最新| ClickHouse入门、调优、实战一条龙全解秘籍
Clickhouse 是一个高性能且开源的数据库管理系统,主要用于在线分析处理 (OLAP) 业务。它采用列式存储结构,可使用 SQL 语句实时生成数据分析报告,另外它还支持索引,分布式查询以及近似计算等特性,凭借其优异的表现,ClickHouse 在各大互联网公司均有广泛地应用。
Why ClickHouse
首先我们来看一下OLAP 场景下的关键特征。
1.大多数数据库访问都是读请求。
2.数据总是以批量形式写入数据库(每次写入大于 1000 行)。
3.已添加的数据一般无需修改。
4.每次查询都从数据库中读取大量的行,但是同时又仅需少量的列。
5.数据表多为宽表,即每个表均包含着大量的列。
6.查询量一般较少(非高并发,通常每台服务器每秒约有数百个查询或更少)。
7.对于简单查询,允许的延迟大约为 50 毫秒(响应时间要迅速)。
8.列中的数据相对较小,一般为数字或短字符串。
9.处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)。
10.事务不是必须的。
11.对数据一致性要求低。
12.查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被存放在单台服务器的内存中。
可以看到,OLAP 业务场景与其它流行的业务场景如 OLTP 等有很大的不同,使用 OLTP 数据库或 Key-Value 数据库去处理分析查询业务将会获得非常差的性能,而且没有任何意义。
另外,相比于行式数据库,列式数据库则更适用于 OLAP 场景,因为对于大多数的查询而言,列式数据库的处理速度要至少比行式数据库快 100 倍。二者的性能差别很大,列式数据库明显占优,可以从以下几方面来解释:
对于分析类查询,通常只需要读取数据表中的一小部分列,使用列式数据库可以很轻松地实现,而使用行式数据库却必须要读取全部的列,这就带来了性能的损失。
列式数据库按列存储数据,使得数据更容易被压缩,可以降低 I/O 传输的体积,从而使查询速度加快。
由于 I/O 体积的降低,可以使得更多的查询数据被系统缓存,进一步加快了查询的速度。
另外,执行一个查询一般需要处理大量的行,在整个列向量上执行所有操作将比在每一行上执行所有操作更加高效,而且还可以更加充分地利用 CPU 资源,从而提升了查询的性能。
ClickHouse 特性
相比于其它的列式数据库,ClickHouse 的以下特性决定了它更适用于 OLAP 业务场景。
1.数据压缩:ClickHouse 会自动对插入的数据进行压缩,这对于性能的提升起到了至关重要的作用。
2.磁盘存储:ClickHouse 被设计为工作在传统磁盘上,这意味着数据存储的成本较低。
3.多核心并行处理:ClickHouse 会利用服务器的一切必要资源,从而以最自然的方式并行化处理大规模查询。
4.分布式查询:在 ClickHouse 中,数据可以保存在不同的分片 (shard) 上,查询可以在所有分片上并行处理。
5.支持 SQL:ClickHouse 的查询语言大部分情况下是与 SQL 标准兼容的,更容易上手。
6.向量引擎:ClickHouse 采用了列向量引擎技术,可以更为高效地使用 CPU 资源。
7.实时数据更新:ClickHouse 使用 MergeTree 引擎对数据进行增量排序,数据可以持续不断地写入到表中并进行合并,而且在整个过程中不会存在任何加锁行为。
8.支持索引:ClickHouse 按照排序键对数据进行排序并支持主键索引,可以使其在几十毫秒内完成对特定值或特定范围的查找。
9.支持近似计算:ClickHouse 提供了许多在允许牺牲数据精度的情况下对查询进行加速的方法。
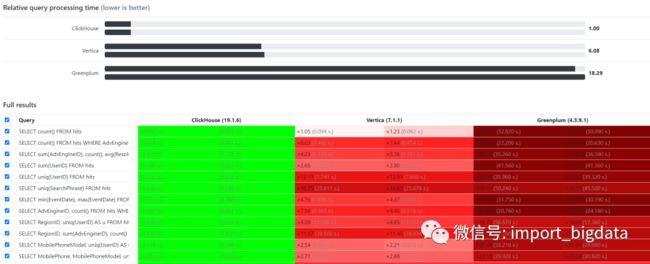
下图显示了 ClickHouse 与其它主流列式数据库的性能对比。可以看到,对于大多数查询而言,ClickHouse 的响应速度更快,这也是选择 ClickHouse 作为 OLAP 数据处理的主要原因。
ClickHouse 配置文件
在使用 ClickHouse 之前,我们需要修改 ClickHouse 配置文件中的一些默认配置,比如数据存储路径,集群信息以及用户信息等,这样可以更好地对 ClickHouse 进行管理控制,以满足我们的业务需求。
01配置说明
1.ClickHouse 支持多配置文件管理,主配置文件为 config.xml,默认位于 /etc/clickhouse-server 目录下,其余的配置文件均需包含在 /etc/clickhouse-server/config.d 目录下。
2.ClickHouse 的所有配置文件均是 XML 格式的,而且在每个配置文件中都需要有相同的根元素,通常为。
3.主配置文件中的一些配置可以通过 replace 或 remove 属性被其子配置文件所覆盖,如子配置文件中的表示将使用该配置来替换主配置文件中的 zookeeper 选项。如果两个属性都未指定,则会递归组合各配置文件的内容并替换重复子项的值。
4.另外,配置文件中还可以定义 substitution 替换,如果一个配置包含 incl 属性,则替换文件中相应的配置将被使用。默认情况下替换文件的路径为 /etc/metrika.xml,可以通过 include_from 配置项进行设置。如果待替换的配置不存在,ClickHouse 会记录错误日志,为了避免这种情况,可以指定配置项的 optional 属性来表示该替换是可选的,如。
5.在启动时,ClickHouse 会根据已有的配置文件生成相应的预处理文件,这些文件中包含了所有已完成替换和覆盖的配置项,它们被统一放置于 preprocessed 目录下,你可以从这些文件中查看最终的配置项是否正确。另外 ClickHouse 会跟踪配置文件的更改,对于某些配置如集群配置以及用户配置等,更改后会自动生效,无需重启 ClickHouse 服务,而对于其它配置项的更改可能需要重启服务才能生效。
6.对于集群中的全部 ClickHouse 节点,除部分配置(如 macros)外,其它所有的配置最好都保持一致,以便于统一管理及使用。
02数据路径配置
1.数据路径下既存储数据库和表的元数据信息(位于 metadata 目录)也存储表的真实数据(位于 data 目录)。元数据是指建库和建表的语句,亦即数据库和表的结构信息,每次 ClickHouse 启动时会根据元数据信息去加载相应的数据库和表。
2.数据路径的配置如下所示,其对应的 XML 标签为。
/path/to/clickhouse/ 3.当单个物理盘无法存储全部的数据时,可以考虑将不同的数据库存储在不同的物理盘上,然后在 /path/to/clickhouse/data/ 目录下创建软连接指向其它物理盘上的数据库目录。
03日志配置
1.ClickHouse 的日志文件中记录了各种类型的事件日志,包括数据的插入和查询的日志以及一些配置和数据合并相关的日志等。一般我们会通过日志文件找出 ClickHouse 报错的具体原因,以便解决问题。
2.日志的配置如下所示,其对应的 XML 标签为。
trace
/path/to/clickhouse-server/clickhouse-server.log
/path/to/clickhouse-server/clickhouse-server.err.log
1000M
10
3.level 表示事件的日志级别,可以配置为 trace,debug,information,warning,error 等值。
4.log 表示主日志文件路径,该日志文件中包含所有 level 级别以上的事件日志。
5.errorlog 表示错误日志文件路径,该日志文件仅包含错误日志,便于问题排查。
6.size 表示日志大小,当日志文件达到指定 size 后,ClickHouse 会进行日志轮转。
7.count 表示日志轮转的最大数量。
8.需要注意,因为事件日志是由多线程异步写入到日志文件中的,所以不同事件之间的日志会产生交错,不利于按顺序进行日志排查。但 ClickHouse 为每个事件都提供了唯一的 ID 来标识,我们可以根据此 ID 来跟踪事件状态的变化。
04集群配置
1.集群的配置主要用于分布式查询,在创建分布式表 (Distributed) 时会用到。2.集群配置文件的示例如下所示,其对应的 XML 标签为。
1
false
hostname1/ip1
9000
1
false
hostname2/ip2
9000
3.cluster_name 表示集群名称,shard 表示集群的分片(即 ClickHouse 节点),集群会有多个 shard,每个 shard 上都存有全部数据的一部分。
4.weight 表示数据写入的权重,当有数据直接写入集群时会根据该权重来将数据分发给不同的 ClickHouse 节点,可以理解为权重轮询负载均衡。
5.replica 表示每个 shard 的副本,默认为 1 个,可以设置多个,表示该 shard 有多个副本。正常情况下,每个副本都会存有相同的数据。
6.internal_replication 表示副本间是否为内部复制,当通过集群向分片插入数据时会起作用,参数的默认值为 false,表示向该分片的所有副本中写入相同的数据(副本间数据一致性不强,无法保证完全同步),true 表示只向其中的一个副本写入数据(副本间通过复制表来完成同步,能保证数据的一致性)。
7.在实际情况下,我们一般不会通过集群进行数据写入,而是将数据直接写入到各 ClickHouse 节点。一来通过集群进行分发数据会带来二次的网络延迟,降低了数据的写入速度,二来当数据量较多时,由于网络带宽限制,数据分发节点会成为数据传输的瓶颈,从而拉低了整体的数据写入效率。
8.可以定义多个集群,以应对不同的查询需要。每次添加新的集群配置后,无需重启 ClickHouse 服务,该配置会即时生效。
05字典配置
1.字典就是一种键->值映射关系,一般在数据查询时使用。相比于多表 JOIN 的查询操作,使用字典查询会更加高效。
2.字典文件的位置需要由 config.xml 文件中的 dictionaries_config 配置项设置。
dictionaries/*_dictionary.xml 上述配置表示 ClickHouse 会从与 config.xml 文件同级的 dictionaries 目录下加载以 _dictionary.xml 为后缀的全部字典文件。
3.字典配置文件的示例如下所示,其对应的 XML 标签为。
TabSeparated
key
String
value
String
true
300
4.name 表示字典名称。
5.source 表示字典的数据来源,数据来源有多种类型,可以是本地的文本文件,HTTP 接口或者其它各种数据库管理系统。
6.layout 表示字典在内存中的存储方式。一般推荐使用 flat,hashed 和 complex_key_hashed 存储方式,因为它们提供了最佳的查询处理速度。
7.structure 表示字典的结构,亦即键值对的信息。
key 表示字典的键值,它可以由多个属性组成。
attribute 表示字典的值,也可以有多个。8.lifetime 表示字典的更新频率,单位为秒。
9.创建完字典后,我们就可以通过 SELECT dictGetTYPE) 语句来查询字典中指定 key 值对应的 value 了。其中 TYPE 表示具体的数据类型,比如获取字符串类型的值可以使用 dictGetString。
10.除了使用配置文件来创建字典外,还可以使用 SQL 语句来生成字典。但相对而言,使用配置文件会更加直观便捷。
06用户配置
1.config.xml 可以指定单独的文件来对用户信息进行配置,用户配置文件的路径通过 users_config 配置项指定,默认为 users.xml。
users.xml 2.与 config.xml 文件类似,用户配置也可以被切分为不同的文件以便于管理,这些文件需要保存到 users.d 目录下。
3.ClickHouse 的默认用户为 default,密码为空。
4.用户配置的示例如下所示,其对应的 XML 标签为。
::/0
profile_name
default
5.user_name 表示待添加的用户名。
6.password 表示明文密码,不推荐使用该方式设置密码。
7.password_sha256_hex 表示经过 sha256 hash 后的密码,推荐使用该方式设置密码,密码的生成方式如下所示。
echo -n "$PASSWORD" | sha256sum | tr -d '-'8.networks 表示允许连接到 ClickHouse 节点的网络地址列表,可以为 IP 地址或 Hostname。::/0 表示该用户可以从任何网络地址连接到 ClickHouse 节点。
9.profile 表示对用户的一系列设置,用以控制用户的行为,如设置该用户具有只读权限等。它是以单独的 XML 标签存在于 users.xml 文件中的。配置的示例如下所示。
8
30000000000
in_order
1
profile 的名称可以任意,不同的用户可以配置相同的 profile。另外需要注意,default profile 必须存在,它会在 ClickHouse 启动时作为默认的设置使用。10.quota 表示用户配额设置,用来限制用户一段时间内的资源使用,如 1 小时内的查询数不超过 1024 等。它同样是以单独的 XML 标签存在于 users.xml 文件中的。配置的示例如下所示。
3600
0
0
0
0
0
配额限制与 profile 中限制的主要区别在于,它可以对一段时间内运行的一组查询设置限制,而不是限制单个查询。11.除了使用配置文件管理用户,还可以基于 SQL 语句来创建、修改或删除用户。但相对而言,使用配置文件会更加直观便捷。
07ZooKeeper 配置
1.zookeeper 配置允许 ClickHouse 与一个 ZooKeeper 集群进行交互。ClickHouse 主要使用 ZooKeeper 来存储复制表的元数据,当不使用复制表时,该配置可以忽略。
2.ZooKeeper 配置文件的示例如下所示,其对应的 XML 标签为。
hostname1/ip1
2181
hostname2/ip2
2181
hostname3/ip3
2181
3.node 表示一个 ZooKeeper 节点,可以设置多个。当尝试连接到 ZooKeeper 集群时,index 属性指定了各节点的连接顺序。
08Macros 配置
1.macros 配置主要用来替换复制表的参数,在创建复制表时需要用到,当不使用复制表时,该配置可以忽略。
2.Macros 配置文件的示例如下所示,其对应的 XML 标签为。
01
hostname/ip
09Prometheus 配置
1.该配置用来供 Prometheus 获取 ClickHouse 的指标信息。
2.Prometheus 配置的示例如下所示,其对应的 XML 标签为。
/metrics
9363
true
true
true
3.endpoint 表示指标接口的 URI。
4.port 表示指标服务所使用的端口。
5.metrics,events 和 asynchronous_metrics 都是标志项,代表是否暴露相应的指标信息。
6.配置完成后,即可访问 http://ip:port/metrics 来查看所有的 ClickHouse 指标信息了。
10MergeTree 配置
1.该配置用来对使用 MergeTree 系列引擎的表进行微调。需要注意,除非你对该配置有充分的了解,否则不建议修改。
2.MergeTree 配置的示例如下所示,其对应的 XML 标签为。
300
3.更多 MergeTree 相关配置可以参见源码中的 MergeTreeSettings.h 头文件。
11其他常用配置
1.时区配置。
Asia/Shanghai 2.最大连接数配置。
4096 3.并发查询数配置。
200 4.ClickHouse 最大内存使用量配置。
0 5.可删除表的最大数据量配置。
0 单位为字节,默认值为 50 G,当表中数据大小超过该限制时,不能使用 DROP 语句去删除该表(防止误操作)。如果设置为 0,表示没有任何限制。如果你仍然想删除某个数据量超限的表而不想修改上述配置并重启 ClickHouse 时,可以在 ClickHouse 的数据目录下创建一个标志文件 /path/to/clickhouse/flags/force_drop_table 表示可以强制删除该表,然后执行 DROP 语句即可删表成功。
需要注意上述标志文件在执行完一次 DROP 语句后会被自动删除以防止再次执行意外的 DROP 操作,因此执行创建标志文件和执行 DROP 语句的系统用户(非 ClickHouse 用户)应该保持一致,以避免在执行完 DROP 语句后,用户没有权限删除标志文件,从而导致后续操作失误并造成数据损失。
6.更多的配置可参见其官方文档,然后再按需调整。
ClickHouse 表引擎
ClickHouse 的表引擎是 ClickHouse 服务的核心,它们决定了 ClickHouse 的以下行为:
1.数据的存储方式和位置。
2.支持哪些查询操作以及如何支持。
3.数据的并发访问。
4.数据索引的使用。
5.是否可以支持多线程请求。
6.是否可以支持数据复制。
ClickHouse 包含以下几种常用的引擎类型:
MergeTree 引擎:该系列引擎是执行高负载任务的最通用和最强大的表引擎,它们的特点是可以快速插入数据以及进行后续的数据处理。该系列引擎还同时支持数据复制(使用Replicated的引擎版本),分区 (partition) 以及一些其它引擎不支持的额外功能。
Log 引擎:该系列引擎是具有最小功能的轻量级引擎。当你需要快速写入许多小表(最多约有 100 万行)并在后续任务中整体读取它们时使用该系列引擎是最有效的。
集成引擎:该系列引擎是与其它数据存储以及处理系统集成的引擎,如 Kafka,MySQL 以及 HDFS 等,使用该系列引擎可以直接与其它系统进行交互,但也会有一定的限制,如确有需要,可以尝试一下。
特殊引擎:该系列引擎主要用于一些特定的功能,如 Distributed 用于分布式查询,MaterializedView 用来聚合数据,以及 Dictionary 用来查询字典数据等。
MergeTree系列引擎
在所有的表引擎中,最为核心的当属MergeTree系列表引擎,这些表引擎拥有最为强大的性能和最广泛的使用场合。对于非MergeTree系列的其他引擎而言,主要用于特殊用途,场景相对有限。而MergeTree系列表引擎是官方主推的存储引擎,支持几乎所有ClickHouse核心功能。
MergeTree表引擎
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来。
MergeTree作为家族系列最基础的表引擎,主要有以下特点:
存储的数据按照主键排序:允许创建稀疏索引,从而加快数据查询速度
支持分区,可以通过PRIMARY KEY语句指定分区字段。
支持数据副本
支持数据采样
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]ENGINE:ENGINE = MergeTree(),MergeTree引擎没有参数
ORDER BY:排序字段。比如ORDER BY (Col1, Col2),值得注意的是,如果没有指定主键,默认情况下 sorting key(排序字段)即为主键。如果不需要排序,则可以使用ORDER BY tuple()语法,这样的话,创建的表也就不包含主键。这种情况下,ClickHouse会按照插入的顺序存储数据。必选。
PARTITION BY:分区字段,可选。
PRIMARY KEY:指定主键,如果排序字段与主键不一致,可以单独指定主键字段。否则默认主键是排序字段。可选。
SAMPLE BY:采样字段,如果指定了该字段,那么主键中也必须包含该字段。比如SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。可选。
TTL:数据的存活时间。在MergeTree中,可以为某个列字段或整张表设置TTL。当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据;如果是表级别的TTL,则会删除整张表的数据。可选。
SETTINGS:额外的参数配置。可选。
建表示例
CREATE TABLE emp_mergetree (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=MergeTree()
ORDER BY emp_id
PARTITION BY work_place
;
-- 插入数据
INSERT INTO emp_mergetree
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_mergetree
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
-- 查询数据
-- 按work_place进行分区
cdh04 :) select * from emp_mergetree;
SELECT *
FROM emp_mergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘查看一下数据存储格式,可以看出,存在三个分区文件夹,每一个分区文件夹内存储了对应分区的数据。
[root@cdh04 emp_mergetree]# pwd
/var/lib/clickhouse/data/default/emp_mergetree
[root@cdh04 emp_mergetree]# ll
总用量 16
drwxr-x--- 2 clickhouse clickhouse 4096 9月 17 17:45 1c89a3ba9fe5fd53379716a776c5ac34_3_3_0
drwxr-x--- 2 clickhouse clickhouse 4096 9月 17 17:44 40d45822dbd7fa81583d715338929da9_1_1_0
drwxr-x--- 2 clickhouse clickhouse 4096 9月 17 17:45 a6155dcc1997eda1a348cd98b17a93e9_2_2_0
drwxr-x--- 2 clickhouse clickhouse 6 9月 17 17:43 detached
-rw-r----- 1 clickhouse clickhouse 1 9月 17 17:43 format_version.txt进入一个分区目录查看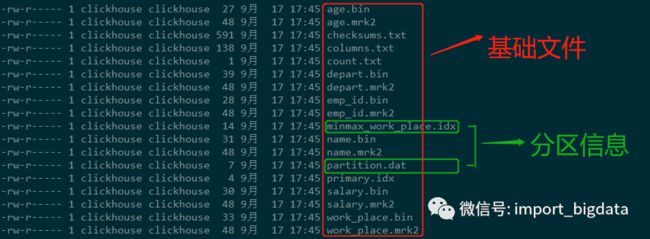
checksums.txt:校验文件,使用二进制格式存储。它保存了余下各类文件(primary. idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。
columns.txt:列信息文件,使用明文格式存储。用于保存此数据分区下的列字段信息,例如
[root@cdh04 1c89a3ba9fe5fd53379716a776c5ac34_3_3_0]# cat columns.txt columns format version: 1 6 columns: `emp_id` UInt16 `name` String `work_place` String `age` UInt8 `depart` String `salary` Decimal(9, 2)count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数
primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引,即通过ORDER BY或者PRIMARY KEY指定字段。借助稀疏索引,在数据查询的时能够排除主键条件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度。
列.bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列的数据。由于MergeTree采用列式存储,所以每一个列字段都拥有独立的.bin数据文件,并以列字段名称命名。
列.mrk2:列字段标记文件,使用二进制格式存储。标记文件中保存了.bin文件中数据的偏移量信息
partition.dat与minmax_[Column].idx:如果指定了分区键,则会额外生成partition.dat与minmax索引文件,它们均使用二进制格式存储。partition.dat用于保存当前分区下分区表达式最终生成的值,即分区字段值;而minmax索引用于记录当前分区下分区字段对应原始数据的最小和最大值。比如当使用EventTime字段对应的原始数据为2020-09-17、2020-09-30,分区表达式为PARTITION BY toYYYYMM(EventTime),即按月分区。partition.dat中保存的值将会是2019-09,而minmax索引中保存的值将会是2020-09-17 2020-09-30。
注意点
多次插入数据,会生成多个分区文件
-- 新插入两条数据
cdh04 :) INSERT INTO emp_mergetree
VALUES (5,'robin','北京',35,'财务部',50000),(6,'lilei','北京',38,'销售事部',50000);
-- 查询结果
cdh04 :) select * from emp_mergetree;
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name──┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 5 │ robin │ 北京 │ 35 │ 财务部 │ 50000.00 │
│ 6 │ lilei │ 北京 │ 38 │ 销售事部 │ 50000.00 │
└────────┴───────┴────────────┴─────┴──────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘可以看出,新插入的数据新生成了一个数据块,并没有与原来的分区数据在一起,我们可以执行optimize命令,执行合并操作
-- 执行合并操作
cdh04 :) OPTIMIZE TABLE emp_mergetree PARTITION '北京';
-- 再次执行查询
cdh04 :) select * from emp_mergetree;
SELECT *
FROM emp_mergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name──┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
│ 5 │ robin │ 北京 │ 35 │ 财务部 │ 50000.00 │
│ 6 │ lilei │ 北京 │ 38 │ 销售事部 │ 50000.00 │
└────────┴───────┴────────────┴─────┴──────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘执行上面的合并操作之后,会新生成一个该分区的文件夹,原理的分区文件夹不变。
在MergeTree中主键并不用于去重,而是用于索引,加快查询速度
-- 插入一条相同主键的数据
INSERT INTO emp_mergetree
VALUES (1,'sam','杭州',35,'财务部',50000);
-- 会发现该条数据可以插入,由此可知,并不会对主键进行去重ReplacingMergeTree表引擎
上文提到MergeTree表引擎无法对相同主键的数据进行去重,ClickHouse提供了ReplacingMergeTree引擎,可以针对相同主键的数据进行去重,它能够在合并分区时删除重复的数据。值得注意的是,ReplacingMergeTree只是在一定程度上解决了数据重复问题,但是并不能完全保障数据不重复。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...][ver]:可选参数,列的版本,可以是UInt、Date或者DateTime类型的字段作为版本号。该参数决定了数据去重的方式。
当没有指定[ver]参数时,保留最新的数据;如果指定了具体的值,保留最大的版本数据。
建表示例
CREATE TABLE emp_replacingmergetree (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=ReplacingMergeTree()
ORDER BY emp_id
PRIMARY KEY emp_id
PARTITION BY work_place
;
-- 插入数据
INSERT INTO emp_replacingmergetree
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_replacingmergetree
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);注意点
当我们再次向该表插入具有相同主键的数据时,观察查询数据的变化
INSERT INTO emp_replacingmergetree
VALUES (1,'tom','上海',25,'技术部',50000);
-- 查询数据,由于没有进行合并,所以存在主键重复的数据
cdh04 :) select * from emp_replacingmergetree;
SELECT *
FROM emp_replacingmergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
-- 执行合并操作
optimize table emp_replacingmergetree final;
-- 再次查询,相同主键的数据,保留最近插入的数据,旧的数据被清除
cdh04 :) select * from emp_replacingmergetree;
SELECT *
FROM emp_replacingmergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘从上面的示例中可以看出,ReplacingMergeTree是支持对数据去重的,那么是根据什么进行去重呢?答案是:ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY。我们在看一个示例:
CREATE TABLE emp_replacingmergetree1 (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=ReplacingMergeTree()
ORDER BY (emp_id,name) -- 注意排序key是两个字段
PRIMARY KEY emp_id -- 主键是一个字段
PARTITION BY work_place
;
-- 插入数据
INSERT INTO emp_replacingmergetree1
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_replacingmergetree1
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);再次向该表中插入相同emp_id和name的数据,并执行合并操作,再观察数据
-- 插入数据
INSERT INTO emp_replacingmergetree1
VALUES (1,'tom','上海',25,'技术部',50000),(1,'sam','上海',25,'技术部',20000);
-- 执行合并操作
optimize table emp_replacingmergetree1 final;
-- 再次查询,可见相同的emp_id和name数据被去重,而形同的主键emp_id不会去重
-- ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY
cdh04 :) select * from emp_replacingmergetree1;
SELECT *
FROM emp_replacingmergetree1
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ sam │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘至此,我们知道了ReplacingMergeTree是支持去重的,并且是按照ORDERBY排序键为基准进行去重的。细心的你会发现,上面的重复数据是在一个分区内的,那么如果重复的数据不在一个分区内,会发生什么现象呢?我们再次向上面的emp_replacingmergetree1表插入不同分区的重复数据
-- 插入数据
INSERT INTO emp_replacingmergetree1
VALUES (1,'tom','北京',26,'技术部',10000);
-- 执行合并操作
optimize table emp_replacingmergetree1 final;
-- 再次查询
-- 发现 1 │ tom │ 北京 │ 26 │ 技术部 │ 10000.00
-- 与 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00
-- 数据重复,因为这两行数据不在同一个分区内
-- 这是因为ReplacingMergeTree是以分区为单位删除重复数据的。
-- 只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除
cdh04 :) select * from emp_replacingmergetree1;
SELECT *
FROM emp_replacingmergetree1
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 北京 │ 26 │ 技术部 │ 10000.00 │
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ sam │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 50000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘总结
如何判断数据重复
ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY。
何时删除重复数据
在执行分区合并时,会触发删除重复数据。optimize的合并操作是在后台执行的,无法预测具体执行时间点,除非是手动执行。
不同分区的重复数据不会被去重
ReplacingMergeTree是以分区为单位删除重复数据的。只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。
数据去重的策略是什么
如果没有设置[ver]版本号,则保留同一组重复数据中的最新插入的数据;如果设置了[ver]版本号,则保留同一组重复数据中ver字段取值最大的那一行。
optimize命令使用
一般在数据量比较大的情况,尽量不要使用该命令。因为在海量数据场景下,执行optimize要消耗大量时间
SummingMergeTree表引擎
该引擎继承了MergeTree引擎,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值,即如果存在重复的数据,会对对这些重复的数据进行合并成一条数据,类似于group by的效果。
推荐将该引擎和 MergeTree 一起使用。例如,将完整的数据存储在 MergeTree 表中,并且使用 SummingMergeTree 来存储聚合数据。这种方法可以避免因为使用不正确的主键组合方式而丢失数据。
如果用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的,即GROUP BY的分组字段是确定的,可以使用该表引擎。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = SummingMergeTree([columns]) -- 指定合并汇总字段
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]建表示例
CREATE TABLE emp_summingmergetree (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=SummingMergeTree(salary)
ORDER BY (emp_id,name) -- 注意排序key是两个字段
PRIMARY KEY emp_id -- 主键是一个字段
PARTITION BY work_place
;
-- 插入数据
INSERT INTO emp_summingmergetree
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_summingmergetree
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);当我们再次插入具有相同emp_id,name的数据时,观察结果
INSERT INTO emp_summingmergetree
VALUES (1,'tom','上海',25,'信息部',10000),(1,'tom','北京',26,'人事部',10000);
cdh04 :) select * from emp_summingmergetree;
-- 查询
SELECT *
FROM emp_summingmergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 北京 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 信息部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
-- 执行合并操作
optimize table emp_summingmergetree final;
cdh04 :) select * from emp_summingmergetree;
-- 再次查询,新插入的数据 1 │ tom │ 上海 │ 25 │ 信息部 │ 10000.00
-- 原来的数据 :1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00
-- 这两行数据合并成:1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00
SELECT *
FROM emp_summingmergetree
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 北京 │ 26 │ 人事部 │ 10000.00 │
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘注意点
要保证PRIMARY KEY expr指定的主键是ORDER BY expr 指定字段的前缀,比如
-- 允许
ORDER BY (A,B,C)
PRIMARY KEY A
-- 会报错
-- DB::Exception: Primary key must be a prefix of the sorting key
ORDER BY (A,B,C)
PRIMARY KEY B这种强制约束保障了即便在两者定义不同的情况下,主键仍然是排序键的前缀,不会出现索引与数据顺序混乱的问题。
总结
SummingMergeTree是根据什么对两条数据进行合并的
用ORBER BY排序键作为聚合数据的条件Key。即如果排序key是相同的,则会合并成一条数据,并对指定的合并字段进行聚合。仅对分区内的相同排序key的数据行进行合并
以数据分区为单位来聚合数据。当分区合并时,同一数据分区内聚合Key相同的数据会被合并汇总,而不同分区之间的数据则不会被汇总。如果没有指定聚合字段,会怎么聚合
如果没有指定聚合字段,则会按照非主键的数值类型字段进行聚合对于非汇总字段的数据,该保留哪一条
如果两行数据除了排序字段相同,其他的非聚合字段不相同,那么在聚合发生时,会保留最初的那条数据,新插入的数据对应的那个字段值会被舍弃
-- 新插入的数据: 1 │ tom │ 上海 │ 25 │ 信息部 │ 10000.00
-- 最初的数据 :1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00
-- 聚合合并的结果:1 │ tom │ 上海 │ 25 │ 技术部 │ 30000.00Aggregatingmergetree表引擎
该表引擎继承自MergeTree,可以使用 AggregatingMergeTree 表来做增量数据统计聚合。如果要按一组规则来合并减少行数,则使用 AggregatingMergeTree 是合适的。
AggregatingMergeTree是通过预先定义的聚合函数计算数据并通过二进制的格式存入表内。与SummingMergeTree的区别在于:SummingMergeTree对非主键列进行sum聚合,而AggregatingMergeTree则可以指定各种聚合函数。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = AggregatingMergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]CollapsingMergeTree表引擎
CollapsingMergeTree就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。
每次需要新增数据时,写入一行sign标记为1的数据;需要删除数据时,则写入一行sign标记为-1的数据。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = CollapsingMergeTree(sign)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]注意点
分区合并
分数数据折叠不是实时的,需要后台进行Compaction操作,用户也可以使用手动合并命令,但是效率会很低,一般不推荐在生产环境中使用。
当进行汇总数据操作时,可以通过改变查询方式,来过滤掉被删除的数据
只有相同分区内的数据才有可能被折叠。其实,当我们修改或删除数据时,这些被修改的数据通常是在一个分区内的,所以不会产生影响。
数据写入顺序
值得注意的是:CollapsingMergeTree对于写入数据的顺序有着严格要求,否则导致无法正常折叠。
如果数据的写入程序是单线程执行的,则能够较好地控制写入顺序;如果需要处理的数据量很大,数据的写入程序通常是多线程执行的,那么此时就不能保障数据的写入顺序了。在这种情况下,CollapsingMergeTree的工作机制就会出现问题。但是可以通过VersionedCollapsingMergeTree的表引擎得到解决。
VersionedCollapsingMergeTree表引擎
上面提到CollapsingMergeTree表引擎对于数据写入乱序的情况下,不能够实现数据折叠的效果。VersionedCollapsingMergeTree表引擎的作用与CollapsingMergeTree完全相同,它们的不同之处在于,VersionedCollapsingMergeTree对数据的写入顺序没有要求,在同一个分区内,任意顺序的数据都能够完成折叠操作。
VersionedCollapsingMergeTree使用version列来实现乱序情况下的数据折叠。
建表语法
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = VersionedCollapsingMergeTree(sign, version)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]可以看出:该引擎除了需要指定一个sign标识之外,还需要指定一个UInt8类型的version版本号。
GraphiteMergeTree表引擎
该引擎用来对 Graphite数据进行'瘦身'及汇总。对于想使用CH来存储Graphite数据的开发者来说可能有用。
如果不需要对Graphite数据做汇总,那么可以使用任意的CH表引擎;但若需要,那就采用 GraphiteMergeTree 引擎。它能减少存储空间,同时能提高Graphite数据的查询效率。
Log系列表引擎
应用场景
Log系列表引擎功能相对简单,主要用于快速写入小表(1百万行左右的表),然后全部读出的场景。即一次写入多次查询。
Log系列表引擎的特点
共性特点
数据存储在磁盘上
当写数据时,将数据追加到文件的末尾
不支持并发读写,当向表中写入数据时,针对这张表的查询会被阻塞,直至写入动作结束
不支持索引
不支持原子写:如果某些操作(异常的服务器关闭)中断了写操作,则可能会获得带有损坏数据的表
不支持ALTER操作(这些操作会修改表设置或数据,比如delete、update等等)
区别
TinyLog是Log系列引擎中功能简单、性能较低的引擎。它的存储结构由数据文件和元数据两部分组成。其中,数据文件是按列独立存储的,也就是说每一个列字段都对应一个文件。除此之外,TinyLog不支持并发数据读取。
StripLog支持并发读取数据文件,当读取数据时,ClickHouse会使用多线程进行读取,每个线程处理一个单独的数据块。另外,StripLog将所有列数据存储在同一个文件中,减少了文件的使用数量。
Log支持并发读取数据文件,当读取数据时,ClickHouse会使用多线程进行读取,每个线程处理一个单独的数据块。Log引擎会将每个列数据单独存储在一个独立文件中。
TinyLog表引擎使用
该引擎适用于一次写入,多次读取的场景。对于处理小批数据的中间表可以使用该引擎。值得注意的是,使用大量的小表存储数据,性能会很低。
CREATE TABLE emp_tinylog (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=TinyLog();
INSERT INTO emp_tinylog
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_tinylog
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);进入默认数据存储目录,查看底层数据存储形式,可以看出:TinyLog引擎表每一列都对应的文件
[root@cdh04 emp_tinylog]# pwd
/var/lib/clickhouse/data/default/emp_tinylog
[root@cdh04 emp_tinylog]# ll
总用量 28
-rw-r----- 1 clickhouse clickhouse 56 9月 17 14:33 age.bin
-rw-r----- 1 clickhouse clickhouse 97 9月 17 14:33 depart.bin
-rw-r----- 1 clickhouse clickhouse 60 9月 17 14:33 emp_id.bin
-rw-r----- 1 clickhouse clickhouse 70 9月 17 14:33 name.bin
-rw-r----- 1 clickhouse clickhouse 68 9月 17 14:33 salary.bin
-rw-r----- 1 clickhouse clickhouse 185 9月 17 14:33 sizes.json
-rw-r----- 1 clickhouse clickhouse 80 9月 17 14:33 work_place.bin
## 查看sizes.json数据
## 在sizes.json文件内使用JSON格式记录了每个.bin文件内对应的数据大小的信息
{
"yandex":{
"age%2Ebin":{
"size":"56"
},
"depart%2Ebin":{
"size":"97"
},
"emp_id%2Ebin":{
"size":"60"
},
"name%2Ebin":{
"size":"70"
},
"salary%2Ebin":{
"size":"68"
},
"work_place%2Ebin":{
"size":"80"
}
}
}当我们执行ALTER操作时会报错,说明该表引擎不支持ALTER操作
-- 以下操作会报错:
-- DB::Exception: Mutations are not supported by storage TinyLog.
ALTER TABLE emp_tinylog DELETE WHERE emp_id = 5;
ALTER TABLE emp_tinylog UPDATE age = 30 WHERE emp_id = 4;StripLog表引擎使用
相比TinyLog而言,StripeLog拥有更高的查询性能(拥有.mrk标记文件,支持并行查询),同时其使用了更少的文件描述符(所有数据使用同一个文件保存)。
CREATE TABLE emp_stripelog (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=StripeLog;
-- 插入数据
INSERT INTO emp_stripelog
VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_stripelog
VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
-- 查询数据
-- 由于是分两次插入数据,所以查询时会有两个数据块
cdh04 :) select * from emp_stripelog;
SELECT *
FROM emp_stripelog
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘进入默认数据存储目录,查看底层数据存储形式
[root@cdh04 emp_stripelog]# pwd
/var/lib/clickhouse/data/default/emp_stripelog
[root@cdh04 emp_stripelog]# ll
总用量 12
-rw-r----- 1 clickhouse clickhouse 673 9月 17 15:11 data.bin
-rw-r----- 1 clickhouse clickhouse 281 9月 17 15:11 index.mrk
-rw-r----- 1 clickhouse clickhouse 69 9月 17 15:11 sizes.json可以看出StripeLog表引擎对应的存储结构包括三个文件:
data.bin:数据文件,所有的列字段使用同一个文件保存,它们的数据都会被写入data.bin。
index.mrk:数据标记,保存了数据在data.bin文件中的位置信息(每个插入数据块对应列的offset),利用数据标记能够使用多个线程,以并行的方式读取data.bin内的压缩数据块,从而提升数据查询的性能。
sizes.json:元数据文件,记录了data.bin和index.mrk大小的信息
提示:
StripeLog引擎将所有数据都存储在了一个文件中,对于每次的INSERT操作,ClickHouse会将数据块追加到表文件的末尾
StripeLog引擎同样不支持ALTER UPDATE 和ALTER DELETE 操作
Log表引擎使用
Log引擎表适用于临时数据,一次性写入、测试场景。Log引擎结合了TinyLog表引擎和StripeLog表引擎的长处,是Log系列引擎中性能最高的表引擎。
CREATE TABLE emp_log (
emp_id UInt16 COMMENT '员工id',
name String COMMENT '员工姓名',
work_place String COMMENT '工作地点',
age UInt8 COMMENT '员工年龄',
depart String COMMENT '部门',
salary Decimal32(2) COMMENT '工资'
)ENGINE=Log;
INSERT INTO emp_log VALUES (1,'tom','上海',25,'技术部',20000),(2,'jack','上海',26,'人事部',10000);
INSERT INTO emp_log VALUES (3,'bob','北京',33,'财务部',50000),(4,'tony','杭州',28,'销售事部',50000);
-- 查询数据,
-- 由于是分两次插入数据,所以查询时会有两个数据块
cdh04 :) select * from emp_log;
SELECT *
FROM emp_log
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart─┬───salary─┐
│ 1 │ tom │ 上海 │ 25 │ 技术部 │ 20000.00 │
│ 2 │ jack │ 上海 │ 26 │ 人事部 │ 10000.00 │
└────────┴──────┴────────────┴─────┴────────┴──────────┘
┌─emp_id─┬─name─┬─work_place─┬─age─┬─depart───┬───salary─┐
│ 3 │ bob │ 北京 │ 33 │ 财务部 │ 50000.00 │
│ 4 │ tony │ 杭州 │ 28 │ 销售事部 │ 50000.00 │
└────────┴──────┴────────────┴─────┴──────────┴──────────┘进入默认数据存储目录,查看底层数据存储形式
[root@cdh04 emp_log]# pwd
/var/lib/clickhouse/data/default/emp_log
[root@cdh04 emp_log]# ll
总用量 32
-rw-r----- 1 clickhouse clickhouse 56 9月 17 15:55 age.bin
-rw-r----- 1 clickhouse clickhouse 97 9月 17 15:55 depart.bin
-rw-r----- 1 clickhouse clickhouse 60 9月 17 15:55 emp_id.bin
-rw-r----- 1 clickhouse clickhouse 192 9月 17 15:55 __marks.mrk
-rw-r----- 1 clickhouse clickhouse 70 9月 17 15:55 name.bin
-rw-r----- 1 clickhouse clickhouse 68 9月 17 15:55 salary.bin
-rw-r----- 1 clickhouse clickhouse 216 9月 17 15:55 sizes.json
-rw-r----- 1 clickhouse clickhouse 80 9月 17 15:55 work_place.binLog引擎的存储结构包含三部分:
列.bin:数据文件,数据文件按列单独存储
__marks.mrk:数据标记,统一保存了数据在各个.bin文件中的位置信息。利用数据标记能够使用多个线程,以并行的方式读取。.bin内的压缩数据块,从而提升数据查询的性能。
sizes.json:记录了.bin和__marks.mrk大小的信息
提示:
Log表引擎会将每一列都存在一个文件中,对于每一次的INSERT操作,都会对应一个数据块
外部集成表引擎
ClickHouse提供了许多与外部系统集成的方法,包括一些表引擎。这些表引擎与其他类型的表引擎类似,可以用于将外部数据导入到ClickHouse中,或者在ClickHouse中直接操作外部数据源。
例如直接读取HDFS的文件或者MySQL数据库的表。这些表引擎只负责元数据管理和数据查询,而它们自身通常并不负责数据的写入,数据文件直接由外部系统提供。目前ClickHouse提供了下面的外部集成表引擎:
ODBC:通过指定odbc连接读取数据源
JDBC:通过指定jdbc连接读取数据源;
MySQL:将MySQL作为数据存储,直接查询其数据
HDFS:直接读取HDFS上的特定格式的数据文件;
Kafka:将Kafka数据导入ClickHouse
RabbitMQ:与Kafka类似
HDFS:使用方式
ENGINE = HDFS(URI, format)URI:HDFS文件路径
format:文件格式,比如CSV、JSON、TSV等
MySQL:使用方式
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);注意:对于MySQL表引擎,不支持UPDATE和DELETE操作,比如执行下面命令时,会报错:
-- 执行更新
ALTER TABLE mysql_engine_table UPDATE name = 'hanmeimei' WHERE id = 1;
-- 执行删除
ALTER TABLE mysql_engine_table DELETE WHERE id = 1;
-- 报错
DB::Exception: Mutations are not supported by storage MySQL.JDBC:使用方式
JDBC表引擎不仅可以对接MySQL数据库,还能够与PostgreSQL等数据库。为了实现JDBC连接,ClickHouse使用了clickhouse-jdbc-bridge的查询代理服务。
首先我们需要下载clickhouse-jdbc-bridge,然后按照ClickHouse的github中的步骤进行编译,编译完成之后会有一个clickhouse-jdbc-bridge-1.0.jar的jar文件,除了需要该文件之外,还需要JDBC的驱动文件,本文使用的是MySQL,所以还需要下载MySQL驱动包。将MySQL的驱动包和clickhouse-jdbc-bridge-1.0.jar文件放在了/opt/softwares路径下,执行如下命令:
[root@cdh04 softwares]# java -jar clickhouse-jdbc-bridge-1.0.jar --driver-path . --listen-host cdh04其中--driver-path是MySQL驱动的jar所在的路径,listen-host是代理服务绑定的主机。默认情况下,绑定的端口是:9019。
然后我们再配置/etc/clickhouse-server/config.xml,在文件中添加如下配置,然后重启服务。
cdh04
9019
Kafka:使用方式
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = 'host:port',
kafka_topic_list = 'topic1,topic2,...',
kafka_group_name = 'group_name',
kafka_format = 'data_format'[,]
[kafka_row_delimiter = 'delimiter_symbol',]
[kafka_schema = '',]
[kafka_num_consumers = N,]
[kafka_max_block_size = 0,]
[kafka_skip_broken_messages = N,]
[kafka_commit_every_batch = 0,]
[kafka_thread_per_consumer = 0]kafka_broker_list :逗号分隔的brokers地址 (localhost:9092).
kafka_topic_list :Kafka 主题列表,多个主题用逗号分隔.
kafka_group_name :消费者组.
kafka_format – Message format. 比如JSONEachRow、JSON、CSV等等
注意点
当我们一旦查询完毕之后,ClickHouse会删除表内的数据,其实Kafka表引擎只是一个数据管道,我们可以通过物化视图的方式访问Kafka中的数据。
首先创建一张Kafka表引擎的表,用于从Kafka中读取数据
然后再创建一张普通表引擎的表,比如MergeTree,面向终端用户使用
最后创建物化视图,用于将Kafka引擎表实时同步到终端用户所使用的表中
其他特殊的表引擎
Memory表引擎
Memory表引擎直接将数据保存在内存中,数据既不会被压缩也不会被格式转换。当ClickHouse服务重启的时候,Memory表内的数据会全部丢失。一般在测试时使用。
CREATE TABLE table_memory (
id UInt64,
name String
) ENGINE = Memory();Distributed表引擎
使用方式
Distributed表引擎是分布式表的代名词,它自身不存储任何数据,数据都分散存储在某一个分片上,能够自动路由数据至集群中的各个节点,所以Distributed表引擎需要和其他数据表引擎一起协同工作。
所以,一张分布式表底层会对应多个本地分片数据表,由具体的分片表存储数据,分布式表与分片表是一对多的关系
Distributed表引擎的定义形式如下所示
Distributed(cluster_name, database_name, table_name[, sharding_key])各个参数的含义分别如下:
cluster_name:集群名称,与集群配置中的自定义名称相对应。
database_name:数据库名称
table_name:表名称
sharding_key:可选的,用于分片的key值,在数据写入的过程中,分布式表会依据分片key的规则,将数据分布到各个节点的本地表。
创建分布式表是读时检查的机制,也就是说对创建分布式表和本地表的顺序并没有强制要求。
同样值得注意的是,在上面的语句中使用了ON CLUSTER分布式DDL,这意味着在集群的每个分片节点上,都会创建一张Distributed表,这样便可以从其中任意一端发起对所有分片的读、写请求。
ClickHouse 常见问题
1.重启 ClickHouse 服务的时间会比较长:主要是由于该节点数据分片过多导致加载缓慢,耐心等待即可。
2.数据插入报错 too many parts exception:主要是由于数据插入过于频繁,导致数据分片在后台 merge 缓慢,ClickHouse 启动自我保护机制,拒绝数据继续插入。此时可尝试增大插入数据的 batch_size (10 万) 并降低数据插入的频率(每秒 1 次)以缓解该问题。
3.复制表变为只读:主要是由于 ClickHouse 无法连接 ZooKeeper 集群或 ZooKeeper 上该复制表的元数据丢失导致的,此时新数据无法插入该表。若要解决该问题,首先要检查 ZooKeeper 的连接状况,如果连接失败,则需进一步检查网络状态以及 ZooKeeper 的状态,连接恢复后,复制表就可以继续插入数据了。如果连接正常而元数据丢失,此时可以将复制表转为非复制表然后再进行数据插入操作。
4.执行 JOIN 操作时内存超限:可能是由于 JOIN 前后的两个子查询中没有添加明确的过滤条件导致的,也有可能是由于 JOIN 的数据本身就很大,无法全部加载到内存。此时可以尝试增加过滤条件以减小数据量,或者适当修改配置文件中的内存限制,以装载更多的数据。
ClickHouse 问题排查方法
1.检查 ClickHouse 运行状态,确保服务正常运行。
2.检查 ClickHouse 错误日志文件,寻找问题根源。
3.检查系统日志文件 (/var/log/messages) 中与 ClickHouse 相关的记录,查看是否是系统操作导致 ClickHouse 异常。
4.对于未知问题或 BUG,可以到官方 GitHub 仓库的 issue 下寻求帮助,需提供完整的问题描述和错误日志信息。
直接写入的风险
用户写入 ClickHouse 一般有两种选择:分布式表(i.e. Distributed),MergeTree 表:
写入分布式表:
数据写入分布式表时,它会将数据先放入本地磁盘的缓冲区,再异步分发给所有节点上的 MergeTree 表。如果数据在同步给 MergeTree 里面之前这个节点宕机了,数据就可能会丢失;此时如果在失败后再重试,数据就可能会写重。因而,直接将数据写入用分布式表时,不太好保证数据准确性的和一致性。
当然这个分布式表还有其他问题,一般来说一个 ClickHouse 集群会配置多个 shard,每个 shard 都会建立 MergeTree 表和对应的分布式表。如果直接把数据写入分布式表,数据就可能会分发给每个 shard。假设有 N 个节点,每个节点每秒收到一个 INSERT Query,分发 N 次之后,一共就是每秒生成 NxN 个 part 目录。集群 shard 数越多,分发产生的小文件也会越多,最后会导致你写入到 MergeTree 的 Part 的数会特别多,最后会拖垮整个文件的系统。
写入 MergeTree 表:
直接写入 MergeTree 表可以解决数据分发的问题,但是依然抗不住高频写入,如果业务方写入频次控制不好,仍然有可能导致 ClickHouse 后台合并的速度跟不上写入的速度,最后会使得文件系统压力过大。
所以一段时间内,我们禁止用户用 INSERT Query 把数据直接写入到 ClickHouse。
典型案例-推荐系统

业务需求
随着 ClickHouse 支持的业务范围扩大,我们也决定支持一些实时的业务,第一个典型案例是推荐系统的实时数据指标:在字节跳动内部 AB 实验 应用非常广泛,特别用来验证推荐算法和功能优化的效果。
最初,公司内部专门的 AB 实验平台已经提供了 T+1 的离线实验指标,而推荐系统的算法工程师们希望能更快地观察算法模型、或者某个功能的上线效果,因此需要一份能够实时反馈的数据作为补充。他们大致有如下需求:
1.研发同学有 debug 的需求,他们不仅需要看聚合指标,某些时间还需要查询明细数据。
2.推荐系统产生的数据,维度和指标多达几百列,而且未来可能还会增加。
3.每一条数据都命中了若干个实验,使用 Array 存储,需要高效地按实验 ID 过滤数据。
4.需要支持一些机器学习和统计相关的指标计算(比如 AUC)。

当时公司也有维护其他的分析型引擎,比如 Druid 和 ES。ES 不适合大批量数据的查询,Druid 则不满足明细数据查询的需求。而 ClickHouse 则刚好适合这个场景。
1.对于明细数据这个需求:ClickHouse > Druid。
2.对于维度、指标多的问题,可能经常变动,我们可以用 Map 列的功能,很方便支持动态变更的维度和指标。
3.按实验 ID 过滤的需求,则可以用 Bloom filter 索引。
4.AUC 之前则已经实现过。
这些需求我们当时刚好都能满足。
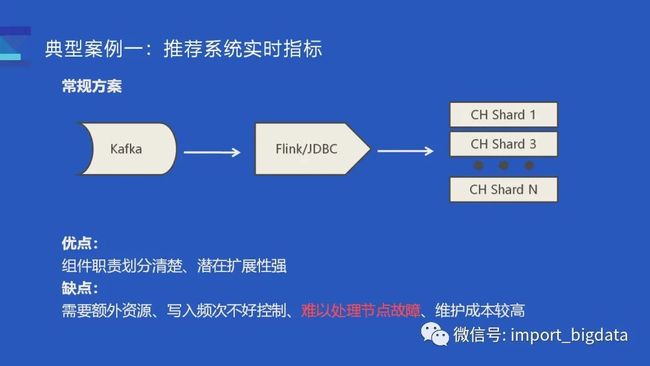
方案设计和比较
常规方案:比较常规的思路,是用 Flink 消费 Kafka,然后通过 JDBC 写入 ClickHouse。
优点: 各个组件职责划分清楚、潜在扩展性强
缺点: 需要额外资源、写入频次不好控制、难以处理节点故障、维护成本较高
关键是后面两点:由于缺少事务的支持,实时导入数据时难以处理节点故障;ClickHouse 组技术栈以 C++为主,维护 Flink 潜在的成本比较高。
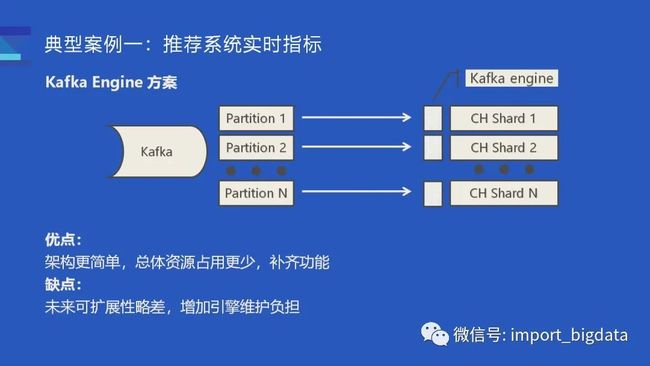
Kafka Engine 方案
第二个方案,则是使用 ClickHouse 内置的 Kafka Engine。我们可以在 ClickHouse 服务内部建一张引擎类型为 Kafka 的表,该表会内置一个消费线程,它会直接请求 Kafka 服务,直接将 Kafka partition 的数据拉过来,然后解析并完成数据构建。对于一个 ClickHouse 集群而言,可以在每个节点上都建一张 Kafka 表,在每个节点内部启动一个消费者,这些消费者会分配到若干个 Kafka Partition,然后将数据直接消费到对应。
这样的架构相对于使用了 Flink 的方案来说更简单一些,由于少了一次数据传输,整体而言开销会相对小一些,对我们来说也算是补齐了 ClickHouse 的一部分功能(比如 Druid 也支持直接消费 Kafka topic)缺点就是未来可扩展性会更差一些,也略微增加了引擎维护负担。
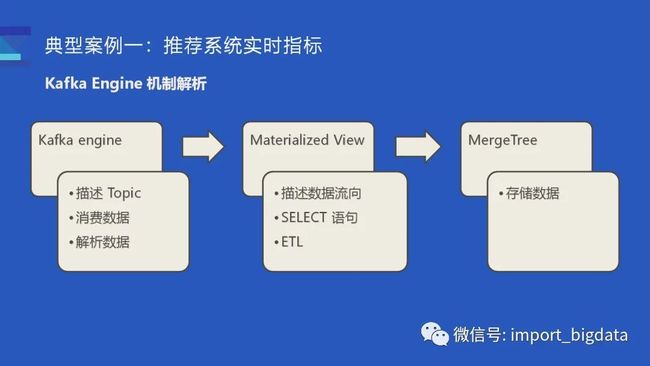
Kafka engine 原理
这里简单介绍一下如何使用 kafka 引擎,为了能让 ClickHouse 消费 Kafka 数据,我们需要三张表:首先需要一张存数据的表也就是 MergeTree;然后需要一张 Kafka 表,它负责描述 Topic、消费数据和解析数据;最后需要一个物化视图去把两张表关联起来,它也描述了数据的流向,某些时候我们可以里面内置一个 SELECT 语句去完成一些 ETL 的工作。只有当三张表凑齐的时候我们才会真正启动一个消费任务。

这是一个简单的例子:最后呈现的效果,就是通过表和 SQL 的形式,描述了一个 kafka -> ClickHouse 的任务。

最终效果
由于外部写入并不可控、技术栈上的原因,我们最终采用了 Kafka Engine 的方案,也就是 ClickHouse 内置消费者去消费 Kafka。整体的架构如图:
1.数据由推荐系统直接产生,写入 Kafka。这里推荐系统做了相应配合,修改 Kafka Topic 的消息格式适配 ClickHouse 表的 schema。
2.敏捷 BI 平台也适配了一下实时的场景,可以支持交互式的查询分析。
3.如果实时数据有问题,也可以从 Hive 把数据导入至 ClickHouse 中,不过这种情况不多。除此之外,业务方还会将 1%抽样的离线数据导入过来做一些简单验证,1%抽样的数据一般会保存更久的时间。

我们在支持推荐系统的实时数据时遇到过不少问题,其中最大的问题随着推荐系统产生的数据量越来越大,单个节点的消费能力也要求越来越大:
改进一:异步构建索引
第一做的改进是将辅助索引的构建异步化了:在社区实现中,构建一个 Part 分为三步:(1)解析输入数据生成内存中数据结构的 Block;(2)然后切分 Block,并按照表的 schema 构建 columns 数据文件;(3) 最后扫描根据 skip index schema 去构建 skip index 文件。三个步骤完成之后才会算 Part 文件构建完毕。
目前字节内部的 ClickHouse 并没有使用社区版本的 skip index,不过也有类似的辅助索引(e.g. Bloom Filter Index, Bitmap Index)。构建 part 的前两步和社区一致,我们构建完 columns 数据之后用户即可正常查询,不过此时的 part 不能启用索引。此时,再将刚构建好数据的 part 放入到一个异步索引构建队列中,由后台线程构建索引文件。这个改进虽然整体的性能开销没有变化,但是由于隐藏了索引构建的时间开销,整体的写入吞吐量大概能提升 20%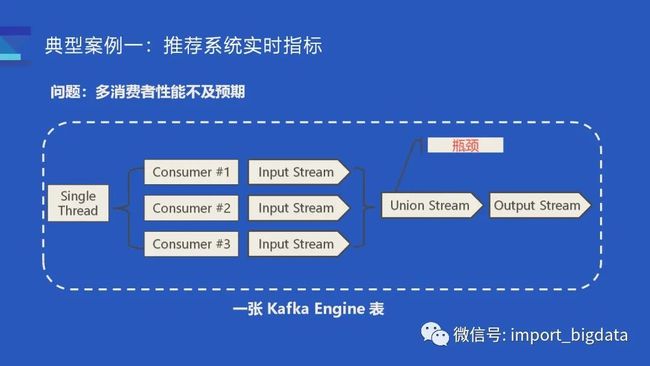
改进二:支持多线程消费
第二个改进是在 Kafka 表内部支持了多线程的消费:
目前实现的 Kafka 表,内部默认只会有一个消费者,这样会比较浪费资源并且性能达不到性能要求。一开始我们可以通过增大消费者的个数来增大消费能力,但社区的实现一开始是由一个线程去管理多个的消费者,多个的消费者各自解析输入数据并生成的 Input Stream 之后,会由一个 Union Stream 将多个 Input Stream 组合起来。这里的 Union Stream 会有潜在的性能瓶颈,多个消费者消费到的数据最后仅能由一个输出线程完成数据构建,所以这里没能完全利用上多线程和磁盘的潜力。

一开始的解决方法,是建了多张 Kafka Table 和 Materialized View 写入同一张表,这样就有点近似于多个 INSERT Query 写入了同一个 MergeTree 表。当然这样运维起来会比较麻烦,最后我们决定通过改造 Kafka Engine 在其内部支持多个消费线程,简单来说就是每一个线程它持有一个消费者,然后每一个消费者负责各自的数据解析、数据写入,这样的话就相当于一张表内部同时执行多个的 INSERT Query,最后的性能也接近于线性的提升。

改进三:增强容错处理
对于一个配置了主备节点的集群,我们一般来说只会写入一个主备其中一个节点。
为什么呢?因为一旦节点故障,会带来一系列不好处理的问题。(1)首先当出现故障节点的时候,一般会替换一个新的节点上来,新替换的节点为了恢复数据,同步会占用非常大的网络和磁盘 IO,这种情况,如果原来主备有两个消费者就剩一个,此时消费性能会下降很大(超过一倍),这对于我们来说是不太能接受的。(2)早先 ClickHouse Kafka engine 对 Kafka partition 的动态分配支持不算好,很有可能触发重复消费,同时也无法支持数据分片。因此我们默认使用静态分配,而静态分配不太方便主备节点同时消费。(3)最重要的一点,ClickHouse 通过分布式表查询 ReplicatedMergeTree 时,会基于 log delay 来计算 Query 到底要路由到哪个节点。一旦在主备同时摄入数据的情况下替换了某个节点,往往会导致查询结果不准。

这里简单解释一下查询不准的场景。一开始我们有两副本,Replica #1 某时刻出现故障,于是替换了一个新的节点上来,新节点会开始同步数据,白框部分是已经同步过的,虚线黄框是正在恢复的数据,新写入的白色框部分就是新写入的数据。如果此时两个机器的数据同步压力比较大或查询压力比较大,就会出现 Replica #1 新写入的数据没有及时同步到 Replica #2 ,也就是这个绿框部分,大量历史数据也没有及时同步到对应的黄框部分,这个情况下两个副本都是缺少数据的。因此无论是查 Replica #1 还是 Replica #2 得到的数据都是不准的。

对于替换节点导致查询不准问题,我们先尝试解决只有一个节点消费的问题。为了避免两个节点消费这个数据,改进版的 Kafka engine 参考了 ReplicatedMergeTree 基于 ZooKeeper 的选主逻辑。对于每一对副本的一对消费者,(如上图 A1 A2),它们会尝试在 ZooKeeper 上完成选主逻辑,只有选举称为主节点的消费者才能消费,另一个节点则会处于一个待机状态。一旦 Replica #1 宕机,(如上图 B1 B2 ),B1 已经宕机连不上 ZooKeeper 了,那 B2 会执行选主逻辑拿到 Leader 的角色,从而接替 B1 去消费数据。

当有了前面的单节点消费机制,就可以解决查询的问题了。假设 Replica #1 是一个刚换上来的节点,它需要同步黄框部分的数据,这时候消费者会与 ReplicatedMergeTree 做一个联动,它会检测其对应的 ReplicatedMergeTree 表数据是否完整,如果数据不完整则代表不能正常服务,此时消费者会主动出让 Leader,让副本节点上的消费者也就是 Replica #2 上的 C2 去消费数据。
也就是说,我们新写入的数据并不会写入到缺少数据的节点,对于查询而言,由于查询路由机制的原因也不会把 Query 路由到缺少数据的节点上,所以一直能查询到最新的数据。这个机制设计其实和分布式表的查询写入是类似的,但由于分布表性能和稳定原因不好在线上使用,所以我们用这个方式解决了数据完整性的问题。
小结一下上面说的主备只有一个节点消费的问题
配置两副本情况下的 Kafka engine,主备仅有一个节点消费,另一个节点待机。
如果有故障节点,则自动切换到正常节点消费;
如果有新替换的节点无法正常服务,也切换到另一个节点;
如果不同机房,则由离 Kafka 更近的节点消费,减少带宽消耗;
否则,由类似 ReplicatedMergeTree 的 ZooKeeper Leader 决定。
典型案例-广告投放实时数据

业务背景
第二个典型案例是关于广告的投放数据,一般是运营同学需要查看广告投放的实时效果。由于业务的特点,当天产生的数据往往会涉及到多天的数据。这套系统原来基于 Druid + Superset 实现的,Druid 在这个场景会有一些难点:
难点一:产生的实时数据由于涉及到较多的时间分区,对于 Druid 来说可能会产生很多 segment,如果写入今天之前的数据它需要执行一些MR的任务去把数据合并在一起,然后才能查历史的数据,这个情况下可能会导致今天之前的数据查询并不及时。
难点二:业务数据的维度也非常多,这种场景下使用 Druid 预聚合的效率并不高。
对比 Druid 和 ClickHouse 的特点和性能后,我们决定将该系统迁移到 ClickHouse + 自研敏捷 BI。最后由于维度比较多,并没有采用预聚合的方式,而是直接消费明细数据。
因为业务产生的数据由 (1) 大量的当天数据和 (2) 少量的历史数据 组成。历史数据一般涉及在 3 个月内,3 个月外的可以过滤掉,但是即便是 3 个月内的数据,在按天分区的情况下,也会因为单批次生成的 parts 太多导致写入性能有一定下降。所以我们一开始是把消费的 block_size 调的非常大,当然这样也有缺点,虽然整个数据吞吐量会变大,但是由于数据落盘之前是没法查到数据的,会导致整体延时更大。

改进一:Buffer Engine 增强
单次写入生成过多 parts 的问题其实也有方案解决。社区提供了 Buffer Engine,可以在内存中缓存新写入的数据,从而缓解 parts 高频生成的问题。不过社区文档也介绍了,Buffer Engine 的缺点是不太能配合 ReplicatedMergeTree 一起工作。如果数据写入到了一对副本(如上图),那么 Buffer #1 和 Buffer #2 缓存的数据其实是不一样的,两个 Buffer 仅缓存了各自节点上新写入的数据。对于某个查询而言,如果查询路由到 Replica #1,那查询到的数据是 MergeTree 部分的数据加上 Buffer #1,这部分的数据其实是和 Replica #2 的 MergeTree 加上 Buffer2 的数据并不等价,即便 MergeTree 的数据是相同的。

针对社区版 Buffer Table 存在的问题,我们也做了相应改进。
(1) 我们选择将 Kafka/Buffer/MergeTree 三张表结合起来,提供的接口更加易用;
(2) 把 Buffer 内置到 Kafka engine 内部, 作为 Kafka engine 的选项可以开启/关闭;
(3) 最重要的是支持了 ReplicatedMergeTree 情况下的查询;
(4) Buffer table 内部类似 pipeline 模式处理多个 Block。
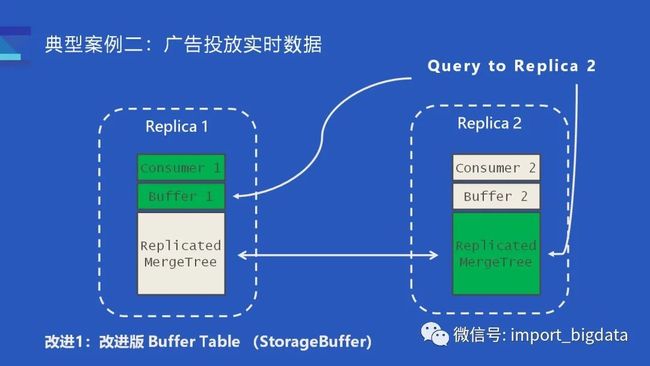
这里解释一下我们如何解决查询一致性的问题。前面提到,目前一对副本仅有一个节点在消费,所以一对副本的两个 Buffer 表,只有一个节点有数据。比如 Consumer #1 在消费时,Buffer #1 就是有缓存数据,而 Buffer #2 则是空的。
对于任何发送到 Replica #1 的查询,数据肯定是完整的;而对于发送到 Replica #2 的查询则会额外构建一个特殊的查询逻辑,从另一个副本的 Buffer #1 读取数据。这样发送到 Replica #2 的查询,获取到数据就是绿框部分也就是 Replica #2 的 MergeTree 再加上 Replica #1 的 Buffer,它的执行效果是等价于发送到 Replica #1 的查询。
改进二:消费稳定性增强
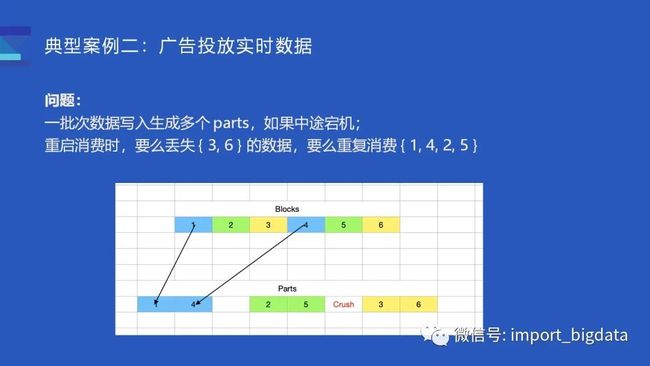
由于业务数据的分区比较分散,某个批次的写入往往生成多个 parts。以上图为例,如果某个批次消费到 6 条数据,假设可以分为 3 个 part(比如涉及到昨天、今天、大前天三天数据),第一条和第四条写入到第一个 part,第二第五条数据写入到第二个 part,这时候服务宕机了,没有及时写入第三第六条数据。
由于 ClickHouse 没有事务的支持,所以重启服务后再消费时,要么会丢失数据 {3, 6},要么会重复消费 {1, 4, 2, 5}。对于这个问题我们参考了 Druid 的 KIS 方案自己管理 Kafka Offset, 实现单批次消费/写入的原子语义:实现上选择将 Offset 和 Parts 数据绑定在一起,增强了消费的稳定性。

每次消费时,会默认创建一个事务,由事务负责把 Part 数据和 Offset 一同写入磁盘中:如果消费的途中写入 part #1 part #2 失败了,事务回滚的时候会把 Offset 和 part #1 part #2 一并回滚,然后从 Part #1 的位置重新消费并重试提交 offset 1-3。
性能奥秘
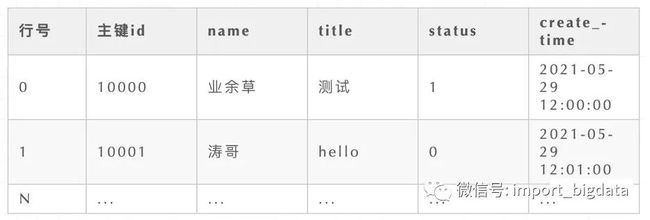
如上述表格所示,传统的 MySQL 数据库的每一行数据都是物理的存储在一起的。如果我要取 id 等于 10000 这一条数据的 name 列,那我就必须要把这一行数据读取出来,然后取 name 列。
再比如,下面的 SQL:

在众多的数据中,我只取一列,但我需要把每条数据都读取出来。
基于上面传统数据库的一些特点,ClickHouse 另辟蹊径,推出了列式存储。

看上图的列式存储示例,完全和 MySQL 等数据库不同。当我执行下面的 SQL 时,查询效率非常的高!

由于 name 列的数据都存储在一起,因此效率大大的超过了传统的数据库。
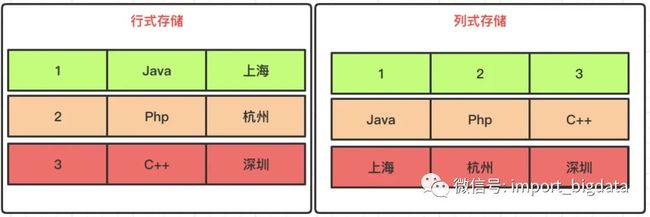
除了逻辑上的不同,磁盘上的组织结构也大不一样。

除了列式存储上的不同,ClickHouse 还有高效的数据压缩,默认使用LZ4算法,总体压缩比可达 8:1。ClickHouse 还采用了分布式多主架构提高并发性能,ClickHouse使读请求可以随机打到任意节点,均衡读压力,写请求也无需转发到master节点,不会产生单点压力。
ClickHouse 还有向量引擎,利用 SIMD 指令实现并行计算。对多个数据块来说,一次 SIMD 指令会同时操作多个块,大大减少了命令执行次数,缩短了计算时间。向量引擎在结合多核后会将 ClickHouse 的性能淋漓尽致的发挥出来。
ClickHouse 在索引上也有不同,采用了稀疏索引及跳数索引。同时还有很多 MergeTree,提供海量业务场景支持。
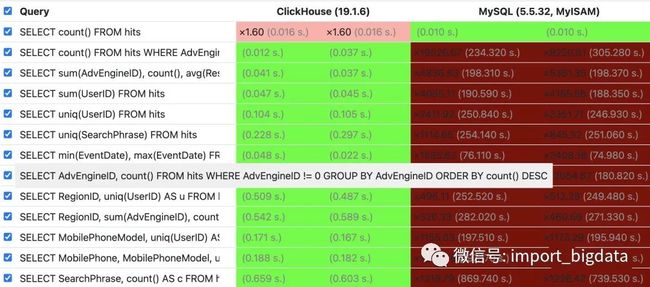
基于以上特点,ClickHouse 在包含 count、sum、group by、order by 等情况的查询对比,同等条件下,ClickHouse 的查询性能异常强悍,官网上的数据显示,是同等条件下 MySQL 的 831 倍。


我整理的学习资料

识别下方二维码,回复“资料合集”,即可获得下载地址。感觉干货多,记得设为星标哦


历史精彩文章
1、原创|实时数仓实战项目-第一节
2、原创|实时数仓实战项目-第二节(数仓分层)
3、原创|实时数仓实战项目-第三节(数仓治理)
4、附PPT|2021年总结实时数仓最新架构图
5、原创|渣渣二本,喝下这杯逆袭鸡汤,看完年薪不到70万,算我输!!!
6、实时数仓实战项目-第四节(命名规范和分层设计)
7、Flink 在伴鱼的实践:如何保障数据的准确性
8、干货|ClickHouse源码阅读计划--理论&工具的准备