51-15 视频理解串讲—TimeSformer论文精读
今天读的论文题目是Is Space-Time Attention All You Need for Video Understanding?
Facebook AI提出了一种称为TimeSformer视频理解的新架构,这个架构完全基于transformer,不使用卷积层。它通过分别对视频的时间和空间维度应用自注意力机制,有效地捕捉动作的时空特征。自transformer提出以来,在NLP领域得到了非常广泛的使用,是机器翻译以及语言理解中最常用的方法。相比于现在的3DCNN,TimeSformer训练要快3倍,推理的时间为它的1/10。除此之外,TimeSformer可以在更长的视频片段上训练更大的模型。当前的3DCNN最多只能够处理几秒钟的片段,使用TimeSformer甚至可以在数分钟的片段上进行训练,它将为AI理解更复杂的人类行为铺好路。
那么它具体是如何实现的呢?众所周知,Transformer的训练非常消耗资源。为了缓解这一问题,TimeSformer通过两个方式来减少计算量,1)将视频拆解为不相交的图像块序列的子集。2)使用一种独特的自注意力方式来避免所有的图像块序列之间进行复杂计算。文中把这项技术叫做分开的时空注意力机制叫Divided Space-Time Attention。
Abstract
我们提出了一种无卷积的视频分类方法,该方法完全基于空间和时间上的self-attention。我们的方法名为“TimeSformer”,通过直接从一系列帧级patch中学习时空特征,使标准的Transformer架构适用于视频。实验研究比较了不同的自注意力方案,并表明“时空分割注意力机制”,即在每个块中分别应用时间注意和空间注意,在所选择的5种设计方案中有最佳的视频分类精度。尽管是全新的设计,TimeSformer在几个动作识别基准上取得了最先进的结果,包括在Kinetics-400和Kinetics-600数据集上。最后,与3DCNN相比,我们的模型训练速度更快,它可以实现更高的测试效率(精度下降很小),并且它也可以应用于更长的视频剪辑(超过一分钟)。代码和模型可在以下网址下载:https://github.com/ facebookresearch/TimeSformer.
Introduction
在过去的几年里,自然语言处理NLP领域由于self-attention方法的出现而发生了革命性的变化。由于它在捕获词之间的远程依赖关系以及训练可扩展性方面的出色能力,自注意架构,如Transformer模型,代表了广泛的语言任务(包括机器翻译、问答和自回归词生成)中的当前最先进的技术。
视频理解与NLP有几个高层次的相似之处。首先,视频和句子都是顺序的。此外,正如一个词的意思通常只能通过将其与句子中的其他单词联系起来才能理解,可能会有人认为,短片段中的原子动作需要与视频的其余部分联系起来,以便完全消除歧义。因此,人们期望NLP的远程自注意模型对视频建模也非常有效。然而,在视频领域,2D或3D卷积仍然是跨不同视频任务进行时空特征学习的核心算子。虽然自注意在卷积层上应用得很好,但据我们所知,没有人试图将自注意作为视频识别模型的唯一构件。
在这项工作中,我们提出了一个问题,即是否有可能通过用自注意替换卷积算子来构建一个高性能的无卷积视频架构。我们认为,这样的设计有可能克服卷积模型在视频分析中的一些固有限制。首先,尽管它们强大的归纳偏置(例如,局部连通性和平移等价性)对小的训练集无疑是有益的,但在数据充足且“所有”都可以从示例中学习的情况下,它们可能会过度限制模型的表达能力。与cnn相比,Transformer施加的限制性归纳偏置更少。这扩大了它们可以表示的功能,并使它们更适合现代大数据策略,其中不太需要强归纳先验。其次,虽然卷积核是专门为捕获短期时空信息而设计的,但它们不能对超出接受野的依赖关系进行建模。而深度卷积堆栈自然地扩展了接受域,这些策略在通过聚合较短范围的信息来捕获远程依赖方面本质上是有限的。相反,自注意机制可以通过直接比较所有时空位置的特征激活来捕获局部和全局远程依赖关系,这远远超出了传统卷积滤波器的接受域。最后,尽管在GPU硬件加速方面取得了进步,但训练深度cnn仍然非常昂贵,特别是在应用于高分辨率和长视频时。静态图像领域的最新研究已经证明,与cnn相比,transformer的训练和推理速度更快,从而可以在相同的计算预算下构建具有更大学习能力的模型。
基于这些结果,我们提出了一种完全基于自注意的视频架构。我们通过将自注意机制从图像空间扩展到时空三维集,将图像模型ViT应用于视频。我们提出的模型名为“TimeSformer”(来自Time-Space Transformer),它将视频视为从单个帧中提取的一系列patches。与ViT一样,每个patch被线性映射到一个嵌入中,并用位置信息进行增强。这使得可以将得到的矢量序列解释为可以送到Transformer encoder的token embedding,类似于NLP计算词嵌入特征。
标准Transformer中自注意的一个缺点是,它需要为所有token对计算相似性度量。在我们的设置中,由于视频中有大量patch,这在计算上是昂贵的。为了解决这些挑战,我们提出了几种可扩展的时空自注意设计,并在大规模动作分类数据集上对它们进行了评估。在提出的方案中,我们发现最好的设计是“分割时空注意力”架构,该架构在网络的每个块中分别应用时间注意力和空间注意力。与基于卷积的视频架构的既定范例相比,TimeSformer采用了完全不同的设计。然而,它达到的准确性可与该领域的最新技术相媲美,在某些情况下甚至更胜一筹。另外模型可以用于长视频建模。
Related Work
我们的方法受到最近使用自注意进行图像分类的工作的影响,这些工作要么与卷积算子结合,要么甚至完全替代卷积算子。在前一类中,非局部网络采用非局部均值,有效地概括了transformer的自注意函数。也有论文提出了一种2D自注意机制,该机制作为2D卷积的替代品具有竞争力,而且当用于用自注意特征增强卷积特征时,结果会更强。除了图像分类之外,关系网络和DETR在卷积特征图上使用自注意进行目标检测。
我们的方法与利用自注意替代卷积的图像网络更密切相关。由于这些工作使用单个像素作为查询,为了保持可管理的计算成本和较小的内存消耗,它们必须将自注意的范围限制在局部邻域,或者在图像大幅缩小版本上使用全局自注意。可扩展到完整图像的替代策略包括稀疏键值采样或限制沿空间轴计算的自注意。在我们的实验中考虑的一些自注意算子采用类似的稀疏和轴向计算,推广到时空volume。然而,我们的方法的效率主要源于将视频分解成一系列帧级patch,然后将这些patch的线性嵌入作为输入给Transformer。该策略最近在vision transformer,ViT中被引入,该策略在图像分类方面提供了令人印象深刻的性能。我们在ViT设计的基础上,通过提出并实证比较几种可扩展的视频时空自我注意方案,将其扩展到视频中。
虽然transformer最近被用于视频生成,但我们并不知道之前的视频识别架构使用自注意作为唯一的构建块。我们也注意到transformer已经在卷积特征映射的基础上被用于动作定位和识别、视频分类和群体活动识别。我们还注意到,有大量文献基于使用text transformer与video cnn相结合来解决各种视频语言任务,如字幕、问答和对话。最后,multimodal video-text transformers 也通过采用masked-token前置任务,在自然语言领域以无监督的方式进行训练或预训练。
The TimeSformer Model
Input clip
一个视频是由多帧图片构成。模型进行对视频进行F帧采样,输入为RGB三通道图像,尺寸H*W,表示为X∈![]() 。
。
Decomposition into patches
与ViT处理方法一样,我们将每一帧分解为N个不重叠的patch,每个patch的大小为P*P,使N个patch跨越整个帧,即N = H*W/P*P。我们将这些patch拉平,扁平化为向量![]()
p = 1......N 表示空间位置,t = 1......F,描述帧上的索引。
Transformer需要将patch构建成sequence进行输入(类似NLP中由token构成sequence),每个patch的尺寸为P*P,所以每patch的数量N(像素点的总数/patch像素点数)展开后,可以表示为向量![]() ,p = 1,...,N,t = 1...,F (3表示RGB三个通道,X(p,t)表示第t帧第p个patch)。
,p = 1,...,N,t = 1...,F (3表示RGB三个通道,X(p,t)表示第t帧第p个patch)。
Linear embedding
我们通过一个可学习的矩阵E将每个Patch x(p,t) 线性映射到嵌入向量Z中。
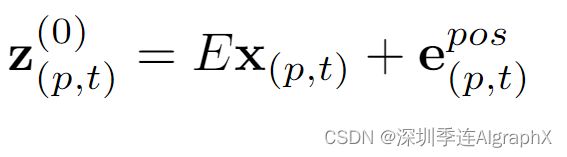
其中 e表示添加的可学习位置嵌入,编码每个patch的时空位置。生成嵌入向量序列z,p=1......N,t = 1.....F,表示 Transformer 的输入,并起到类似于在 NLP 中输入文本,Transformer 嵌入单词序列的作用。与原始 BERT Transformer 一样,我们在序列的第一个位置添加了一个特殊的可学习向量 z(0) 来表示分类标记的嵌入。
Query-Key-Value computation
Timesforer由 L 个 encoding 块组成。对每个 encoding 块 L,从前一个 encoding 块输出的 Z(L-1)
向量计算出每个patch的 query/key/value。
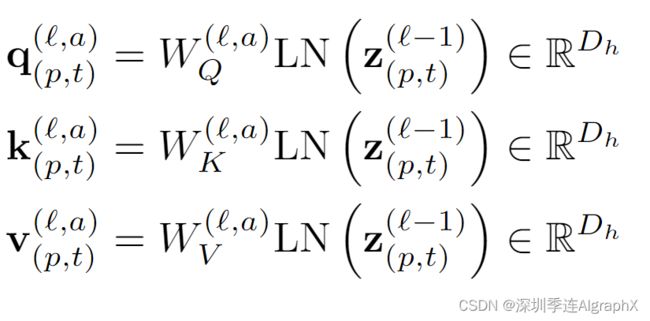
其中 LN() 表示 LayerNorm, = 1, . . . ,
= 1, . . . ,  是多头注意力的索引, 表示注意力头的总数。每个注意力头的维数设置为 Dh = D/a。
是多头注意力的索引, 表示注意力头的总数。每个注意力头的维数设置为 Dh = D/a。
Self-attention computation
自注意力权重通过点积计算。查询每个patch的自注意力权重 (黑体)由下式给出
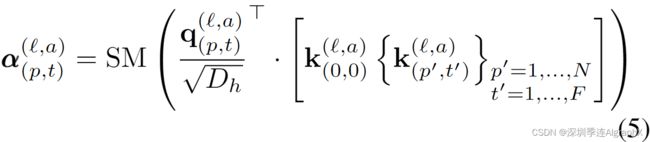
其中SM表示softmax激活函数。注意,当仅在一个维度上计算注意力时(例如,仅在空间上或仅在时间上),计算量会显著减少。例如,在空间注意力的情况下,只进行N+1个查询关键字比较,只使用与查询相同帧的关键字。
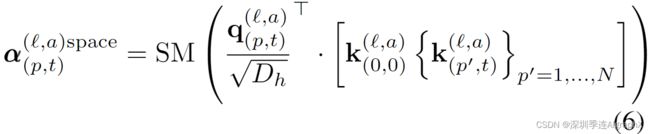
Encoding
首先使用每个注意力头的自注意力系数,计算value向量的加权和,得到encoding块 L 处的编码 Z。
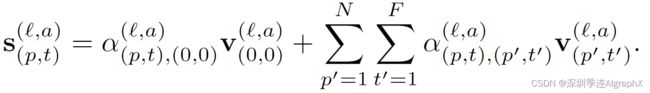
然后经过投影、MLP。
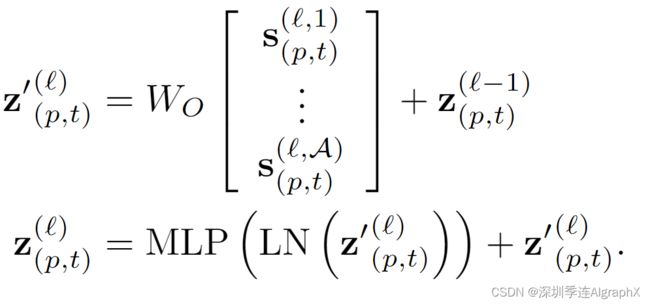
Classification embedding
最终clip enbedding是从分类token最后块中获得。
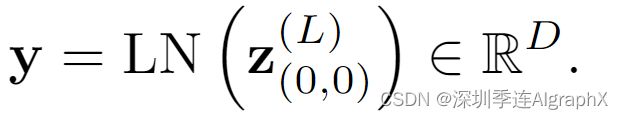
在这种表示之上,我们附加了一个1-hidden-layer MLP,用于预测最终的视频类。
Space-Time Self-Attention Models
我们可以通过将方程5的时空注意力替换为每帧内的空间注意力来降低计算成本(方程6)。但是,这样的模型忽略了捕获跨帧的时间依赖关系。如我们的实验所示,与全时空注意相比,这种方法导致分类精度下降,特别是在需要强大的时间建模的基准上。
我们提出了一种更有效的时空注意力架构,称为“时空分割注意力”(用T+S表示),其中时间注意力和空间注意力分别应用。该架构与下图中的空间和联合时空注意力的架构进行了比较。
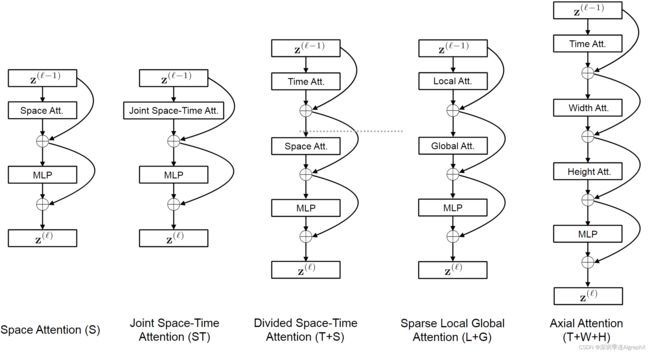
Divided Space-Time Attention(时空分割注意力机制T+S),对于分割注意力模型(T+S),模型学习了不同的 query/key/value 矩阵,分别覆盖时间和空间维度。
先应用时间注意力机制,对每一帧的同一位置的patch计算attention(时间注意力关注的是时间上的变化,即同一位置不同帧t之间的关系)。
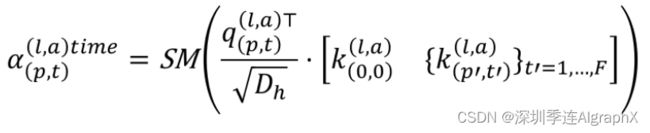
再应用空间注意力机制,对同一帧的不同patch计算attention空间注意力关注的是空间上的变化,即同一帧不同位置p之间的关系。
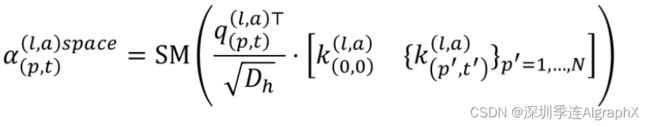
与联合时空注意力模型每个 patch 需要的 (NF + 1)次比较相比,分割注意力仅进行每个patch (N+F+2)次比较,作者发现,分开的时空注意力机制效果要好于联合使用的时空注意力机制。
下面来看注意力机制是如何运作的。
下图给出了视频示例中不同注意力模型的可视化。图中蓝色的图像块是query的图像块,其余颜色的图像块是每个自注意力策略使用到的图像块。没有颜色的图像块没有被使用到策略中,有多种颜色的图像块代表注意力机制是分开进行的,比如T+S就是先T后S,L+G也是同理。注意,这里图中只展示了三帧,但是作用在整个序列上的。通过对输入图像进行分块,本论文中一共研究了五种不同的注意力机制。1)空间注意力机制S,只取同一帧内的图像块进行自注意力机制。2)时空共同注意力机制S+T,需所有帧中的所有图像块进行注意力机制。3)分开的时空注意力机制T+S,先对同一帧中的所有图像块进行自注意力机制,然后对不同帧中对应位置的图像块进注意力机制。4)吸收局部全局注意力机制L+G,先利用所有针中相邻的H和W的图像块计算局部的注意力,然后在空间上使用两个图像块的布长在整个序列中计算自注意力机制,这个可以看作全局的时空注意力以更快的近似。5)轴向的注意力机制T+W+H。先在时间维度上进行自注意力机制,然后在纵坐标相同的图像块上行自注意力机制,最后在横坐标相同的图像块上进行自注意力机制。
Experiments
我们在四个流行的动作识别数据集上对TimeSformer进行了评估:Kinetics-400、Kinetics-600、Something-SomethingV2和Diving-48。我们采用在ImageNet-1K或ImageNet-21K预训练的“基础”上的ViT架构,如每个实验所规定的。除非另有说明,否则我们使用大小为8×224×224的剪辑,帧的采样率为1/32。patch大小为16×16像素。在推理过程中,除非另有说明,否则我们在视频中间采样一个时间片段。我们使用时间片段中的3个空间裁剪(左上、中、右下),并通过对这3个剪裁的得分进行平均来获得最终预测。
Analysis of Self-Attention Schemes
对于第一组实验,我们从在ImageNet-21K上预训练的ViT开始。在表中,我们给出了在K400和SSv2上使用TimeSformer获得的五个提出的时空注意力方案的结果。首先,我们注意到只有空间注意力(S)的TimeSformer在K400上表现良好。这是一个有趣的发现。事实上,先前的工作已经表明,在K400上,为了实现较强的准确性,空间线索比时间信息更重要。在这里,我们表明,在没有任何时间建模的情况下,可以在K400上获得可靠的精度。然而,请注意,仅关注空间在SSv2上表现不佳。这强调了在后一个数据集上进行时间建模的重要性。
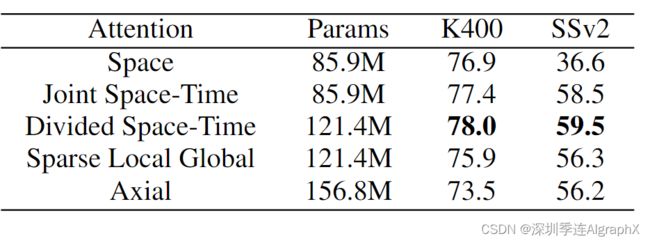
此外,我们观察到,分割的时空注意力在K400和SSv2上都达到了最佳的准确性。这是有道理的,因为与联合时空注意力相比,分割时空注意力具有更大的学习能力(见上表),因为它包含时间注意力和空间注意力的不同学习参数。
当使用更高的空间分辨率(左)和更长的视频(右)时,我们还比较了联合时空注意力与分割时空注意力的计算成本。我们注意到,在这两种情况下,分割时空的方案都能很好地扩展。相反,当分辨率或视频长度增加时,联合时空注意力的方案导致显著更高的成本。在实践中,一旦空间帧分辨率达到448像素,或者一旦帧数增加到32,联合时空注意力就会导致GPU内存溢出,因此它实际上不适用于大帧或长视频。因此,尽管有更多的参数,但当在更高的空间分辨率或更长的视频上操作时,分割时空注意力比联合时空注意力更有效。因此,对于所有后续实验,我们使用由分割的时空自注意块构建的TimeSformer。
Comparison to 3D CNNs
在本小节中,我们进行了一项实证研究,旨在了解TimeSformer与3D卷积架构相比的区别特性,3D卷积架构是近年来视频理解的主要方法。我们将比较重点放在两个3D CNN模型上:1)SlowFast(这是视频分类中最先进的;2)I3D,它已被证明受益于基于图像的预训练,与我们自己的模型类似。我们在表中对这两个网络进行了定量比较,并强调了以下关键观察结果。
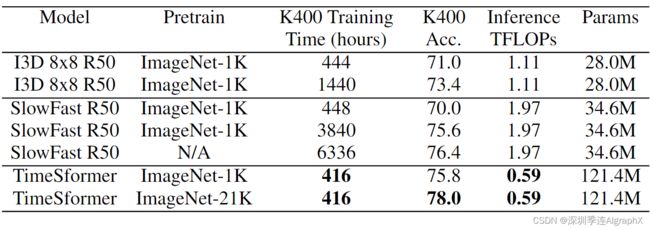
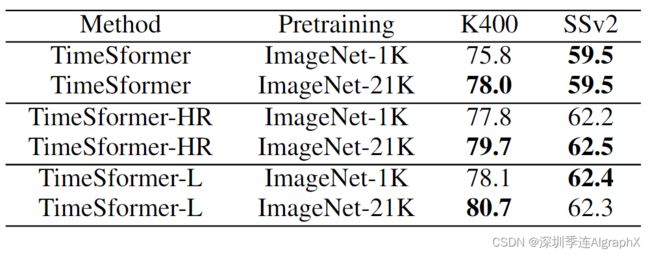
从Model Capacity,Video Training Time,The Importance of Pretraining,The Impact of Video-Data Scale进行了比较。
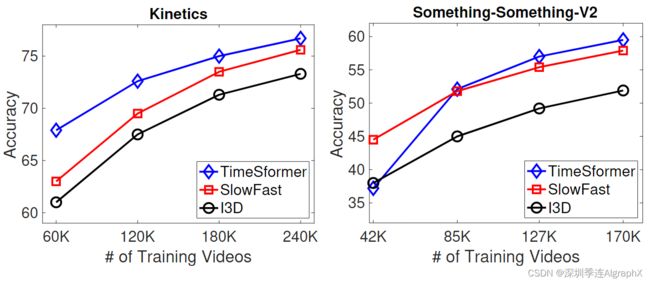
Varying the Number of Tokens
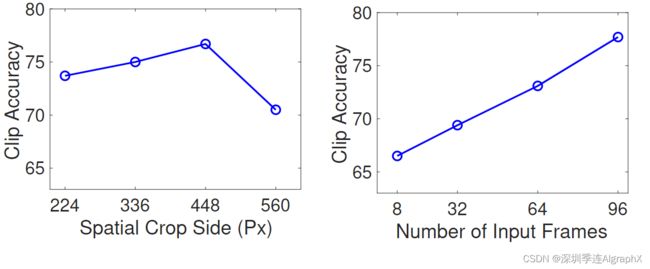
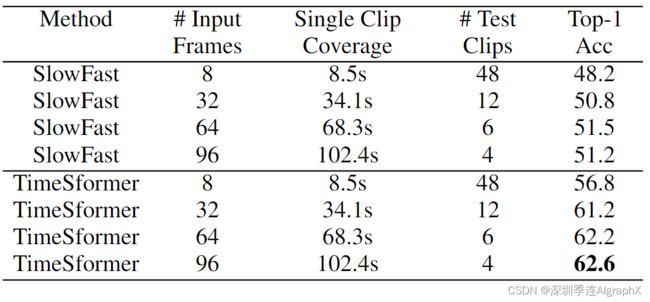
与大多数3DCNN相比,我们模型的可扩展性使其能够在更高的空间分辨率和更长的视频上运行。我们注意到,这两个方面都会影响提供给Transformer的token序列的长度。具体地说,增加空间分辨率导致每帧更高数量的patch(N)。当使用更多的帧时,输入token的数量也会增加。我们进行了一项实证研究,在这两个轴上分别增加token的数量。
我们在下图中报告了研究结果。我们看到,提高空间分辨率(达到一定程度)会提高性能。类似地,我们观察到,增加输入片段的长度会导致一致的精度增益。由于GPU内存限制,我们无法在超过96帧的剪辑上测试我们的模型。尽管如此,我们还是想指出,使用96帧的剪辑与当前的卷积模型有很大的不同,后者通常仅限于处理8−32帧的输入。
The Importance of Positional Embeddings
为了研究我们学习的时空位置嵌入的重要性,我们还对TimeSformer的一些变体进行了实验,这些变体使用:1)无位置嵌入,2)仅空间位置嵌入,以及3)时空位置嵌入。我们在表4中报告了这些结果。基于这些结果,我们观察到,使用时空位置嵌入的模型变体在Kinetics-400和Something-Something-V2上都产生了最佳精度。有趣的是,我们还观察到,在Kinetics-400上使用仅限空间的位置嵌入会产生可靠的结果,但在Something-Something-V2上会产生更糟糕的结果。这是有道理的,因为Kinetics-400在空间上更偏向,而SomethingSomething-V2需要复杂的时间推理。

Comparison to the State-of-the-Art
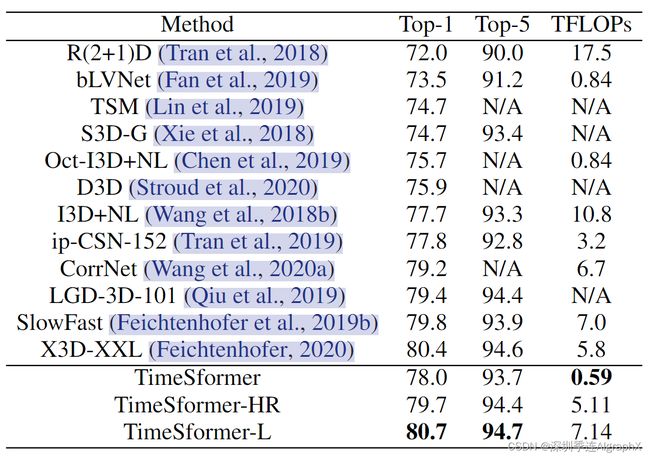
K400数据集
K600数据集
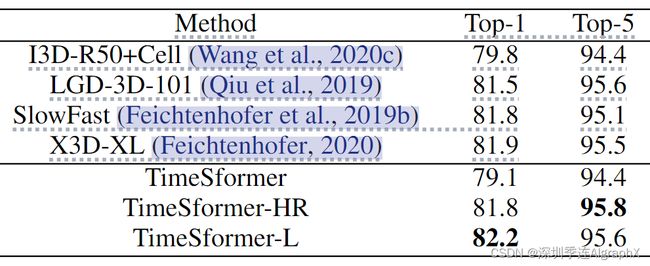
SSv2和Diving-48数据集
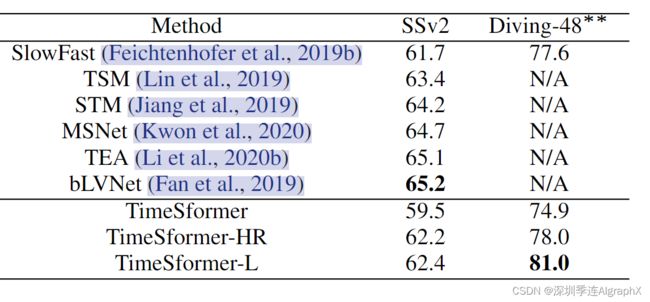
Long-Term Video Modeling
我们首先注意到,对于相同的单剪辑覆盖率,TimeSformer以8-11%的大幅度优于相应的SlowFast。我们还观察到,较长范围的TimeSformer做得更好,即,我们的最长范围变体实现了最佳的视频级分类精度。这些结果表明,我们的模型非常适合需要长期视频建模的任务。
Additional Ablations
Smaller & Larger Transformers
除了ViT基础模型之外,我们还试验了large ViT。报告说,在 Kinetics-400 和 Something-Something-V2 上的结果都差了 1%。鉴于基础模型已经有 121M 个参数,我们怀疑当前的数据集还不够大,不足以证明进一步增加模型容量的合理性。我们还尝试了“小型”ViT变体,其精度比我们默认的“基本”ViT模型差约5%。
Larger Patch Size
我们还试验了不同的patch大小,即P=32,结果比使用P=16的默认变体差约3%。我们推测,P=32时性能的下降是由于空间粒度的减小。我们没有训练任何P值低于16的模型,因为这些模型的计算成本要高得多。
The Order of Space and Time Self-Attention
研究了颠倒时空注意力的顺序(即先应用空间注意力,然后应用时间注意力)是否会对结果产生影响。首先应用空间注意力,然后应用时间注意力会导致Kinetics-400和Something-Something-V2的准确率下降0.5%,平行时空比采用“分时空注意力”方案相比,它的准确率降低了0.4%。
Qualitative Results
Visualizing Learned Space-Time Attention
在图7中,我们展示了通过在Something-Something-V2视频上应用TimeSformer获得的时空注意力可视化。为了使学习到的注意力可视化,我们使用了注意力滚动方案。结果表明,TimeSformer学习关注视频中的相关区域,以执行复杂的时空推理。例如,我们可以观察到,模型在可见时关注手的形状,而在不可见时仅关注这个对象。

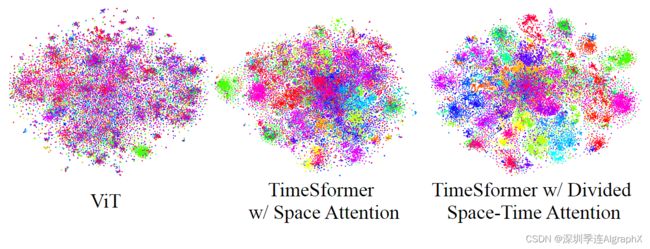
Visualizing Learned Feature Embeddings
我们还可视化了TimeSformer在Something-Something-V2上学习到的特征。可视化是使用t-SNE完成的,其中每个点表示单个视频,不同的颜色描绘不同的动作类别。基于这一说明,我们观察到具有划分的时空注意力的TimeSformer比具有仅空间注意力或ViT的TimeSformer在语义上学习到更多的可分离特征。
Conclusion
TimeSformer,这是一种与基于卷积的视频网络的既定范式截然不同的视频建模方法。我们展示了设计一个有效的、可扩展的视频架构是可能的,它完全建立在时空自我关注的基础上。我们的方法1)概念简单,2)在主要动作识别基准上获得了最先进的结果,3)具有较低的训练和推理成本,4)可以应用于超过一分钟的视频剪辑,从而实现长视频建模。未来,我们计划将该方法扩展到其他视频分析任务,如动作定位、视频字幕和问答等。
原论文地址 https://arxiv.org/abs/2102.05095