Python通过selniumwire抓取公开信息全过程
Python抓取数据解析有两种模式,一种是网站前后端融合的情况,利用Beautiful Soup 来解析,即网页显示有什么就能抓取什么,这种方法缺陷是解析速度慢,以及网页结构可能变化要随时修正脚本。另一种是针对前后端分离的情况,网站后端通过接口返回数据给前端解析显示,这种时候我们只需要抓到这个接口,再发起请求就可以得到数据字段比页面显示更丰富、格式更标准的数据。
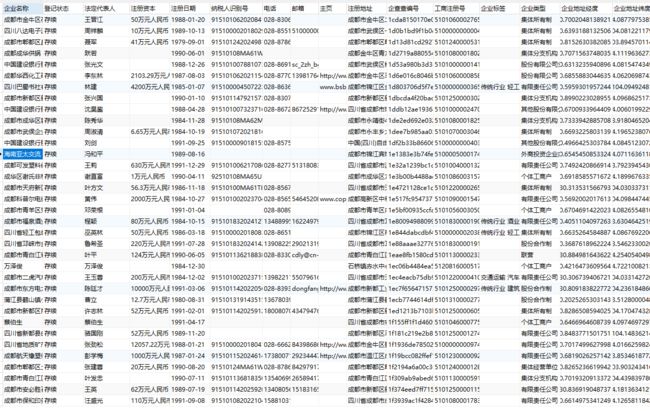

对前后端分离的网站,在发起请求时会调用自身的接口返回数据给前端,如果是普通网站这时候我们已经可以通过浏览器F12观察接口的header,在脚本里构造好带cookies、header、请求参数params的get/post请求。这里使用高级查询功能调用接口

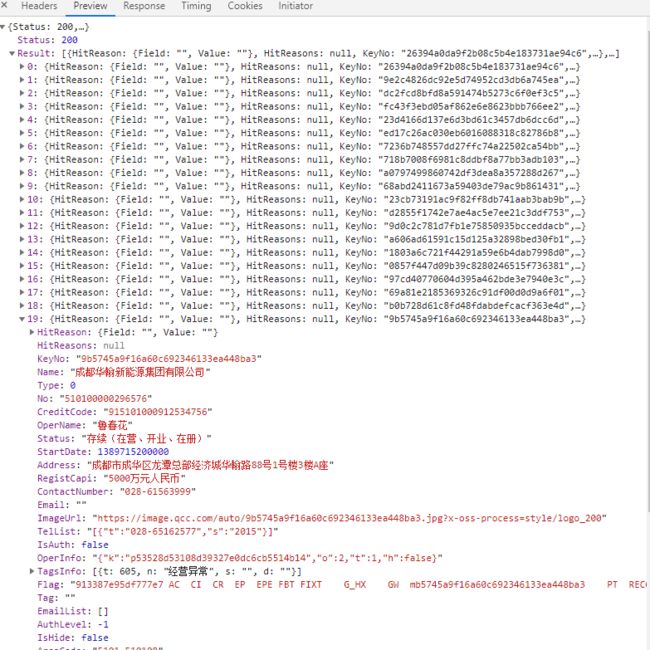

但在脚本里直接用request请求接口时候会发现,接口只可用一次,每次只返回20条数据。这是因为请求里含分页信息,每页只返回20条,获取更多则需要在请求参数里填写请求第二页第三页。而我们脚本利用构造的请求时,只会返回当页请求,无法返回第二页第三页,仔细观察,原来是请求头headers中构造了一个企查查的自定义字段,每次发起新请求时(包括请求其他页数)该字段都会变化,所以脚本无法直接利用request请求所有数据。

但是我们在浏览器里访问的时候,是可以手动点击下一页下一页的,所以我们可以采用selnium来模拟浏览器的操作,来获得每次请求时网站生成的header中随机自定义字段,再利用request请求调用企查查原生接口获得返回数据。selnium是用脚本模拟人操作浏览器的工具,可以做到和人工操作一样,来完成一些纯请求脚本不好做的事情,支持多种浏览器,这里下载一个谷歌浏览器,再下载对应谷歌浏览器版本的selnium驱动放到Python文件夹里即可。我们在这里除了要模拟浏览器操作,还需要获取请求头headers的信息,所以我们要用的是selniumwire,可以理解为selnium加强版。
技术路径准备好后,考虑抓取流程,即使在浏览器里查看,每次最多也只会返回5000条数据,所以要把这500多W条抓完,就必须把数据分段,这里可以使用企业注册日期来分段,使得每个日期区间的企业数量在5000条内即可,然后脚本中模拟人工查询、翻页操作,再调用request请求解析最后写入数据库。
首先我们要做日期分段功能,把日期切分到每段区间不超过5000条。人工观察了下,越早注册的企业越少,后期成都注册的企业一天就几千条了,所以我按照时间来粗分。2003年以前,以30天为分段;2003-2015以5天为分段;2015以后,每天为分段。期间如果多天分段的大于5000条则进一步拆分为每天分段,如果每天也大于5000则记录到日志中跳过,如果某段结果小于1000条,则扩展该段日期。
导入和定义一些基础信息
import sys
from ast import keyword
from asyncio.windows_events import NULL
from cgitb import small
from cmath import e
from ctypes import addressof
from email import header
import email
import errno
import json
from nturl2path import url2pathname
from os import stat
from pickletools import long1
from re import S
from tkinter import E
from urllib.error import HTTPError
import winreg #windows相关库
#加载自动化测试模块
#from selenium import webdriver
from bs4 import BeautifulSoup #网页解析库
import urllib.request #请求库
import requests
#from lxml import etree
import time
import pymysql
#加载自动化测试模块
from seleniumwire import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import gzip
import datetime
from selenium.webdriver.common.keys import Keys
def get_desktop(): #获得windows桌面路径
key = winreg.OpenKey(winreg.HKEY_CURRENT_USER,r'Software\Microsoft\Windows\CurrentVersion\Explorer\Shell Folders')
return winreg.QueryValueEx(key, "Desktop")[0]
log_path = get_desktop()+"\\脚本\\log\\log_抓企查查通过搜索抓基础信息.txt"
Paging_path = get_desktop()+"\\脚本\\config\\config_抓企查查通过搜索抓基础信息_分页.txt"
Paging_log_path = get_desktop()+"\\脚本\\log\\log_抓企查查通过搜索抓基础信息_分页_单日大于5000条的日期.txt"
config_path = get_desktop()+"\\脚本\\config\\config_抓企查查通过搜索抓基础信息.ini"
lastDate = datetime.datetime.now()
lastDate = lastDate+datetime.timedelta(days=-15)定义一些selium操作浏览器时选择、点击相关元素的基础方法
# 利用异常捕获和递归实现网络延迟下的稳定抓取
def find_element_by_css_selector(driver,id):
try:
get = driver.find_element_by_css_selector(id)
except:
time.sleep(0.2)
get = find_element_by_css_selector(driver,id)
return get
# 利用异常捕获和递归实现网络延迟下的稳定抓取
def find_element_by_class_name(driver,id):
try:
get = driver.find_element_by_class_name(id)
except:
time.sleep(0.2)
get = find_element_by_class_name(driver,id)
return get
# 利用异常捕获和递归实现网络延迟下的稳定抓取
def find_element_by_link_text(driver,id):
try:
get = driver.find_element_by_link_text(id)
except:
time.sleep(0.2)
get = find_element_by_link_text(driver,id)
return get
# 利用异常捕获和递归实现网络延迟下的稳定抓取
def find_element_by_xpath(driver,id):
try:
get = driver.find_element_by_xpath(id)
except:
time.sleep(0.2)
get = find_element_by_xpath(driver,id)
return get
def find_element_by_css_selector2(driver,id,ele):
try:
get = driver.find_element_by_css_selector(id)
except:
ele.click()
time.sleep(1)
get = find_element_by_css_selector2(driver,id,ele)
return get
主程序流程:打开平台,自动登录帐号,手动操作通过验证码,然后自动进入高级查询查询成都企业数据,然后执行把日期分段到每段5000条结果内的操作
if __name__ == '__main__':
sys.setrecursionlimit(20000)
#打开数据库连接
conn = pymysql.connect(host = 'localhost',user = "root",passwd = "",db = "企业信息")
Paging_file = open(Paging_path,'a+',encoding='utf8',buffering=1)
#获取游标
cur=conn.cursor()
logfile = open(log_path,'a+',encoding='utf8',buffering=1)
driver = webdriver.Chrome()
driver.maximize_window()
driver.get("https://www.qcc.com/weblogin")
ele_login = find_element_by_class_name(driver,"login-change")
ele_login.click()
ele_login2 = find_element_by_link_text(driver,"密码登录")
ele_login2.click()
inputs = driver.find_elements_by_tag_name("input")
for input in inputs:
if "phone-number"==input.get_attribute("name"):
ele_username = input
if "password"==input.get_attribute("name"):
ele_password = input
ele_username.send_keys("你的帐号")
ele_password.send_keys("你的密码")
inputs =driver.find_elements_by_tag_name("button")
for input in inputs:
#print(input.get_attribute("id")+" | "+ input.get_attribute("name")+" | "+input.get_attribute("class"));
if "btn btn-primary login-btn"==input.get_attribute("class"):
ele_login3 = input
ele_login3.click()
find_element_by_css_selector(driver,"#searchKey")
driver.get("https://www.qcc.com/web/search/advance")
ele_select1 = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div.fixed-bottom > div > div.bottom-result > div > a.btn.btn-default.m-r.store-tip-container")
ele_select1.click()
ele_select2 = find_element_by_css_selector(driver,"body > div.app-nmodal.modal.fade.in > div > div > div.modal-body > div > section > ul > div:nth-child(1)")
ele_select2.click()
ele_select3 = find_element_by_link_text(driver,"重新选择")
ele_select3.click()
time.sleep(2)
ele_select4 = find_element_by_xpath(driver,"/html/body/div[1]/div[2]/div[1]/div/div/div[2]/div[5]/div[1]/div[2]/div[8]/label")
ele_select4.click()
inputs =driver.find_elements_by_class_name("ant-calendar-input")
ele_startDate = inputs[0]
ele_endDate = inputs[1]
#getPagingFile(datetime.datetime.strptime("1800-01-01", "%Y-%m-%d"),datetime.datetime.strptime("1980-10-01", "%Y-%m-%d"),ele_startDate,ele_endDate)
#print("结束数量抓取")
Paging_file.close()
Paging_file = open(Paging_path,'r',encoding='utf8')
dateRanges=Paging_file.readlines()
for dateRange in dateRanges:
startDateSTR = dateRange.split()[0]
endDateSTR = dateRange.split()[1]
#insertSQLStrings="INSERT IGNORE INTO `企业信息`.`成都企业信息库`(`企业名称`, `登记状态`, `法定代表人`, `注册资本`, `注册日期`, `纳税人识别号`, `电话`, `邮箱`, `主页`, `注册地址`, `企查查编号`, `工商注册号`, `企业标签`, `企业类型`, `企业地址经度`, `企业地址纬度`, `企业地址城市`, `企业地址区县`, `企业行业标签`, `行业大类`, `行业中类`, `行业小类`, `行业最小类`) VALUES "
ele_temp = driver.find_elements_by_link_text("重置筛选")
if ele_temp == []:
ele_select3 = find_element_by_link_text(driver,"重新选择")
while 1:
#滚动到浏览器顶部
js_top = "var q=document.documentElement.scrollTop=0"
driver.execute_script(js_top)
try:
ele_select3.click()
break
except:
ele_select3 = find_element_by_link_text(driver,"重新选择")
time.sleep(2)
while 1:
try:
ele_select4 = find_element_by_xpath(driver,"/html/body/div[1]/div[2]/div[1]/div/div/div[2]/div[5]/div[1]/div[2]/div[8]/label/label/span[2]")
ele_select4.click()
break
except:
driver.refresh()
time.sleep(1)
inputs =driver.find_elements_by_class_name("ant-calendar-input")
ele_startDate = inputs[0]
ele_endDate = inputs[1]
ele_startDate.send_keys(Keys.CONTROL,'a')
time.sleep(0.2)
ele_startDate.send_keys(Keys.BACK_SPACE)
ele_startDate.send_keys(startDateSTR)
ele_endDate.send_keys(Keys.CONTROL,'a')
time.sleep(0.2)
ele_endDate.send_keys(Keys.BACK_SPACE)
ele_endDate.send_keys(endDateSTR)
while 1:
try:
#滚动到浏览器顶部
js_top = "var q=document.documentElement.scrollTop=0"
driver.execute_script(js_top)
time.sleep(0.3)
ele_temp = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div.container.m-t > div > div > div.npanel-body > div:nth-child(4) > span")
time.sleep(0.3)
ele_temp.click()
time.sleep(0.1)
except:
time.sleep(0.2)
print("点击查找失败1")
try:
#点击查找 失败五次额外处理
ele_select5 = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div.fixed-bottom > div > div.bottom-result > div > a.btn.btn-primary")
ele_select5.click()
print("即将抓下一批,休眠6秒")
time.sleep(6)
break
except:
time.sleep(0.2)
print("点击查找失败2")
#每页显示40条结果
temp = ""
while temp.find("40")<0:
#ele_select6 = find_element_by_css_selector2(driver,"body > div:nth-child(2) > div.app-search-advance > div > nav > ul > li.size-change > a",ele_select5)
ele_select6 = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div > nav > ul > li.size-change > a")
temp = ele_select6.text
time.sleep(0.5)
ele_select6.click()
ele_select7 = find_element_by_css_selector2(driver,"body > div:nth-child(2) > div.app-search-advance > div > nav > ul > li.size-change.open > div > a:nth-child(3)",ele_select6)
ele_select7.click()
time.sleep(0.5)
temp = 0
while 1:
temp+=1
#等待加载出请求的数据结果为止
res=None
trytime = 0
while res==None:
trytime+=1
time.sleep(0.1)
reqs = driver.requests
reqs.reverse()
#reqs[0].response.body.decode
res = getResonseByRequests(reqs,temp)
if trytime>=6:
driver.refresh()
trytime = 0
data = json.loads(res)
insertSQLStrings="INSERT IGNORE INTO `企业信息`.`成都企业信息库`(`企业名称`, `登记状态`, `法定代表人`, `注册资本`, `注册日期`, `纳税人识别号`, `电话`, `邮箱`, `主页`, `注册地址`, `企查查编号`, `工商注册号`, `企业标签`, `企业类型`, `企业地址经度`, `企业地址纬度`, `企业地址城市`, `企业地址区县`, `企业行业标签`, `行业大类`, `行业中类`, `行业小类`, `行业最小类`) VALUES "
if 'Result' in data:
lists = data['Result']
for list in lists:
Name = list['Name']
Name = Name.replace("'","")
KeyNo = list['KeyNo']
No = list['No']
CreditCode = list['CreditCode']
OperName= list['OperName']
ShortStatus= list['ShortStatus']
#毫秒级时间戳转为日期
StartDate= list['StartDate']
timestamp = StartDate
# 转换成localtime
try:
time_local = time.localtime(timestamp/1000)
# 转换成新的时间格式(精确到秒)
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
d = datetime.datetime.fromtimestamp(timestamp/1000)
StartDate = d.strftime("%Y-%m-%d")
except:
#1970年以前日期是另外公式
timestamp = timestamp/1000
StartDate = datetime.datetime(1970, 1, 1) + datetime.timedelta(seconds=timestamp+8*3600)
StartDate = StartDate.strftime("%Y-%m-%d")
Address = list['Address']
RegistCapi = list['RegistCapi']
ContactNumber= list['ContactNumber']
Email= list['Email']
strGW= list['GW']
EconKind = list['EconKind']
strX = list['X']
strY= list['Y']
Area= list['Area']
City = ""
if 'City' in Area:
City= Area['City']
County = ""
if 'County' in Area:
County = Area['County']
Industry = list['Industry']
SubIndustry = ""
MiddleCategory = ""
SmallCategory = ""
if 'SubIndustry' in Industry:
SubIndustry= Industry['SubIndustry']
if 'MiddleCategory' in Industry:
MiddleCategory = Industry['MiddleCategory']
if 'SmallCategory' in Industry:
SmallCategory = Industry['SmallCategory']
Industry= Industry['Industry']
Tag= list['Tag']
Tag = Tag.replace("\t"," ")
TagsInfos = list['TagsInfo']
TagsInfosStr =""
if TagsInfos!=None:
for TagsInfo in TagsInfos:
TagsInfo = TagsInfo['n']
TagsInfosStr=TagsInfosStr+TagsInfo+" "
# print(Name)
#这里要用批量插入,不要一条插一次,不然一条就要半秒钟
insertSQLString = "('{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}',{},{},'{}','{}','{}','{}','{}','{}','{}'),".format(Name,ShortStatus,OperName,RegistCapi,StartDate,CreditCode,ContactNumber,Email,strGW,Address,KeyNo,No,Tag,EconKind,strX,strY,City,County,TagsInfosStr,Industry,SubIndustry,MiddleCategory,SmallCategory)
insertSQLString = insertSQLString.replace("\\","")
insertSQLStrings = insertSQLStrings + insertSQLString
insertSQLStrings = insertSQLStrings[:-1]
try:
cur.execute(insertSQLStrings)
#conn.commit()
except Exception as e:
print(insertSQLStrings)
print((str)(datetime.datetime.now())+"抓企查查通过搜索 写入数据库 出现异常:"+str(e)+" "+insertSQLStrings)
logfile.write((str)(datetime.datetime.now())+"抓企查查通过搜索 写入数据库 出现异常:"+str(e)+" "+insertSQLStrings+"\n")
#根据页数计算这批是否完结,完结后则跳出循环再选新日期
if 'Paging' in data:
lists = data['Paging']
PageSize = lists['PageSize']
PageIndex = lists['PageIndex']
TotalRecords = lists['TotalRecords']
#print(PageSize*PageIndex)
if PageSize*PageIndex>=TotalRecords:
del driver.requests
break
print("准备进下一页"+(str)(temp))
##删除当前请求很重要,否则浏览器打开至今的请求都会累计,最后抓一页都要几万条请求获取速度超慢!
time1 = datetime.datetime.now()
del driver.requests
time2 = datetime.datetime.now()
print(time2-time1)
#这一页解析完成后,开始进入下一页
js_buttom = "var q=document.documentElement.scrollTop=10000"
driver.execute_script(js_buttom)
time.sleep(0.2)
ele_select8 = driver.find_element_by_link_text(">")
time3 = datetime.datetime.now()
print(time3-time2)
#这里加延迟是防止企查查限制
time.sleep(0.5)
ele_select8.click()
#如果因为网络延迟,点了下一页也没动一直停留当前页,做出判定
waittime=0
time33 = datetime.datetime.now()
print(time33-time3)
while 1:
if (waittime>=6):
print("多次尝试进入下一页")
time11 = datetime.datetime.now()
js_buttom = "var q=document.documentElement.scrollTop=10000"
driver.execute_script(js_buttom)
time22 = datetime.datetime.now()
print(time22-time11)
time.sleep(0.2)
ele_select8 = driver.find_element_by_link_text(">")
time.sleep(0.1)
time33 = datetime.datetime.now()
print(time33-time22)
ele_select8.click()
waittime=0
time333 = datetime.datetime.now()
print(time333-time33)
currenPage = driver.find_element_by_class_name("active").text
time4 = datetime.datetime.now()
print(time4-time333)
if (currenPage==(str)(PageIndex)):
time.sleep(1)
print("跳转失败,等待一秒")
waittime+=1
else:
print("已经进下一页"+(str)(temp))
break
conn.commit()
print("抓取完一批,休眠5秒")
#刷新很重要!可以清空浏览器缓存,避免长期执行内存占用累计直至崩溃!
driver.refresh()
time.sleep(5)
# insertSQLStrings = insertSQLStrings[:-1]
# time1 = datetime.datetime.now()
# try:
# cur.execute(insertSQLStrings)
# conn.commit()
# except Exception as e:
# print(insertSQLStrings)
# print((str)(datetime.datetime.now())+"抓企查查通过搜索 写入数据库 出现异常:"+str(e)+" "+insertSQLStrings)
# logfile.write((str)(datetime.datetime.now())+"抓企查查通过搜索 写入数据库 出现异常:"+str(e)+" "+insertSQLStrings+"\n")
# time2 = datetime.datetime.now()
# print(time2-time1)
# print("本批次抓取插入结束,总用时")
# print(time2-time11)
# print("\n")
Paging_file.close()
conn.close()
logfile.close()这里面有两个关键方法,一个是获取接口返回的时间短内企业数量getCountResonseByRequests,一个是根据日期和日期区间内企业数量来划定最终日期区间方法getPagingFile。
getCountResonseByRequests参数(reqs,startDate,endDate) ,reqs是所有请求参数,通过selniumwire获取的请求头是打开浏览器后的所有headers,所以需要筛选我们需要的请求的最新的headers,startDate,endDate是日期区间的开始与结束日期
#获取request请求列表的返回数据,一定要有返回结果,避免网络延迟无返回结果
def getCountResonseByRequests(reqs,startDate,endDate):
startDate = startDate.replace("-","")
endDate = endDate.replace("-","")
#print(startDate)
for req in reqs:
if ((str)(req.body).find(endDate)>0) and ((str)(req.body).find(startDate)>0):
try:
#driver里的请求参数是对的但不会返回后面页数请求的结果,所以必须取出后面页的header再重新发起post请求
res=requests.post("https://www.qcc.com/api/search/searchCount",data=req.body,headers=req.headers).text
print(req.body)
data = json.loads(res)
if 'Result' not in data:
return 0
count = data['Result']
count = count['Count']
#print(count)
return count
except:
#用异常捕获并延迟等待循环请求返回数据,否则请求有了返回数据还无
time.sleep(1)
getCountResonseByRequests(reqs,startDate,endDate)
getPagingFile参数(startDate,endDate,ele_startDate,ele_endDate)是开始结束日期,与浏览器中开始结束日期输入框元素的位置。
#把结果分为5000页内日期区间
def getPagingFile(startDate,endDate,ele_startDate,ele_endDate):
startDateSTR = (str)(startDate)[:10]
endDateSTR = (str)(endDate)[:10]
if endDate<=lastDate:
ele_startDate.send_keys(Keys.CONTROL,'a')
time.sleep(0.2)
ele_startDate.send_keys(Keys.BACK_SPACE)
ele_startDate.send_keys(startDateSTR)
ele_endDate.send_keys(Keys.CONTROL,'a')
time.sleep(0.2)
ele_endDate.send_keys(Keys.BACK_SPACE)
ele_endDate.send_keys(endDateSTR)
#temp = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div.container.m-t > div > div > div.npanel-body > div:nth-child(5) > span")
#temp.click()
count=None
while count==None:
time.sleep(1)
reqs = driver.requests
reqs.reverse()
count = getCountResonseByRequests(reqs,startDateSTR,endDateSTR)
#2003年以前,以30天为分段;2003-2015以5天为分段;2015以后,每天为分段。期间如果多天分段的大于5000条则进一步拆分为每天分段,如果每天也大于5000则记录到日志中跳过
if endDate5000:
#当区间断大于5000条结果,则按每天来分段,若每天里还有大于5000的,记录并跳过
if (endDate != startDate):
endDate=startDate
getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
else:
print(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理")
Paging_logfile.write(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理"+"\n")
startDate = endDate+datetime.timedelta(days=1)
endDate=startDate
getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
else:
print(startDateSTR+" "+endDateSTR+" "+(str)(count))
Paging_file.write(startDateSTR+" "+endDateSTR+" "+(str)(count)+"\n")
startDate = endDate+datetime.timedelta(days=1)
endDate=endDate+datetime.timedelta(days=31)
getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
elif endDate5000:
#当区间断大于5000条结果,则按每天来分段,若每天里还有大于5000的,记录并跳过
if (endDate != startDate):
endDate=startDate
getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
else:
print(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理")
Paging_logfile.write(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理"+"\n")
startDate = endDate+datetime.timedelta(days=1)
endDate=startDate
getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
else:
print(startDateSTR+" "+endDateSTR+" "+(str)(count))
Paging_file.write(startDateSTR+" "+endDateSTR+" "+(str)(count)+"\n")
startDate = endDate+datetime.timedelta(days=1)
endDate=endDate+datetime.timedelta(days=6)
getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
else:
if count<1000:
endDate = endDate+datetime.timedelta(days=1)
getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
elif count>5000:
print(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理")
Paging_logfile.write(startDateSTR+"-"+endDateSTR+"超过5000,请手动查看处理"+"\n")
startDate = endDate+datetime.timedelta(days=1)
endDate=startDate
getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
else:
print(startDateSTR+" "+endDateSTR+" "+(str)(count))
Paging_file.write(startDateSTR+" "+endDateSTR+" "+(str)(count)+"\n")
#如果抓取了所有日期结果分段,则结束数量抓取方法
if endDate==lastDate:
return
startDate = endDate+datetime.timedelta(days=1)
endDate=startDate
getPagingFile(startDate,endDate,ele_startDate,ele_endDate)
else:
getPagingFile(startDate,lastDate,ele_startDate,ele_endDate)
这个过程完成后后,我们就可以获得写入txt的日期分段,每行数据是日期区间的开始日期、结束日期、日期区间内企业数量

然后再开始按遍历所有日期区间开始一页页抓取调用原生接口searchmulti,这里写一个解析该接口结果的方法
#获取request请求列表的返回数据,一定要有返回结果,避免网络延迟无返回结果
def getResonseByRequests(reqs,page):
strPage = "\"pageIndex\":"+(str)(page)
for req in reqs:
if ((str)(req.body).find("\"pageSize\":40")>0) and (str)(req.body).find(strPage)>0:
try:
#driver里的请求参数是对的但不会返回后面页数请求的结果,所以必须取出后面页的header再重新发起post请求
res=requests.post("https://www.qcc.com/api/search/searchMulti",data=req.body,headers=req.headers).text
# res = req.response.body
# res=gzip.decompress(res).decode("utf-8")
# print(res)
print(req.body)
#print("获取数据中")
#print(res)
return res
except:
#用异常捕获并延迟等待循环请求返回数据,否则请求有了返回数据还无
time.sleep(1)
getResonseByRequests(reqs,page)
主程序里开始解析每个日期区间的结果并写入数据库
Paging_file = open(Paging_path,'r',encoding='utf8')
dateRanges=Paging_file.readlines()
for dateRange in dateRanges:
startDateSTR = dateRange.split()[0]
endDateSTR = dateRange.split()[1]
ele_temp = driver.find_elements_by_link_text("重置筛选")
if ele_temp == []:
#滚动到浏览器顶部
js_top = "var q=document.documentElement.scrollTop=0"
driver.execute_script(js_top)
ele_select3 = find_element_by_link_text(driver,"重新选择")
ele_select3.click()
time.sleep(2)
ele_select4 = find_element_by_xpath(driver,"/html/body/div[1]/div[2]/div[1]/div/div/div[2]/div[6]/div[1]/div[2]/div[8]/label")
ele_select4.click()
inputs =driver.find_elements_by_class_name("ant-calendar-input")
ele_startDate = inputs[0]
ele_endDate = inputs[1]
ele_startDate.send_keys(Keys.CONTROL,'a')
time.sleep(0.2)
ele_startDate.send_keys(Keys.BACK_SPACE)
ele_startDate.send_keys(startDateSTR)
ele_endDate.send_keys(Keys.CONTROL,'a')
time.sleep(0.2)
ele_endDate.send_keys(Keys.BACK_SPACE)
ele_endDate.send_keys(endDateSTR)
ele_temp = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div.container.m-t > div > div > div.npanel-body > div:nth-child(5) > span")
ele_temp.click()
#点击查找
ele_select5 = find_element_by_css_selector(driver,"body > div:nth-child(2) > div.app-search-advance > div.fixed-bottom > div > div > a.btn.btn-primary")
ele_select5.click()
#每页显示40条结果
temp = ""
while temp.find("40")<0:
ele_select6 = find_element_by_css_selector2(driver,"body > div:nth-child(2) > div.app-search-advance > div > nav > ul > li.size-change > a",ele_select5)
temp = ele_select6.text
ele_select6.click()
ele_select7 = find_element_by_css_selector2(driver,"body > div:nth-child(2) > div.app-search-advance > div > nav > ul > li.size-change.open > div > a:nth-child(3)",ele_select6)
ele_select7.click()
time.sleep(0.5)
temp = 0
while 1:
temp+=1
#等待加载出请求的数据结果为止
res=None
while res==None:
time.sleep(1)
reqs = driver.requests
reqs.reverse()
res = getResonseByRequests(reqs,temp)
data = json.loads(res)
if 'Result' in data:
lists = data['Result']
for list in lists:
Name = list['Name']
KeyNo = list['KeyNo']
No = list['No']
CreditCode = list['CreditCode']
OperName= list['OperName']
ShortStatus= list['ShortStatus']
#毫秒级时间戳转为日期
StartDate= list['StartDate']
timestamp = StartDate
# 转换成localtime
try:
time_local = time.localtime(timestamp/1000)
# 转换成新的时间格式(精确到秒)
dt = time.strftime("%Y-%m-%d %H:%M:%S", time_local)
d = datetime.datetime.fromtimestamp(timestamp/1000)
StartDate = d.strftime("%Y-%m-%d")
except:
#1970年以前日期是另外公式
timestamp = timestamp/1000
StartDate = datetime.datetime(1970, 1, 1) + datetime.timedelta(seconds=timestamp+8*3600)
StartDate = StartDate.strftime("%Y-%m-%d")
Address = list['Address']
RegistCapi = list['RegistCapi']
ContactNumber= list['ContactNumber']
Email= list['Email']
strGW= list['GW']
EconKind = list['EconKind']
strX = list['X']
strY= list['Y']
Area= list['Area']
City = ""
if 'City' in Area:
City= Area['City']
County = ""
if 'County' in Area:
County = Area['County']
Industry = list['Industry']
SubIndustry = ""
MiddleCategory = ""
SmallCategory = ""
if 'SubIndustry' in Industry:
SubIndustry= Industry['SubIndustry']
if 'MiddleCategory' in Industry:
MiddleCategory = Industry['MiddleCategory']
if 'SmallCategory' in Industry:
SmallCategory = Industry['SmallCategory']
Industry= Industry['Industry']
Tag= list['Tag']
Tag = Tag.replace("\t"," ")
TagsInfos = list['TagsInfo']
TagsInfosStr =""
if TagsInfos!=None:
for TagsInfo in TagsInfos:
TagsInfo = TagsInfo['n']
TagsInfosStr=TagsInfosStr+TagsInfo+" "
# print(Name)
try:
insertSQLString = "INSERT IGNORE INTO `企业信息`.`成都企业信息库`(`企业名称`, `登记状态`, `法定代表人`, `注册资本`, `注册日期`, `纳税人识别号`, `电话`, `邮箱`, `主页`, `注册地址`, `企查查编号`, `工商注册号`, `企业标签`, `企业类型`, `企业地址经度`, `企业地址纬度`, `企业地址城市`, `企业地址区县`, `企业行业标签`, `行业大类`, `行业中类`, `行业小类`, `行业最小类`) VALUES ('{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}','{}',{},{},'{}','{}','{}','{}','{}','{}','{}');".format(Name,ShortStatus,OperName,RegistCapi,StartDate,CreditCode,ContactNumber,Email,strGW,Address,KeyNo,No,Tag,EconKind,strX,strY,City,County,TagsInfosStr,Industry,SubIndustry,MiddleCategory,SmallCategory)
cur.execute(insertSQLString)
conn.commit()
except Exception as e:
print(insertSQLString)
print((str)(datetime.datetime.now())+"通过搜索 写入数据库 出现异常:"+str(e)+" "+insertSQLString)
logfile.write((str)(datetime.datetime.now())+"通过搜索 写入数据库 出现异常:"+str(e)+" "+insertSQLString+"\n")
#根据页数计算这批是否完结,完结后则跳出循环再选新日期
if 'Paging' in data:
lists = data['Paging']
PageSize = lists['PageSize']
PageIndex = lists['PageIndex']
TotalRecords = lists['TotalRecords']
#print(PageSize*PageIndex)
if PageSize*PageIndex>TotalRecords:
break
#这一页解析完成后,开始进入下一页
ele_select8 = find_element_by_link_text(driver,">")
ele_select8.click()
Paging_file.close()
conn.close()
logfile.close()至此完成抓取,全过程基本自动化,只有脚本启动后的登录过程需要手动通过验证码,同理可以抓取其他省市、其他限定条件的数据。