【数据分析】matplotlib、numpy、pandas速通
教程链接:【python教程】数据分析——numpy、pandas、matplotlib
资料:https://github.com/TheisTrue/DataAnalysis
1 matplotlib
官网链接:可查询各种图的使用及代码
对比常用统计图
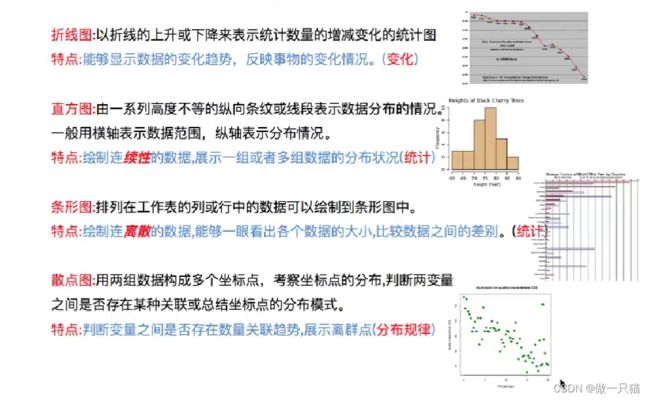
1.1 折线图
(1)引入
from matplotlib import pyplot as plt
(2) 示例
x = range(2, 26, 2) # 2到25,步长2
y = [15, 13, 14.5, 17, 20, 25, 26, 26, 24, 22, 18, 15]
(3) 设置图片大小
figsize: 图片的 (长, 宽)
dpi: 每英寸像素点的个数,例如选定为 80 (图像模糊时可传入dpi参数使图片年更清晰)
fig = plt.figure(figsize = (20, 8), dpi = 80)
(4) 绘图
plt.plot(x, y)
# plt.plot(x, y, label="day01") # 和后续plt.legend()一起使用
# 这里可添加参数改变图形的样式
(5) 设置刻度
注: 这里绘图和设置刻度的先后顺序影响不大
① 常规
plt.xticks(x)
② range范围
plt.xticks(range(2,25))
③ 增加步长
range无法设置步长,采用列表生成式 [expression for item in iterable if condition]
expression 表示新列表中的元素表达式,item 是迭代器 iterable 中的每个元素,condition 是要应用的筛选条件(可选)
xtick_labels = [i/2 for i in range(4, 49)]
plt.xticks(xtick_labels[::3]) # 在xtick_labels的基础上再设置3的步长(注:这里步长以0.5为准,因为前面是i/2)
xtick_labels = ["hour{}".format(i) for i in range(1,13)]
#plt.xticks() 第一个参数是 x 轴上的位置列表,第二个参数是标签列表
plt.xticks(x,xtick_labels) # 若x为字符串型,则要转换为range(len(x))
plt.yticks(range(min(y1), max(y1)+1))
(6) 添加描述信息
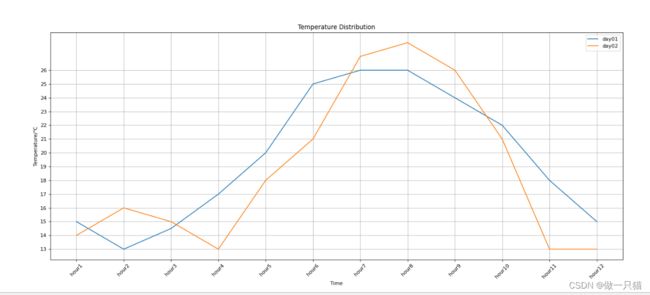
plt.xlabel("Time") # 设置 x 轴标签
plt.ylabel("Temperature/℃") # 设置 y 轴标签
plt.title("Temperature Distribution") # 设置标题
(7) 绘制网格
plt.grid()
(6)保存
可保存为 svg 矢量图格式,则在缩放过程中不会有锯齿
plt.savefig("./sig_size.png")
(7)展示
plt.show()
补充1 占位符
str.format() 占位符{}
name = "Alice"
age = 25
print("My name is {}, and I am {} years old.".format(name, age))
# 输出:My name is Alice, and I am 25 years old.
注: 这里省略了一个例子,例子包含处理中文显示,可到原视频中学习
补充2 设置中文
plt.rcParams['font.family'] = ['sans-serif'] # 设置默认字体为sans-serif
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置sans-serif采用SimHei,SimHei 是一种常用的中文字体
汇总
# 1 引入
import matplotlib
from matplotlib import pyplot as plt
matplotlib.rc
# 2 示例
x = range(2, 26, 2) # 2到25,步长2
y1 = [15, 13, 14.5, 17, 20, 25, 26, 26, 24, 22, 18, 15] # day01
y2 = [14, 16, 15, 13, 18, 21, 27, 28, 26, 21, 13, 13] # day02
# 3 设置图片大小
# figsize:图片的 (长, 宽)
# dpi:每英寸像素点的个数,例如选定为 80 (图像模糊时可传入dpi参数使图片年更清晰)
fig = plt.figure(figsize = (20, 8), dpi = 80)
# 4 绘图
plt.plot(x, y1, label="day01")
plt.plot(x, y2, label="day02")
# 5 设置刻度
# 注:这里绘图和设置刻度的先后顺序影响不大
#plt.xticks(x)
#plt.xticks(range(2,25))
# range无法设置步长,采用列表生成式 [expression for item in iterable if condition]
# expression 表示新列表中的元素表达式,item 是迭代器 iterable 中的每个元素,condition 是要应用的筛选条件(可选)
#xtick_labels = [i/2 for i in range(4, 49)]
#plt.xticks(xtick_labels[::3]) # 在xtick_labels的基础上再设置3的步长(注:这里步长以0.5为准,因为前面是i/2)
xtick_labels = ["hour{}".format(i) for i in range(1,13)]
#plt.xticks() 第一个参数是 x 轴上的位置列表,第二个参数是标签列表
plt.xticks(x,xtick_labels) # 若x为字符串型,则要转换为range(len(x))
plt.yticks(range(min(y1), max(y1)+1))
# 6 添加描述信息
plt.xlabel("Time") # 设置 x 轴标签
plt.ylabel("Temperature/℃") # 设置 y 轴标签
plt.title("Temperature Distribution") # 设置标题
# 7 绘制网格
plt.grid()
# 8 添加图例 - 即将label显示到图中
# 默认0是寻找最佳位置,此外还有1~10,可自行定义位置 通过ctrl+B两次查看源码
plt.legend()
# 7 保存
# plt.savefig(String pathName):用于保存图片至指定的路径下(可保存为 svg 矢量图格式,则在缩放过程中不会有锯齿)
plt.savefig("./sig_size.png")
# 8 展示
plt.show()
1.2 绘制其他图形
# 1 散点图
plt.scatter(x,y)
# 2 条形图
plt.bar(x,y)
plth.bar(x,y) #横着的条形图
# 3 直方图
a = [15, 13, 14.5, 17, 20, 25, 26, 26, 24, 22, 18, 15]
# a是列表 num表将数据分成num组,即num个竖条
# num的计算公式:极差 / 组距
d = 1 #组距,组距应尽量选择能按公式整除
num = (max(a)-min(a))//d
plt.hist(a,num) # 纵坐标表每组的组频 可添density=True参数改为频率图
1.3 其他绘图工具
echarts
echarts官网实例
echarts-pink教程
plotly
可视化工具中的github,相比于matplotlib更为简单,图形更漂亮,同时兼容natplotlib和pandas,使用简单,照着文档写即可
plotly文档地址
seaborn
实现略优于Matplotlib的功能,更为方便
seaborn官网
2 numpy
2.1 创建数组
import numpy as np
t1 = np.array([1, 2, 3])
print("t1 =", end=" ")
print(t1)
print(type(t1))
print("="*30)
t2 = np.array(range(10))
print("t2 =", end = " ")
print(t2)
print(type(t2))
print("="*30)
t3 = np.arange(10)
print("t3 =", end = " ")
print(t3)
print(type(t3))
# 输出
t1 = [1 2 3]
<class 'numpy.ndarray'>
==============================
t2 = [0 1 2 3 4 5 6 7 8 9]
<class 'numpy.ndarray'>
==============================
t3 = [0 1 2 3 4 5 6 7 8 9]
<class 'numpy.ndarray'>
2.2 指定数据类型
(1)初始化数据类型
array(obj, dtype=),其中dtype
int8或i1float16或f2c8:即 8 字节的复数 complex64bool:存储 True 或 False 值

t4 = np.array(range(10), dtype="i1")
print("t4 = ", t4)
print(t4.dtype)
print("="*50)
t5 = t4.astype("bool")
print("t5 =", end = " ")
print(t5)
print(t5.dtype)
(2)修改数据类型
t4 = np.array(range(10), dtype="i1")
t5 = t4.astype("bool") # 修改成bool类型
# np.round(b,2) 保留2位小数
(3)生成随机数数组
np.array([rd.random() for i in range(6)]) 注意要有方括号
np.round(obj, bit) : 至多保留 bit 位小数
import random as rd
randArray = np.array([rd.random() for i in range(6)])
print("randArray =", end=" ")
print(randArray)
roundedRandArray = np.round(randArray, 2)
print("roundedRandArray =", end=" ")
print(roundedRandArray)
(4)修改数组形状
# 注:以下方法都不会修改到原t
t = np.arrange(12)
t.shape() # 查看数组形状
t.ashape(12,) # 改成一维数组 t.ashape(1,12) 是1行12列,本质是二维数组
t.ashape(3,4) # 改成二行三列数组
t.ashape(2,2,3) # 改成两块二行三列数组
# 注:ashape中有几个数就是几维数组,数的乘积等于元素个数 如t有12个元素,所以2*2*3=12
t.flatten() # 将数据展开为 1 维的数组
t + 2 # t中的每个元素值都+2,加减乘除都可行
t + t1 # 同维数组对应位置元素可相加减乘除
# 此外不同维度下一些特殊情况也可进行计算,见下图

(5)轴(Axis)
- 在numpy中可以理解为方向,使用0,1,2…数字表示,对于一个一维数组,只有一个0轴,对于2维数组(shape(2,2)),有0轴和1轴,对于三维数组(shape(2,2, 3)),,有0,1,2轴
- np.arange(0,10).reshape((2,5)) reshpe中2表示0轴长度(包含数据的条数)
2.3 数组的索引和分片
(1)numpy读取数据
CSV: Comma-Separated Value,逗号分隔值文件
显示: 表格状态
源文件: 换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录
由于csv便于展示,读取和写入,所以很多地方也是用csv的格式存储和传输中小型的数据,为了方便教学,我们会经常操作csv格式的文件,但是操作数据库中的数据也是很容易的实现的
np.loadtxt(fname,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
注: unpack就是转置

(2)numpy的转置
# 三个方法任选一个
t.T
t.transpose()
t.swapaxes()
(3)numpy的索引和切片
# coding=utf-8
# coding=utf-8
import numpy as np
# 下两个csv文件在git的day03中
# us_file_path = "./US_video_data_numbers.csv"
# uk_file_path = "./GB_video_data_numbers.csv"
# t1 = np.loadtxt(us_file_path,delimiter=",",dtype="int",unpack=True)
# t2 = np.loadtxt(us_file_path,delimiter=",",dtype="int")
t2 = np.array([
[1, -5, 12, 9],
[6, -1, -5, 3],
[0, 12, 32, 8],
[1, 2, 3, 4],
[12,22, 13,24]])
# print(t1)
print(t2)
print("*"*100)
# 取行
print(t2[2]) # 取第3行
print(t2[1,:]) # 取第2行
# 取连续的多行
print(t2[2:]) #从第3行开始取所有行
# 取不连续的多行
print(t2[[0,1,3]]) # 取1,2,4行
print(t2[[1,3,4],:]) # 取第2,4,5行
# 取列
print(t2[:,0]) # 取第1列
# 取连续的多列
print(t2[:,2:]) # 取第3列开始的所有列
# 取不连续的多列
print(t2[:,[0,2]]) # 取第1,3列
# 取i行i列的某个值
a = t2[2,3] # 取第3行,第四列的值
print('a=',a)
print(type(a))
# 取多行和多列,取第3行到第5行,第2列到第4列的结果
# 取的是行和列交叉点的位置
b = t2[2:5,1:4] #注:索引取到下标为5的前一个位置,即下标为4的位置,也即第5行
print('b=',b)
# 取多个不相邻的点
# 选出来的结果是(0,0) (2,1) (2,3)
c = t2[[0,2,2],[0,1,3]]
print('c=',c)
(4)numpy中数值的修改

(5)numpy中布尔索引
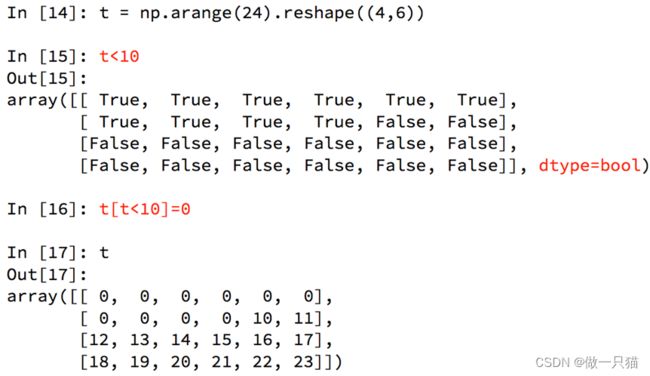
(6)numpy中三元运算符
np.where(t<10,0,10) 小于10的替换成0,大于10的替换成10

(7)numpy中的nan和inf
nan(NAN,Nan):not a number表示不是一个数字
什么时候numpy中会出现nan: 当我们读取本地的文件为float的时候,如果有缺失,就会出现nan
当做了一个不合适的计算的时候(比如无穷大(inf)减去无穷大)
inf(-inf,inf):infinity,inf表示正无穷,-inf表示负无穷
什么时候回出现inf:包括(-inf,+inf) 比如一个数字除以0,(python中直接会报错,numpy中是一个inf或者-inf)
(8)numpy中的clip(裁剪)
t.clip(10,18)小于10的替换成10,大于18的替换成18

2.4 数组常用方法
2.4.1 数组的拼接
(1)数组的拼接

(2)数组的行列交换
import numpy as np
t = np.arange(12, 24).reshape(3, 4)
t[[0, 1, 2], :] = t[[1, 0, 2], :]
原:
array([[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]])
后:
array([[20, 21, 22, 23],
[12, 13, 14, 15],
[16, 17, 18, 19]])
(3)数组的其他操作
-
获取最值
np.min()
np.max() -
获取最大值最小值的位置
np.argmax(t,axis=0)
np.argmin(t,axis=1) -
创建一个全0的数组: np.zeros((3,4))
-
创建一个全1的数组:np.ones((3,4))
-
创建一个对角线为1的正方形数组(方阵):np.eye(3)
2.4.2 numpy生成随机数

2.4.3 numpy的注意点copy和view
a=b a只是一个指向b的新引用,且a和b相互影响
a = b[:] 视图的操作,一种切片,会创建新的对象a,但是a的数据完全由b保管,他们两个的数据变化是一致的
a = b.copy() 复制,a和b互不影响
2.4.4 numpy中的nan的注意点

2.4.5 numpy中常用统计函数
求和:t.sum(axis=None)
均值:t.mean(a,axis=None) 受离群点的影响较大
中值:np.median(t,axis=None)
最大值:t.max(axis=None)
最小值:t.min(axis=None)
极差:np.ptp(t,axis=None) 即最大值和最小值之差
标准差:t.std(axis=None)
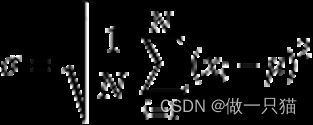
3 pandas
常用数据类型
Series 一维,带标签数组
DataFrame 二维,Series容器
3.1 Series创建
import pandas as pd
# 列表形式
t1 = pd.Series([1,2,3])
t1[t1>1]
# 字典形式
t2 = pd.Series({"name":"hh","age":18})
t2[["name","age"]]
t2.index
len(t2.index)
list(t2.index)[:2]
3.2 pandas读取外部文件
pd.read_csv() # 读csv
pd.read_sql() # 读sql
# 从Mongodb读
from pymongo import MongoClient
client = MongoClient()
collection = client["douban"]["tv1"]]
data = list(collection,find())
3.3 DataFrame
3.3.1 索引
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
pd.DataFrame(np.arange(12).reshape(3,4))
pd.DataFrame(np.arange(12).reshape(3,4),index=list("abc"),columns=list("WXYZ"))


d1 = {"name":["hh","yy"],"age":[20,22]}

3.3.2 DatafFrame常用方法

df.sort_values(by="Count_AnimalName",ascending=False) # ascending为true表升序排序
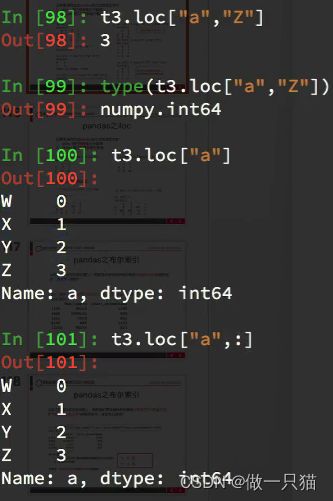
df.loc 通过标签索引行数据
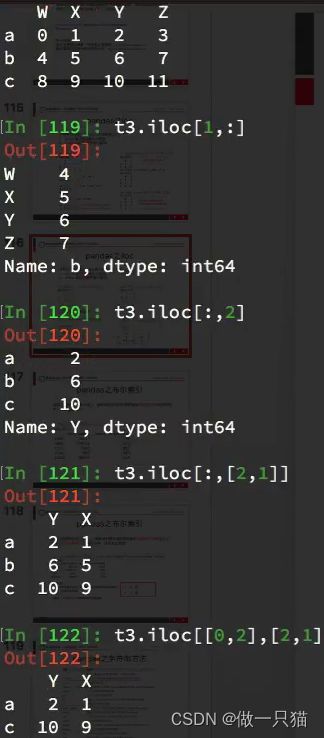
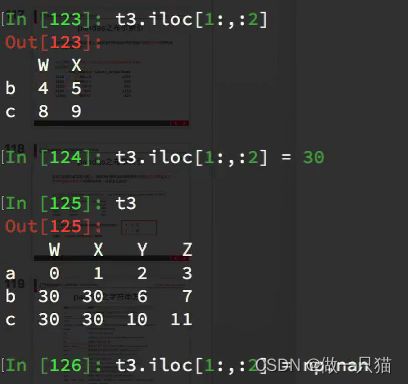
df.iloc 通过位置获取行数据

loc

iloc
3.3.3 pandas的布尔索引

3.3.4 pandas之字符串方法
df.str.xxx
