Redis分布式系统:哨兵机制

“普通到不普通的人,哭着笑着的人~”
Redis在主从复制的机制下,一旦主节点出现了故障宕机,不能提供服务后。就需要人工进行主从切换,重新从各从节点中选取新的主节点。同时大量的应用方请求被通知切换到新的主节点上。
当然,上述的一系列操作都是谁要去维护处理的?程序员。只要是人工处理,就有可能出现人工的失误。加之如果处理过程繁琐,浪费的时间也会随之增加。显然,恢复处理过程中的时间开销过长,这对于Redis而言是不能接受的。
——前言
基本概念
由于Redis中出现了多种名词,所以我们在介绍哨兵Sentinel之前,对一些看过的名词作一定的解释。
|
名词
|
逻辑结构
|
物理结构
|
|
主节点
|
Redis 主服务
|
⼀个独⽴的 redis-server 进程
|
|
从节点
|
Redis 从服务
|
⼀个独⽴的 redis-server 进程
|
|
Redis 数据节点
|
主从节点
|
主节点和从节点的进程
|
|
哨兵节点
|
监控 Redis 数据节点的节点
|
⼀个独⽴的 redis-sentinel 进程
|
|
哨兵节点集合
|
若⼲哨兵节点的抽象组合
|
⼀个独⽴的 redis-sentinel 进程
|
|
Redis 哨兵(Sentinel)
|
哨兵节点集合 和 Redis 主从节点
|
哨兵节点集合 和 Redis 主从节点
|
|
应⽤⽅
|
泛指⼀个多多个客⼾端
|
一个或多个连接 Redis 的进程
|
Redis Sentinel是Redis当中实现高可用的方案,在实际的⽣产环境中,对提⾼整个系统的⾼可⽤是⾮常有帮助的。
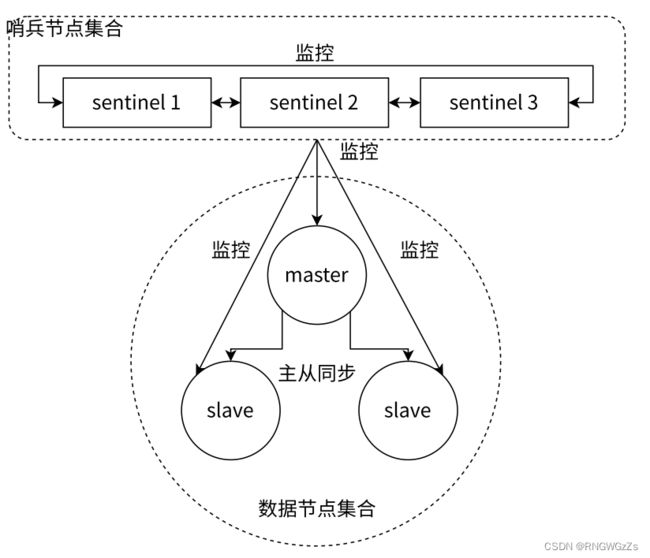
哨兵架构
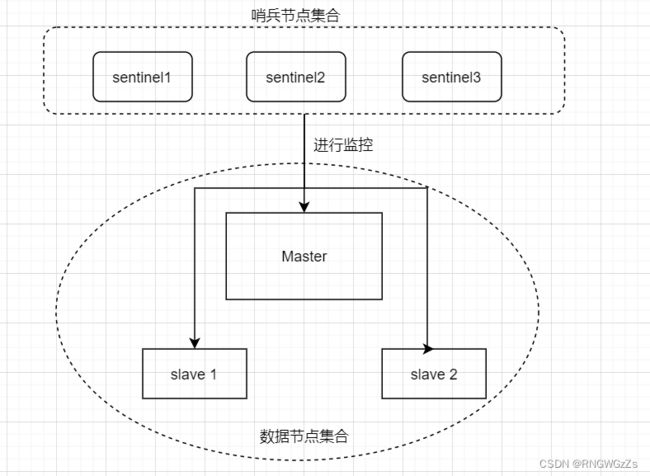
Redis Sentinel 相⽐于主从复制模式是多了若⼲Sentinel 节点,⽤于实现监控数据节点。哨兵节点会定期监控所有节点(包含数据节点和其他哨兵节点)。针对主节点故障的情况,故障转移流程⼤致如下:
1)主节点故障,从节点同步连接中断,主从复制停⽌。
搭建哨兵架构
为什么使用docker?
我们现在需要用到三个Redis数据节点和三个Sentinel哨兵节点,这六个节点需要放在不同的服务器上。可是,迫于无奈我们现目前只有一台机器,我们只能将这些环境部署在这一台资源少得可怜的服务器上。
当然,配置这些节点的过程也十分繁琐,各个节点所依赖的端口号\配置文件\数据文件多需要严格独立一份,这可以参考上篇的主从模式结构的配置。
采用虚拟机,也未尝不是一个解决方案,但是碍于一些云服务器的配置低,效果不是很好,还可能让你的服务器连接挂掉。
docker可以视为“轻量级”虚拟机,起到了同虚拟机相似的资源隔离的效果,并且对硬件要求并不高,我们可以借此搭建出多个相似的虚拟环境,来模拟将Redis部署在不同服务器上的场景。
安装部署
1) 安装docker-compose 和 docker
因为我们会在linux的机器里创建多个docker,当我们对docker中不同的redis服务器操作时, 为了避免一个一个地进行,我们可以借助docker-compose进行统一操作。
# centos
yum install docker-compose
# ubuntu
apt install docker-compose2)停止之前的redis
# 停止redis
service redis-server stop
# 停止 redis-sentine (如果有)
service redis-sentinel stop3) 使用docker获取redis镜像
docker pull redis:5.0.9
这里类似于git pull,使用git从中央代码仓库中拉取代码。docker pull则是默认从中央仓库(docker hub)上拉取镜像。
这里的镜像:上面会安装一个精简的Linux操作系统,以及redis。现在,我们只需要基于这个镜像,创建容器,并跑起来,那么我们的redis服务器就搭建好了。
使用命令:
# 系统下载好了的镜像
docker images
搭建环境
我们现在基于docker环境,完成对redis哨兵机制环境进行进搭建。因为此处涉及到多个redis server,多个redis 哨兵节点,那么每一个redis server每一个redis哨兵节点都需要一个单独的容器。所以,我们需要使用dockers-compose容器编排,更简便统一地进行搭建。
容器编排:
通过一个配置文件,把具体要创建的哪些容器,容器运行的具体参数等描述清楚。后续可以通过简单命令,批量对这些容器进行控制。
在docker-compose中,采用的是yml格式来进行配置。
注:文件格式固定“docker-compose.yml, docker-compose.yaml, compose.yml”
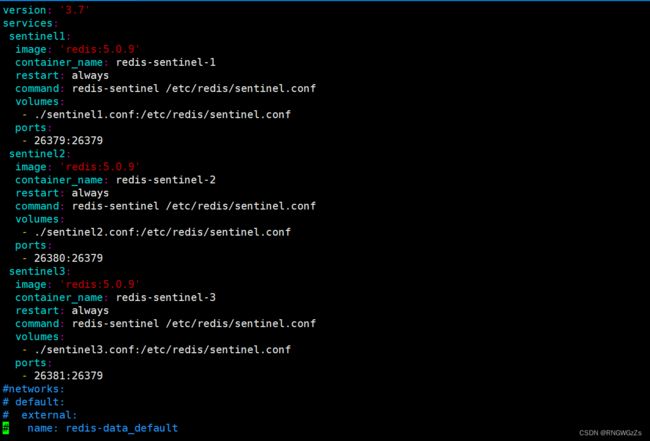
创建三个容器,作为redis的数据节点:
创建三个容器,作为redis的哨兵节点:


创建数据节点
# 创建容器并启动
docker-compose up -d
#停⽌并删除刚才创建好的容器.
docker-compose down
# 查看容器内日志
docker-compose logs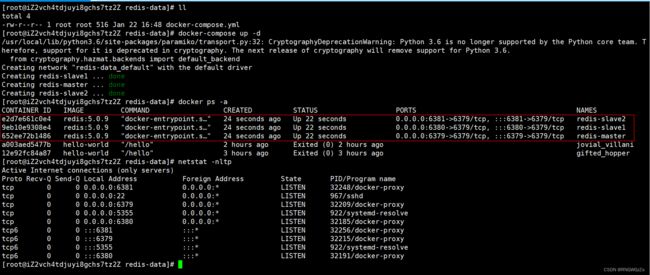
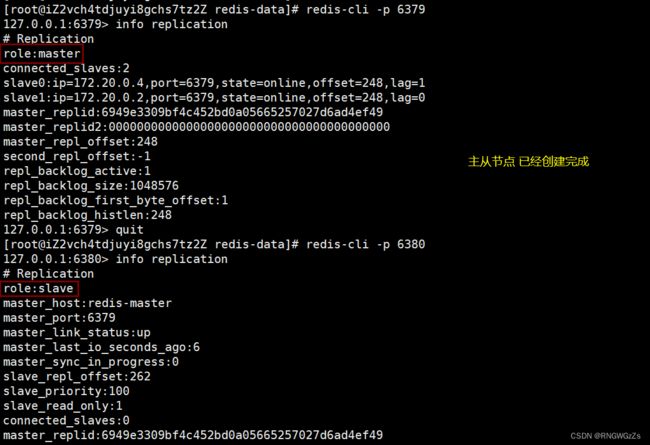
创建哨兵sentinel节点
我们需要为每一个哨兵节点,创建独立的配置文件:

我们再使用docker-compose up统一创建并启动容器。 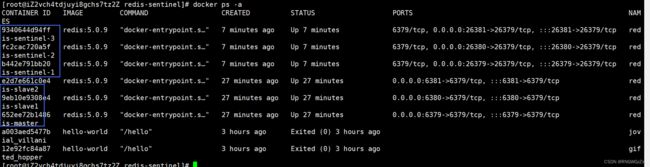
此时我们就可以看到哨兵节点、数据节点独立地运行在各自的容器之中。
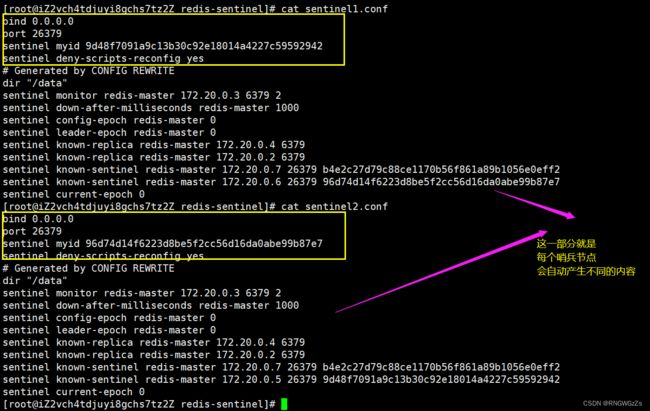
局域网互联
如果在sentinel的配置文件中,注释掉最后几行。我们再开始启动容器,可能会出现sentine哨兵节点无法解析找到 要监视的节点 Master。
这是因为,每创建一个新的容器,docker会为之新增一个新的局域网。
# 查看docker创建的局域网
docker network ls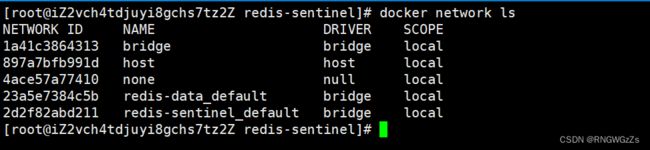
我们使用命令查看docker内的局域网,分别新创建了两个一份是数据节点,一份是哨兵节点。造成这个的原因,就是我们分两次创建容器。在默认情况下,这两个局域网是不互通的。所以,为了避免在创建哨兵节点时另外新创建一个局域网,我们给sentinel的配置文件中加上那份被注释的选项。

此时,六个节点都处在同一个局域网内,可以实现相互通信了。
Redis哨兵选举流程
(1) 从现象感知
现在,在我们的docker容器中,正启动着六个redis服务。我们现在动手将主节点干掉! 
docker stop redis-master
观察哨兵日志:
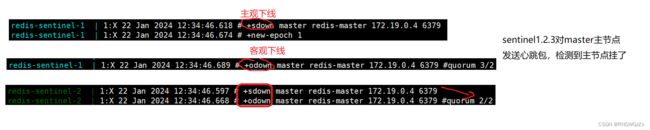
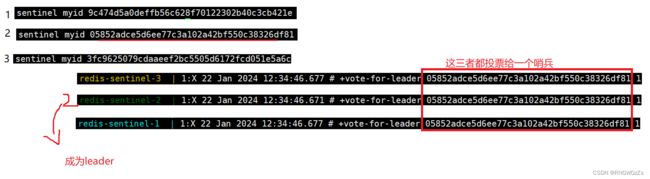
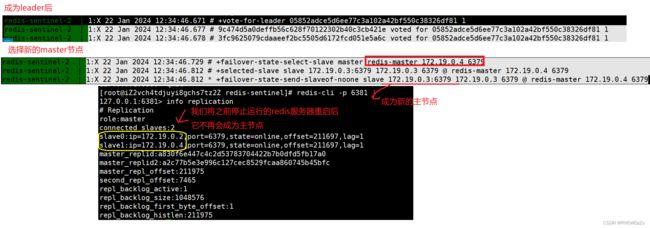

我们最终会得出以下结论:
(2) 选举原理
假定当前环境如上⽅介绍, 三个哨兵,⼀个主节点,两个从节点。
主观下线
当 redis-master 宕机, 此时 redis-master 和三个哨兵之间的⼼跳包就没有了。网络延迟低、响应快的哨兵节点则会将这个redis-master判顶为观下线。
客观下线
其他哨兵节点也发现了主节点故障后,发起投票。当投票数 > “法定票数”,
(sentinel monitor redis-master 172.22.0.4 6379 2 这个票数在我们是sentinel中设置的)
则会判断为客观下线,redis-master 故障这个事情被做实了。
选举出哨兵的 leader
接下来,首先发现宕机主节点的哨兵节点,会主动申请为leader,并向其他哨兵节点拉票,投票完成后,这个哨兵节点会成为leader。
leader负责挑选⼀个 slave 成为新的 master。当其他的 sentenal 发现新的 master 出现了, 就说明选举结束了。
最后,将新的Master节点,告知其他的哨兵节点,更新它们所监视的节点对象。
整个哨兵选举的过程就是这样,与我们印象中不同的是,需要先从哨兵间选取leader,才能继续由leader去挑选数据节点中哪一个从节点,成为新的主节点。所以,到底挑选哪一个从节点,就是需要一定的准则。
挑选规则:
① 优先级,优先级是配置⽂件中的配置项 “slave-priority” 或者 “replica-priority ”。
② replication offset 谁复制的数据多, ⾼的上位。
③ ⽐较 run id , 谁的 id ⼩, 谁上位。run id记录的是redis服务器启动时间就生成的id。
当某个 slave 节点被指定为 master 之后:
leader会指定该节点进行slave no one,成为新的master。其余剩下的slave节点,会重新slave of 到这个新的Master。
Redis哨兵机制的反思
哨兵机制,避免了人工处理可能会出现的失误,以及能够24小时不间断地对Redis数据节点进行监控。从而提高了系统的稳定性和可用性。
值得注意的是:
本篇到此结束,感谢你的阅读。
