后门防御阅读笔记,GangSweep: Sweep out Neural Backdoors by GAN
论文标题:GangSweep: Sweep out Neural Backdoors by GAN
论文单位:Old Dominion University,Norfolk, VA, USA
论文作者:Liuwan Zhu,Rui Ning,Cong Wang
收录会议:ACM MULTIMEDIA 2020
开源代码:https://github.com/nicholasbennet/neural-network-backdoor-removal
GangSweep:通过GAN去“扫出“神经后门(防御)
简单总结
第一篇使用GAN去检测和识别后门攻击的防御算法
-
先前的防御只能检测和识别带有一个后门的中毒模型,即当一个模型存在着多个后门,只能检测出其中一个。
-
场景:后门模型可能存在多个触发器的场景,并且只能通过查询访问模型(类似黑盒场景)和一小组清洁标签验证数据
-
针对防御的攻击方法:BadNets,Trojaning Attack, Hidden Trigger Backdoor
-
==核心:利用GAN去重构每个可能的目标类对应的扰动掩码(逆向触发器)。==具体方法是,使用需要判断是否存在后门的模型作为判别器,生成器为生成一个扰动掩码(触发器)的自动编码器,判别器的参数固定,更新生成器的参数即可,使用了判别器的输出对生成器的训练进行干预(体现在生成器的损失函数上)。对于每一个可疑的标签,都要训练一个生成器,因此N个标签,即有N个生成器。
-
本文其他方法都是在重构得到的触发器基础上,结合NC进行推广,该论文的核心就是GAN构造的逆向触发器效果非常好,作者用了两个角度进行切入分析了GAN为什么比NC的方法效果好。
-
数据流形的角度
基于梯度的方法(指NC所用的BIM)在高维的数据流形和 L 2 L2 L2范数边界的限制扰动下自然地追求一个对抗的方向,但由于真实数据(以及触发器)仍然保持在低维流形上,GAN通过对抗性学习直接恢复了这些artifacts。换句话说,因为GangSweep中的生成器类似于自动编码器,所以它提取输入图像的特征并将其压缩为低维。由此,GAN可以在接近干净数据流形的小潜在空间中产生扰动掩模,从而更好的代表的触发特性。
-
误差曲面的局部or全局最小值
通过对生成的误差曲面进行分析,NC得到一个很大的平面极小值。因此,给定一个随机起点,基于梯度的方法将快速收敛到平面上的一个随机点。当只有一个触发器时,它可以工作,但在处理多触发器场景时性能很差,在多触发器场景中,触发器被映射到大平面上的不同区域。一旦它到达平面,损失接近于零,梯度下降消失,从而停止优化。因此,恢复的触发器很可能只有一个,而不是全部。相反,GangSweep会导致一个形状良好的损失景观,特别是在多触发场景中,因此更有可能在训练期间达到全局最小值。
-
-
检测后门和缓解后门
- 检测后门
- 揭示了GAN产生的扰动掩码(逆向触发器)是具有持久性,并且在特征空间中表现出具有小转换方差和大转换距离的有趣统计特性。
- 持久性指的是一张图片生成的扰动掩码应该在另外一张同一个类别的图片上也可以触发后门。
- 小转换方差指的是输入图片和加上扰动掩码(某标签对应的生成器)的图片分别在后门模型输出的logits的方差,越小说明该标签越可能是恶意的。
- 大转换距离指的是输入图片和加上扰动掩码(某标签对应的生成器)的图片分别在后门模型输出的logits的最大值的差,越大说明该标签可能是恶意的。
- 利用上面的特性设计了检测后门的算法
- 揭示了GAN产生的扰动掩码(逆向触发器)是具有持久性,并且在特征空间中表现出具有小转换方差和大转换距离的有趣统计特性。
- 缓解后门
- 利用构造的触发器和一小部分干净的验证集微调原模型
- 检测后门
值得做的点(仅从本文出发)
- 参考之前的动态感知的后门攻击,那里的自动编码器类似于本文的生成器,然后可以尝试设计一个特别的判别器,简单来说,是否可以借助GAN的特性去训练一个生成更加鲁棒的触发器的生成器呢?
- 该方法的检测机制里面,有一个持久性的定义,即一张图片生成的扰动掩码应该在同类的另外一张图片上也可以触发后门,但显然,这个检测是防御不了动态感知的后门攻击,我们可以重新迭代升级该方法去防御目前最新型的攻击手段。
abstract
- 这项工作提出了GangSweep,一个新的后门检测框架,利用生成对抗性网络(GAN)的超级重建能力来检测和“扫出”神经后门。
- 揭示了GAN产生的扰动掩码是持久的,并且在特征空间中表现出具有小移位方差和大移位距离的有趣统计特性。
- 与以前的解决方案相比,所提出的方法消除了对训练数据访问的依赖,并显示出高度的鲁棒性和效率,以检测和减轻大部分的各种设置下的后门模型。
1.introduction
- 对于开发人员和最终用户来说,大规模训练自己的模型往往是负担不起的。 相反,大多数用户求助于第三方例如“机器学习作为一种服务”(MLaaS)或重新使用线上免费开放的模型。因此,这带来了种种安全问题,例如后门攻击。
- 攻击的隐身源于模型权重的不透明和无法解释的性质,这使得通过简单地窥视数百万浮点权重参数来识别是不可行的。但是,已经有部分相关工作开展了对这一系列后门攻击的检测和识别。
- 为了建立一个稳健的防御,作者提出了一种新的方法,称为GangSweep。 不是使用掩码通过梯度优化捕获后门触发器,而是利用生成对抗性网络(GAN)的超级重建能力检测并“扫出”所有的神经后门。
主要贡献
-
使用生成网络通过有效地重建目标类周围的流形来挖掘神经后门的基本弱点,并揭露攻击者为成功攻击而植入的所有artifacts。
-
作者发现目标标签的触发器在特征空间中表现出一些具有低移位方差和大移位距离的有趣统计特性。 提出了一种有效的离群点检测机制,可以明确区分触发器和普通对抗性扰动。
-
作者进行了广泛的实验,以表明该防御是有效的。对3种最先进的后门木马攻击,通过不同数量、不同模式和不同大小的触发器,跨越5个数据集,进行了防御测试。 这个机制可以检测和减缓所有这样的触发器组合,而不仅仅只对检测单个、小尺寸和不变触发器有效。
2.related work
三种后门攻击
后面测试防御需要使用
- BadNets
- Trojaning Attack
- Hidden Trigger Backdoor Attacks
一些先前的防御手段
这些防御手段存在着一些弊端,目标函数过于复杂,收敛慢;需要访问干净的训练数据。
- Neural Cleanse
- Activation Clustering
- Fine-Pruning
3.threat model
-
作者考虑了后门模型可能存在多个触发器的场景,后门可以通过以下两种设置被激活:(1)多个触发器中的任何一个(2)多个触发器的任意组合。 后门模型将带有触发器的输入错误地分类到目标标签上,同时在干净的输入上正常执行。
-
防御者只能访问模型和一小组干净的验证数据(不能访问训练数据或训练过程)。防御者的目标首先是检测后门标签,然后根据恢复的触发图像来减缓后门。
4.GANGSWEEP
GangSweep主要包括下面3个阶段
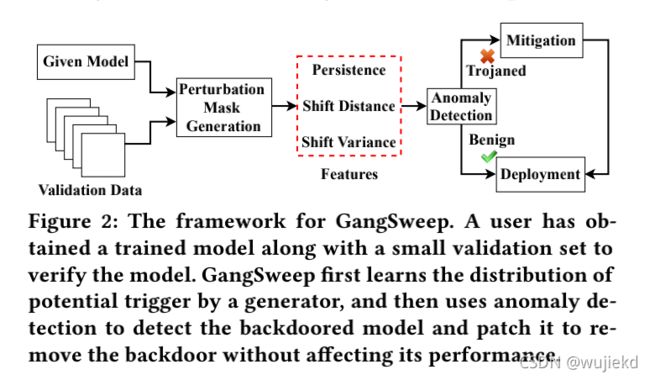
-
Perturbation Mask Generation
设计了一个生成网络,它可以为输入图像生成一个扰动掩码,从而将其错误地分类为目标标签。对于给定的DNN,我们假设模型被回溯,并枚举每个标签作为一个假设的目标标签来生成扰动掩码。
-
Malicious Model Detection
采取扰动掩码的特征,并使用离群点检测算法来判断是否有一个持久的、通用的扰动掩码(触发器)导致将所有图像错误分类为目标标签。 如果存在这样的掩码,模型被认为是恶意的,并且掩码本质上恢复了用于训练后门的原始触发器。
-
Backdoor Mitigation
利用恢复的触发器来移除后门,而不影响干净数据的性能。
4.1 扰动掩码生成器
-
触发器和目标类周围流形的关系
后门的攻击是通过在干净的图像印上一个触发器激活后门来构造的。 触发器通常很小,以使攻击隐身。对抗样本通常将样本从数据流形上推出,然而,后门植入过程被纳入训练中,因此目标类周围的流形是从触发图像中学习的。
-
GAN的原理
GAN企图找到一个未知的数据分布。判别器的目的是将真实数据与生成器生成的(伪造的)数据分开,而生成器则试图通过生成真实数据来欺骗判别器。 随着游戏的进行,生成器隐式地学习未知分布。
-
作者提出的方法和Neural Cleanse的区别
因为防御者不知道攻击者攻击的目标标签是什么,因此目标标签周围的分布也是未知的。Neural Cleanse最小化损失函数,以匹配生成的掩码与假定的触发器。虽然它可以暴露一个单一的触发器,但它探索其余的大多数未知分布是无效的,仍可能存在着其他触发器。为此,作者扩展了GAN的生成能力来学习这种未知分布,从而完全恢复攻击者植入的所有后门。
(1)提出的GAN结构
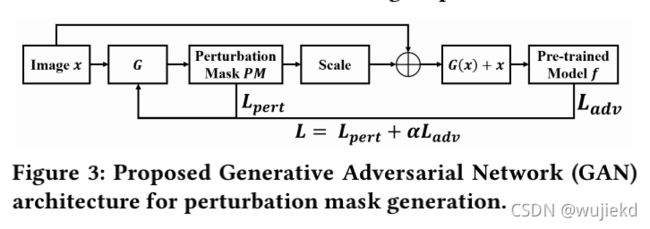
G G G是生成器(基于ResNet结构), f f f是后门模型
可以看到 f f f模型的参数是固定的,只需要更新生成器 G G G的参数,这里使用了判别器的输出 L a d v L_{adv} Ladv对生成器的训练进行干预,下面给出了新定义的目标函数:

其中Font metrics not found for font: .是超参数,平衡了扰动的大小和对抗性攻击成功率之间的重要性。 _{} Lpert控制了扰动的可感知性,而 _{} Ladv用于优化所生成的对抗性扰动的攻击成功率。在生成器训练的第一次迭代中,作者根据经验让Font metrics not found for font: .= 2来鼓励错误分类。在下一个迭代中,将根据和进行动态更新:
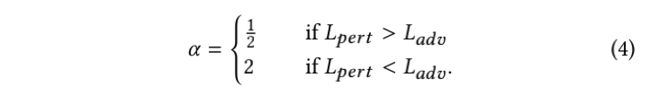
-
训练
对于一个给定DNN f f f和一个图像验证集,假设每个标签都可能是目标标签,因此使用该图像验证集对每个标签分别训练一个生成器 G G G。
-
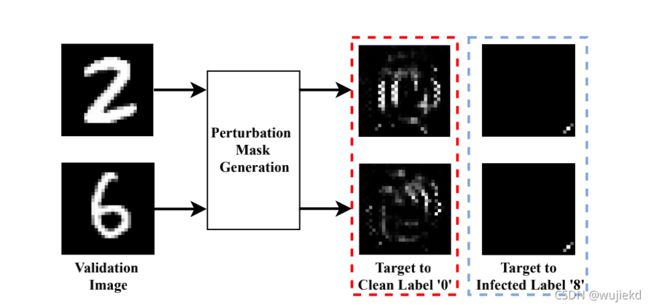
测试
将验证集的图片分别输入各个标签对应的生成器,可以看到输出的mask的效果,如下图所示,真正目标标签对应的生成器输出的mask和真实的触发器几乎非常相似。
(2)深入了解基于GAN的mask生成
-
深入了解GAN体系结构产生的扰动掩码与传统的优化或基于梯度的方法之间的区别,例如L-BFGS, Carlini and Wagner Attack (C&W),用于Neural Cleanse的基于迭代梯度的方法(BIM)。
使用以上的方法在一个提前构建好的后门模型上进行,可以看到当使用传统的方法时,为两幅图像生成的mask由随机像素扰动组成,并且有很大的不同,但GAN生成了类似真实触发器的mask。

- 从数据流形的角度进行深入了解
实验表明,虽然所有的方法都是针对后门模型上的“鹿”标签,但基于梯度的方法在高维的数据流形和0.1的 L 2 L2 L2范数边界的限制扰动下自然地追求一个对抗的方向。
由于真实数据(以及触发器)仍然保存在低维流形上,GAN通过对抗性学习直接恢复了这些artifacts。换句话说,因为GangSweep中的生成器类似于自动编码器,所以它提取输入图像的特征并将其压缩为低维。由此,GAN可以在接近干净数据流形的小潜在空间中产生扰动掩模,从而更好的代表的触发特性。这也部分地解释了为什么这种神经元木马(在流形上)不能单独工作。它通过调整模型权重来共同发挥作用。
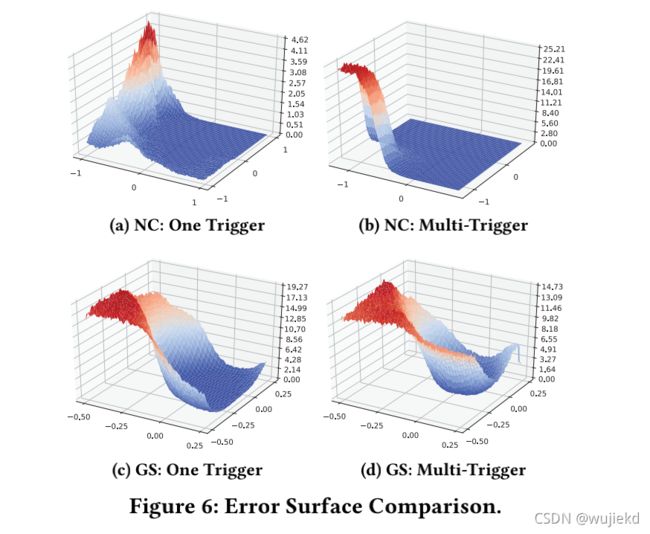
- 从误差曲面的局部or全局最小值进行深入了解
为了对GangSweep (GS)和Neural Cleanse (NC)之间的掩模生成有更深入的了解,我们采用引入的方法来近似误差曲面,而反向工程通过不同的方法触发误差曲面。如上图所示,NC得到一个很大的平面极小值。因此,给定一个随机起点,基于梯度的方法将快速收敛到平面上的一个随机点。当只有一个触发器时,它可以工作,但在处理多触发器场景时性能很差,在多触发器场景中,触发器被映射到大平面上的不同区域。一旦它到达平面,损失接近于零,梯度下降消失,从而停止优化。因此,恢复的触发器很可能只有一个,而不是全部。相反,GangSweep会导致一个形状良好的损失景观,特别是在多触发场景中,因此更有可能在训练期间达到全局最小值。
对比了单触发和多触发场景下的GangSweep和NC,如下图所示,跟上述描述一致。图7©显示了一个更复杂的触发器场景,其中攻击者将攻击过程多样化,为图像均匀地随机放置左下角或右下角的触发器。事实上,这是一个更强大的攻击,攻击成功只需要预先放置一个触发器即可攻击成功。正如我们所看到的,只要在培训过程中内置了触发因素,GangSweep就可以完全暴露这两者。另一方面,NC被多样化的触发器产生严重误导,在完全不同的位置只产生一个单一的掩模。

4.2后门模型检测
两个Observation
上面的讨论已经证明了基于Gan的a方法可以基于输入图像生成(恢复)扰动掩码,这样它就会被错误地分类到后门模型的目标类中。那么其他的图像呢?生成的扰动掩模是保持不变还是完全不同?为此,作者提出以下几点看法。
Observation 1
Persistence: 后门模型中目标标签的扰动掩码(触发器)在不同的输入图像中保持持久
作者提出了一种评价是否持久的方法:

一张干净图像 ∈ X ∈X x∈X,加上同类其它干净图像 _ xc生成的扰动掩模,输入后门模型,如果输出目标标签 t对应的概率很高,就表明该扰动掩码很可能是一个触发器。(这里在本文中规定了同一类,同一个类别的图片可以导致一个等价的转换,这其实在GAN的生成器的训练可以体现,我认为也可以从不同原始类所处的流形位置不一样去解释)
Observation 2
在后门模型中,目标标签的扰动掩码(触发器)在特征空间中表现出较低的shifting variance和较大的shifting distance。
-
shifting variance
将()定义为干净图像的logits向量,并将(+())定义为生成的对抗样本的logits向量。对于一个干净的标签,产生的扰动掩码在其输出特征向量上表现出更多的多样性。这一发现与以往的研究表明,虽然扰动是偏离流形的,但它们的模式依赖于数据流形来优化,并将“欺骗性特征”用于误分类(我的理解是这里生成的扰动偏离了原图像的数据流形,但目标标签对应的数据流形和触发器对应的数据流形会更加相近)这激励作者推导出shift variance of the logits:Font metrics not found for font: .,其中 ′ = + ( ) '=+() x′=x+G(x)和 ( ⋅ ) (·) var(⋅)表示 和 ′ 和' x和x′的logits向量之间的方差。
-
shifting distance
干净标签和目标标签的扰动掩模在特征空间中表现出不同的移动距离。具体地说,我们将定义shifting distance:Font metrics not found for font: .,中 m a x ( ⋅ ) max(·) max(⋅)表示logits向量的最大值。从后门生成的扰动掩模显示了向目标标签的强烈移动(即),而干净标签的掩模移动距离通常很小,仅仅是为了确保错误分类。
-
下图显示了一个基于GTSRB基准的示例。图8(a)中右下角的红点表示目标标签的扰动掩模(移动方差较小,移动距离较大),与干净标签的扰动掩模有明显区别。

后门检测算法
-
Persistence
给定一个DNN模型及其验证数据集,我们从每个类中随机选择一组图像。 基于每幅图像,我们生成它的微扰掩码,目标是所有可能的输出标签,除了图像的实际标签。 对于每个目标标签,图像用来自同一类的其他图像生成的不同扰动掩码印章,然后输入DNN模型,以评估攻击是否成功,即错误分类到目标标签。 我们将攻击成功率定义为“持久性”。如果它高于阈值,作者认为它是一个潜在的恶意标签。 在作者的实现中,阈值是90%,接下来将讨论。
-
Anomaly Index
如果识别出潜在的恶意模型,我们使用图像和先前生成的掩码来测量shifting variance和shifting distance。 然后运行离群点检测算法(这个离群点算法和NC里面提到的MAD算法一致),以检测特定标签的扰动掩码是否具有强的和相似的shifting patterns。 如果结果是阳性,即判断该标签被感染。
-
给出完整算法伪代码

4.3后门缓解
一旦检测到后门模型,可以通过模型修补来缓解后门,即使用一个新数据集来微调后门DNN模型,该数据集包括一小部分(小于10%)的验证数据和(10%)的对抗数据。注意,对抗数据是通过将生成的扰动掩码印在干净的验证图像上并将其标记为原始的、正确的标签来获得的。相对于使用Neural Cleanse的原始训练数据集,该方法不需要访问原始训练数据,也不需要访问实际对抗数据。
5.EVALUATION
- 实验数据集:: MNIST, GTSRB, CIFAR10, VGG-FACE, Mini ImageNet
- 测试的后门攻击: BadNets,TrojanNN, and Hidden Trigger Backdoor
- 比较的防御方法:Neural Cleanse (NC)
前面的方法已经介绍的非常详细,如若复现,再具体察看实现细节~