机器学习笔记02:特征工程
机器学习笔记02:特征工程
文章目录
- 机器学习笔记02:特征工程
-
- 1. 特征工程定义
- 2. 数据的特征抽取:
-
-
- 1. 字典特征抽取:
- 2. 文本特征抽取:
- 3. tf-df分析问题
-
- 3.特征预处理
-
-
- 1.特征处理的方法:
-
- 1.数值型数据:标准缩放:
- 2.类别型数据:
- 3.事件类型:
-
- 4.数据降维:
-
-
-
- 1. 特征选择:
- 2. 主成分分析PCA---->降维:
- 3. 特征选择和主成分分析的比较:
-
-
- 5.需要明确的几点问题:
- 6.机器学习基础
-
-
- 1. 数据类型
- 2.机器学习算法分类
-
1. 特征工程定义
- 定义:提高预测效果。是将原始数据转换为更好地代表预测模型的潜在问题的特征的过程,从而提高了对未知数据的模型准确性。
- 工具:scikit-learn库
2. 数据的特征抽取:
针对非连续型数据、对文本进行特征值化。
API:sklearn.feature_extraction
1. 字典特征抽取:
import sklearn
from sklearn.feature_extraction import DictVectorizer
def dictvec():
# 字典数据抽取
# 实例化
dict = DictVectorizer()
#调用fit_transform
data = dict.fit_transform([{'city':'北京','temperature':100},{'city':'上海','temperature':60},{'city':'河北','temperature':30}])
print(data)
return None
if __name__ == "__main__":
dictvec()

这个是sparse矩阵:节约内存,方便读取处理。把它转换为数组,就是在dict = DictVectorizer(sparse = False)

print(dict.get_feature_names())

One-hot编码:避免因为12345678出现的优先级问题,所以只有数字1。
2. 文本特征抽取:
import sklearn
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
cv = CountVectorizer()
data = cv.fit_transform(['life is short,i klike python','life is too long,i dislike python'])
print(cv.get_feature_names())
print(data.toarray()) # 把sparse矩阵换成数组
return None
if __name__ == "__main__":
countvec()

统计文章中所有的词,重复的只统计一次,单个字母并不统计(因为它对文章主题没影响)。
对每个词统计出现的次数。
中文文本怎么办?
import sklearn
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
cv = CountVectorizer()
data = cv.fit_transform(['life is short,i klike python','life is too long,i dislike python'])
data = cv.fit_transform(['人生苦短,我喜欢python','人生漫长,不用python'])
print(cv.get_feature_names())
print(data.toarray()) # 把sparse矩阵换成数组
return None
if __name__ == "__main__":
countvec()


所以中文要进行分词处理:jieba分词
import sklearn
import jieba
from sklearn.feature_extraction.text import CountVectorizer
def cutword():
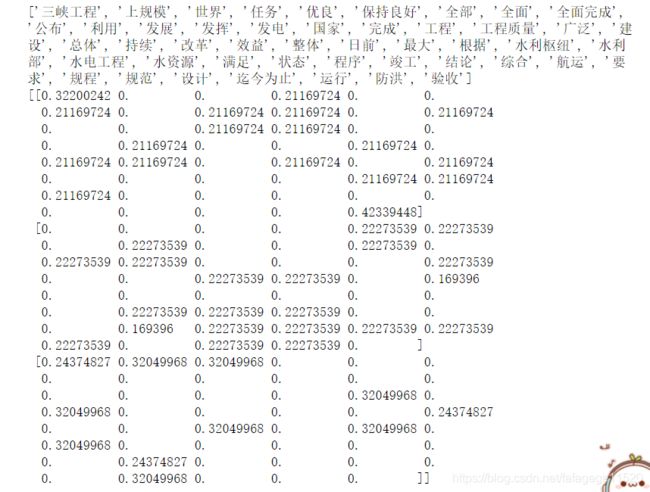
con1 = jieba.cut('水利部、国家发展改革委1日公布,三峡工程日前完成整体竣工验收全部程序。根据验收结论,三峡工程建设任务全面完成')
con2 = jieba.cut('工程质量满足规程规范和设计要求、总体优良,运行持续保持良好状态,防洪、发电、航运、水资源利用等综合效益全面发挥')
con3 = jieba.cut('三峡工程是迄今为止世界上规模最大的水利枢纽工程和综合效益最广泛的水电工程。')
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1,c2,c3
def countvec():
# cv = CountVectorizer()
# data = cv.fit_transform(['life is short,i klike python','life is too long,i dislike python'])
# data = cv.fit_transform(['人生 苦短,我 喜欢 python','人生 漫长,不用python'])
# 中文分词
c1,c2,c3 = cutword()
print(c1,c2,c3)
data = cv.fit_transform([c1,c2,c3])
print(cv.get_feature_names())
print(data.toarray()) # 把sparse矩阵换成数组
return None
if __name__ == "__main__":
countvec()

3. tf-df分析问题
- 每篇文章都会出现的词语:‘我’‘可以‘‘能够’。。。。。
- tfidf:避免了1的发生。tf * idf:重要性程度
- TF:term frequency 词的频率
- IDF:inverse document frequency 逆文档频率:log(总文档数量/该词出现的文档数量)
import sklearn
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
def cutword():
con1 = jieba.cut('水利部、国家发展改革委1日公布,三峡工程日前完成整体竣工验收全部程序。根据验收结论,三峡工程建设任务全面完成')
con2 = jieba.cut('工程质量满足规程规范和设计要求、总体优良,运行持续保持良好状态,防洪、发电、航运、水资源利用等综合效益全面发挥')
con3 = jieba.cut('三峡工程是迄今为止世界上规模最大的水利枢纽工程和综合效益最广泛的水电工程。')
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1,c2,c3
def tfidfvec():
tf = TfidfVectorizer()
# 中文分词
c1,c2,c3 = cutword()
data = tf.fit_transform([c1,c2,c3])
print(tf.get_feature_names())
print(data.toarray()) # 把sparse矩阵换成数组
return None
if __name__ == "__main__":
tfidfvec()
3.特征预处理
通过特定的统计方法,将数据转换成算法要求的数据。
API:sklearn.preprocessing模块
1.特征处理的方法:
1.数值型数据:标准缩放:
- 归一化:
- 特点:通过对原始数据进行变换把数据映射到默认为[0,1]之间。
- 公式:
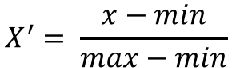
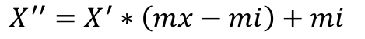
注:作用于每一列,max为一列的最大值,min为一列的最小值,那么X’’为最终结果,mx,mi分别为指定区间值默认mx为1,mi为0 - 目的:多个特征值同等重要的时候,使某一个特征不会对结果造成更大的影响。
- 缺点:易受异常点影响,鲁棒性较差,只适合传统精确小数据场景,一般不用。
- 鲁棒性:反应稳定性的一个词。
import sklearn
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler
def mm():
# 归一化处理
mm = MinMaxScaler(feature_range=(2,3))
data = mm.fit_transform([[90,2,10,40],[60,4,15,45],[75,3,13,46]])
print(data)
return None
if __name__ == "__main__":
mm()

- 标准化:适合目前嘈杂的大数据的现状
- 特点:通过对原始数据进行变换把数据变换到均值为0,标准差为1范围内。
- 公式:
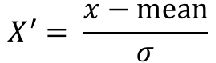


- 方差:数据分散方差较大,数据集中方差较小。
- 对于归一化来说:如果出现异常点,影响了最大值和最小值,那么结果显然
会发生改变 - 对于标准化来说:如果出现异常点,由于具有一定数据量,少量的异常点对
于平均值的影响并不大,从而方差改变较小。
import sklearn
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
def stand():
# 标准化缩放
std = StandardScaler()
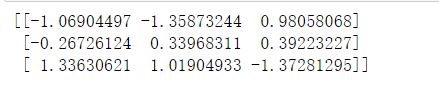
data = std.fit_transform([[1.,-1.,3.],[2.,4.,2.],[4.,6.,-1.]])
print(data)
return None
if __name__ == "__main__":
stand()
- 缺失值处理:删除或插补(按列)。
np.nan是float类型
import sklearn
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import Imputer
import numpy as np
def im():
# 缺失值处理
im = Imputer(missing_values = 'NaN',strategy = 'mean',axis = 0) # 0是列
data = im.fit_transform([[1,2],[np.nan,3],[7,6]])
print(data)
return None
if __name__ == "__main__":
im()

2.类别型数据:
见字典
3.事件类型:
后面结合具体案例再学习。
4.数据降维:
- 维度:指的是特征的数量,不是数组的维度。
1. 特征选择:
- 特征选择:
是单纯地从提取到的所有特征中选择部分特征作为训练集特征,特征在选择前和选择后可以改变值、也不改变值,但是选择后的特征维数肯定比选择前小,毕竟我们只选择了其中的一部分特征。- 原因:
冗余:部分特征的相关度高,容易消耗计算性能
噪声:部分特征对预测结果有负影响 - 主要方法:
Filter(过滤式):Variance(方差)Threshold
Embedded(嵌入式):正则化、决策树
神经网络 - Filter(过滤式):从方差大小考虑
- 原因:
import sklearn
import jieba
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MinMaxScaler
from sklearn.feature_selection import VarianceThreshold
def var():
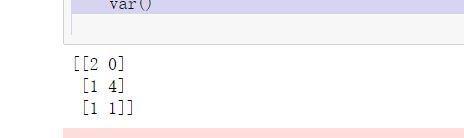
var = VarianceThreshold(threshold=0.0)
data = var.fit_transform([[0,2,0,3],[0,1,4,3],[0,1,1,3]])
print(data)
return None
if __name__ == "__main__":
var()
2. 主成分分析PCA---->降维:
- PCA:当特征数量达到上百之后,考虑数据的简化。不仅仅是删除数据,还会更改数据。
- 目的:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
- 高维度数据容易出现的问题:特征之间通常是线性相关的
- 原理没必要掌握比较难。
# 主成分分析
import sklearn
from sklearn.decomposition import PCA
def pca():
pca = PCA(n_components=0.9) # 这个参数可以是整数也可以是百分数
data = pca.fit_transform([[2,8,4,5],[6,3,0,8],[5,4,9,1]])
print(data)
return None
if __name__ == "__main__":
pca()

- 案例:
#案例1:想把用户分为几个类别
import sklearn
from sklearn.decomposition import PCA
import numpy as np
import pandas as pd
# 读取四张表的数据
prior = pd.read_csv('/data/ins')
products = pd.
orders =
aisles =
# 合并到一张表
_mg = pd.merge(prior,products,on = ['products_id','products_id'])
_mg = pd.merge(_mg,orders,on = ['order_id','order_id'])
mt = pd.merge(_mg,aisles,on = ['aisle_id','aisle_id'])
# 交叉表(特殊的分组工具)
cross = pd.crosstab(mt['user_id'],mt['aisles'])
#进行主成分分析
pca = PCA(n_components=0.9)
data = pca.fit_transform(cross)
3. 特征选择和主成分分析的比较:
5.需要明确的几点问题:
- 算法是核心,数据和计算是基础。
- 找准定位:自己是应用还是创造~
6.机器学习基础
1. 数据类型
离散型数据(分类)和连续型数据(回归)。(字面意思较好理解)
2.机器学习算法分类
- 监督学习:有特征值+目标值
分类 k-近邻算法、贝叶斯分类、决策树与
随机森林、逻辑回归、神经网络
回归 线性回归、岭回归
标注 隐马尔可夫模型 (不做要求) - 非监督学习:只有特征值
聚类 k-means - 开发流程:
- 数据:公司本身就有、合作过来的、购买的数据
- 建立模型:明确问题做什么
- 数据的基本处理:pd处理缺失值、合并表等等
- 特征工程:对特征进行处理
- 找到合适的算法进行预测
- 模型评估:判定效果
- 上线使用,以API形式提供