InnoDB的Buffer Pool
前置概念:一个数据页16KB,一个数据页可能有多个记录,即使我们只需要访问一条记录,需要把整个数据页加载到内存中,加载到内存后不是直接释放,而是缓存到内存当中(当然对于buffer pool的缓存是在存储引擎层的发生在优化器之后,而mysql的查询缓存和buffer pool不是一个东西,查询缓存发生在最开始的时候)。
buffer pool的概念
提出buffer pool是为了缓存磁盘中的页,在mysql服务器启动的时候就向操作系统申请一片连续的内存,这一片的内存就是buffer pool,也就缓冲池。
默认情况下 buffer pooll只有128M大小,我们可以在启动服务器的时候配置innodb_buffer_pool_size参数的值。
buffer pool内部组成
buffer pool中的缓存页大小和磁盘中数据页相同16KB。
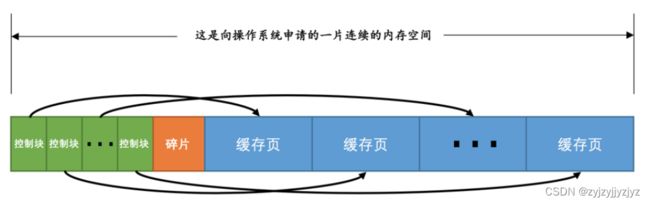
1)每个缓存页对应一个控制块,控制块是什么呢,描述缓存页的表空间编号,页号,存储也在buffer pool中的地址,一些所信息等。
2)每个缓存页对应的控制信息占用的内存大小是相同的。在mysql5.7中控制块占用808字节。
3)控制块和缓存页都存放到buffer pool中,控制块放在buffer pool的前边,缓存也放在buffer pool的后面。
free链表和flush链表
1、free链表
首先mysql服务器初始化,向操作系统申请一段连续的内存空间,然后把他划分成若干对控制块和缓存页,此刻缓存页都还没有用到。随着程序的运行会不断地有磁盘的页 被缓存到buffer pool中,那么往哪个缓存页中放呢?换句话说mysql是怎么知道哪个缓存页是空闲的呢?
链表!在存储数据的磁盘中,也就是文件系统的表空间中,管理数据页、区都是用的链表。
管理缓存页也是用链表,两个链表,一个是free链表,一个是flush链表。
顾名思义free链表中全是空闲的缓存页。另外我们呢要注意一点链表管理的是控制块,也就是说控制块作为一个节点放到链表中,控制块管理缓存页。

注意:基节点占用的不是buffer pool而是单独申请的一块内存空间。
流程:当需要从磁盘加载一个页到buffer pool中就从free链表中去一个空闲的缓存页,并且把该缓存也的控制块信息天上。之后把缓存页对应的控制块的free链表节点从链表中移除表示该缓存页已经使用了。
缓存页的哈希处理
前面说了,当我们要访问某个也的数据时,就会把该页从磁盘加载到 buffer pool,如果该页已经在buffer pool中的话就直接使用就可以了。那mysql怎么知道该页在不在buffer pool中呢?难道是遍历一遍链表,no遍历太慢。
hasn结构,我们是根据表空间号+页号定位一个页的。相当于表空间号+页号是一个key,缓存页就是对应的value。
2、flush链表
当修改了某个缓存页中的数据,那他就和磁盘的数据页不一致了,这时候的缓存页就叫脏页。
如果每一次有脏页产生就立刻同步到磁盘上对应的页上,那性能非常低。所以我们呢不着急立刻修改同步磁盘上。而是存起来,到未来的某个时间点进行同步。这个管理脏页的数据结构还是链表,flush链表中放的就是被修改的脏页。
LRU链表的管理
众所周知,buffer pool对应的内存大小是有限的,可定会满,满了就清,那怎么进行清理呢?
我们要留存的数据,必定是热点数据,或者说必须缓存命中率必须越高越好。
参考微信聊天列表,排在前面的都是频繁使用到的。排在后面的都是很久不联系的。用什么样的数据结构来维护这个“微信列表”链表呢?LRU链表
简单LRU链表介绍
最近最少使用的原则去淘汰缓存页。当我们需要访问某个页的时候,LRU链表发生了这个情况:
1)如果该页不在buffer pool,在把该页从磁盘加载到buffer pool中的缓存页时,就把该缓存页对应的控制块作为节点塞到LRU链表的头部。
2)如果该页已经在buffer pool中,直接把控制块移动到头部。
划分区域的LRU链表
上面介绍的简单LRU链表mysql并没有应用,而是使用的划分区域的LRU链表。
为什么不使用简单的LRU链表呢?简单的LRU链表有什么问题呢?两种情况不适用。
情况一:预读(还没用使用到就从磁盘读到buffer pool)
线性预读
如果顺序访问某个区的页面超过了innodb_read_ahead_threshold(默认为56,一个区64个页,超过54就预读下一个区的全部页面)系统变量的值,就会触发一次异步读取下一个区中全部的页面到buffer pool的请求。
随机预读
如果buffer pool已经缓存了某个区的13个连续的页面,不论这些页是否时顺序读取的,都会出发一次一部读取本区全部页面的buffer pool请求。
预读的问题
预读的页面放到了链表的头部,有很多页面可能会用不到 ,降低了缓存命中率。
情况二:全表扫描
很好理解,全表扫描会大量读取页面,但是全表扫描发生的概率不大,所以简单LRU缓存的页没有大用,降低了缓存命中率。
总结
上面的两种情况反映出了两个问题:
1)加载到buffer pool的页不一定被用到
2)用的少的页面把热点页面挤掉。
划分LRU链表的结构
为了解决这两种情况,InnoDB把LRU量表分为两段,分别是热数据段和冷数据段。

注意:InnoDB时按照某个比例将LRU链表分为两半的,也就是说随着程序运行,某个节点的区域会发生变化。
复杂LRU链表的优化
针对预读的优化
其实并没有对预读进行优化,只是InnoDB规定当磁盘上的某个页面初次加载到buffer pool中的某个缓存页时,该缓存页对应的控制块会被放到old区域的头部,如果后续不进行访问,就会从old区域逐出。从而不会影响到young区域中的缓存页。
针对全表扫描的优化
在mysql中规定每次区页面中读取一条记录时,都算时访问一次页面,而一个页面可能 会包含很多条记录,也就是说读取完某个页面的记录就像当于访问这个页面好多次。这样按理来说young区域会被挤出很多热点数据。
InnoDB为了解决上面的问题是这么规定的:在对某个在old区域的缓存页进行第一次访问的时候就在他对应的控制块中记录下这个访问时间,如果后续的访问时间于第一次的访问时间在某个时间间隔内,就那么该页面就不会被从old区域移动到young区域的头部,否则就会被移动到young区域的头部。
复杂LRU链表的进一步优化
这次优化时针对young区域的缓存页进行优化的。
young区域有一个问题,因为被经常访问,那么他会经常移动到头节点,这样的开销太大了。
针对这个问题进行优化:
只有被访问的缓存页位于young区域的1/4后面,才会被移动到LRU链表头部,这样能降低调整LRU链表的牝鹿,从而提升性能。换句话说,某个缓存页对应的节点在young区域的1/4中,访问也不会移动到LRU链表头部。
刷新脏页到磁盘
后台有专门的线程每隔一段时间就会把脏页刷新到磁盘,这样就可以不影响用户线程处理正常的请求。两种刷新方法:
从LRU的冷数据中刷新一部分页面到磁盘。
后台线程会定时从LRU链表尾部开始扫描页面,发现脏页就会刷新到磁盘。
从flush链表中刷新一部分页面到磁盘
后台线程也会定时从flush链表中刷新一部分页面到磁盘。刷新的速率取决于当时系统是不是很繁忙。
思考:
有两个线程,后台线程和用户线程。用户线程在准备加载一个磁盘也到buffer pool时没有可用的缓存页,这时候就会从LRU链表尾部直接释放掉为修改的页面,如果没有未修改的页面,就不得不将LRU链表尾部的一个脏页同步刷新到磁盘。
总结
1)InnoDB想操作系统申请一段连续的内存空间作为缓存
2)innodb_buffer_pool_size参数可以调整buffer pool的大小
3)buffer pool有两个部分,控制块和缓存页。每个控制块和缓存页都是一一对应的。
4)innodb使用了使用链表来管理buffer pool。free链表、frush链表、LRU链表。
5)链表中的节点都是控制块。
6)为了快速定位某个也是否被加载到buffer pool,使用了hash算法,使用空间号+页号作为key,缓存页作为value,建立hash表。
7)在buffer pool中修改的页面叫脏页,脏页不是立刻刷新到磁盘,而是加入到flush列表中,之后某一时刻同步刷新到磁盘
8)LRU链表分为young和old两个区域,首次加载到buffer pool的页会被放到old区域的头部,在某个时间间隔内访问该页不会移动到young区域头部,在没有可用的缓存页的时候首先会淘汰掉old区域的一些页,如果是脏页会刷新到磁盘再淘汰。