C语言中算术运算的隐式类型转换规则
(转载)http://www.hookcn.org/2011/01/implicit-conversions-of-usual.html
在C语言的算术运算中,如果两个操作数都是算术类型但具体类型不同,编译器会把它们都转为同一个类型再执行运算。这属于隐式(implicit)类型转换的一种。本以为这是个很简单的事情,但在回答别人问题的时候发现,具体的规则如何判断(对某种类型组合会转换为哪个类型),并不是一两句话就能说清楚的。
注:此文针对 C 语言初学者,为简单起见,没有涉及 C99 添加的 _Bool 和 _Complex 类型,有关 位域(bit-field) 的描述也删掉了。有兴趣的同学,可以阅读 C99 标准( ISO/IEC 9899:1999)。
前文提到了 隐式类型转换,相对的概念是 显式(explicit)类型转换——在代码中使用类型转换(cast)操作符导致的类型转换。例如“int(2.1f)”就是一个显式类型转换,把 float 型的 2.1 转换为 int 型。本文只讨论算术运算中的隐式类型转换。
“算术类型”:任何 浮点类型或 整数类型。
“浮点类型”指 float / double / long double 中的任意一种,而 “整数类型”指 char / short / int / long / long long / bit-field / enum 的任意一种。整数类型可以是有符号的(signed)或无符号的(unsigned)。
下文中,“浮点类型”也可能简称为“浮点”,“整数类型”也可能简称为“整数”。注意“整数”不是指 int 类型,如果要指代后者,我会直接使用“int”以避免歧义。
在算术运算的两个操作数中,如果至少有一个是浮点类型,那么转换规则比较简单:比较两个操作数的类型级别,较低的操作数被转换成较高的那个类型。也就是说,任何一个操作数是 long double 则另一个被转换为 long double。如果都不是 long double,则如果有一个是 double 另一个被转换为 double。然后是 float,依此类推。特殊来说,如果是一个浮点数 F 和一个整数 I 参加运算,则整数转为浮点,也即 I 将被转换为与 F 相同的类型再参与运算。
问:你说“类型级别较低”,难道类型还有级别高低之分吗?
答:这只是为了方便表述而使用的概念,可以理解为不同类型之间的一种“次序”。具体的说是这样的:
- 类型级别的次序关系满足传递性,也就是
若 TypeA < TypeB 且 TypeB < TypeC, 则 TypeA < TypeC- 有符号(signed)和无符号(unsigned)修饰不影响类型次序。例如:
signed int = int = unsigned int
signed char = char = unsigned char- 两个不同(有无符号的差别不算)的整数类型级别必有高低而不会相同。精度越高的类型,其级别也越高。也就是
char < short < int < long int < long long int- 从上面的浮点转换规则,可以理解为任何浮点类型的级别都比整数类型高,也就是
所有整数类型 < float < double < long double(这样说只是为了比较好理解上述规则,但其实标准中并没有给出浮点类型的级别次序)- 至于枚举值(enum),标准并没有定死枚举的整数类型(编译器可以自己选择用 char / int / unsigned int),枚举的级别就是其对应整数类型的级别。
对初学者来说比较复杂的是两个操作数都不是浮点类型的情况,也就是均为整数类型。此时编译器先对两个操作数执行“整型提升(integer promotions)”,再根据不同情况进行后续类型转换,最后计算得出结果。后续类型转换的规则如下(匹配到某一条就不再考虑后面的规则了):
- 如果整型提升后两个操作数类型相同,则无需进一步转换。
- 如果两个都是操作数都是有符号或者都是无符号的,则将类型级别较低的操作数转换成级别较高的那个类型。
- 如果无符号的那个操作数其类型级别高于或等于有符号的操作数,则将有符号操作数转换到无符号操作数的类型。
- 如果有符号的那个操作数其类型能表达无符号操作数的类型,则将无符号操作数转换为有符号操作数的类型。
- 将两个操作数都转换为有符号操作数的类型所对应的无符号类型。(这句比较绕,看下面表格更清楚)
“整型提升”:对于那些属于整数类型但其类型级别低于 int 的值,将其转换为一个 int 型或 unsigned int 型。不符合条件的其他值不做转换。
“类型 T1 能表达类型 T2”:如果类型 T1 能表示所有类型 T2 的可能值(也就是任何 T2 类型的值都不会超出 T1 能表达的数值范围),我们就说 T1 能表达 T2。注意不能用精度高低来判断,要考虑是否有符号。例如 int 不能表达精度相同的 unsigned int,又比如 unsigned int 也不能表达精度更低的 short。
以上规则的表达比较冗长,我们可以借助下面的表格进行理解:
| 操作数op1类型 | 操作数op2类型 | 转换操作 |
| T (相同) | T (相同) | 无需转换 |
| signed t1 | signed t2 | 低级转换成高级 |
| unsigned t1 | unsigned t2 | 低级转换成高级 |
| signed t1 | unsigned t2 | |
| t1 <= t2 | op1 转换成 unsigned t2 | |
| t1 > t2 | ||
| signed t1 能表达 unsigned t2 | op2 转换成 signed t1 | |
| signed t1 不能表达 unsigned t2 | op1 和 op2 都转换成 unsigned t1 注意既不是 op1 的类型也不是 op2 的类型 |
可以看到,都是有符号或都是无符号的情况是很简单的,低级转换到高级而已。而一个有符号一个无符号就比较复杂了,幸好,现在几乎所有编译器都会对“signed 与 unsigned 之间的运算”提出警告,以免发生意外的类型转换导致得不到预期的结果。所以,千万不要无视编译器的警告,这是很不好的习惯。
----------------------------- PS -----------------------------
细心的同学估计已经注意到了,整型提升的定义里有一个“或”(int 或 unsigned int),然后就有问题了:那编译器到底怎么判断是该用 int 还是 unsigned int?
在 AnsiC 标准中提出的原则是,优先使用 int,并尽量保证提升后值的含义不变。也就是:
可以看到,这种策略和上面的转换表中最后两行的策略是一脉相承的。换句话说,一个操作数被整型提升时所使用的判定规则,类似于让一个 signed int 与其运算时所使用的类型转换规则。于是我们可以(不严谨的)把整型提升理解为“把操作数 op 替换为(0+op)”这么一个操作,这样就可以直接套用上面那张表了。希望这能减少初学者的头晕程度吧。
---------------------------- PS.2 ----------------------------
许多比较老的尤其是 AnsiC 标准出来之前的编译器实现,所使用的规则是不同的。前面所述的AnsiC规则称为保值规则(意为“优先保证值的含义”),而这些比较老式的编译器所使用的规则称为保无符号规则(意为“优先保证无符号运算”)。
在“保无符号规则”的指导下,整型提升的定义要改为:
上面的转换表最后两行也要改为:
举例说得更明白一些。假设 L(long) 能表达 UI(unsigned int),I(int) 能表达 US(unsigned short)。那么,如果使用保无符号规则是这样的:
UI + L -> (整型提升) UI + L -> UL
UI + I -> (整型提升) UI + I -> UI
UI + S -> (整型提升) UI + I -> UI
US + I -> (整型提升) UI + I -> UI
而按照AnsiC的保值规则是这样的:
UI + L -> (整型提升) UI + L -> L
UI + I -> (整型提升) UI + I -> UI
UI + S -> (整型提升) UI + I -> UI
US + I -> (整型提升) I + I -> I
以上不同之处已标红,注意有的不同发生在整数提升阶段,有的在后续转换阶段。
从上面可以看到,如果类型级别较低的那个操作数是无符号的而较高那个是有符号的,两种规则就可能导致不同结果。例如
int b = 3;
则(a-b)的求值结果,根据AnsiC的保值规则结果为(int)(-1),而根据保无符号规则结果却为0xFF...FF,其实是(unsigned int)(-1)。
所以,写代码时一定要小心注意有符号与无符号之间的运算,大部分编译器遇到这种情况也会给出警告。那么,再重复一次,无视编译器的警告是很不好的习惯。
例子:
#include <iostream> #include <bitset> #include <string> using namespace std; int main(int argc, char *argv[]) { signed char a = 0xe0; unsigned char b = a; if (a == b) { cout << "a == b" << endl; } return 0; }
反汇编看看是如何进行比较的:

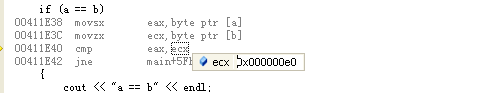
可以看到当对他们进行“==”比较的时候,提升为int类型了。也印证了这句话:
“整型提升”:对于那些属于整数类型但其类型级别低于 int 的值,将其转换为一个 int 型或 unsigned int 型。不符合条件的其他值不做转换。
例子2:
#include <iostream> #include <bitset> #include <string> using namespace std; int main(int argc, char *argv[]) { signed char a = 0xe0; unsigned int b = a; // 这里b的值为0xffff ffe0 if (a == b) { cout << "a == b" << endl; } return 0; }
(1)首先unsigned int b的值可以看成,signed char类型提升为int类型,然后int类型提升为unsigned int类型。
(2)比较的时候,a的提升为unsigned int类型了,然后也b进行比较故输出"a == b"。
例子3:
#include <iostream> #include <bitset> #include <string> using namespace std; int main(int argc, char *argv[]) { unsigned char a = 0xe0; int b = a; if (a == b) { cout << "a == b" << endl; } return 0; }


从这里我们也可以看到unsigned char进行类型提升的时候,符号位是不起作用的。
故这里输出的也是"a == b"。