AWS学习(二)——数据工程
文章目录
- 一、数据获取
-
- 1. Kinesis
-
- (1)Kinesis Video Stream
- (2)Kinesis Data Stream
- (3)Kinesis Data Firehose
- (4)Kinesis Data Analytics
- (5)Kinesis Agent
- 2. SQS
- 3. AWS IoT
- 4. MSK
- 5. Kinesis安全
- 二、数据存储
-
- 1. S3
- 2. DynamoDB
- 3. Redshift
- 4. AWS RDS和Aurora
- 5.数据库迁移
-
- (1)AWS Database Migration Service
- (2)Direct Connect
- (3)Snoeball
- 三、数据处理
-
- 1. Glue
- 2. AWS EMR
- 四、数据分析
-
- 1. Elasticsearch
- 2. Amazon Athena
- 3. 总结
- 五、数据可视化
-
- 1. QuickSight
- 五、其他服务
-
- 1. AWS batch
- 2. AWS Step
- 六、安全
-
- 1. KMS、HSM
- 2.STS
- 3. Federation
- 4. Cloudtrial
一、数据获取
1. Kinesis
AWS Kinesis是AWS提供的一种托管式流处理服务。它旨在帮助用户收集、分析和处理实时数据流,以便用于实时应用程序、实时分析和大数据处理。类似于GCP中的pub/sub+Dataflow。AWS Kinesis的的服务主要包括以下四种:Video Stream、Data Stream、Data Firehose、Data Analytics。
(1)Kinesis Video Stream
Kinesis Video Streams是AWS提供的一项服务,用于流式传输、存储和处理实时视频数据。它专门设计用于处理大规模的视频流,并提供了一系列功能来管理和处理实时视频数据。下面是Video Stream的工作流程。

(2)Kinesis Data Stream
Kinesis Data Streams是AWS提供的一项托管式流处理服务,用于收集、存储和处理实时数据流。它专注于高可扩展性和低延迟,适用于需要处理大量实时数据的应用程序和系统。
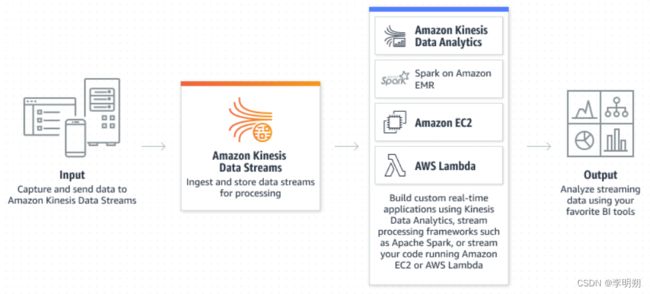
Kinesis Data Stream的一些关键概念:
- shard:shard是数据流中唯一标识的数据记录序列。 流由一个或多个shard组成,每个shard提供固定的容量单位。数据流的总容量是其shard容量的总和。
- Producer:发送数据到Kinesis。输入源包括
- Kinesis Agent
- Kinesis Producer Library:适用于高性能的场景,允许将数据以批量形式发送,并且可与多种开发工具和语言集成,如Java、Python、Go等
- Kinesis SDK:适用于低吞吐、较高延迟、API调用、AWS Lambda。吞吐超出异常的解决办法:过段时间重试、增加shard、修改partition key
- 第三方库
- Consumer:从Kinesis接收数据。输出可以是
- SDK:使用GetRecords从shard中获取数据
- Kinesis Client Library:提供自动检查点管理(利用DynamoDB)、分布式处理来接收和处理数据
- Firehouse
- AWS Lambda:Lambda可以处理来自KPL的数据并将其发送至S3、DynamoDB、Redshift等位置里
- 第三方库
- Kinesis Fan Out:蒋Shard发送给多个Consumer时,每个Consumer都会有2MB/s的吞吐量。
- retention period: Kinesis Data Stream中数据默认保存24小时,最多保存365天。
- 数据记录:存储在 Kinesis 数据流中的数据单元。 数据记录由序列号、分区键和data blob 组成,data blob 是不可变的字节序列。 Kinesis Data Streams 不会以任何方式检查、解释或更改 blob 中的数据。 数据 blob 最大可达 1 MB。
- Scaling:
- 增加shard:可以向高负载的shard进行增加操作来增加处理效率
- 合并shard:合并那些负载低的shard来节省成本
- 可以使用AWS Lambda实现auto-scaling
Kinesis Data Stream中数据默认保存24小时,最多保存7天。
(3)Kinesis Data Firehose
Kinesis Data Firehose是AWS提供的一项托管式流式数据传输服务(ETL),用于将实时数据加载到各种目标存储和分析服务。它旨在简化数据传输和导入的复杂性,提供一种简便的方式来处理实时数据流。
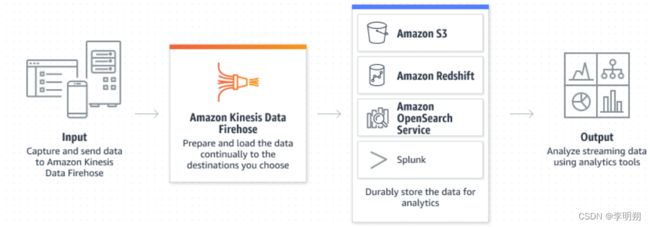
Kinesis Data Firehose的关键特点包括:
- 数据传输和导入:它可以接收来自各种数据源的实时数据流,包括Kinesis数据流、AWS IoT、日志文件等,并将数据以流式方式传输到目标存储或分析服务。
- 目标存储和分析:Kinesis Data Firehose支持将数据流式传输到多个AWS服务和第三方服务,包括Amazon S3、Amazon Redshift、Amazon Elasticsearch Service、Splunk、Datadog等。
- 数据转换和压缩:它提供数据转换和压缩功能,可以在传输过程中对数据进行转换、压缩和格式化,以便符合目标存储或分析服务的要求,通过Lambda进行数据转换。
- 数据缓冲和重试:Kinesis Data Firehose具有内置的数据缓冲和重试机制,可以处理暂时性的网络或目标服务故障,确保数据的可靠传输和持久性。可以设置缓存大小和缓存时间。
- auto-scaling
(4)Kinesis Data Analytics
Kinesis Data Analytics是AWS提供的一项托管式流数据分析服务,用于实时处理和分析流式数据。它提供了一种简单且可扩展的方式来处理实时数据流,并支持使用标准的SQL查询语言进行实时的转换、分析和聚合操作。

Kinesis Data Analytics主要有以下特点和功能:
- 实时数据处理:Kinesis Data Analytics可以处理实时流式数据,这意味着您可以立即对数据进行分析和处理,而不需要等待数据积累到批量处理的阶段。
- 简化的SQL查询:Kinesis Data Analytics支持使用标准的SQL查询语言对流式数据进行处理和分析。这使得数据分析师和开发人员可以使用熟悉的SQL语法来进行实时数据查询。
- 支持多个数据源:Kinesis Data Analytics可以从多种数据源中读取数据,包括Amazon Kinesis Data Streams、Amazon Kinesis Data Firehose、Apache Kafka等。这使得它适用于多样化的数据流输入。
- 弹性计算:Kinesis Data Analytics可以自动调整计算资源,根据数据处理的负载情况来调整所需的计算资源,从而实现弹性的数据处理。
- 无服务器架构:Kinesis Data Analytics支持无服务器架构,意味着您无需管理服务器,只需关注数据处理的逻辑和结果。
(5)Kinesis Agent
Kinesis Agent是AWS提供的一种本地数据收集工具,用于将日志数据和其他文件数据流式传输到AWS服务,例如Kinesis Data Streams、Kinesis Data Firehose和CloudWatch Logs。它简化了数据收集和传输的过程,可轻松地将本地文件数据发送到AWS云中进行进一步的处理和分析。
2. SQS
AWS SQS (Simple Queue Service) 是亚马逊网络服务(AWS)提供的一项完全托管的消息队列服务。它允许不同的组件和应用程序之间通过异步消息传递来实现解耦和可靠性。
AWS SQS 的主要特点和功能:
- 简单易用:AWS SQS 提供了简单的 API 接口,使开发者能够方便地发送、接收和删除消息。它具备可扩展性和高可靠性,并且不需要开发者管理底层的消息队列基础设施。
- 完全托管:AWS SQS 是一项完全托管的服务,AWS 管理了消息队列的底层基础设施和可用性。开发者无需担心硬件和软件的维护和管理,可以专注于应用程序的开发。
- 异步通信:AWS SQS 支持异步消息传递,使不同的组件和应用程序能够以解耦的方式进行通信。发送方将消息发送到队列中,而接收方则从队列中接收和处理消息。
- 可靠性和持久性:AWS SQS 提供了高度可靠和持久的消息传递。它存储消息在多个服务器和数据中心中,以确保消息的安全传递,即使出现故障也能够保证消息的可靠性。
- 消息的延迟处理:AWS SQS 允许开发者设置消息的延迟处理时间,以控制消息何时可供接收方处理。这对于实现延迟任务和定时任务非常有用。
- 队列的可扩展性:AWS SQS 具备高度可扩展性,可以处理大量的消息和高并发的读写请求。开发者可以根据需要创建多个队列,以满足不同应用程序的需求。
- FIFO队列
- 可以通过发送S3元数据来发送更大的消息
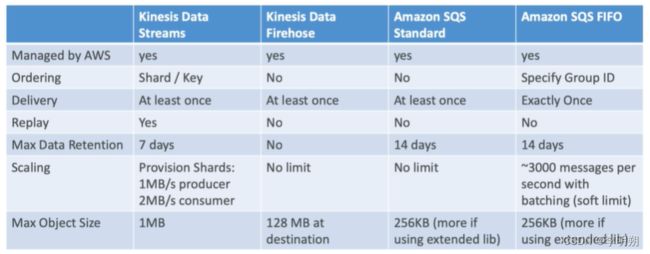
AWS SQS和Kinesis Data Streams在功能和使用场景上有一些区别:
- 消息传递模型:
- SQS:SQS使用标准队列和FIFO队列两种消息传递模型。标准队列提供高度可扩展的、至少一次的消息传递。FIFO队列提供有序的、仅一次的消息传递。
- Kinesis:Kinesis是一个流式数据服务,提供按顺序和持续传输的数据流。它主要用于实时数据流处理和实时数据分析。
- 数据持久性:
- SQS:SQS保证消息的持久性,一旦消息被发送到队列,它会持久保存,即使接收方不在线或消息没有被立即处理。
- Kinesis:Kinesis提供数据的有限持久性,数据在流中存储的时间是有限的。默认情况下,Kinesis保留数据最长为24小时。
- 实时性:
- SQS:SQS可以用于异步通信,消息在队列中等待被接收和处理,没有实时性保证。
- Kinesis:Kinesis专注于实时数据处理,可以提供毫秒级的延迟。
- 消息处理方式:
- SQS:SQS适用于多个独立的消息消费者,并且每个消息只能被一个消费者接收和处理。
- Kinesis:Kinesis适用于多个消费者并发处理同一数据流,每个消费者都可以独立地读取和处理数据。
- 使用场景:
- SQS:SQS适用于解耦和异步通信,例如任务队列、应用程序解耦、消息驱动的体系结构等。
- Kinesis:Kinesis适用于实时数据流处理和实时数据分析,例如实时数据采集、实时仪表板、实时指标计算、流式ETL等。

3. AWS IoT
AWS IoT(Internet of Things)是AWS提供的一套全面的云端解决方案,用于构建、部署和管理物联网(IoT)应用程序。AWS IoT提供了一系列服务和功能,用于连接、管理和分析大规模的物联网设备和数据。
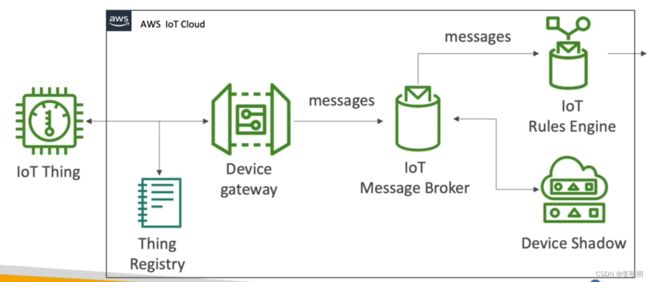
- Device Gateway:Device Gateway提供了一个安全的通信通道,使设备能够连接到AWS IoT Core,并与其他AWS服务进行交互。
- Message Broker: Message Broker 提供了可靠、安全和可扩展的消息传递机制,以确保设备之间的通信和数据交换。
- Rule Engine:是一种基于规则的服务,能够根据预定义的规则对接收到的消息进行过滤、转换和路由,以实现消息的实时处理和分发。
- Rule Actions:AWS IoT Rule Engine支持多种操作(actions)来处理接收到的物联网设备消息。这些操作定义了在规则匹配成功后要执行的动作,可以将消息传递给其他AWS服务
- Device Shadows:提供了一种虚拟表示设备状态的机制,允许应用程序与设备进行交互,无论设备是否在线。设备影子充当了设备状态的中间层,使应用程序能够读取和更新设备的状态,而不需要直接与设备进行通信。
- AWS IoT Greengrass:用于在边缘设备上运行物联网应用程序和进行本地数据处理的服务。它提供本地计算、消息路由、安全管理和设备通信等功能,实现边缘计算和边缘设备的智能化,可以在设备上运行Lambda函数。
4. MSK
AWS MSK(Managed Streaming for Kafka)是亚马逊网络服务(AWS)提供的一项托管式Apache Kafka服务,用于构建和运行可扩展、可靠的实时数据流应用程序。
AWS MSK 提供以下主要功能和特点:
- 托管式Kafka集群:AWS MSK 提供了一个托管的、高度可靠的Apache Kafka集群,用户无需管理基础设施的细节,可以专注于应用程序开发和数据流处理。
- 可靠性和可扩展性:AWS MSK 提供了高度可靠的消息传递机制,并能够自动扩展以适应数据流的需求。它支持水平扩展,可以根据负载情况自动调整集群的大小。
- 数据持久性和容错性:AWS MSK 使用Apache Kafka的持久性和容错机制,确保消息的持久存储和高可靠性传递。消息会被可靠地写入持久存储,并能够进行跨多个副本的复制。
- 安全性和身份验证:AWS MSK 提供了安全的数据传输和身份验证机制,可以使用TLS(传输层安全)加密保护数据的传输,同时支持使用IAM角色、TLS证书和SASL/SCRAM进行身份验证。
- 监控和运维:AWS MSK 提供了集成的监控和运维工具,使用户可以实时监测集群的性能和健康状态,以及进行故障排除和性能优化。
- 与AWS生态系统的集成:AWS MSK 可与其他AWS服务进行集成,如Amazon S3、Amazon Redshift、Amazon EMR等,以构建更强大的实时数据流应用程序。
AWS MSK(Managed Streaming for Kafka)和 AWS Kinesis 的区别:
- 基础架构:AWS MSK 是一个托管的 Apache Kafka 服务,它提供了一个可伸缩和可靠的 Kafka 集群,可以直接使用 Kafka 的功能和生态系统。AWS Kinesis 是 AWS 的流数据处理服务,包括 Kinesis Data Streams、Kinesis Data Firehose 和 Kinesis Data Analytics。
- 数据处理模型:AWS MSK 使用 Apache Kafka 的发布-订阅模型,支持多个消费者组以及高吞吐量和低延迟的数据处理。AWS Kinesis 使用分区和消费者模型,其中数据流被分成不同的分区,并允许多个消费者对不同的分区进行并行处理。
- 生态系统集成:AWS MSK 可以与 Apache Kafka 生态系统无缝集成,可以使用 Kafka Connect 连接到各种数据源和目标,使用 Kafka Streams 进行流处理和转换。AWS Kinesis 与 AWS 的其他服务(如 Lambda、S3、Redshift 等)集成更紧密,可以方便地与这些服务进行数据交互和处理。
AWS MSK 的适用场景:
- 需要与现有的 Kafka 生态系统集成的应用程序。
- 需要具有高吞吐量、低延迟和可靠性的实时数据处理和流式分析。
- 需要支持多个消费者组以及发布-订阅模型的应用程序。
AWS Kinesis 的适用场景:
- 需要处理大量实时数据流的应用程序,如日志收集、事件处理、实时监控等。
- 需要构建实时流数据处理和分析应用程序。
- 需要与其他 AWS 服务紧密集成进行数据处理和存储。
5. Kinesis安全
二、数据存储
1. S3
S3存储类型:
- S3 standard:默认存储类型,费用最昂贵
- S3 intelligence tiering:通过自动将数据移动到两种accrss tiers(不经常访问和经常访问)来优化费用
- S3 One Zone-IA:对于较低频率访问的数据(小于每月一次)且仅存储在一个区域里
- S3 Glacier:对于更低频率访问的数据(小于每三个月一次)
- S3 Glacier Deep Archive:对于最低频率访问的数据(小于半年一次),最便宜
- S3 Standard-IA:长时间存在、不经常访问,当需要时可快速访问,用于备份、灾难恢复
AWS S3中的加密选项:
- 服务器端加密(Server-Side Encryption):
- SSE-S3:由AWS S3托管的密钥进行加密。对象在存储过程中自动进行加密和解密。
- SSE-KMS:使用AWS Key Management Service(KMS)托管的密钥进行加密。KMS提供了更高级别的密钥管理和审计功能。
- SSE-C:使用用户提供的加密密钥对对象进行加密。用户负责管理密钥和加密操作,必须使用HTTP。
- 客户端加密(Client-Side Encryption):客户端加密是在上传数据之前,由客户端应用程序负责对数据进行加密。然后,客户端将加密的数据上传到S3存储桶。
- 控制访问权限:
- S3桶策略和ACL(访问控制列表):通过配置S3桶策略和ACL,可以限制对存储在S3中的对象的访问权限。
- IAM策略:通过AWS Identity and Access Management(IAM)策略,可以控制用户和角色对S3存储桶和对象的访问权限。
Bucket Version:对象版本控制功能,允许在存储桶中保留和管理对象的多个版本。当版本控制启用后,每次对同一键(Key)的对象进行更新或删除操作时,都会创建一个新的版本,并将之前的版本保留在存储桶中,需要注意的是,版本控制会增加存储成本。S3版本控制的主要特点和使用方式如下:
- 数据保护:通过启用版本控制,每个对象的更新和删除操作都会创建一个新版本,并保留之前的版本。这样可以保护数据免受意外删除或覆盖的影响,以及恶意或误操作造成的数据丢失。
- 版本管理:版本控制使得可以跟踪和管理每个对象的不同版本。可以使用AWS S3 API、AWS管理控制台或命令行界面(CLI)查看、恢复或删除特定版本的对象。
- 恢复和回滚:通过版本控制,可以轻松地恢复到先前的对象版本。如果意外地修改或删除了对象,可以选择恢复到先前的版本,以避免数据丢失。
- 审计和合规性:版本控制功能可用于数据审计和合规性要求的满足。可以跟踪和记录每个版本的操作历史,包括创建、更新和删除操作的时间戳和执行者信息。
Lifetime:在S3中,对象的生命周期可以通过配置进行管理。对象的生命周期指定了对象在存储桶中的不同阶段的行为,包括存储、转换存储类别、过期和删除等。通过配置生命周期规则,可以根据业务需求自动管理对象的存储类别和生命周期。这有助于优化存储成本,并确保不再需要的对象被及时删除。我们可以定义对象的以下两个关键方面:
- 存储类别转换:可以根据对象的年龄或指定的时间间隔将对象从一种存储类别转换为另一种存储类别。例如,可以将频繁访问的对象从标准存储转换为低频访问存储,以降低存储成本。
- 对象过期和删除:可以设置对象的过期时间,在到达指定的时间后自动将对象删除。过期时间可以基于对象的创建日期、最后修改日期或自定义的元数据来定义。
Cross-Region Replication:跨区域复制是一项功能,允许将一个存储桶中的对象通过异步复制的方法复制到另一个AWS区域的存储桶中。这提供了数据冗余和灾难恢复的能力,以确保数据在多个区域之间的复制和可用性。同时支持跨账户复制、版本控制复制。
ETag(Entity Tag):是一个用于标识对象的特殊标识符。它通常是一个由双引号括起来的字符串,可以用于验证对象在传输或存储过程中是否完整和一致。
S3 CORS(Cross-Origin Resource Sharing):S3 CORS,可以控制允许从其他域访问S3存储桶中的对象的规则。
S3监控
2. DynamoDB
DynamoDB是亚马逊网络服务(AWS)提供的一种全托管、高可扩展的NoSQL数据库服务。它旨在提供低延迟和高吞吐量的性能,以满足各种规模和负载的应用程序需求。
以下是DynamoDB的主要特点和功能:
-
自动扩展,支持数据在多个AWS区域之间的自动复制和同步。数据会在多个可用区中进行复制,以实现高可用性和灾难恢复。
-
DynamoDB是一种键值存储数据库,每个项目都由主键唯一标识。除了主键之外,DynamoDB还支持范围键和全局二级索引,以提供更灵活的数据访问模式。
- Local Secondary Index (LSI)(局部二级索引):LSI是在DynamoDB表中创建的索引,它具有与主键相同的分区键(Partition Key),但具有不同的排序键(Sort Key)。LSI只能在与原始表位于相同分区的范围内执行查询,因此它被称为局部索引。每个表最多可以创建5个LSI。
- Global Secondary Index (GSI)(全局二级索引):GSI是在DynamoDB表中创建的索引,它具有独立于原始表的分区键和排序键。GSI可以跨越不同的分区,并提供与主键不同的查询方式,使得在多个属性上进行快速查询成为可能。每个表最多可以创建20个GSI。
-
常用操作:读、写、更新、删除item,批量写入、读取item,查询数据、扫描全表。
-
Primary Key:用于唯一标识表中的每个项目(item)的关键属性,用于索引和检索数据。DynamoDB的主键可以分为两种类型:
- 单一主键(Single-Attribute Primary Key):单一主键由一个属性(attribute)组成,称为分区键(Partition Key)或哈希键(Hash Key)。分区键用于将数据分配到DynamoDB的不同分区(partition),以支持高吞吐量和扩展性。例如,可以使用用户ID作为分区键,使得具有相同分区键的项目被存储在相同的分区中,从而实现数据的分布式存储和访问。
- 复合主键(Composite Primary Key):复合主键由两个属性组成,分别是分区键(Partition Key)和排序键(Sort Key)。分区键的作用与单一主键相同,用于数据分区。排序键用于对同一分区中的项目进行排序和检索。例如,可以使用用户ID作为分区键,使用时间戳作为排序键,使得具有相同分区键的项目按照时间顺序进行排序和检索。
-
Consistent Read:一致性读取是指读取操作返回最新写入数据的能力。
- 最终一致性读取(Eventually Consistent Read),这意味着读取操作可能会返回稍旧的数据,因为在读取之间可能存在数据复制和传播的延迟。
- 请求一致性读取(Strong Consistent Read)。通过使用一致性读取,读取操作可以确保返回最新的写入数据,而不考虑数据复制和传播的延迟,使用时将ConsistentRead参数设置为true。
-
RCU(Read Capacity Units)和 WCU(Write Capacity Units):用于衡量读取和写入操作的计量单位,可以根据应用程序的需求和负载模式来调整RCU和WCU的配置。
-
分区(Partitions)是用于存储和分布数据的逻辑单元。每个DynamoDB表都由一个或多个分区组成,分区用于将数据分布在不同的物理存储节点上,以实现高吞吐量和可扩展性。通过合理设计分区键和合理规划表的吞吐量,可以实现在DynamoDB中高度可扩展和高吞吐量的数据存储和访问。
-
DynamoDB Accelerator (DAX) : DynamoDB 的全管理缓存服务。它可以显著提高 DynamoDB 数据库的读取性能,通过减少与 DynamoDB 的网络通信以及读取数据的负载。
-
DynamoDB Streams: DynamoDB提供的一个实时流服务,用于捕获和跟踪对DynamoDB表的数据修改事件。它允许应用程序实时处理和响应这些数据变更事件,可以使用Lambda函数获取Streams。
-
TTL(Time to Live):是一项功能,允许为表中的项目设置过期时间。一旦项目到达其过期时间,DynamoDB会自动将其标记为过期并删除。
DynamoDB的anti pattern:
- 避免使用Scan操作来执行全表扫描。尽量使用Query操作来检索特定的项目。
- 过度使用单一分区键可能导致数据热点,不利于负载均衡。考虑使用复合主键和局部二级索引(Local Secondary Indexes)来支持更多的查询方式。
- 确保为经常访问的属性创建适当的全局二级索引(Global Secondary Indexes),以便能够高效地查询这些属性。
- 适度使用批量操作(BatchWriteItem和BatchGetItem),并考虑使用并行查询和分段(Segment)扫描等方法来优化性能。
- 过低的吞吐量可能导致性能瓶颈,而过高的吞吐量可能带来不必要的成本。
- DynamoDB对于频繁的属性更新(特别是大型项目的更新),可能会导致高开销和潜在的性能问题。在这种情况下,考虑将属性划分为较小的单元(如映射或列表),以便更精确地更新所需的部分。
3. Redshift
AWS Redshift是一种完全托管的数据仓库解决方案,适用于需要高性能、可扩展和可靠的大规模数据分析工作负载。它使用列式存储和并行处理的架构,能够高效地处理大量结构化数据。
以下是一些关键特点和功能:
- 数据压缩:Redshift使用列式存储和压缩算法来最大程度地减少存储空间,从而降低存储成本,并提高数据查询的性能。
- 列式存储:Redshift使用列式存储来组织和存储数据。列式存储可以提供更高的压缩率和查询性能。由于查询通常只涉及到少量的列,列式存储可以仅读取所需的列数据,减少了磁盘I/O和网络传输的数据量。
- 并行处理:Redshift使用并行查询执行引擎,将查询任务分配给集群中的多个计算节点并同时执行。这种并行处理能力可以显著加速查询执行时间,特别是在处理大量数据和复杂查询时。
- 缓存和数据预取:Redshift在查询过程中使用高速缓存来存储中间结果和常用数据,以避免重复的计算和访问磁盘。此外,Redshift还通过数据预取技术提前从磁盘读取和加载数据,以减少查询延迟。
- 数据一致性:Redshift支持ACID(原子性、一致性、隔离性和持久性)事务,保证数据的一致性和可靠性。适用于OLAP(Online Analytical Processing),而不是OLTP(Online Transaction Processing)。
- 数据分布和切片(Data Distribution and Slicing):Redshift根据您定义的分布键将数据切片并分布到计算节点中。分布键决定了数据在集群中的分布方式,应根据查询模式和数据访问模式进行优化。每个计算节点只负责处理分配给它的数据分片,这样可以实现并行查询和数据操作。
- Sort Key(排序键):是一种用于定义表中数据排序方式的特性。通过指定Sort Key,可以提高查询性能和数据压缩比例,并减少磁盘I/O的需求。可以选择一个或多个列作为Sort Key。
- 数据流和命令:COPY用来加载数据到Redshift,UNLOAD用来导出数据,使用SQL来查询和管理数据。
Redshift的架构
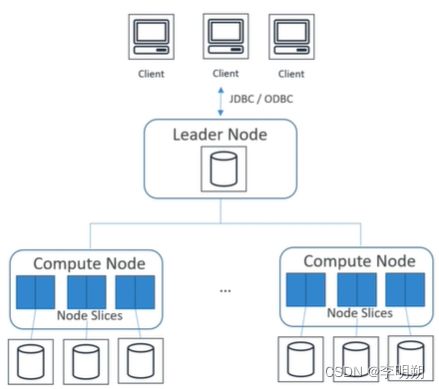
Redshift的基本组织单位是集群,由一个或多个节点(Nodes)组成。节点分为两种类型:Leader Node(主节点)和Compute Nodes(计算节点)。
- 主节点负责接收和处理客户端的请求,规划查询计划,并协调计算节点之间的任务分配。
- 计算节点是存储和处理数据的节点,它们具有列式存储引擎和并行处理功能,可以并行执行查询操作。可以分为深度计算节点和深度存储节点。
Redshift的工作负载管理(Workload Management):通过工作负载管理,可以管理并发查询,设置优先级和资源限制,以确保关键业务查询的性能,并避免对系统的过度负载。以下是Amazon Redshift中工作负载管理的一些关键概念和功能:
- 队列(Queue):队列是工作负载管理的基本单位,用于将查询分组和隔离。每个队列都有自己的优先级、资源配额和查询调度规则。可以为不同的用户、应用程序或查询类型创建多个队列,以根据业务需求对查询进行分类和管理。
- 查询队列(Query Queue):查询队列是一个特殊类型的队列,用于管理查询的执行。可以为查询队列设置最大并发查询数和最大资源配额,以控制同时执行的查询数量和资源使用量。查询队列还可以设置超时时间和查询优先级,以确保关键查询获得足够的资源和响应时间。
- 查询调度(Query Scheduling):查询调度是指根据工作负载管理的规则和策略,将查询分配给可用资源并进行优先级调度的过程。Redshift使用基于队列和查询优先级的调度算法,确保高优先级的查询优先获得资源和执行时间。
- 优先级(Priority):优先级用于指定查询的重要程度。较高优先级的查询将在资源分配和执行顺序上得到更高的优先级。您可以为不同的队列和查询设置不同的优先级,以确保关键业务查询得到及时响应和适当的资源。
4. AWS RDS和Aurora
AWS RDS(Amazon Relational Database Service)是亚马逊云服务(AWS)中的一项托管数据库服务,用于轻松部署、管理和扩展关系型数据库。AWS RDS支持多种数据库引擎,包括MySQL、PostgreSQL、Oracle、Microsoft SQL Server和Amazon Aurora。支持ACID事务。
主要特点和用途:
- 托管服务:AWS RDS是一种完全托管的服务,AWS负责管理底层基础设施、数据库软件安装和升级,使用户可以专注于数据库应用程序的开发和管理。
- 多种数据库引擎:AWS RDS支持多种关系型数据库引擎,您可以选择最适合您的应用程序的数据库引擎。
- 自动备份和恢复:AWS RDS自动进行数据库备份,并支持数据库的灾难恢复和点-in-time恢复。
- 可扩展性:AWS RDS可以根据负载自动扩展数据库实例的计算和存储资源,以满足不同规模的业务需求。
- 安全性:AWS RDS提供数据加密、访问控制和VPC(Virtual Private Cloud)集成,确保数据库的数据安全和隐私性。
- 监控和性能优化:AWS RDS提供各种监控和性能优化工具,帮助您监控数据库性能并进行调优。
Amazon Aurora是亚马逊云服务(AWS)中的一种托管关系型数据库服务,是一种高性能、高可用性的数据库引擎。它兼容MySQL和PostgreSQL,并提供了许多增强功能,使其成为一种强大的关系型数据库解决方案。
主要特点和用途:
- 高性能:Amazon Aurora采用高度优化的存储和复制机制,实现了高性能的读写操作,并支持并行查询,从而提供快速的数据库访问速度。
- 可扩展性:Amazon Aurora可以根据负载自动扩展数据库实例的计算和存储资源,以满足不同规模的业务需求。它支持读写分离,可以将读操作分发到多个实例,提高数据库的可扩展性和性能。
- 高可用性:Amazon Aurora使用多个可用区的部署,实现数据库的高可用性和容错性。它具有自动备份和故障转移功能,保障数据的持久性和灾难恢复。
- 数据库兼容性:Amazon Aurora兼容MySQL和PostgreSQL,因此您可以无缝地将现有的MySQL或PostgreSQL应用程序迁移到Aurora上,而无需进行任何修改。
- 安全性:Amazon Aurora提供数据加密、访问控制和VPC(Virtual Private Cloud)集成,确保数据库的数据安全和隐私性。
- 监控和性能优化:Amazon Aurora提供各种监控和性能优化工具,帮助您监控数据库性能并进行调优。
Aurora和RDS的一些区别:
-
支持的数据库引擎:
- Amazon Aurora是一种特定于AWS的关系型数据库引擎,兼容MySQL和PostgreSQL。它是AWS自主开发的高性能、高可用性的数据库引擎,基于MySQL和PostgreSQL的开源代码,但具有许多增强功能。
- AWS RDS支持多种数据库引擎,包括MySQL、PostgreSQL、Oracle、Microsoft SQL Server和Amazon Aurora。AWS RDS为这些数据库引擎提供完全托管的服务。
-
性能和可用性:
- Amazon Aurora具有高性能、高可用性和可扩展性。它采用了高度优化的存储和复制机制,支持并行查询,提供快速的读写操作,并具有自动故障恢复功能。
- AWS RDS根据所选的数据库引擎不同,性能和可用性可能有所不同。例如,AWS RDS for MySQL和PostgreSQL提供一定程度的性能和可用性,但相对于Amazon Aurora,可能在某些方面稍逊一筹。
-
数据库兼容性:
- Amazon Aurora兼容MySQL和PostgreSQL,因此您可以无缝地将现有的MySQL或PostgreSQL应用程序迁移到Aurora上。
- AWS RDS支持多种数据库引擎,您可以选择适合您应用程序需求的数据库引擎。
-
成本:Amazon Aurora通常相对于AWS RDS的其他数据库引擎而言,具有更高的价格。它提供了更强大的性能和功能,但在一些特定的应用场景下,AWS RDS的其他数据库引擎可能更为经济实惠。
5.数据库迁移
(1)AWS Database Migration Service
AWS Database Migration Service(DMS)是亚马逊网络服务(AWS)提供的一项数据库迁移服务,旨在帮助用户轻松、快速地将现有数据库迁移到AWS云中的各种数据库解决方案。
AWS Database Migration Service 提供了以下主要功能和特点:
- 数据库迁移:AWS DMS 支持不同数据库之间的迁移,包括关系型数据库(如Oracle、MySQL、SQL Server、PostgreSQL等)和非关系型数据库(如MongoDB、DynamoDB等)。它可以实现同种数据库的版本升级迁移,或者将不同类型的数据库迁移到AWS云中。
- 迁移类型:AWS DMS 支持多种迁移类型,包括全量迁移、增量迁移和零停机迁移。全量迁移将现有数据库的所有数据迁移到目标数据库中;增量迁移实时将变更应用到目标数据库;零停机迁移保证在迁移过程中业务不中断。
- 实时数据复制:AWS DMS 可以在源数据库和目标数据库之间建立实时的数据复制流,确保源数据库的变更实时同步到目标数据库中。
- 数据迁移验证:AWS DMS 提供了数据迁移的验证和校验功能,可以验证源数据库和目标数据库之间的数据一致性和准确性。
- 数据迁移任务管理:AWS DMS 具备任务管理功能,可以创建、配置、监控和管理数据迁移任务。用户可以通过AWS管理控制台或命令行界面进行任务管理操作。
- 可靠性和安全性:AWS DMS 提供可靠的数据迁移服务,通过使用CDC(Change Data Capture)技术捕获变更并应用到目标数据库,确保数据的一致性和完整性。同时,它支持加密数据传输,并提供数据库迁移过程中的安全性控制。
- 需要创建EC2实例来运行复制任务
AWS Schema Conversion Tool:SCT是亚马逊网络服务(AWS)提供的一款用于帮助用户在迁移到AWS云数据库时进行数据库模式转换的工具。它可以自动分析和转换关系型数据库(如Oracle、SQL Server、MySQL等)的模式和存储过程,以适应AWS云中的目标数据库。
(2)Direct Connect
AWS Direct Connect是亚马逊网络服务(AWS)提供的一项网络服务,它允许用户通过专用网络连接(Direct Connect连接)将本地数据中心或私有网络与AWS云进行直接连接。
AWS Direct Connect 提供以下主要功能和特点:
- 专用连接:AWS Direct Connect 提供专用的、物理隔离的连接,通过专线将本地数据中心或私有网络与AWS云中的特定区域进行连接。这种专用连接提供了更高的可靠性、更低的延迟和更高的带宽,相比于通过公共互联网进行连接。
- 快速和可扩展:AWS Direct Connect 提供多种连接速度选项,从1 Gbps到100 Gbps不等。用户可以根据需求选择适当的连接速度,并根据业务需求进行灵活扩展。
- 私密性和安全性:AWS Direct Connect 连接是私密的,不经过公共互联网传输数据。这提供了额外的安全性,可防止数据在传输过程中被拦截或篡改。
- 混合云扩展:通过 AWS Direct Connect,用户可以轻松地扩展现有的本地数据中心或私有网络到AWS云中,构建混合云解决方案。这使得用户可以在本地和云端之间实现灵活的数据和应用程序交互。
- 高可靠性和容错性:AWS Direct Connect 连接具有高可靠性和容错性,通过冗余连接、多个物理路径和备份设备,确保连接的稳定性和可用性。
- 管理和监控:AWS Direct Connect 提供了管理和监控工具,用户可以轻松管理连接、监测带宽使用和监控连接状态。
(3)Snoeball
AWS Snowball是亚马逊网络服务(AWS)提供的一项数据迁移和传输服务,旨在帮助用户将大规模数据安全地从本地环境迁移到AWS云中,或从AWS云中迁移到本地环境。
AWS Snowball的主要特点和功能如下:
- 大规模数据传输:AWS Snowball支持大规模数据的传输。它提供了一种快速、安全的方式来迁移大量的数据,无论是从本地环境迁移到AWS云,还是从AWS云迁移到本地环境。
- Snowball设备:AWS Snowball使用一种称为Snowball的物理设备来进行数据传输。Snowball是一种便携式存储设备,具有高容量和高速传输能力。用户可以将数据存储在Snowball设备中,并将设备快速、安全地传输到目标地点。
- 数据安全和加密:AWS Snowball提供数据的安全传输和存储。数据在传输过程中使用TLS(Transport Layer Security)进行加密,并在Snowball设备上存储时进行加密保护。
- 快速传输:AWS Snowball利用高速网络连接,以及Snowball设备的高速传输能力,实现了快速数据传输。这比通过公共互联网传输大量数据更快捷和高效。
- 简化操作:AWS Snowball提供了简化的操作界面和工具,以帮助用户管理数据传输任务。用户可以轻松配置设备、监控传输进度并跟踪数据传输状态。
- 数据导入和导出:AWS Snowball不仅支持将数据从本地环境迁移到AWS云中,还支持将数据从AWS云迁移到本地环境。这使得用户可以在不同环境之间进行灵活的数据导入和导出。
三、数据处理
1. Glue
AWS Glue是AWS提供的一项完全托管的ETL(Extract, Transform, Load)服务。它旨在帮助用户轻松地准备和转换来自于多个数据源的大型数据集,以供数据分析、数据仓库和机器学习等用途使用。AWS glue的整体架构如下图
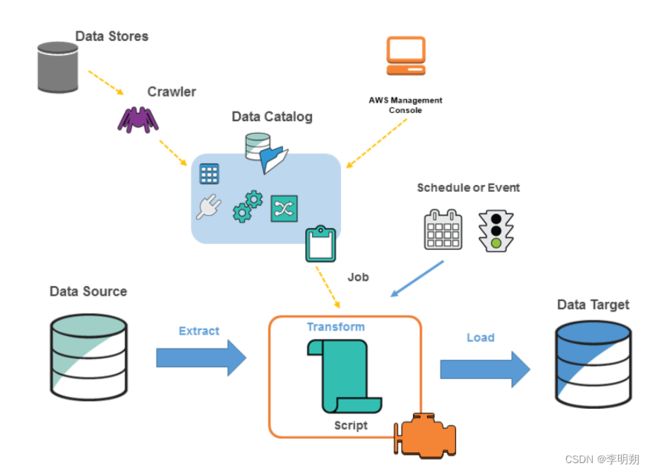
其主要组件包括包括:
- 数据目录(Data Catalog):数据目录是Glue的核心组件,用于存储和管理数据的元数据信息。它记录了数据表、架构、数据源和目标等的定义和属性。数据目录可以与多个AWS服务和外部数据存储系统集成,提供了一个统一的数据管理和查询接口。
- ETL作业(ETL Jobs):ETL作业是AWS Glue中的一个重要组件,用于定义和执行数据抽取、转换和加载(ETL)的流程。用户可以使用Glue提供的开发环境编写ETL脚本,并设置作业的调度和触发规则,以自动化执行数据处理任务。
- 抽取器(Crawlers):抽取器是Glue的一项功能,用于自动发现和推断数据的架构和模式。用户可以配置抽取器来扫描数据源(如Amazon S3、关系数据库等),分析数据集并生成相应的数据目录和表定义。这样可以减少手动定义数据架构的工作量。
- 数据目标:Glue支持将转换后的数据加载到不同的数据目标中。常见的数据目标包括Amazon S3、Amazon Redshift、Amazon RDS等。用户可以配置目标连接和映射规则,将数据按照定义的目标架构和格式加载到相应的数据存储中。
- 调度器和触发器:Glue提供了调度器和触发器的功能,用于自动化执行ETL作业。用户可以设置作业的执行计划和频率,或者使用触发器来响应特定的事件或条件。这样可以实现作业的自动化调度和执行。
- 数据转换和处理引擎:Glue使用Apache Spark作为其底层的数据转换和处理引擎。Spark提供了强大的分布式计算能力,用于执行ETL作业中的数据转换和处理操作。Glue利用Spark的功能来实现高效、可扩展的数据处理。
- AWS Glue Databrew:AWS Glue服务中的一个组件,它是一种可视化数据准备工具,旨在帮助用户快速、轻松地准备和清洗数据,以供后续分析和机器学习使用。
2. AWS EMR
Amazon EMR(Elastic MapReduce)是亚马逊网络服务(AWS)提供的一种全托管的大数据处理服务。它基于Apache Hadoop和Apache Spark等开源框架,旨在简化和加速大数据处理的部署和管理。
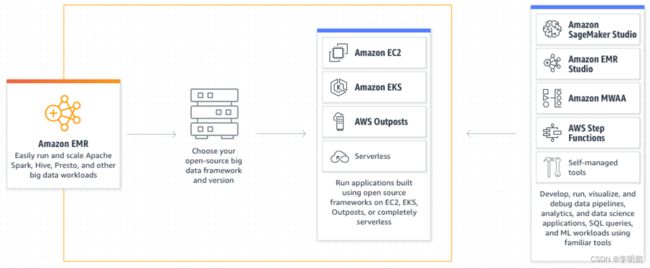
以下是AWS EMR的一些关键特点和功能:
- 弹性扩展:EMR可以根据工作负载的需求自动扩展或收缩集群的容量。您可以根据需要增加或减少计算资源,以适应不同大小的数据处理任务。
- 多样的数据处理工具:EMR支持多种数据处理工具和框架,包括Hadoop、Spark、Presto、Hive、Flink等。您可以根据具体的需求选择适合的工具来处理和分析大数据。
- 高可靠性和容错性:EMR提供了高可靠性和容错性的特性,确保数据处理的稳定性和可靠性。它具有自动监控和自动恢复功能,可以处理节点故障和任务失败,确保数据处理的连续性。
- 安全性和数据保护:EMR提供了多层级的安全性和数据保护措施。它支持VPC(Virtual Private Cloud)网络隔离、数据加密、访问控制和日志审计等功能,确保数据在传输和存储过程中的安全性。
- 集成AWS生态系统:EMR与AWS生态系统的其他服务无缝集成。您可以将EMR与S3存储、Redshift数据仓库、Glue数据准备服务等组合使用,构建完整的大数据处理和分析解决方案。
- 实时和流式处理:EMR支持实时和流式数据处理。它与Apache Kafka、Amazon Kinesis等流处理服务集成,可以处理实时数据流,进行实时分析和决策。
AWS EMR的架构
- 集群(Cluster):EMR的核心单元是集群,它是一组计算资源的集合,用于处理和分析大数据。
集群由一个主节点和多个核心节点组成。集群可以根据需要进行灵活调整,可以增加或减少节点的数量以适应不同的工作负载。 - 主节点(Master Node):主节点是EMR集群的控制节点,负责协调任务和资源管理。主节点维护集群的状态信息,调度任务并监视节点的运行状况。客户端通过主节点与集群进行交互,提交作业、查询状态和获取结果。
- 核心节点(Core Node):核心节点是EMR集群中的计算节点,用于执行数据处理任务。核心节点通过HDFS(Hadoop Distributed File System)存储和管理数据,以便在集群中进行分布式计算。核心节点还可以运行大数据框架(如Hadoop和Spark)的各种任务,如MapReduce、Spark作业、Hive查询等。
- 任务节点(Task Node):任务节点是可选的节点类型,用于执行短暂的、无状态的任务。任务节点通常用于扩展集群的计算能力,以支持更多并发任务和更快的数据处理。任务节点在集群中的角色类似于核心节点,但不具备持久化存储能力。
- 存储:EMR集群使用HDFS来管理数据存储。HDFS是一个可扩展的、分布式的文件系统,允许大数据框架在多个节点上并行存储和访问数据。除了HDFS外,EMR还可以与Amazon S3等云存储服务集成,使得数据可以存储在持久性存储中,并在需要时进行访问。
EMR中的组件:
- Spark:EMR支持Spark,这意味着可以在EMR集群中运行和管理Spark作业。Spark是一种快速、通用且可扩展的大数据处理框架,它支持数据的批处理和实时处理,并提供强大的数据处理能力。
- Pig:EMR支持Pig,允许在EMR集群中运行和管理Pig作业。Pig是一种高级的数据流处理语言,用于将复杂的数据处理任务抽象成简单的脚本,并在Hadoop平台上执行这些脚本。支持多种文件系统包括HDFS,S3。
- Hive:EMR 支持Hive,允许在EMR集群中运行和管理Hive作业。Hive是一个数据仓库和查询语言,它允许您使用类似于SQL的HiveQL查询语言来对存储在Hadoop分布式文件系统(HDFS)或其他数据存储中的数据进行查询和分析。Hive Metastore是一个关键的组件,它用于管理Hive表的元数据信息。Hive Metastore存储了Hive表的结构定义、表的位置信息以及其他相关的元数据,使得Hive可以在执行查询时快速找到和访问表的数据。
- Hbase:EMR支持HBase,允许在EMR集群中运行和管理HBase作为分布式数据库。HBase是一个开源的NoSQL列式数据库,设计用于存储大规模结构化数据,并提供实时读写访问。
- Presto:EMR支持Presto,允许在EMR集群中运行和管理Presto作为交互式查询引擎。Presto是一个开源的分布式SQL查询引擎,设计用于快速查询大规模数据集,并支持多种数据源,如Hive、Amazon S3、RDBMS等。
- Hue:EMR 支持Hue(Hadoop User Experience),允许在EMR集群中使用Hue作为交互式的Web界面来管理和执行Hadoop和其他大数据工具。Hue提供了一个用户友好的界面,使得在Hadoop集群上进行数据查询、作业管理、工作流程设计等操作变得更加简单和直观。
- S3DistCP:用于在Amazon S3之间复制大规模数据。这个工具能够高效地将数据从一个Amazon S3存储桶复制到另一个存储桶,也支持从HDFS(Hadoop Distributed File System)到Amazon S3的复制。
Spark集成:
- Spark streaming+Kinesis:Spark Streaming可以与Amazon Kinesis集成,以实现实时数据流处理。这种集成允许从Amazon Kinesis数据流中读取数据,并将其传送给Spark Streaming进行实时处理和分析。
- Spark+Redshift:Spark可以与Amazon Redshift集成,允许在Spark中处理和分析数据,并将结果保存到Redshift数据仓库中。这种集成能力使您可以使用Spark的强大分析功能来处理大规模数据,并将处理结果存储在Redshift中,以便进行后续的查询和分析。
四、数据分析
1. Elasticsearch
AWS Elasticsearch是亚马逊云服务(AWS)中的一项托管服务,它基于开源的Elasticsearch引擎构建。AWS Elasticsearch为用户提供了一个简单、可扩展和可管理的Elasticsearch集群,用于进行搜索和分析大规模数据。
AWS Elasticsearch主要特点和用途:
- 托管服务:AWS Elasticsearch是一种完全托管的服务,AWS负责管理底层基础设施,包括硬件和软件补丁更新,使用户可以专注于数据处理和分析任务。
- 自动扩展:AWS Elasticsearch可以根据负载自动扩展,根据数据量和查询负荷的增减来调整集群规模,保证性能和可用性。
- 安全性:AWS Elasticsearch提供访问控制和身份验证机制,确保数据的安全性和隐私性。
- 高可用性:AWS Elasticsearch支持多个可用区的部署,保障数据的高可用性和容错性。
- 整合AWS服务:AWS Elasticsearch与其他AWS服务无缝集成,例如Amazon S3、Amazon Kinesis、AWS Lambda等,使得数据的导入和导出变得更加简单和高效。
- Kibana可视化:AWS Elasticsearch集成了Kibana,用于数据可视化和交互式查询。用户可以使用Kibana创建仪表板、图表和地图,从数据中获得更直观的洞察。
2. Amazon Athena
Amazon Athena是AWS提供的一种交互式查询服务,用于分析存储在Amazon S3中的数据。它允许用户使用标准的SQL语言查询和分析大规模的结构化、半结构化和非结构化数据,而无需事先定义模式或进行数据加载。
主要特点和用途:
- 无服务器架构:Amazon Athena是一种无服务器服务,不需要用户管理或配置任何基础设施。您只需提交查询,并让Athena自动处理查询的执行。
- 标准SQL查询:Amazon Athena支持标准的ANSI SQL查询语言,使得用户可以使用熟悉的SQL语法来进行数据查询和分析。
- 数据格式灵活:Athena可以处理多种数据格式,如JSON、CSV、Parquet等。您可以直接查询这些数据,而无需事先进行转换。
- 高效性能:Athena使用分布式查询引擎来处理大规模数据集,从而实现高效的查询性能。
- 可视化工具集成:您可以将Amazon Athena与其他AWS服务和BI工具集成,如Amazon QuickSight、Tableau等,用于数据可视化和报表生成。
- 按需计费:Amazon Athena采用按需计费模式,您只需支付实际查询的数据扫描量,无需预先付费或长期合约。
3. 总结
Amazon Athena、AWS EMR、AWS Redshift和Elasticsearch是AWS云服务中用于数据处理和分析的不同类型的服务,它们之间有一些区别:
- Amazon Athena:Amazon Athena是一种无服务器的查询服务,用于在Amazon S3上执行交互式SQL查询。它适用于在原始数据存储在S3上的场景,支持标准SQL查询,并无需预先加载或转换数据。
适用场景:快速数据探索、数据查询和分析,适合数据湖架构,不需要预先定义模式。 - AWS EMR (Elastic MapReduce):AWS EMR是一种完全托管的大数据处理服务,它支持在分布式集群上运行和管理大规模数据处理工作负载。EMR集成了Hadoop、Spark、Hive等开源大数据工具。
适用场景:复杂的大规模数据处理和分析,包括批处理、实时处理、机器学习等。EMR适合处理需要复杂ETL操作、数据转换和多个数据源的场景。 - AWS Redshift:AWS Redshift是一种完全托管的数据仓库服务,它专用于存储和分析大规模数据集。Redshift使用列式存储和压缩技术,提供高性能的数据查询和复杂的数据聚合功能。
适用场景:构建数据仓库,用于复杂的业务查询、数据报表和BI应用。适合频繁的数据更新和事务处理。 - Elasticsearch:Elasticsearch是一个开源的分布式搜索和分析引擎,专注于快速、可扩展和实时的搜索和分析。它适用于处理大规模的实时数据,如日志分析、数据搜索和实时监控。
适用场景:实时数据搜索、日志分析、实时监控和数据可视化。
五、数据可视化
1. QuickSight
Amazon QuickSight是AWS提供的一种全托管的商业智能(BI)工具和服务。它允许用户从各种数据源中创建、可视化和分享交互式的数据仪表板和报告。
以下是一些关键特点和功能:
- 数据连接和集成:QuickSight可以连接到多种数据源,包括AWS服务(如Amazon S3、Amazon Redshift、Amazon Athena等)、关系型数据库、NoSQL数据库和第三方服务(如Salesforce、MySQL、PostgreSQL等)。它支持数据的实时查询和集成,可以从多个数据源中提取、转换和加载数据。
- 数据探索和可视化:QuickSight提供了丰富的可视化选项,包括图表、图形、表格和地图等。用户可以使用直观的界面和拖放式操作来探索数据、创建交互式仪表板和报告,并通过过滤、排序和交互式控件来进行数据分析和发现。
- 智能分析和预测:QuickSight内置了一些智能分析功能,如自动图表推荐、智能文本解析和异常检测等。它还提供了机器学习集成,可以进行预测分析和趋势预测,帮助用户更好地理解数据并做出有意义的决策。
- 实时协作和共享:QuickSight允许用户与团队成员实时协作,并共享仪表板和报告。用户可以设定访问权限、创建用户组和发布仪表板,以便团队内部或跨部门共享和访问数据可视化结果。
- 安全和可扩展性:QuickSight提供了多层级的安全性和数据保护措施,包括访问控制、数据加密和网络隔离等。它是一种完全托管的服务,自动进行容量管理和扩展,无需用户关心基础架构和资源管理。
AWS QuickSight SPICE(Super-fast, Parallel, In-memory Calculation Engine)是Amazon QuickSight的数据处理和查询引擎。SPICE是一种高性能、并行处理的内存计算引擎,用于加速数据查询和分析,提供快速的数据可视化和报表生成功能。
五、其他服务
1. AWS batch
AWS Batch是亚马逊网络服务(AWS)提供的一项托管式、可扩展的计算服务,用于在云环境中运行大规模批处理作业。它使您能够高效地调度、管理和执行计算密集型工作负载,如批处理处理、数据处理、模拟和分析等。
以下是AWS Batch的一些主要特点和功能:
- 批处理作业调度:AWS Batch提供了灵活的作业调度功能,可以自动按需扩展和分配计算资源(包括GPU)来执行批处理作业。它根据作业的优先级、计算资源的可用性和定义的调度规则来动态分配资源。
- 容器化计算环境:AWS Batch基于容器技术,支持在容器中运行作业。您可以将批处理作业打包到容器镜像中,并使用AWS Batch运行这些容器作业。这样可以实现应用程序的隔离性、可移植性和可重复性。
- 作业定义和参数化:AWS Batch允许您定义作业模板和参数化作业配置。您可以定义作业的计算资源要求、作业的输入和输出位置、环境变量等。这样可以灵活地定义和管理不同类型的批处理作业。
- 任务并行和依赖管理:AWS Batch支持任务并行执行和依赖管理。您可以定义作业中的多个任务,并设置任务之间的依赖关系。这样可以在满足依赖关系的前提下并行执行任务,提高作业的效率和性能。
- 调度器和队列:AWS Batch使用调度器和队列来管理作业的调度和执行。调度器根据队列中的作业请求和可用资源来进行调度,并根据定义的优先级和调度规则来决定作业的执行顺序。
- 监控和日志记录:AWS Batch提供了监控和日志记录功能,帮助您跟踪作业的执行情况和性能指标。您可以使用Amazon CloudWatch监控作业的指标,并通过CloudWatch日志记录来查看作业的日志信息。
AWS batch和AWS Lambda
2. AWS Step
AWS Step Functions是亚马逊网络服务(AWS)提供的一项有状态的无服务器工作流服务。它允许您协调和编排多个AWS服务和Lambda函数,以构建灵活、可靠和可扩展的应用程序和工作流,例如任务的顺序、条件分支、循环、并行处理和错误处理等。
AWS Step Functions支持两种类型的工作流:标准工作流和Express工作流。
- 标准工作流(Standard Workflow):标准工作流是一种具备完整功能和灵活性的工作流类型。它支持多种状态类型,包括任务状态(Task State)、并行状态(Parallel State)、条件状态(Choice State)、延时状态(Wait State)等,以及自定义状态。标准工作流提供了丰富的工作流建模功能,包括条件分支、循环、重试和错误处理等。它适用于需要复杂逻辑和工作流控制的场景,提供更高级的功能和灵活性。
- Express工作流(Express Workflow):Express工作流是一种针对简单、短暂工作流的轻量级工作流类型。它是一种无服务器工作流类型,不支持自定义状态类型,只能使用Lambda任务状态(Lambda Task State)。Express工作流不支持延时状态、条件分支、循环和错误处理等高级功能。与标准工作流相比,Express工作流具有更低的延迟和更高的吞吐量,适用于需要快速响应和高吞吐量的简单工作流场景。
六、安全
AWS Encryption是指在亚马逊云服务(AWS)中对数据进行加密,以确保数据在存储、传输和处理过程中的安全性和保密性。AWS提供了多种加密选项,可以用于保护数据在各种服务和存储中的安全性。
以下是AWS中常见的加密选项:
- 服务器端加密(Server-Side Encryption):在服务器端加密中,数据在上传到AWS服务之前或存储在AWS服务中时,由AWS服务自动对数据进行加密,同时在数据被读取时自动解密。
- 客户端加密(Client-Side Encryption):客户端加密是指在客户端对数据进行加密,并将加密后的数据上传到AWS服务。服务端不需要知道加密密钥,因此可以确保数据在传输和存储过程中的完全保密。用户可以在本地或应用程序中对数据进行加密,然后将加密后的数据上传到AWS服务。解密时,需要在客户端进行解密操作。
- 数据库加密:在AWS RDS(Amazon Relational Database Service)等数据库服务中,用户可以使用服务器端加密选项对数据库实例进行加密,确保数据在存储和传输过程中的安全性。
1. KMS、HSM
AWS Key Management Service(KMS)为AWS云中的各种服务和应用程序提供了安全的密钥管理功能,帮助用户保护数据的机密性,并确保数据在存储和传输过程中的安全性。
AWS CloudHSM(Cloud Hardware Security Module)是亚马逊云服务(AWS)中的一项安全服务,它为客户提供了一个硬件安全模块(HSM)来保护密钥和执行加密操作。HSM是一种专用硬件设备,用于生成、存储和管理加密密钥,并在安全的环境中执行加密和解密操作。
CloudHSM和 KMS在设计和用途上有一些区别:
- 设计和部署方式:
- AWS CloudHSM是一种硬件安全模块(HSM),它为客户提供了专用的硬件设备来保护密钥和执行加密操作。CloudHSM以物理设备的形式提供,需要在AWS中部署专用的HSM实例。
- AWS KMS是一种托管服务,提供了一种更简单的方式来创建和管理密钥,无需用户管理硬件设备。KMS将密钥以软件形式存储,并受AWS进行管理和保护。
- 密钥管理:
- AWS CloudHSM允许客户完全控制密钥的生成、存储和管理。客户的应用程序可以直接与CloudHSM进行交互,执行加密和解密操作,同时保护密钥不离开HSM。
- AWS KMS提供了更简化的密钥管理,AWS KMS服务为客户自动管理密钥的创建、轮换、备份和监控,同时也提供了访问控制和审计功能。
- 适用场景:
- AWS CloudHSM适用于安全性要求非常高的场景,如金融服务、医疗保健等领域,这些领域可能需要自己控制密钥和执行加密操作。
- AWS KMS适用于更广泛的用例,适用于许多应用程序和服务,不需要自行管理硬件设备,以简化密钥管理。
- 成本:
- AWS CloudHSM通常较为昂贵,因为它涉及到硬件设备的购买和部署,以及实例的运行费用。
- AWS KMS则相对较为经济实惠,因为它是AWS的托管服务,无需用户支付硬件成本。
2.STS
AWS STS(Security Token Service)是亚马逊云服务(AWS)中的一项服务,它允许用户获取临时安全凭证,用于访问AWS资源和执行操作。STS提供了一种安全的方式,让用户获得有限的权限来访问特定的AWS资源,而不需要共享长期的AWS访问凭证。
主要特点和用途:
- 临时凭证:AWS STS发放临时安全凭证,包括临时访问密钥、安全令牌和临时会话令牌。这些临时凭证有效期有限,通常在几分钟到几小时之间。
- 跨账户访问:AWS STS支持跨AWS账户的访问。用户可以在一个AWS账户中使用STS获取临时凭证,然后将这些凭证用于访问另一个AWS账户的资源。
- 联合身份:STS可以与身份提供商(如Amazon Cognito、Azure AD等)进行集成,实现联合身份验证,用于访问AWS资源。
- 条件访问:STS允许用户在获取临时凭证时添加条件,如限制访问特定的AWS资源、限制操作权限等,从而实现更细粒度的访问控制。
- IAM角色:STS可以用于获取IAM角色的临时凭证,这样可以实现临时授权,而无需共享长期的访问凭证。
3. Federation
AWS Federation是指在亚马逊云服务(AWS)中使用身份联合(Federation)来实现跨域访问和身份验证。它允许用户在一个AWS账户中获取临时安全凭证,并将这些凭证用于访问另一个AWS账户的资源。通过AWS Federation,用户可以使用单一身份进行跨AWS账户的访问,而无需共享长期的AWS凭证。
主要特点和用途:
- 跨账户访问:AWS Federation允许用户在一个AWS账户中登录并获取临时凭证,然后将这些临时凭证用于访问另一个AWS账户的资源。这样可以实现跨账户的资源访问和管理。
- 联合身份提供商:AWS Federation可以与身份提供商(Identity Provider,IdP)进行集成,如Microsoft Active Directory、Amazon Cognito等。用户可以使用自己组织内的凭证进行登录,而不是使用AWS的凭证。
- 临时凭证:在使用AWS Federation时,用户获取的是临时的安全凭证,包括临时访问密钥、安全令牌和临时会话令牌。这些凭证的有效期有限,通常在几分钟到几小时之间,从而增加了安全性。
- IAM角色:AWS Federation通常结合IAM(Identity and Access Management)角色使用,用户可以在跨账户访问时获取临时的IAM角色凭证,从而实现临时授权。
- 安全访问控制:AWS Federation可以通过IAM角色和权限策略来实现安全的访问控制。用户可以对临时凭证添加条件和限制,从而控制访问特定的AWS资源和操作。
AWS联合相关的一些关键服务:
- AWS Security Token Service(STS):AWS STS是核心服务之一,它负责颁发临时安全凭证,包括临时访问密钥、安全令牌和临时会话令牌。这些临时凭证的有效期有限,用于实现更安全的访问控制和资源访问。
- AWS Identity and Access Management(IAM):IAM是AWS的身份和访问管理服务,用于创建和管理用户、组和角色,并定义资源的访问权限。通过联合身份验证,IAM角色可以被临时扮演,授予用户对AWS资源的临时访问权限。
- 身份提供商(Identity Providers,IdPs):身份提供商是外部系统或服务,提供身份认证和用户身份信息。AWS支持多种身份提供商,包括基于SAML的IdPs,如Microsoft Active Directory、ADFS,以及第三方身份提供商,如Google、Okta、PingFederate等。
- Amazon Cognito:Amazon Cognito是一个全托管的服务,提供用户池(User Pools)用于创建用户目录,管理用户身份认证和授权。它还提供身份池(Identity Pools),允许您为经过联合身份提供商认证的用户颁发临时AWS凭证。
- AWS Single Sign-On(SSO):AWS SSO是一个服务,简化了多个AWS账户的管理和联合身份访问。用户只需使用现有的企业凭证登录一次,即可访问多个AWS账户,无需输入单独的AWS凭证。
- AWS Organizations:AWS Organizations是一个服务,允许您集中管理多个AWS账户。与AWS联合结合使用,可以实现跨账户访问和资源共享。
- AWS SAML终端点:AWS提供了基于SAML的终端点,允许身份提供商与AWS进行通信,交换身份认证和授权信息。这在基于SAML的联合身份验证场景中使用。
4. Cloudtrial
AWS CloudTrail是亚马逊云服务(AWS)中的一项服务,用于跟踪和记录AWS账户中的API活动和资源操作。CloudTrail可以帮助用户实现对AWS环境中的安全性、合规性和操作可视化的监控。
主要特点和用途:
- API活动跟踪:CloudTrail会记录AWS账户中发生的每个API调用,包括对AWS管理控制台、命令行工具和AWS SDK的调用。这些活动包括创建、删除、修改AWS资源的操作等。
- 资源操作监控:除了API活动,CloudTrail还会记录对AWS资源的操作,如启动EC2实例、更改S3存储桶策略等。这有助于审计和监控AWS资源的使用情况。
- 安全审计:CloudTrail记录的日志信息可以用于安全审计和调查安全事件。它可以帮助识别不正常的活动和潜在的安全威胁。
- 合规性要求:CloudTrail生成的日志符合多个合规性标准,如PCI DSS、HIPAA和FISMA等。它可以用于满足各种监管和合规性要求。
- 日志存储:CloudTrail日志可以存储在AWS S3存储桶中,用户可以自定义存储位置和日志保留期限。
- 故障排除:通过查看CloudTrail日志,可以帮助快速诊断和解决AWS环境中的故障和问题。