Hadoop-MapReduce-跟着日志理解整体流程
一、数据准备
vi input_01.txt
vi input_02.txt
vi input_03.txt
文本内容如下:
-----------------input_01.txt----------------
java scala python
c++ java js
go go vba
c c c++
java scala python
php css html
js java java scala vba
c# .net
R R R java
-----------------input_02.txt----------------
vba java css
Perl css js
Swift c++ c++
go
php python
-----------------input_03.txt----------------
R Swift scala
python java java css js
html c# vba Perl
.net
查看输入文件大小
二、数据上传HDFS
hadoop fs -mkdir /input
hadoop fs -put input_*.txt /input
hadoop fs -du -h /input
三、运行示例wordcount
cd $HADOOP_HOME/share/hadoop/mapreduce
启动
hadoop jar hadoop-mapreduce-examples-2.7.0.jar wordcount /input /output
[hhs@minganrizhi-3 mapreduce]$ hadoop jar hadoop-mapreduce-examples-2.7.0.jar wordcount /input /output
24/01/16 15:19:52 INFO input.FileInputFormat: Total input paths to process : 3 //有3份输入文件
24/01/16 15:19:53 INFO mapreduce.JobSubmitter: number of splits:3 //分片数量为3
24/01/16 15:19:53 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1704362364978_0007 //提交作业
24/01/16 15:19:53 INFO impl.YarnClientImpl: Submitted application application_1704362364978_0007 //如果ApplicationMaster状态是NEW,NEW_SAVING,SUBMITTED(新创建,正在保存,已提交)中的一种则开始提交应用24/01/16 15:19:53 INFO mapreduce.Job: The url to track the job: http://minganrizhi-3:8088/proxy/application_1704362364978_0007 //作业进度信息的URL
24/01/16 15:19:53 INFO mapreduce.Job: Running job: job_1704362364978_0007
24/01/16 15:19:58 INFO mapreduce.Job: Job job_1704362364978_0007 running in uber mode : false //作业没有在uber模式下运行(所谓uber模式是指ApplicationMaster不另外申请容器,而是将MapTask、ReduceTask以线程的方式在ApplicationMaster所在容器运行。)
24/01/16 15:19:58 INFO mapreduce.Job: map 0% reduce 0%
24/01/16 15:20:02 INFO mapreduce.Job: map 33% reduce 0%
24/01/16 15:20:03 INFO mapreduce.Job: map 100% reduce 0%
24/01/16 15:20:06 INFO mapreduce.Job: map 100% reduce 100%//上述进度是默认1000ms打印一次(当作业状态为PREP时会跳过不打印)可以通过mapreduce.client.progressmonitor.pollinterval修改间隔打印时间,在生产中调整此值可能会导致不需要的客户端-服务器流量。)
24/01/16 15:20:07 INFO mapreduce.Job: Job job_1704362364978_0007 completed successfully //作业成功完成
24/01/16 15:20:07 INFO mapreduce.Job: Counters: 49
File System Counters //本地文件和HDFS文件操作统计
FILE: Number of bytes read=379
FILE: Number of bytes written=475079
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=534
HDFS: Number of bytes written=100
HDFS: Number of read operations=12
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters //Job 相关统计
Launched map tasks=3 //map任务数量
Launched reduce tasks=1 //reduce任务数量
Data-local map tasks=3 //map任务和数据在同节点的map任务数量
Total time spent by all maps in occupied slots (ms)=8711
Total time spent by all reduces in occupied slots (ms)=2613
Total time spent by all map tasks (ms)=8711//map任务消耗时间
Total time spent by all reduce tasks (ms)=2613//reduce任务消耗时间
Total vcore-seconds taken by all map tasks=8711
Total vcore-seconds taken by all reduce tasks=2613
Total megabyte-seconds taken by all map tasks=8920064//8711*1024
Total megabyte-seconds taken by all reduce tasks=2675712//2613*1024
Map-Reduce Framework
Map input records=18 //map输入有18行数据
Map output records=54 //map输出有54行
Map output bytes=450 //map输出字节数
Map output materialized bytes=391
Input split bytes=300 //输入分片大小
Combine input records=54
Combine output records=36 //Combine对map输出进行合并
Reduce input groups=16 //reduce输入有16个不同的key
Reduce shuffle bytes=391 //reduce从map所在容器读了391字节数据
Reduce input records=36 //reduce输入有36行
Reduce output records=16 //reduce输出有16行
Spilled Records=72 //溢写文件行数
Shuffled Maps =3 //reduce从3个map读数据
Failed Shuffles=0
Merged Map outputs=3 //reduce从3个map合并数据
GC time elapsed (ms)=227 //GC工作消耗的时间
CPU time spent (ms)=2330 //CPU工作消耗的时间
Physical memory (bytes) snapshot=1002934272 //获取进程树中所有进程使用的常驻集大小(rss)内存。
Virtual memory (bytes) snapshot=8946356224 //获取进程树中所有进程使用的虚拟内存。
Total committed heap usage (bytes)=721420288 //Java虚拟机中的内存总量
Shuffle Errors //Shuffle 阶段没有出错
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=234 //正好是input_01.txt、input_02.txt、input_03.txt文件大小总和
File Output Format Counters
Bytes Written=100 //输出结果文件大小,下面有截图
从控制台日志中我们可以看到
1、文件系统(本地和HDFS)的读写统计
2、job相关的统计数据
3、MapReduce计算框架的统计数据
4、Shuffle 错误数据统计
5、输入输出统计
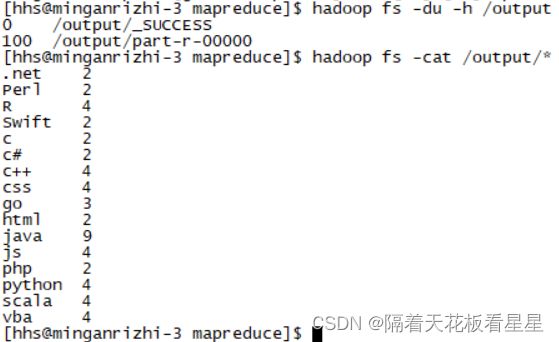
四、查看结果
hadoop fs -du -h /output
hadoop fs -cat /output/*
五、下载yarn日志
yarn logs -applicationId application_1704362364978_0007 > wordcount_yarn.log
可以已经上传到百度网盘,对照着往下学习更具体哟
链接: https://pan.baidu.com/s/1qkdbDsqXq6g6Uto6s0JD_g 提取码: pvqd
六、分析yarn日志
整体上可以看到一共有5个Container
Container: container_1704362364978_0007_01_000001 on minganrizhi-1_33301
===============================================================
......
Container: container_1704362364978_0007_01_000002 on minganrizhi-1_33301
===============================================================
......
Container: container_1704362364978_0007_01_000003 on minganrizhi-3_46754
===============================================================
......
Container: container_1704362364978_0007_01_000004 on minganrizhi-3_46754
===============================================================
......
Container: container_1704362364978_0007_01_000005 on minganrizhi-3_46754
===============================================================
......
从编号上我们可以看出,yarn一共给我们分配了5个Container,这5个Container分别在minganrizhi-1、minganrizhi-3节点上,且Container编号格式为:container_job编号_序号
我们再细心的观察下可以发现
container_1704362364978_0007_01_000001 上运行的是ApplicationMaster
container_1704362364978_0007_01_000002 ~ 4 上运行的是3个MapTask
container_1704362364978_0007_01_000005 上运行的是ReduceTask
考虑到有些同学会利用空余学习(地铁上、厕所里...),不方便一边看日志一边看文章,下面我附上几张截图方便同学们学习
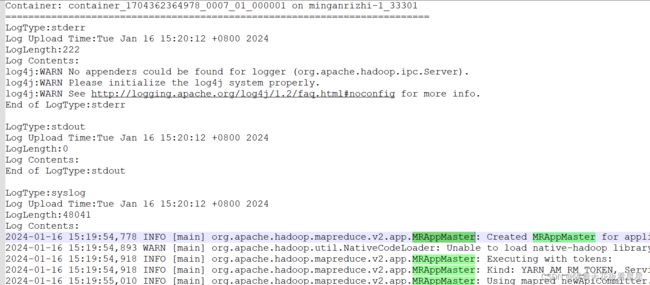
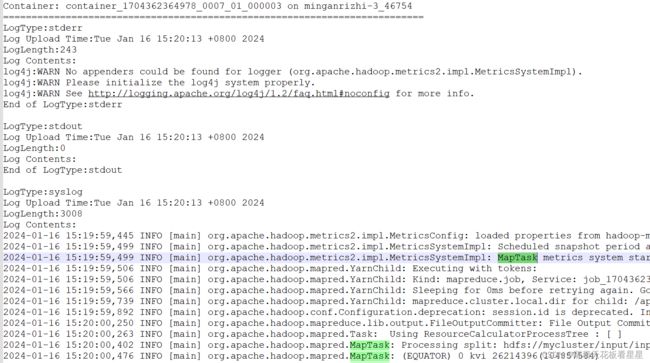
下面我们逐个看看每个角色在各自容器都做了什么
1、ApplicationMaster
1.1、创建 MRAppMaster 服务(Map Reduce应用程序母版,MR AppMaster是松散耦合服务的组合。服务之间通过事件进行交互。这些组件类似于Actors模型。该组件对接收到的事件进行操作,并将事件发送到其他组件。事件由中央调度机制进行调度。所有组件都注册到Dispatcher。使用AppContext在不同组件之间共享信息。)
1.2、初始化并启动ApplicationMaster
1.3、初始化并启动指标统计系统(从 hadoop-metrics2.properties 加载 度量指标配置)
1.4、开始job,但不启动(判断是否启用小型作业“ubertask”优化,如果开启就不用申请另外的容器了,所有的任务将在当下容器运行)
1.5、创建MapTask,但是不启动(但此时统计了输入数据的大小以及分片数量,因此MapTask数量也已经确定)
1.6、创建ReduceTask,但是不启动(已经计算完ReduceTask数量)
1.7、所有组件启动后,启动作业
1.8、机架感知
1.9、与ResourceManager交互,申请容器(为MapTask申请3个容器)
1.10、将jvm和尝试MapTask关联 (在ApplicationMaster申请的容器中运行的Task被称为尝试任务,如果失败会启动新的容器再次运行,尝试任务运行完毕后,相对应的任务也会被更新为完成)
1.11、MapTask运行
1.12、MapTask全部完成
1.13、机架感知
1.14、与ResourceManager交互,申请容器(为ReduceTask申请1个容器)
1.15、将jvm和尝试ReduceTask关联
1.16、ReduceTask运行
1.17、Shuffle (从三个MapTask所在容器拉取数据)
1.18、MapTask所在的容器被ApplicationMaster杀掉
1.19、ReduceTask完成
1.20、更改Job状态为完成
1.21、JobHistoryEventHandler程序处理HDFS上该作业的相关临时文件,并为该作业生成History url
1.22、删除YARN为该作业分片的临时目录
1.23、停止相关服务,并中断任务心跳处理
2、MapTask
2.1、启动MapTask度量系统(从 hadoop-metrics2.properties 加载 度量指标配置)
2.2、配置本地目录(在节点本地创建一个用于作业存放数据的目录)
2.3、任务初始化
2.4、处理分片 (hdfs://mycluster/input/input_03.txt:0+60 、hdfs://mycluster/input/input_01.txt:0+121、hdfs://mycluster/input/input_02.txt:0+53 可以发现每个文件的偏移量都是该文件的字节大小,因为每个文件都只有一个块)
2.5、MapTask中wordcount程序实现的map方法开始处理数据
2.6、计算分区数量
2.7、开始刷新map输出(溢写、排序、合并)
2.8、MapTask完毕
3、ReduceTask
3.1、启动MapTask度量系统(从 hadoop-metrics2.properties 加载 度量指标配置)
3.2、配置本地目录(在节点本地创建一个用于作业存放数据的目录)
3.3、任务初始化
3.4、fetching Map Completion Events 获取map完成事件
3.5、开始Shuffle(启动 map 输出提取器线程,Fetcher 是 Shuffle 启动线程的实现类 )
3.6、从日志上开得到了3个map-outputs
3.7、释放Shuffle线程
3.8、从日志上可以看到,内存中有3份map-outputs、磁盘上有0份map-outputs
3.9、开始排序、合并map-outputs
3.10、MapTask中wordcount程序实现的reduce方法开始处理数据
3.11、将ReduceTask的输出保存到HDFS临时目录(hdfs://mycluster/output/_temporary/1/task_1704362364978_0007_r_000000)
3.12、ReduceTask完毕