【提效】让GPT帮你写爬虫程序,不懂爬虫也能行
文章目录
-
- 1. 详细操作步骤
- 2. 总结
我的爬虫背景:基本小白,只知道网页的代码大概长啥样,但是css之类的完全不懂。在这样的背景下,我使用GPT帮我完成了爬虫程序。所以本文比较 适合爬虫小白。大神请绕道 ~
下面来看操作步骤。以 GitHub的 Trending页面(https://github.com/trending)为例,我们的目标是爬取出Trending列表中的项目名称、url、简介、start数等信息。
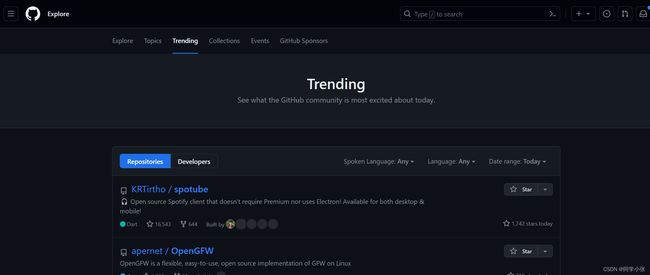
1. 详细操作步骤
(1)打开网页,F12快捷键打开网页调试界面,可以看到网页的元素
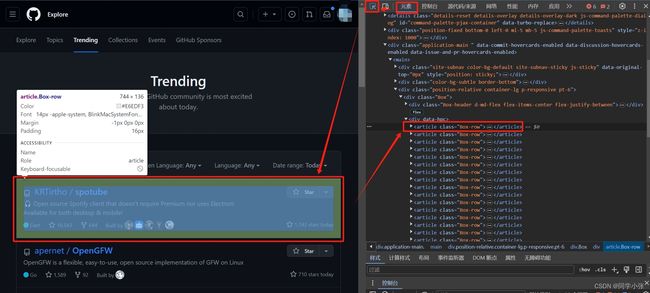
(2)如上图,在调试窗口,选“元素”选项卡,可以看到页面元素
(3)点击调试窗口左上角带小箭头的那个图标,点击后在左侧页面中鼠标停留的地方会捕捉当前位置的元素。
(4)如图中我们选择一个仓库的信息,可以在右侧对应看到这个仓库信息对用的元素代码是 Box-row。这就是与我们想要的数据相关的信息。
(5)给大模型提示时,我们选取两个Box-row元素就可以。在调试窗口中元素上右键 —> 复制 —> 复制元素,粘贴到本地一个新建的 .html 文件中。
- 为什么要用.html文件粘贴?因为vscode打开后,在OUTLINE中可以看到结构。
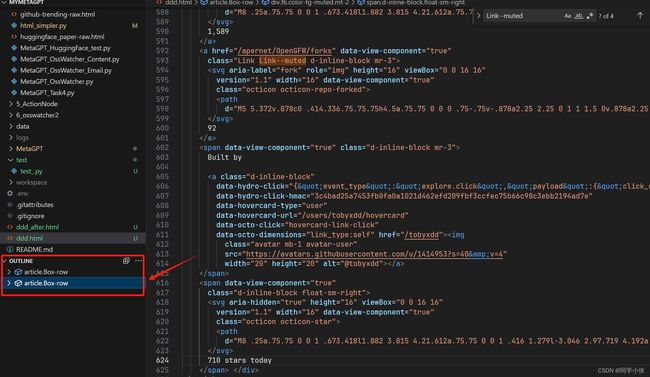
(6)可以看到全部复制下来后,元素非常多,给大模型时没必要这么多,一是给这么多的元素也会超出大模型的token限制,二是给很多没用的元素会干扰大模型给出正确答案。我们通过下面的代码对Html内容进行精简(不用懂原理,直接用就行,通用的,这个代码的作用是挑选出Html中的css元素,用css元素足以定位html里的元素)
from bs4 import BeautifulSoup
with open("D:\GitHub\MyMetaGPT\ddd.html") as f: ## 这里改成你粘贴下来的元素的html文件
html = f.read()
soup = BeautifulSoup(html, "html.parser")
for i in soup.find_all(True):
for name in list(i.attrs):
if i[name] and name not in ["class"]:
del i[name]
for i in soup.find_all(["svg", "img", "video", "audio"]):
i.decompose()
with open("D:\GitHub\MyMetaGPT\ddd_after.html", "w") as f: ## 这里改成你想要的输出文件,可以与上面处理的html文件相同
f.write(str(soup))
经过以上代码瘦身后,原本粘贴下来的html元素由600多行变成了200多行。看下内容,确实精简了不少。
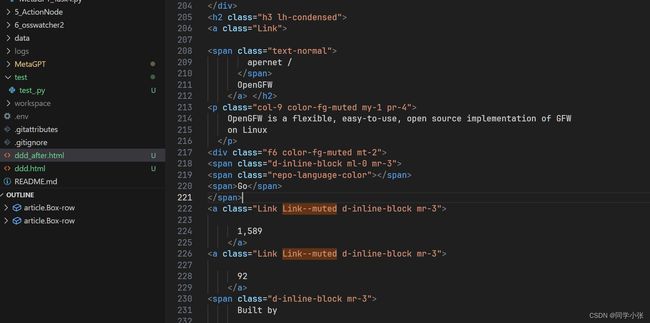
(7)有了数据,就可以问大模型了。Prompt如下:
你是一个精通python的爬虫工程师,需要使用aiohttp爬取https://github.com/trending,然后用BeautifulSoup解析出榜单中的几个字段:仓库名,仓库对应的url,仓库的描述,star数、所对应的语言类型、今日star数
---
{你的网页数据}
运气好的话大模型会给出正确代码。但99%都属于运气不好的,需要不断引导大模型修正代码。下面是我的对话过程(字数太多,就不贴在本文中了,直接上链接,感兴趣的可以参考下)。
https://chat.openai.com/share/f9023b18-f18a-404a-8f72-820f124aca05
(8)大功告成,我们的爬虫程序就写好了。看下最终代码和结果。
- 完整爬虫代码
import aiohttp
import asyncio
from bs4 import BeautifulSoup
async def fetch_github_trending():
url = 'https://github.com/trending'
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
return await response.text()
def parse_github_trending(html):
soup = BeautifulSoup(html, 'html.parser')
articles = soup.find_all('article', class_='Box-row')
for article in articles:
repo_name = article.find('h2').find('a').text.strip()
repo_url = 'https://github.com' + article.find('h2').find('a')['href']
description_element = article.find('p')
repo_description = description_element.text.strip() if description_element else 'N/A'
star_count = article.find_all('a', class_='Link--muted')[0].text.strip().replace(',', '')
language_type_element = article.find('span', class_='repo-language-color')
language_type = language_type_element.find_next('span').text.strip() if language_type_element else 'N/A'
# Get today's star count using a more reliable method
today_star_element = article.find('span', class_='float-sm-right')
today_star_count = today_star_element.text.strip().split()[0] if today_star_element else 'N/A'
print(f"仓库名: {repo_name}")
print(f"仓库URL: {repo_url}")
print(f"仓库描述: {repo_description}")
print(f"Star数: {star_count}")
print(f"语言类型: {language_type}")
print(f"今日Star数: {today_star_count}")
print("-" * 50)
async def main():
html = await fetch_github_trending()
parse_github_trending(html)
if __name__ == '__main__':
asyncio.run(main())
- 运行结果
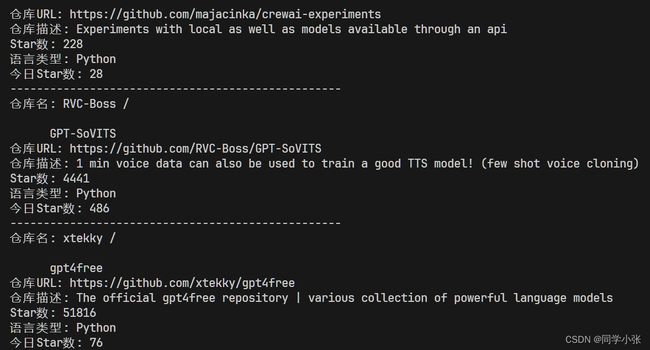
2. 总结
总结下上述主要步骤:
- 首先选取包含想要信息的网页元素,例如上文Box-row,选取1-3个元素即可,粘贴到本地,保存成html文件
- 利用瘦身代码将html瘦身,这一步的作用非常重要:一是避免超出大模型token限制,二是去除一些不必要的干扰信息
- 与大模型对话,得到爬虫程序
看到这,是不是觉得挺简单的?不会爬虫也能写爬虫程序,上面的步骤基本都是体力活。赶快去试试吧!
如果觉得有用,麻烦点个赞和关注呗 ~ 感谢!可+v jasper_8017,一起讨论一起学习进步!