淘宝用户购物行为数据可视化
1、 流量分析:PV/UV是多少,通过分析PV/UV能发现什么规律?
PV是指页面浏览量或点击量,用户每次请求则被计算一次。
UV是指访问您网站的一台电脑客户端为一个访客。00:00-24:00内相同的客户端访问只被记录为一次。
按天进行PV、UV和PV/UV值的计算
计算PV
data['date'] = data['time'].astype('datetime64') # 将字符型时间转换为时间型时间
data['day'] = data['time'].apply(lambda x : x.split(' ')[0]).astype('datetime64') # 取出时间中,天的部分数据
data['day'].value_counts().sort_index().head() # 按照时间进行分组计数,sort_index是为了对时间进行排序
计算UV
UV = data.groupby(['day','user_id']).count() # 按照天和用户id进行分组计数,得到的索引就是我们要的数据
UV = .reset_index(['user_id','day']) # 重置索引
UV = UV['day'].value_counts().sort_index() # 再按照天进行分组计数即可得到UV
计算PV/UV
把上面两个代码相除即可
plt.figure(figsize=(20,6),facecolor='#fff',dpi = 300) # 定义画布,长宽为20×6,背景颜色为白色,清晰度为300,dpi越高导出的图片文件越大,也越清楚
#绘制PV图像
plt.plot(data['day'].value_counts().sort_index().index,
data['day'].value_counts().sort_index().values/100,
c = 'crimson',linewidth = 2)
#绘制UV图像 plt.plot( data.groupby(['day','user_id']).count().reset_index(['user_id','day'])['day'].value_counts().sort_index().index, data.groupby(['day','user_id']).count().reset_index(['user_id','day'])['day'].value_counts().sort_index().values, c = 'teal',linewidth = 2)
#绘制PV/UV的图像
plt.plot(res.index,res.values100,color = 'peru')
plt.legend(['PV','UV','PV/UV'])
plt.xticks(data['day'].value_counts().sort_index().index.tolist()[::4])
plt.show()
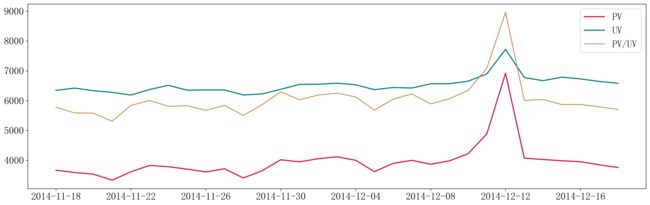
这里为三个指标绘制到同一个画布中,对数据进行了缩放,具体值看代码中。
从图中可知,非促销日的客户流浪量比较稳定,在双十二促销节中突然出现峰值,说明促销活动能够吸引更多的用户进行活动参与。
按小时进行UV、PV和PV/UV值的计算
计算方法和天的一样只不过需要按照小时的纬度进行计算而已
#时间中的小时时间
data['hour'] = data['time'].apply(lambda x : x.split(' ')[1])
按天计算的可视化结果
res1 = data['hour'].value_counts().sort_index()/data.groupby(
['hour','user_id']).count().reset_index(['user_id','hour'])['hour'].value_counts().sort_index()
plt.figure(figsize=(20,6),facecolor='#fff',dpi = 300)
plt.plot(
data['hour'].value_counts().sort_index().index,
data['hour'].value_counts().sort_index().values/100,
c = 'teal'
)
plt.plot(
data.groupby(['hour','user_id']).count().reset_index(['user_id','hour'])['hour'].value_counts().sort_index().index,
data.groupby(['hour','user_id']).count().reset_index(['user_id','hour'])['hour'].value_counts().sort_index().values,
c = 'crimson'
)
plt.plot(res1.index,res1.values100,color = 'peru')
plt.legend(['PV','UV','PV/UV'])
#plt.xticks(data['day'].value_counts().sort_index().index.tolist()[::4])
plt.show()
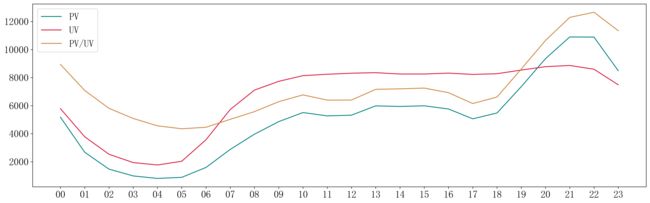
同理,这里的数值也进行了缩放处理。
从图中可知,凌晨期间,各项指标均呈现下降趋势且在3~4点之间处于最小值。在白天时,各项指标较为稳定且高于凌晨的用户访问量。18点之后PV值开始增长,UV值保持不变,PV/UV值也呈现增长趋势,总人数不变,但访问量增加,即同一个人存在多次访问淘宝的情况,说明这个人是商家的重要客户或者是潜在客户。
2 、 漏斗分析:用户“浏览-收藏-加购-购买”的转化率是怎样的?哪一步的折损比例最大?
这里的漏斗按照题目所给的流程进行计算,中途加入的用户不计入结果。(不算中途加入的原因是不了解怎么不进行访问商品页面就对商品进行收藏、加购物车和购买的情况)
计算逻辑:
先计算浏览的人数,即筛选behavior_type = 1的人,按照用户id进行分组计数,并形成pandas后续要用。
其次,在前一步生成的人群中返回到原始数据集筛选出这群人,并且按照behavior_type = 2的人筛选再分组用户id,并再次生成一个pandas为后续使用。
按照这个步骤一直循环到最后一层。
b1 = pd.DataFrame(data[data['behavior_type'] == 1]['user_id'].value_counts().index.tolist())
b1['c'] = 1
b1.rename(columns = {0:'b'},inplace = True)
b2 = pd.DataFrame(data[data['behavior_type'] == 2]['user_id'].value_counts().index.tolist())
b2['c'] = 1
b2.rename(columns = {0:'b'},inplace = True)
print(pd.merge(b1,b2,on = 'b',how = 'left').dropna(axis = 0).shape)
b3 = pd.DataFrame(data[data['behavior_type'] == 3]['user_id'].value_counts().index.tolist())
b3['c'] = 1
b3.rename(columns = {0:'b'},inplace = True)
print(pd.merge(b2,b3,on = 'b',how = 'left').dropna(axis = 0).shape)
b4 = pd.DataFrame(data[data['behavior_type'] == 4]['user_id'].value_counts().index.tolist())
b4['c'] = 1
b4.rename(columns = {0:'b'},inplace = True)
print(pd.merge(pd.merge(b2,b3,on = 'b',how = 'left').dropna(axis = 0),b4,on = 'b',how = 'left').dropna(axis = 0).shape)
b4 = pd.DataFrame(data[data['behavior_type'] == 4]['user_id'].value_counts().index.tolist())
b4['c'] = 1
b4.rename(columns = {0:'b'},inplace = True)
print(pd.merge(pd.merge(b2,b3,on = 'b',how = 'left').dropna(axis = 0),b4,on = 'b',how = 'left').dropna(axis = 0).shape)
可视化结果
import pyecharts.options as opts
from pyecharts.charts import Funnel
x_data = ['浏览','收藏','加购物车','购买']
y_data = [10000,6730,6020,5739]
Data = [[x_data[i], y_data[i]] for i in range(len(x_data))]
c = (
Funnel(init_opts=opts.InitOpts(bg_color='#fff'))
.add(
series_name="",
data_pair=Data,
gap=2,
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a}
{b} : {c}"),
label_opts=opts.LabelOpts(is_show=True, position="inside"),
itemstyle_opts=opts.ItemStyleOpts(border_color="#fff", border_width=1),
)
.set_global_opts(title_opts=opts.TitleOpts(title="", subtitle=""))
#.render("funnel_chart.html")
)
c.render_notebook()

这里计算的是每一层的总人数,如果计算转换率可以用如下公式:(上一层的人数 - 下一层的人数)除以上一层的人数。
从图中可知,用户行为从浏览转到收藏的人群呈现较大幅度的下降,从收藏到加购物车的人群减少得不太明显,从加购车到购买商品的人群有较明显的浮动。
商家或平台应该主要分析浏览到收藏存在较大下降是由于推荐系统不够准确导致用户浏览了自己不太喜欢的东西,还是商品本身不太符合大众的购买意愿等情况。
3、用户价值分析:对电商平台什么样的用户是有价值的?如果你作为商家,要重点关注哪部分用户?
对于商家而言,关注的用户是有可能购买商品的用户,所以目的就是预测用户是否有可能进行购买商品。统计每个用户的浏览、收藏、加购物车和购买的行为情况,如果存在该类行为,则记为1;或者记为0。
基于上面统计得到的数据进行决策树分析,得到如下的分类规则。
模型效果
采用默认参数,随机种子为42。数据集划分为7:3,随机种子为42,模型的准确率为0.886。
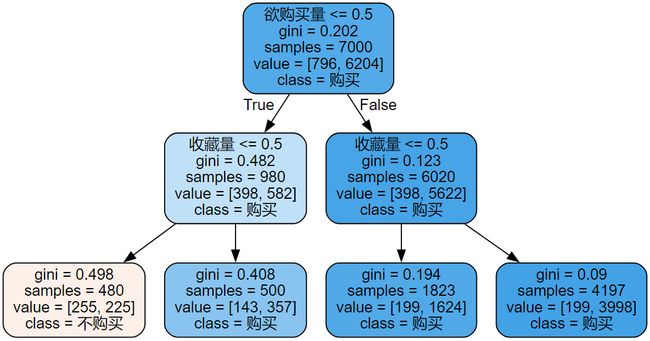
欲购买量即加购物车的行为
从图中可知,存在加购物车行为无论是否收藏该商品的用户都会进行购买。不存在加购物车行为,但存在收藏行为的客户也会购买;而不存在加购物车行为且不收藏行为的客户则大概率不会购买。所以商家主要关注用户是否对某一商品进行加购物车和收藏商品,因为客户可能由于某些因素导致目前无法购买或者缺少购买的契机。
待更!!!!