遗传算法及其MATLAB实现(附完整代码)
遗传算法是经典的智能算法, 经常被用来求解各种N-P问题, 各种非线性函数的优化等, 可以实现各类模型的非最优解优化. 遗传算法稳定性比较强, 优化的效果比较好, 不是特别依赖初值, 尤其对离散自变量的函数优化是很合适的, 比较容易得到理论最优解, 整体的运行效率比较好, 对线性或非线性的约束都很友好.
遗传算法的大体流程如下:

流程包括:
(1)编码的设计方案, 编码就是染色体的编码, 每一个染色体都与目标函数的一个解是对应的, 也就是遗传算法的一个染色体是目标函数解的一个单射, 一个染色体唯一对应一个解(但反过来不一定, 不同的染色体可以对应同样的一个解). 编码的设计方案对于求目标函数解的可行性和效率是非常重要的, 对于不同的问题模型, 我们需要专门设计编码方案, 比如对于离散的排序问题, 我们可以设计一个自然数排序编码 [1,3,2,5,4]这样的排序编码, 来映射排序问题的自变量或解, 对于多维实数域的函数优化问题, 可以把编码设计为[0.1,0.5,1.2,1.3,2.5]这样的多维实数编码,直接对应自变量x. 如何设计编码是各类智能算法永恒的课题.
(2)读取或设置问题模型的数据和参数.
(3)设置遗传算法参数, 如种群数, 迭代次数, 交叉率, 变异率.
(4)初始化种群, 一般采用随机产生一组染色体作为算法的初始染色体.
(5)开始迭代, 进行染色体的变异操作.
(6)对染色体进行交叉操作.
(7)对染色体进行解码, 这个过程就是把染色体映射到解
(8)根据解计算目标函数值和约束,, 再把解带入问题模型,得到目标函数值以及是否满足约束等.
(9)根据解得到的目标函数对染色体进行选择, 这个选择的操作方法也是比较关键的, 这里面体现了进化论的思想, 也即适者生存, 或者适者被选中的概率更大, 久而久之,随着迭代的进行, 适应性更好的染色体会存活下来, 最后得到的是较优解, 当然如果迭代次数够充分, 种群数够大, 往往是可以得到理论最优解的, 但并不能保证你得到.
(10)输出结果, 一般包括迭代曲线和最优编码,最优解, 最优目标函数等. 进而完成了整个算法的构建和问题模型的求解.
那么如何用MATLAB实现遗传算法呢?根据以上的步骤, 我们的问题模型是:

其中xi∈[0,1], N=5
那么我们可直接采用5维实数编码构造染色体(见染色体函数mygenchrome.m) ,
初始化染色体
N=5, 上下限维[0,1]区间, 则一个合法的染色体可表示为[0.1,0.5,0.6,1.0,0.4], 完全均匀随机产生, 见染色体函数mygenchrome.m.
变异(采用单点变异)
(1) 产生一个随机自然数r1,r1表示第r1位的基因发生变异
(2) 采用随机变异的方式将第r1位的基因进行变异.
举例:
r1=2, 那么染色体的变异为
[0.1,0.5,0.6,1.0,0.4]→[0.1,0.2,0.6,1.0, 0.4]
交叉
(1) 随机选择两个染色体作为父本
(2) 产生2个随机自然数r1和r2
(3) 将两个父本染色体r1至r2之间的基因片段进行交换, 得到两个子代染色体
举例:
选择的两个父本染色体
[0.1,0.5,0.6,1.0,0.4] [0.1,0.5,0.6,0.70,0.54]
r1=2, r2=4
那么交叉过程为
[0.1,0.5,0.6,1.0,0.4] [0.1,0.5,0.6,0.7,0.54]
交叉后
[0.1,0.5,0.6,0.7, 0.4] [0.1,0.5,0.6,1.0, 0.54]
其他目标函数何选择函数等较为简单, 不再赘述.
MATLAB是设计遗传算法以及其他智能算法的非常好的工具, 下面给大家提供下遗传算法的完整程序:
主程序main.m
%% 遗传算法 优化函数
clc;close all;clear all;warning off;%清除变量
rand('seed', 100);
randn('seed', 100);
format long g;
my_N=10; % 设定优化问题维数
% 设定遗传算法参数
my_popsize=500;% 设定遗传算法种群数
my_maxgen=1000;% 设定遗传算法迭代次数
my_PM=0.1;% 设定变异概率
my_PC=0.8;% 设定交叉概率
lb=0*ones(1,my_N);
ub=1*ones(1,my_N);
%% 遗传算法主程序
my_tracemat=zeros(my_maxgen,2);% 设定性能跟踪
my_gen=0;
tic;
Chrom_my=mygenchrome(my_popsize,my_N,lb,ub);% 建立种群
Value_my=mydecodingfun(Chrom_my,my_popsize);% 解码染色体
[vmin_my,indexmin_my]=min(Value_my);
bestChrom_my=Chrom_my(indexmin_my,:);% 记录最优染色体
bestValue_my=vmin_my;% 记录的最优值
%% 遗传算法优化的主循环
while my_genvmin_my
bestValue_my=vmin_my;%记录的最优值
bestChrom_my=Chrom_my(indexmin_my,:);
end
my_tracemat(my_gen,2)=mean(Value_my);
my_tracemat(my_gen,1)=bestValue_my;% 保留最优
end
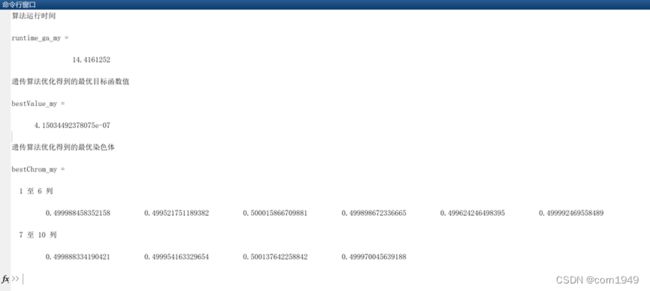
disp('算法运行时间');
runtime_ga_my=toc
% 显示结果
disp('遗传算法优化得到的最优目标函数值');
bestValue_my
disp('遗传算法优化得到的最优染色体');
bestChrom_my
figure;
plot(my_tracemat(:,1),'r-','linewidth',1);
hold on;
plot(my_tracemat(:,2),'b-','linewidth',1);
legend({'种群最优值','种群均值'},'fontname','宋体');
xlabel('迭代次数','fontname','宋体');
ylabel('目标函数值','fontname','宋体');
title('遗传算法迭代曲线','fontname','宋体');
交叉函数 mycrossga.m
function Chrom=mycrossga(Chrom,popsize,PC,N)
% 种群交叉,2点交叉
index100=randperm(popsize);
long1=fix(popsize/2);
set1=index100(1:long1);
set2=index100(long1+1:long1*2);
for i=1:long1
a=rand;
if a解码函数mydecodingfun.m
function Value = mydecodingfun(Chrom,popsize)
%解码染色体
Value=zeros(popsize,1);
for i=1:popsize
x=Chrom(i,:);
y=myfun(x);
Value(i,1)=y;
end
目标函数myfun.m
function y=myfun(x)
y=sum((x-0.5).^2);
初始染色体函数mygenchrome.m
function Chrom=mygenchrome(popsize,N,lb,ub)
% 建立种群
Chrom=zeros(popsize,N);
for i=1:popsize
for j=1:N
Chrom(i,j)=lb(j)+(ub(j)-lb(j))*rand(1,1);
end
end
染色体变异函数mymutationga.m
function Chrom=mymutationga(Chrom,popsize,PM,N,lb,ub)
% 种群变异,单点变异
for i=1:popsize
a=rand;
if a
分配适应度函数
function FitnV = myranking(ObjV, RFun, SUBPOP);
% Identify the vector size (Nind)
[Nind,ans] = size(ObjV);
if nargin < 2, RFun = []; end
if nargin > 1, if isnan(RFun), RFun = []; end, end
if prod(size(RFun)) == 2,
if RFun(2) == 1, NonLin = 1;
elseif RFun(2) == 0, NonLin = 0;
else error('Parameter for ranking method must be 0 or 1'); end
RFun = RFun(1);
if isnan(RFun), RFun = 2; end
elseif prod(size(RFun)) > 2,
if prod(size(RFun)) ~= Nind, error('ObjV and RFun disagree'); end
end
if nargin < 3, SUBPOP = 1; end
if nargin > 2,
if isempty(SUBPOP), SUBPOP = 1;
elseif isnan(SUBPOP), SUBPOP = 1;
elseif length(SUBPOP) ~= 1, error('SUBPOP must be a scalar'); end
end
if (Nind/SUBPOP) ~= fix(Nind/SUBPOP), error('ObjV and SUBPOP disagree'); end
Nind = Nind/SUBPOP; % Compute number of individuals per subpopulation
% Check ranking function and use default values if necessary
if isempty(RFun),
% linear ranking with selective pressure 2
RFun = 2*[0:Nind-1]'/(Nind-1);
elseif prod(size(RFun)) == 1
if NonLin == 1,
% non-linear ranking
if RFun(1) < 1, error('Selective pressure must be greater than 1');
elseif RFun(1) > Nind-2, error('Selective pressure too big'); end
Root1 = roots([RFun(1)-Nind [RFun(1)*ones(1,Nind-1)]]);
RFun = (abs(Root1(1)) * ones(Nind,1)) .^ [(0:Nind-1)'];
RFun = RFun / sum(RFun) * Nind;
else
% linear ranking with SP between 1 and 2
if (RFun(1) < 1 | RFun(1) > 2),
error('Selective pressure for linear ranking must be between 1 and 2');
end
RFun = 2-RFun + 2*(RFun-1)*[0:Nind-1]'/(Nind-1);
end
end;
FitnV = [];
% loop over all subpopulations
for irun = 1:SUBPOP,
% Copy objective values of actual subpopulation
ObjVSub = ObjV((irun-1)*Nind+1:irun*Nind);
% Sort does not handle NaN values as required. So, find those...
NaNix = isnan(ObjVSub);
Validix = find(~NaNix);
% ... and sort only numeric values (smaller is better).
[ans,ix] = sort(-ObjVSub(Validix));
% Now build indexing vector assuming NaN are worse than numbers,
% (including Inf!)...
ix = [find(NaNix) ; Validix(ix)];
% ... and obtain a sorted version of ObjV
Sorted = ObjVSub(ix);
% Assign fitness according to RFun.
i = 1;
FitnVSub = zeros(Nind,1);
for j = [find(Sorted(1:Nind-1) ~= Sorted(2:Nind)); Nind]',
FitnVSub(i:j) = sum(RFun(i:j)) * ones(j-i+1,1) / (j-i+1);
i =j+1;
end
% Finally, return unsorted vector.
[ans,uix] = sort(ix);
FitnVSub = FitnVSub(uix);
% Add FitnVSub to FitnV
FitnV = [FitnV; FitnVSub];
end
选择函数myselect.m
function SelCh = myselect(SEL_F, Chrom, FitnV, GGAP, SUBPOP);
% Check parameter consistency
if nargin < 3, error('Not enough input parameter'); end
% Identify the population size (Nind)
[NindCh,Nvar] = size(Chrom);
[NindF,VarF] = size(FitnV);
if NindCh ~= NindF, error('Chrom and FitnV disagree'); end
if VarF ~= 1, error('FitnV must be a column vector'); end
if nargin < 5, SUBPOP = 1; end
if nargin > 4,
if isempty(SUBPOP), SUBPOP = 1;
elseif isnan(SUBPOP), SUBPOP = 1;
elseif length(SUBPOP) ~= 1, error('SUBPOP must be a scalar'); end
end
if (NindCh/SUBPOP) ~= fix(NindCh/SUBPOP), error('Chrom and SUBPOP disagree'); end
Nind = NindCh/SUBPOP; % Compute number of individuals per subpopulation
if nargin < 4, GGAP = 1; end
if nargin > 3,
if isempty(GGAP), GGAP = 1;
elseif isnan(GGAP), GGAP = 1;
elseif length(GGAP) ~= 1, error('GGAP must be a scalar');
elseif (GGAP < 0), error('GGAP must be a scalar bigger than 0'); end
end
% Compute number of new individuals (to select)
NSel=max(floor(Nind*GGAP+.5),2);
% Select individuals from population
SelCh = [];
for irun = 1:SUBPOP,
FitnVSub = FitnV((irun-1)*Nind+1:irun*Nind);
ChrIx=feval(SEL_F, FitnVSub, NSel)+(irun-1)*Nind;
SelCh=[SelCh; Chrom(ChrIx,:)];
end
% End of function
选择函数用轮盘赌子函数rws.m
function NewChrIx = rws(FitnV,Nsel)
% 轮盘赌选择
[Nind,ans] = size(FitnV);
cumfit = cumsum(FitnV);
trials = cumfit(Nind) .* rand(Nsel, 1);
Mf = cumfit(:, ones(1, Nsel));
Mt = trials(:, ones(1, Nind))';
[NewChrIx, ans] = find(Mt < Mf & ...
[ zeros(1, Nsel); Mf(1:Nind-1, :) ] <= Mt);
程序结果如下: