务的总数。
-
startMs:当前时间轮的创建时间。
-
queue:DelayQueue类型,整个层级时间轮共用的一个任务队列,其元素类型是TimerTaskList(实现了Delayed接口)。
-
currentTime:时间轮的指针,将整个时间轮划分为到期部分和未到期部分。在初始化时,currentTime被修剪成tickMs的倍数,近似等于创建时间,但并不是严格的创建时间。
-
interval:当前时间轮的时间跨度,即tickMswheelSize。当前时间轮只能处理时间范围在currentTime~currentTime+tickMsWheelSize之间的定时任务,超过这个范围,则需要将任务添加到上层时间轮中。
-
overflowWheel:上层时间轮的引用。
在TimeWheel中提供了add、advanceClock、addOverflowWheel三个方法,这三个方法实现了时间轮的基础功能。add方法实现了向时间轮中添加定时任务的功能,它同时也会检测待添加的任务是否已经到期。
SystemTimer
SystemTimer是Kafka中的定时器实现,它在TimeWheel的基础上添加了执行到期任务、阻塞等待最近到期任务的功能。下面来分析其核心字段。
- taskExecutor:JDK提供的固定线程数的线程池实现,由此线程池执行到期任务。
- delayQueue:各个层级的时间轮共用的DelayQueue队列,主要作用是阻塞推进时间轮表针的线程(ExpiredOperationReaper),等待最近到期任务到期。
- taskCounter:各个层级时间轮共用的任务个数计数器。
- timingWheel:层级时间轮中最底层的时间轮。
- readWriteLock:用来同步时间轮表针currentTime修改的读写锁。
SystemTimer.add方法在添加过程中如果发现任务已经到期,则将任务提交到taskExecutor中执行;如果任务未到期,则调用TimeWheel.add方法提交到时间轮中等待到期后执行。
DelayedOperation
在前面介绍ProducerRequest和FetchRequest两种请求时提到,服务端在收到这两种请求时并不是立即返回响应,可能会等待一段时间后才返回。
对于ProducerRequest来说,其中的acks字段设置为-1表示ProducerRequest发送到Leader副本之后,需要ISR集合中所有副本都同步该请求中的消息(或超时)后,才能返回响应给客户端。
ISR集合中的副本分布在不同Broker上,与Leader副本进行同步时就涉及网络通信,一般情况下我们认为网络传输是不可靠的而且是一个较慢的过程,通常采用异步的方式处理来避免线程长时间等待。
当FetchRequest发送给Leader副本后,会积累一定量的消息后才返回给消费者或Follower副本,并不是Leader副本的HW后移一条消息就立即将其返回给消费者,这是为了实现批量发送消息,提高有效负载。
Kafka利用前面介绍的SystemTimer来定期检测请求是否超时,但是这些请求真正的目的并不是为了超时执行,而是为了满足其他条件后执行,例如ProducerRequest的响应条件ISR集合中所有副本都同步了请求中的消息,所以仅使用SystemTimer就无法满足需求了。Kafka使用DelayedOperation抽象类表示延迟操作,它对TimeTask进行了扩展,除了有定时执行的功能,还提供了检测其他执行条件的功能。我们可以认为DelayedOperation是一个延迟的、异步的操作。
如图所示,DelayedOperation有四个实现类,分别表示四类不同的延迟操作,也对应了四种不同的请求。DelayedOperation是一个抽象类,completed字段是AtomicBoolean类型,标识了此DelayedOperation是否完成,初始值为false;delayMs记录了延迟操作的延迟时长。
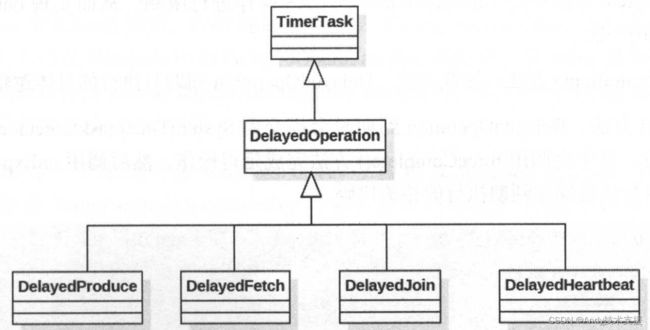
DelayedOperation可能因为到期而被提交到SystemTimertaskExecutor线程池中执行,也可能在其他线程检测其执行条件时发现已经满足执行条件,而将其执行。

DelayedOperationPurgatory
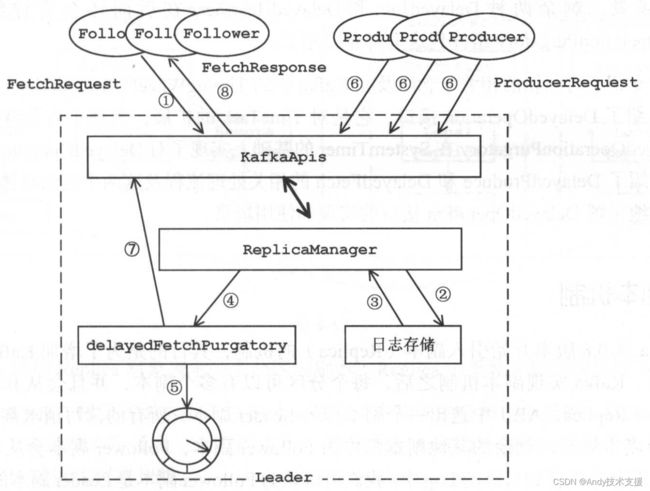
DelayedOperationPurgatory是一个辅助类,提供了管理DelayedOperation以及处理到期DelayedOperation的功能。DelayedOperationPurgatory依赖的组件如图所示。
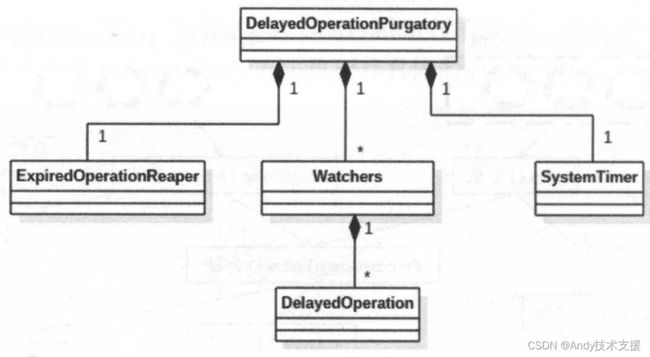
DelayedOperationPurgatory中的watchersForKey字段用于管理DelayedOperation,它是Pool[Any,Watchers]类型,Pool的底层实现是ConcurrentHashMap。
watchersForKey集合的key表示的是Watchers中的DelayedOperation关心的对象,其value是Watchers类型的对象,Watchers是DelayedOperationPurgatory的内部类,表示一个DelayedOperation的集合,底层使用LinkedList实现。
DelayedProduce
经过前面的介绍,我们已经了解了SystemTimer和DelayedOperationPurgatory的工作原理。
在详细介绍DelayedProduce的相关实现之前,先来了解一下当ProducerRequest的acks字段为-1时,服务端的处理流程:在KafkaApis中处理ProducerRequest的方法是handleProducerRequest()方法,它会调用ReplicaManager.appendMessages方法将消息追加到Log中,生成相应的DelayedProduce对象并添加到delayedProducePurgatory处理。
delayedProducePurgatory是ReplicaManager中的字段,它是专门用来处理DelayedProduce的DelayedOperationPurgatory对象。
DelayedFetch
DelayedFetch是FetchRequest对应的延迟操作,它的原理与DelayedProduce类似。
我们先来粗略分析FetchRequest的处理流程:来自消费者或Follower副本的FetchRequest由KafkaApis.handleFetchRequest()方法处理,它会调用ReplicaManager.fetchMessages()方法从相应的Log中读取消息,并生成DelayedFetch添加到delayedFetchPurgatory中处理。
delayedFetchPurgatory是ReplicaManager中的字段,它是专门用来处理DelayedFetch的DelayedOperationPurgatory对象。
零拷贝
在消费者获取消息时,服务器先从硬盘读出数据到内存,然后将内存中的数据原封不动地通过Socket发送给消费者。
虽然这个操作描述非常简单,但是其中涉及的步骤非常多,效率也比较差,尤其是当数据量较大时。
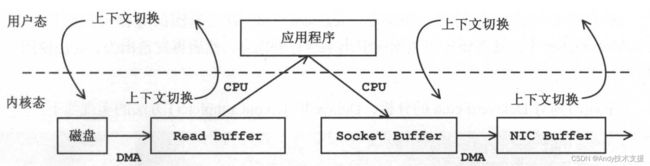
按照这种设计,其底层执行步骤大致如下:
首先,应用程序调用read方法时需要从用户态切换到内核态,将数据从磁盘上读取出来保存到内核缓冲区中;
然后,内核缓冲区中的数据传输到应用程序,此时read方法调用结束,从内核态切换到用户态;
之后,应用程序执行send方法,需要从用户态切换到内核态,将数据传输给Socket Buffer;
最后,内核会将Socket Buffer中的数据发送NIC Buffer(网卡缓冲区)进行发送,此时send方法结束,从内核态切换到用户态。
如图所示,在这个过程中涉及四次上下文切换(Context switch)以及四次数据复制,并且其中有两次复制操作由CPU完成。
但是在这个过程中,数据完成没有进行变化,仅仅是从磁盘复制到了网卡缓冲区中,会浪费大量的CPU周期。
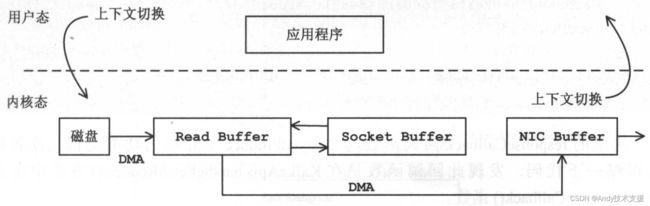
通过“零拷贝”技术可以去掉这些无谓的数据复制操作,同时也会减少上下文切换的次数。
大致步骤如下:首先,应用程序调用transferTo方法,DMA会将文件数据发送到内核缓冲区;
然后,Socket Buffer追加数据的描述信息;
最后,DMA将内核缓冲区的数据发送到网卡缓冲区,这样就完全解放了CPU,实现了零拷贝,如图所示。
我们对DelayedFetch的相关处理流程做一下总结,这里以来自Follower副本为例,如图所示。