GC标记-清除算法

GC标记-清楚算法
- 面试官:什么是GC标记-清除算法?
- 我:就是由标记阶段和清除阶段组成的垃圾回收算法。
- 面试官:然后呢?
- 我: 我已经说完了啊。
- 面试官:下一位。
- 我: 我说错了吗?
- 面试官:你没有说错,但说的太少了。你能说说,标记的是啥?清除的是啥?
- 我:标记的是活动的对象,清除的是非活动的对象,也就是垃圾?
- 面试官:保安,你进来一下。把这个人拖出去。
- 我:先别拖,我会写伪代码。(摸摸的从自己包里拿出了纸和笔)。
伪代码
- 我:我写好了,你看。(把纸递给了面试官)
mark_sweep() {
mark_phase()
sweep_phase()
}
- 面试官:这也太简单了吧?
- 我:你别急,我先画一张图给你。
执行GC前堆的状态

- 我:这里的椭圆表示GC roots. 灰色的表示对象。这个对象是特指虚拟机里面的对象。
- 面试官:虚拟机的对象是啥?
- 我:你看,从概念上看,虚拟机里面的对象有两部分组成:对象头(Header)和域(Fields)。对象头就像是一列地铁的车头(假设地铁是单向的)。
里面存放了对象的类型,对象的大小,和GC运行相关的信息。域才是对象里面使用者真正能够访问的地方。既然是标记算法,就要在对象头里面搞一个
标记用于记录对象的状态。你看,下面的矩形表示堆,堆里面第一个对象没有被GC roots引用,所以是死去的对象,第二个对象有被GC roots引用,是活的对象。
而第三个对象不被GC root引用,是死了的对象。 - 面试官:你逗我吧?你说第三个对象是死了的对象?没有被GC roots引用的对象就不能活?
- 我: 我没有逗你,第三个对象是死对象,不仅仅是因为他没有被GC root引用,还因为它没有在引用链(reference chain)上。引用链就是指自己没有被GC roots引用,但引用自己的对象有直接或间接被GC roots引用。而第三个对象虽然引用了第二个对象,但它本身没有在引用链上,就没有被程序所使用,把它当垃圾回收了,也不影响程序正常运行,就是死亡的对象。
- 面试官:哦,哦,哦。你说的对。
- 我: 第四个对象有被GC root引用。同时他的对象域里面有两个指针,分别指向第五个和第六个对象,这个叫引用链(reference chained). 我管它叫裙带关系,一人得到,鸡犬升天那种。第六个对象没有升天,所以死了。
- 面试官:听着是那么回事,就是感觉有怪味儿。
- 我:我没有工作,有味正常,你看我给你写个伪代码。
标记阶段伪代码
for(r : $roots) {
mark(*r)
}
- 我:你看这个 $roots 表示所有的GC roots对象。擒贼先擒王,挽弓当挽强。我先找到所有GC roots 引用的对象。把他们都标记为存活状态。
- 面试官:那mark(*r)的伪代码,你能写一下么?
mark(obj) {
if (obj.mark == FALSE) {
obj.mark == TRUE
for (child : children(obj)) {
mark(*child)
}
}
}
- 我:第二行,检查作为实参传递的obj是否已被标记,如果已经被标记了,证明已经被处理过了,我就不再处理了。这个情况叫做循环引用,你想象一下, 第五个对象假如也是根对象的话,如果不加判断,是不是要被重复处理。所以加判断是为了避免重复进行标记。
- 面试官:那这个mark就是你说的标志位了?
- 我:是的,你看第三行。GC就像一个阎王一样,拿着一个大笔守候在奈何桥边,手里拿着GC-roots账本,能来的都已经是有后台有关系的GC-roots对象了。他就拿大笔一挥,在人家脑门子上画一个NIKE标记(Object header)。这还不算。还要盘查一下它有没有引用其他对象,凡是有关系的,一个一个的拎出来在脑门子上打钩。然后继续株连九族,说错了,是活连N族。
- 面试官:啥玩意儿?NIKE标记?
- 我:哦,就是一个对象头里面的标志位,用于记录对象是否存活。来来来,我给你看看他们的大脑儿门上的NIKE。

- 我:我再给你画个标记完后的图。

- 面试官:嗯,有那个内味儿了,你能算算花费的时间吗?
- 我: 我们聊了大半个小时了吧。
- 面试官:我是问如何计算标记所有活动对象,花费的时间。
- 我: 这个花费的时间嘛,当然是看活动对象的多少了,如果活动对象多,阎王爷标记花的时间就多,用数学的术语形容叫成正比例。而且阎王爷GC眼力劲儿不好,标记的时候要那些对象停止活动, 人间一秒,地府一年呀,他也没办法呀,担心这些对象在被标记的时候耐不住寂寞,发生对象找对象,对象甩对象,或者对象生对象之类乱七八糟的,又人之常情的事情,谁活着不是为了找对象,谈恋爱,生孩子呀?虽然不至于整个地府(堆:heap)都这样乱七八糟的,但只要是它清点的那一片区域,就要强制要求对象停止活动的。 时间久了,对象们都憋不住了,那个闹腾啊,控制不住就直接憋死了,还让不让人爽了?阎王爷也是个爱琢磨的人,它发现找GC roots上的对象很快,搞“活连N族”,根据引用链找到所有间接引用的对象,就有点费时间,也在慢慢琢磨改进,这是后话。
- 面试官:你只说了阎王爷(GC)标记Roots对象,你能在聊聊上面“活连N族”的过程吗?也就是你说的标记对象生存状态的详细过程?
- 我: 这个嘛,据说阎王爷 GC 的时候,用到了深度优先搜索(depth-first search)和广度优先(breadth-first search)搜索。说什么深度优先比广度优先更能压低内存使用量。我没有品出来这个味。你帮我看看呢?
深度优先搜索(depth-first search)
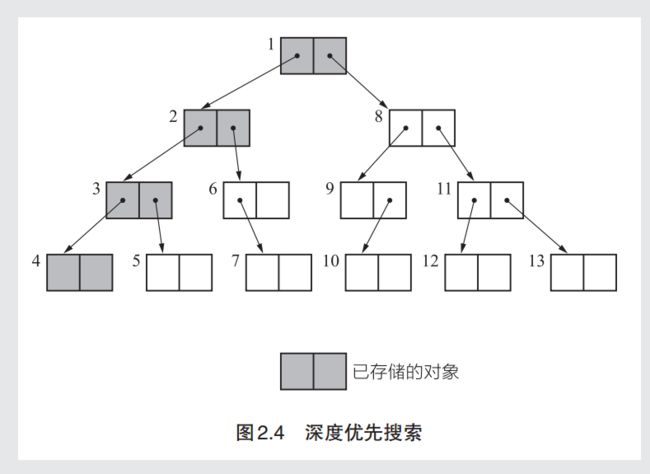
- 我:感觉深度优先就是在遍历引用关系链表的时候,一杆子插到底,如果标记一个GC root的对象,就顺藤摸瓜把这个对应引用的一串对象全找出来,再处理顶上与他同级的兄弟对象,在兄弟对象的引用关系上又一杆子插到底。
广度优先搜索(breadth-first search)

- 我:而广度优先,我没有看懂。还想和上面的代码不符,管他的,至少我知道标记阶段经常用到的是深度优先搜索。
清除阶段
- 面试官:那你在聊聊清除阶段吗?
- 我:清除阶段结合垃圾收集器有关了(collector), collector 会遍历整个堆,回收没有打上标记的对象,释放它们占用的空间。
- 面试官:怎么个清除法?
- 我:我给你比划比划下伪代码。
清除阶段伪代码
执行合并的sweep_phase()函数
sweep_phase() {
sweeping = $heap_start
while(sweeping < $heap_end) {
if(sweeping.mark == TRUE) {
sweeping.mark = FALSE
} else {
// 你细品这两句代码
sweeping.next = $free_list
$free_list = sweeping
}
sweeping += sweeping.size
}
}
- 我: 这里的sweeping.size. 表示一个存储对象大小,也就是对象占用字节数的域。他和mark域一样,也是需要事先在各对象头里面定义的。我这里用变量sweeping获取堆的开始地址( h e a p s t a r t ) 引 用 的 对 象 , 遍 历 完 堆 中 的 所 有 对 象 , 直 到 超 出 堆 的 结 束 地 址 ( heap_start)引用的对象, 遍历完堆中的所有对象,直到超出堆的结束地址( heapstart)引用的对象,遍历完堆中的所有对象,直到超出堆的结束地址(heap_end)。对于每个对象,如果脑门上有个NIKE标记(对象头的mark域值为true)。恭喜这个对象,它活下来了,赶紧把脑门上的NIKE标记擦掉,表示是存活下来的对象。如果脑门上没有NIKE标记,我会先搞一个空闲指针。
- 面试官:啥空闲指针?
- 我:哦,我还是放一张图吧,不然编不下去了。

- 我:请看图,堆中第一个对象是死去的对象。空闲链表在图中,就是一个指针,他初始状态下指向了第一个死去的对象的起始地址。当它遍历到第三个死去的对象的时候。
sweeping.next = $free_list这句代码。你品一下,$free_list就是第一个死去对象的起始地址。你可以想想一下,空闲链表就是一个菜市场卖肉的那种大铁钩,不过阎王爷人家用的是琵琶钩,带铁链那种,还记得新白娘子传奇里,许仙在端午节被白娘子变成蛇精吓死了那集吗?许仙的魂被黑白无常抓取了,用的就是带铁链的琵琶钩,这个琵琶钩有个好处,可以把死去的对象一个一个串起来,谁也别想跑,又方便,比用把每个人都看到,只要看好端头的那个就好了。阎王爷先用琵琶钩住第一个死去对象起始地址,当他发现第二个死去对象的时候,会再拿出一个琵琶钩(指针),直接挂进第二个死去对象肩膀那块的肉里面(这里指代死去对象的域)。用另外一头挂到空闲链表挂的那个位置,也就是上一个死去对象的位置,经过这么一链接呀,就把新发现死去的对象和空闲链表上一次发现的死去对象连上了。然后再把指向上一个死去对象的琵琶钩,挂到新发现的死去对象的肩膀上,这样一来,就连上了。 - 面试官:太血腥了,你直接挂到人家肉里面。这样不好吧?也就是说,你直接在死对象域里面临时硬占了一个域(Field)存储指针,不好吧?之前不是说,域是程序访问的地方吗?也就是存储数据的地方吗?会不会破坏对象存储的信息。
- 我:没事,死都都死了,还操心个啥,反正在GC标记-清除法里面,死了的对象都活不了,你看菜市场卖的猪肉,上面挂个洞。也不影响销售呀。这样做主要是为了节省空间。不然还得在对象头上面开一个区域,太占空间了,划不来。
- 面试官:有道理。
- 我:后面的回收,你注意观察一下清除阶段处理完后,空闲链表的引用,他指向了最后一个死亡对象的头,最后一个死亡对象的域里面,又有一个指针指向了第三个对象的头,第三个对象的头,又指向了第一对象的头。像不像阴曹地府里面黑白无常抓到的一串鬼啊?
- 面试官:大白天的,你别说啥鬼呀鬼的,把老子整得提心吊胆的。说正事,你这就释放完啦?感觉怪怪的?
- 我:嗯,是有点怪怪的。你看,一块好好的内存,之前还热热闹闹的,搞得现在稀稀疏疏的了。剩下的区域,有的大,有的小,而且还不连续。用专业的说法就是:内存碎片太多了,如果想分配一个大一点的对象,根据对象的size在这些零散的对象里面找,不一定就能找到合适的,如果大点,还可以切分,如果都小了,就麻烦了,即使空闲内存总数足够大,但是因为被切分成的块都小于给定的对象大小,不扩容就要报内存溢出了。
- 面试官:虽然看上去稀稀疏疏的,但还好,人家没有另外搞一块内存区域。对了,你再说说分配吧。
- 我:我先撒泡尿,回来我们再继续面吧。
- 面试官:等等我,我们一起去。
厕所里面响起了一起嘘嘘的流水声,面试官和我隔着一个槽位各自嘘嘘,他们都把头看到墙,不敢斜视旁边的对方,以免尴尬。
分配
- 面试官:好了,我们继续吧。
- 我:我们聊到哪儿了?
- 面试官:内存分配。
- 我:哦,内存分配这事情归 mutator 管,这里的分配,特指将回收的垃圾进行再利用。还记得那一串儿死对象么。就是那个空闲链表。
- 面试官:记得,那玩意儿就是一个又一个死去的对象“手拉手“。
- 我: 哈哈哈哈,对,你说得太对了,就是那玩意儿,哪些死去的对象有的大,有的小,而且还必须挨个去访问。分配对象的时候,可麻烦了。
- 面试官:咋了?怎么个麻烦法?
- 我:别慌,你看我这里有小抄。
- 面试官:小抄?
- 我:哦,不不不,是笔记,笔记, 伪代码笔记。
new_obj()函数
new_obj(size) {
chunk = pickup_chunk(size, $free_list)
if (chunk != NULL) {
return chunk
} else {
allocation_fail()
}
}
- 面试官:你这个小抄上面的 chunk 是啥玩意儿啊?
- 我:chunk 特指为了分配对象而找的一块内存区域。这个 new_obj(size) 方法,就是创建对象用的。会根据传入的对象大小,调用
pickup_chunk(size, $free_list)方法,
在空闲链表里面,也就是那堆死去的对象里面,找一个一样 size 的对象。 - 面试官:一样size?
- 我:对,就是指一样大的对象,或者指存放对象的存储空间 size 一样大。
我盲猜这个大小是不包括对象头的。只是对象可访问域的大小。没有拷证过,假设他是对的。 - 面试官:感觉这个方法有点问题呀?
- 我:是有问题,我也是没有办法, 本来就是个回收再利用的过程,我只能挨个去找大小一样的。找到了还好,直接返回,如果找不到,就只能调用 allocation_fail() 方法, 报告分配失败了。
- 面试官:能往细了说说 pickup_chunk(size, $free_list) 到底干了写啥不?
- 我:你大爷的,我刚才不是说了吗,pickup_chunk 函数就是用于遍历 $free_list,寻找等于size 的分块。
- 面试官:你大爷的! 你确定是只寻找等于size的分块(chunk)? 难道就不能奢侈点,返回一个大一点的分块。
- 我: 能是能,但严格意义上还是不能,内存分配不能像我们平时写代码那样,大点小点无所谓。一服务程序,存活的实例对象上千上万,要是在分配的时候你多一点儿,我多一点儿,累积起来浪费的可就更多啦。所以即使返回来大于原来的块。也要根据要使用的大小进行精确切割,分成和 size 大小相同的块和去掉size后剩余大小的分块。并把剩余的分块返回空闲链表。
- 面试官:慢着,你说了精确切割成size大小的块。那你刚才是不是说错了,这个size不仅仅包括对象能访问的域,也包括它的头,不然分配的空间不够存储呀。
- 我:你说的有道理,可能我说错了,留着后面拷证吧。
- 面试官:感觉你还没有把 pickup_chunk(size, $free_list) 给说透。
- 我:我嘴巴都说干了,衣服都湿透了,你说我没有说透。你倒是来给我说个透。
- 面试官:你别激动,我是想说,在寻找分块的时候,可以采取哪些策略。
- 我:哦,好吧。这个要看负责分配内存的人(allocator)勤快不勤快了,如果他想偷懒,不想再分配上浪费过多的时间,在挨个找的过程中,只要找到一个死对象,它的大小大于等于给定的对象。就直接返回这个死对象曾经使用过的区块(chunk)。有人把这个方式叫 First-fit。就是返回发现的第一个大于等于size的分块。
- 面试官:还有其它策略吗?
- 我:有,有,有。如果 allocator 人勤快,本份,或者说有点强迫症。就会遍历完空闲链表,找出那一个大于等于size的最小分块,返回回去。这种方式叫 Best-fit,就是找到最好的意思。
- 面试官:这两种比较,哪个好一点呢?
- 我:如果只使用单存的空闲链表,当然是时间快的好啦,也就是Fist-fit。
- 面试官:还有其他方式没?
- 我:还有一个,叫 Worst-fit. 就是找出空闲链表中最大的分块,将其分割成 mutator 申请大小的块和分割后剩余的大小。目的是将分割后剩余的分块最大化,但因为Worst-fit很容易生成大量小的分块,所以不推荐。
- 面试官:在我看,Worst-fit很容易生成大量小的分块,Best-fit 和 First-fit 也存在切分。所以也会产生小的分块。小的分块随着时间的推移,感觉也是个隐患。
- 我: 嗯,是的,如果空闲链表里面的分块越来越小,越来越多,稍微大一点的对象,就找不到分块了。所以,需要一个合并分块的过程。
- 面试官:能不能聊一下合并分块的过程?
- 我:你等等,我找找我的小抄。
合并
- 我:你看,不同的分配策略,会产生大量小的分块,但如果他们是连续的,我们就能把所有连续挨在一起的小分块,合成一个大分块。这种“连接连续分块”的操作,就叫做合并(coalescing)
- 面试官:听起来有点意思,那他在什么时候进行呢?
- 我:在清除阶段, 这两行代码有点难懂,看下图,假设此时空闲链表指向第一个死对象,sweeping已经指向了第二个对象,发现它是死的。
他只要通过sweeping = $free_list + $free_list.size确定:上一个死亡对象加上自己的大小,得出的地址刚好是第二个死亡对象的起始地址。就证明了这两个死亡对象是连续的,就可以进行合并操作,而合并操作超级简单,只需要把第二个死亡对象占用的空间大小累加到第一个死亡对象上。然后忘了有第二个死亡对象这回事儿,不在第二个死亡对象上进行任何指针操作。就可以了。 - 面试官:我的乖乖,原来内存管理,是通过指针实现的。
sweep_phase() {
sweeping = $heap_start
while(sweeping < $heap_end) {
if(sweeping.mark == TRUE) {
sweeping.mark = FALSE
} else {
if (sweeping == $free_list + $free_list.size) {
$free_lize.size += sweeing.size
} else {
sweeping.next = $free_list
$free_list = sweeping
}
}
sweeping += sweeping.size
}
}

优点
- 面试官:那GC标记-清除算法,有哪些优点吗?
- 我:小抄上说的算法简单,实现容易。我觉得打脑壳。还可以拿这个算法和其他算法组合。根据不同的情况选择不同的收集算法。但是当我看了部分-标记算法,才知道这个要好理解太多了。
- 面试官:先不提那个 “部分-标记算法”, 继续说说 GC标记清除算法 还有什么优点?
- 我:注意观察,阎王爷(GC)不管是在标记阶段,还是在移动阶段,并没有移动存活的对象,更没有把这个对象从一个地方复制到另外一个地方。不移动,就不需要另外找一块堆区域去存放它,太划算了,这也算是他的优点。换句话说,只要在复制过程中,满足对象不移动的算法,就叫做保守式算法,而保守式算法,和其他场景的 GC复制算法,标记-压缩算法,是不兼容的。因为GC标记-清除算法不会移动对象,就非常适合搭配保守式GC算法。
缺点
- 面试官:那GC标记-清除算法,有哪些缺点吗?
- 我:碎片化(fragmentation), 因为整个算法过程中都不移动对象,而且为了内存不浪费,请求多少size的对象,就会根据找到的chunk切割,产生新的分块。用得越久,细化的碎片就越多,虽然有合并,但是只能合并连续的碎片,万一碎片和碎片之间正好有活动的对象,就没法在不移动对象的前提下,跨过活动的对象合并两个间隔的分块了。碎片多了,即使这些碎片合起来的空间足够大,也不能给size大的对象分配。导致堆溢出了。并且,碎片越多,mutator的执行负担就越重。很可出现
瞎忙活,白忙活的情况。 - 面试官:有什么解决方法不?
- 我:有,可以压缩整理,以及BiBOP法。这个是另外的话题了,先不聊。
- 面试官:还有啥缺点?
- 我: 还有一个缺点,也是因为碎片化导致的分配速度问题。
- 面试官:有什么解决方法不?
- 我:有倒是有,分配速度慢,很大的原因在于空闲链表的查询。要根据给定的大小去遍历查找,而把大小不同的空闲 chunk 放到一个链表里面,就像把一堆大小不同的苹果放在同一个杯状容器里面。找起来确实麻烦。可以通过 多个空闲链表(multiple free-list) 对 chunk 按大小不同进行分类。当然,BiBOP方法也可以提高速度。
- 面试官:还有啥缺点不?
- 我:与 写时复制技术(copy-on-write) 不兼容。
- 面试官:啥?写时复制技术(copy-on-write)?
- 我:嗯,写时复制技术,是在Linux等Unix系统上使用的技术。假设现在有一个进程,它有自己的内存空间,可以读取到对应的数据。在Linux中复制进程时,会使用 fork() 函数,而这里有个问题,有没有必要把该进程所使用的所有空间都复制一份。想象一下,如果我都复制,当然能满足要求,但是会增加时间开销和内存开销,如果我只复制这个进程里面的必要的信息,大部分的内存空间,fork出来的进程和原进程都使用同一个地址。
- 面试官:那写咋办?这样搞实际上是将内存空间共享了,如果用fork出来的进程进行写,岂不是把原来进程关联的对象也改了,串味了!
- 我:嗯,是串味了。不过也有解决的办法。就是不允许访问共享的空间。在重写时,要复制自己的私有空间,堆私有空间进行重写。换句话说,fork出来的进程在执行写的时候,必然导致空间的复制。而GC标记-清除法,需要标记对象存活状态标志位,就导致了不应该发生的复制。占用了内存空间,
让可以使用的内存空间减少了。 - 面试官: 咋办?这么好的算法,不用怪可惜的?
- 我:也简单,用位图标记(bitmap marking)算法, 换个地方记录对象存活状态,就避免写操作了。
- 面试官:你看,中午十二点了,要不先去吃个饭?我们回来再详细说说你说的多个空闲链表,BiBOP法和位图标记法。
- 我:嗯,我先去买罐红牛提提神儿。
多个空闲链表法
- 面试官:好了,继续聊聊多个空闲链表吧
- 我:我还累,等下一个空闲时间再聊吧。
- 面试官:振作点,再挤挤,我想把你榨干,请开始你的表演。
- 我:之前聊了单个空闲链表,在单个空闲链表中,对大的分块和小的分块进行了同样的处理,这增加了分配时查找固定大小空闲块的难度。如果我多弄几个空闲链表,把这些空闲链表的头指针存放到一个组数里面,数组的不同下标,对应的值存放着对应的空闲链表,而每个空闲链表上,都是相同大小的空闲块,那分配的时候岂不是爽歪歪?直接拿来用就好了,不用再找了。找什么找呀。大家同一个大小,用谁不是用呢?
- 面试官:把你小抄上面的图给我看看。
- 我:你咋知道我小抄上面有?
- 面试官:我知道你从哪里抄的呀。
- 我:(汗颜!!!)
只利用一个空闲链表的情况

利用多个空闲链表的情况
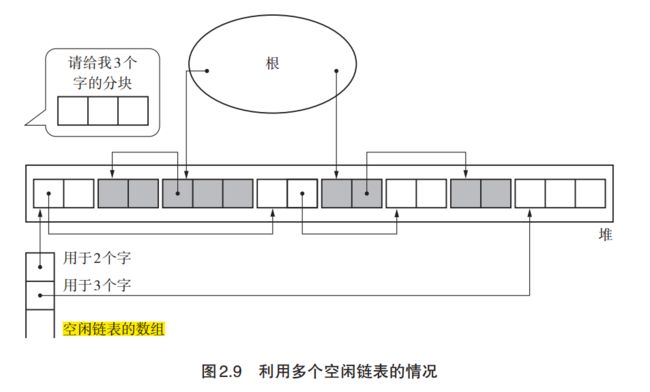
- 面试官:那到底要用多大的数组存这些空闲链表的头地址呢?也就是说,到底制造多少个空闲链表才合适?既然对象的大小是正整数,而没有最大的正整数,岂不是要搞一个很大的数组。和更多的指针?
- 我:你说的是理论上的可能性,在现实中,一般情况下,mutator 很少会申请非常大的分块。为了应对这种极少出现的情况而大量制造空闲链表,会占用过多的内存空间。
- 面试官:那怎么办?
- 我:给分块大小设定一个上限被,如果超了,就全部采用一个空闲链表处理。
- 面试官:使用多个空闲链表,你上面的代码不对,是不是要改一下?
- 我:哦,是的,需要修改 new_obj() 函数和 sweep_phase()函数。你看:
利用多个空闲链表的new_obj()函数
new_obj(size) {
// WORD_LENGTH表示字长,在不同的机器上有不同的值。
index = size / (WORD_LENGTH / BYTE_LENGTH)
// 小于100的块
if(index <= 100) {
//如果数组对应的位置有空闲链表
if($free_list[index] != NULL) {
// 直接获取对应空闲链表的第一个分块chunk
chunk = $free_list[index]
// 空闲链表第一个死对象的next指针指向下一个死对象,把它赋值给空闲链表头,以让第二个死对象称为链表的第一个死对象,而第一个死对象完成移除操作
$free_list[index] = $free_list[index].next
// 返回找到的chunk
return chunk
}
} else {
// 大于100的情况,当做同一种情况处理。尝试获取分块
chunk = pickup_chunk(size, $free_list[101])
if(chunk != NULL) {
return chunk
}
}
allocation_fail()
}
利用多个空闲链表的sweep_phase()函数
sweep_phase() {
// 每次清除,都把上一次保留的空闲链表清空。
for(i : 2..101) {
$free_list[i] = NULL
}
// 获取堆的起始地址
sweeping = $heap_start
// 一直遍历完整个堆
while(sweeping < $heap_end) {
// 如果是存活的对象
if(sweeping.mark == TRUE) {
// 重置标志
sweeping.mark = FALSE
} else {
// 已经死亡的对象,获取它占用的内存大小,以(WORD_LEGNTH/BYTE_LENGTH)为单位
index = size / (WORD_LENGTH / BYTE_LENGTH)
// 小于100的情况
if (index <= 100) {
// 要回收的 sweeping 对象的next指针,指向空闲链表里存储的上一个死对象。
sweeping.next = $free_list[index]
// 把空闲链表的头指针,指向这个新回收的对象。
$free_list[index] = sweeping
} else {
// 大于100的情况,把回收对象的next指针,指向特殊处理的空闲链表里面的第一个对象。
sweeping.next = $free_list[101]
// 把忒书处理的空闲链表头指针,指向新回收的sweeping对象。
$free_list[101] = sweeping
}
}
// 将 sweeping 的地址累加 回收对象sweeping的大小,以指向下一个对象。
sweeping += sweeping.size
}
}
BiBOP法(Big Bag Of Pages)
- 面试官:那BiBOP法有是什么意思?
- 我: BiBOP 是 Big Bag Of Pages 的缩写。
- 面试官:啥玩意?
- 我: 将大小相近的对象整理成固定大小的块进行管理的做法
- 面试官:还是没懂。
- 我: 就是先把堆分割成固定大小的块,让每个块只能配置同样大小的对象。它和多个空闲链表法的思想是一样的,多个空闲链表法,是用多个空闲链表,每个空闲链表存放同样大小的对象。这样对象通过链表串在了一起,可以想象成逻辑上是在一起了。而 BiBOP,像是提前给对划分了固定大小的区域。每个区域只能配置同样大小的对象。
- 面试官:你上个图吧。
- 我:我找找。
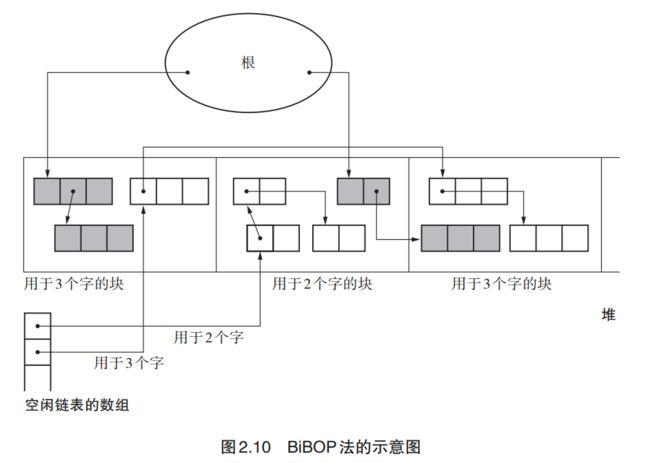
- 面试官:这样倒腾为啥呢?
- 我:提高内存的使用率,因为每个块中只能配置同样大小的对象,所以不可能出现大小不均的分块。
- 面试官:他能完全消除碎片吗?
- 我:不能,比如说分成的块全部用于2个字的块中,只有一两个活动对象。其他的字块空着,这种情况下,就不能算是有效利用了堆。这个情况下, 更像是扩大了堆中内存块的最小存储单位,但由于分块的存在,本来连续的对象,离散的分到不同块去了。造成在多个块分散残留着同样大小的对象。反而会降低堆的使用率。
位图标记法(Bitmap Table)
- 面试官:对了,你有提到过位图标记法?
- 我:嗯,就是换了个地方标记。GC在死亡对象的头节点上打标记,必然会写内存。而这在Linux和Unix类的系统使用的写复制技术不兼容,导致内存压迫。那就换一个地方记录死亡的对象吧。把阎王爷(GC)在死亡对象脑门上打钩的方式,换成阎王爷拿一个小本本记录的方式。比如阎王爷(GC)要对这块堆里面对象进行回收了,他就搞一个位图表格(bitmap table).用这个位图表格来记录哪些对象死亡了。
- 面试官:别给我整哪些乌七八糟的,忍你很久了,好好说话不行么?
- 我:哦,那我对比一下吧,在单存的GC标记-清除算法中,用于标记的位是分配到各个对象的头中的。算法是把对象和头一并处理了,这导致跟写复制技术不兼容。
- 面试官:那到底什么是位图标记法?你倒是给个清晰的说法。
- 我:位图标记,就是只收集各个对象的标志并表格化,不跟对象一起管理。在标记的时候,不在对象的头里置位,而是在表格中的特定场所置位。
- 面试官:那个表格是啥?是相亲的时候填的表格么?
- 我:不是相亲登记表格,是位图表格(bitmap table). 位是标记为的意思,利用这个表格进行标记的行为称为“位图标记”。
- 面试官:还是没听明白,你到底说说他和相亲表格有啥不同?(面试官摸了摸头上剩余的几撮头发,又按了按脸上的青春痘,想起了自己单身很久了)。
- 我:位图表格的实现方式有多种,例如散列表格,树形结构,为了简单,我用整数型数组比划比划吧。
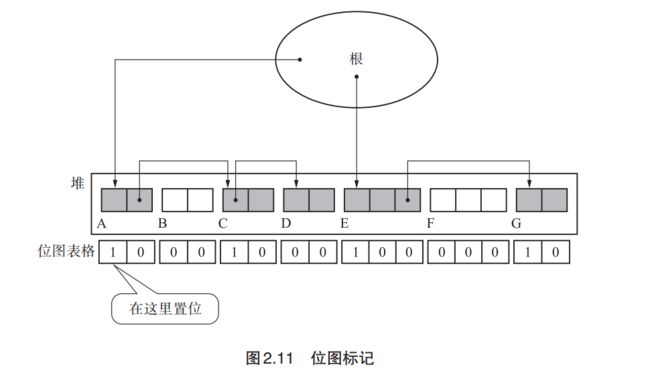
- 我:你看这个图,位图表格中的位置要和堆里的各对象切实对应。比如第一个对象是活的,第一个格子就是1,第3个对象因为被引用,也是活的,起始地址在第5个格子。所以位图表格的第5位就设置为1.
- 面试官:那到底如何标记呢?
- 我:你看,这个就是位图标记中的mark()函数
位图标记中的mark()函数
mark(obj) {
// 那对象的起始地址,减去堆的起始地址,再除以字长,得到对象占用的字长
// 这里WORD_LENGTH表示各机器中1个字的位宽(比如32位机器的WORD_LENGTH就是32)
// obj_num 指的是从位图表格前面数起,obj的标志位在第几个。比如这里图2.11 中E的位置是9(从左往右).
obj_num = (obj - $heap_start) / WORD_LENGTH
// 得到行号
index = obj_num / WORD_LENGTH
// 得到偏移量作为列号
offset = obj_num % WORD_LENGTH
// 如果位图中对应的位置没有标记
if (($bitmap_table[index] & (1 << offset)) == 0) {
//用或运算,将对应的位置设为1
$bitmap_tbl[index] |= (1 << offset)
// 遍历对象,标记该对象引用的子对象
for(child : chidren(obj)) {
mark(*child)
}
}
}
- 我:我把要说的话,都写到注释里面了,再给张小抄图。
- 面试官:我好像明白你的意思了。

- 面试官:你整这么多门门道道儿,那位图标记法有什么优点吗?
- 我:最大的优点就是,与写时复制技术兼容。不会发生没必要的复制了。
- 面试官:虽然对象不会复制了,但是要对位图表格进行重写,这里还是会发生复制呀。
- 我:虽然会复制,但是位图表格非常小,所以即使被复制也不会有什么大的影响。
- 面试官:没有听明白
- 我:这个好比你想啃10个兔儿脑壳,之前是买10个兔子,会花很多钱。还有个方法就是,去专门卖兔儿脑壳的地方,只要花一只兔子的钱,就能买到10个兔儿脑壳了。
- 面试官:聊技术就聊技术,别把我口水整出来啦。它还有什么优点?
- 我:清除操作更加高效了,以往的清除操作都必须遍历整个堆,把非活动对象链接到空闲链表,同时取消活动对象的标志位。现在有了位图表格,把所有对象的标志位集合到了一处,所以可以快速消去标志位了。
- 面试官:怎么个快法?
- 我:哈哈哈,就你最会来事儿,我给你看看我的无敌小抄。
sweep_phase() {
// 堆开始的地址
sweeping = $heap_start
index = 0
offset = 0
// 遍历整个堆
while (sweeping < $heap_end) {
// 用index找到对应的行,用偏移量和与运算判断对应的位是否为 0,为 0 表示该对象已经死了。
if($bitmap_tbl[index] & (1 << offset) == 0) {
// 将此对象链接到空闲链表
// 对象已经死了,把发现的死对象的next指向链表头里面上一个死对象
sweeping.next = $free_list
// 在把链表的头指针指向新发现的死对象
$free_list = sweeping
}
// 累加行索引
index += (offset + sweeping.size) / WORD_LENGTH
// 累加偏移量索引
offset = (offset + sweeping.size) % WORD_LENGTH
// 为了遍历堆,移到下一个对象地址
sweeping += sweeping.size
}
// 已经把所有死对象都链接到空闲链表里面了,不需要位图表格里面的标志位了,遍历清空就好了。
for (i : 0..(HEAP_SIZE / WORD_LENGTH - 1)) {
$bitmap_tbl[i] = 0
}
}
- 面试官:看来位图标记法,只是在GC标记-清楚法里面,搞了一个位图,用来临时记录标记。
- 我:嗯,辅助记录一下,占空间少,清除快。
- 面试官:那有什么需要注意的地方吗?
- 我:需要注意对象地址和位图表格的对应。
- 面试官:如果有多个堆,并且对象地址不连续呢?
- 我:如果有多个堆,每个堆的地址不连续,就无法用单存的位运算求出标志位的位置了。
- 面试官:现实世界的虚拟机可能不止一个堆哦。
- 我:一个不够,我就给每个堆都准备一个位图表格,不就可以啦。
延迟清除法
- 面试官:对了,你之前说,清除操作所花费的时间,与堆大小成正比。
- 我:嗯,处理的堆越大,GC标记 - 清除算法所花费的事件就越长,结果就妨碍到mutator的处理了。
- 面试官:mutator是啥?
- 我:我也不知道,是提出这个算法的人搞出来的玄乎乎的词,意味改动者,在JVM里面复制分配内存的家伙。
- 面试官:这个不好办呀,假如用户跑的程序是自动驾驶系统,你突然给停了一会儿,岂不是要车毁人亡?而且GC标记-清除算法,就是为了减少最大停顿时间的。
- 我:可以用**延迟清除算法(Lazy Sweep)**缩减因清除操作而导致的 mutator 最大暂停时间。
- 面试官:能详细说说吗?
- 我:就是标记操作结束后,不一并进行清除操作,而是让它“延迟”一会,通过“延迟”来防止 mutator 长时间暂停。
- 面试官:说得云里雾里的,你到底在说啥?
- 我:我给你比划比划
new_obj()函数
new_obj(size) {
// 在分配时,直接调用 lazy_sweep()函数进行清除操作
chunk = lazy_sweep(size)
// 如果能找到chunk,直接返回
if (chunk != NULL) {
return chunk
}
// 如果不能分配分块,就执行标记操作
mark_phase()
// 再调用 lasz_sweep() 函数来分配分块
chunk = lazy_sweep(size)
// 如果拿到了,就返回
if (chunk != NULL) {
return chunk
}
// 没有拿到,意味着堆上没有分块,mutalor 不能再进行下一步处理了。
allocation_fail()
}
- 面试官;这个 lay_sweep() 函数,看上去好神秘。
- 我:先看看伪代码吧
lazy_sweep(size)函数
lazy_sweep(size) {
// 一直遍历堆
while($sweeping < $heap_end) {
// 活的对象把标志位复原
if($sweeping.mark == TRUE) {
$sweeping.mark = FALSE
} else if ($sweeping.szie >= size) { //找到了大于等于所申请大小的分块
// 记录找到的分块
chunk = $sweeping
// 把遍历指针跳过找到的分块大小,以指向下一个对象的起始地址
$sweeping += $sweeping.size
// 返回所找到的分块
return chunk
}
// 没有找到,将sweeping指向下一个对象
$sweeping += $sweeping.size
}
// 复原sweeping,指向堆首地址
$sweeping = $heap_start
// 返回空
return NULL
}
- 面试官:你说说呗
- 我:这里最关键的是全局变量
$sweeping。 可以把他想想成一条听话的猎狗。标记过程就相当于猎人啪啪啪用猎枪一顿猛轰,搞死了一片对象。在分配的时候,你告诉 allocator, 找一个大小为2的分块。听话的猎狗(allocator)在空闲链表上一个一个往下找,如果找到了,就返回找到的分块。同时,他会待在所找到死对象的下一个死对象的首地址。等你再一次分配内存空间的时候,请注意,你没有进行标记操作,而是继续利用上一次标记操作的结果。猎狗(allocator)继续往前走,如果找到一个大于等于size的分块,good lucky. 省了一次标记过程。如果没有找到,让猎狗回到堆的起始位置。并返回为NULL。 - 面试官:这么看来,延迟清除法不是一下遍历整个堆
- 我:嗯,它只在分配时执行必要的遍历。所以可以压缩因清除操作儿导致的 mutator 的暂停事件,这就是 “延迟” 清除操作的意思。
有了延迟清除法就够了吗
- 面试官:延迟清除法有什么缺点?
- 我:最大的缺点就是清除的效果不均衡。

- 我:你看,活动的对象变成了活动对象堆,死的对象变成了垃圾堆。它们形成了一种邻接的状态。
- 面试官:有什么问题么?
- 我:如果在清除较多的部分时,能马上或得分块,所以能减少用户程序(mutator)的暂停事件。
- 面试官:这不是优点吗?我问题的是缺点
- 我:然而一旦程序开始清除活动对象周围,就会郁闷的,都是活的对象,怎么也找不到死的对象,也就无法获得分块,这就增加了 mutator 暂停的时间。
- 面试官:这种情况很少吧?
- 我:但是清理时间一会长,一会短的,就像神经刀一样,好的时候牛逼,发生的时候,只能MMP了。
- 面试官:还有什么办法可以提升?
- 我:(我看了看时间,居然面了这么久了…)。我不想面了。
- 面试官:为啥?
- 我:心累呀,面试造火箭。
- 面试官:我这还有其它问题没有问呢。请问 mysql的索引是怎么实现的?spring mvc 是啥? redis用过没?消息队列用过没?
- 我:啥???我不知道。算了,不面了,我拿回自己的简历,拖着疲惫的身体走了出去。
- 面试官: (默默的在写下面试反馈:会点技术,就是骚味太重了。)
本故事纯属虚构,故事里面的知识点全属瞎扯蛋,请勿当真。