tritonserver学习之一:triton使用流程
tritonserver学习之二:tritonserver编译
tritonserver学习之三:tritonserver运行流程
tritonserver学习之四:命令行解析
tritonserver学习之五:backend实现机制
1、triton环境搭建
1.1 docker安装
以Ubuntu为例:
curl -fsSL https://test.docker.com -o test-docker.sh
sudo sh test-docker.sh1.2 下载tritonserver镜像
当前最新版本tritonserver镜像为23.12,对应的cuda版本为12,低版本无法运行,拉取镜像命令:
sudo docker pull nvcr.io/nvidia/tritonserver:23.12-py3client镜像:
sudo docker pull nvcr.io/nvidia/tritonserver:23.12-py3-sdk1.3 下载trtionserver源码
github地址:
https://github.com/triton-inference-server/server下载命令:
git clone --branch r23.12 https://github.com/triton-inference-server/server
git clone --branch r23.12 https://github.com/triton-inference-server/third_party
git clone --branch r23.12 https://github.com/triton-inference-server/backend
git clone --branch r23.12 https://github.com/triton-inference-server/core
git clone --branch r23.12 https://github.com/triton-inference-server/commonserver代码下载,也可以使用以下命令:
git clone --branch v2.41.0 https://github.com/triton-inference-server/server1.4 下载测试模型
进入目录:server-2.41.0/docs/examples,比如:
cd study/triton/server-2.41.0/docs/examples/
./fetch_models.sh模型下载成功后,创建了以下目录:
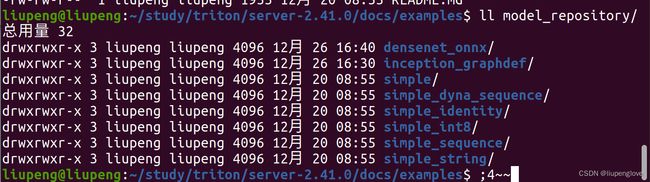
1.5 安装nivida docker
添加nvidia docker源:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list安装源:
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit重启docker:
sudo systemctl restart docker配置容器:
sudo nvidia-ctk runtime configure --runtime=containerd
sudo systemctl restart containerd验证安装是否完成:
sudo docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi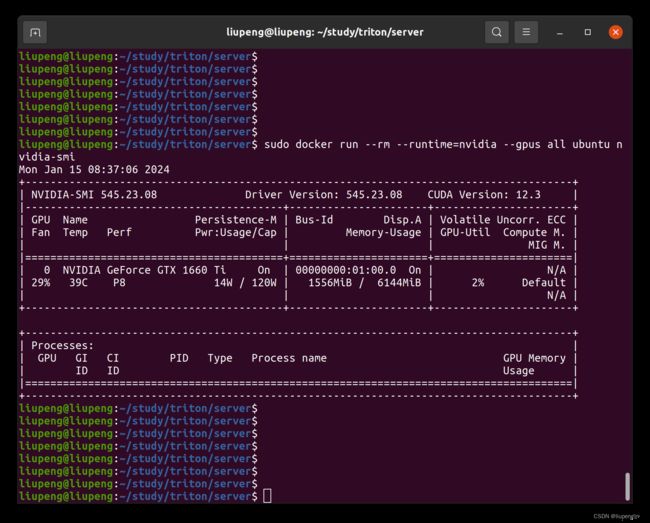
具体可以参考:Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit 1.14.3 documentation
2、运行triton
cpu版本:
sudo docker run --rm -p8000:8000 -p8001:8001 -p8002:8002 -it -v /home/liupeng/study/triton/server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:23.12-py3gpu版本:
sudo docker run --gpus=1 --rm -p8000:8000 -p8001:8001 -p8002:8002 -it -v /home/liupeng/study/triton/server/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:23.12-py3进入镜像后,启动triton:
tritonserver --model-repository=/models进入client镜像,测试tritonserver推理。
sudo docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:23.12-py3-sdk通过client客户端,请求tritonserver,默认是请求本地的tritonserver服务:
/workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg返回:
root@liupeng:/workspace# /workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg
Request 0, batch size 1
Image '/workspace/images/mug.jpg':
15.349563 (504) = COFFEE MUG
13.227461 (968) = CUP
10.424893 (505) = COFFEEPOT