R语言学习——数据框
x = c(42,7,64,9)
y=1:4
z.df = data.frame(INDEX=y, VALUE=x)
z.df
dim(z.df) # 查看几行几列
colnames(z.df) # 查看列名
rownames(z.df) # 查看行名
z.df[,1]
z.df[1,]
z.df[c(1,2),c(1,2)]
df1 = data.frame(C1=c(1,5,14,1,54), C2=c(9,15,85,9,42), C3=c(8,7,42,8,16))
df1
df2 <- unique(df1) #去除重复
df2
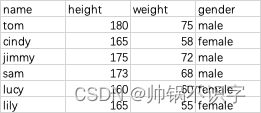
test <- read.csv('/Users/zhangzhishuai/Downloads/13 lesson13 R数据框(一)/dataframe/test.csv', header = T, row.names = 1)
test
test <- read.table('/Users/zhangzhishuai/Downloads/13 lesson13 R数据框(一)/dataframe/test.csv', header = T, sep = ",", row.names = 1)
test
test <- read.table('/Users/zhangzhishuai/Downloads/13 lesson13 R数据框(一)/dataframe/test.txt', header = T, sep = "\t", row.names = 1)
test
test[1,] #提取第一行
test[,2] # 提取第二列
test[,"gender"] #提取特定列
test$height #提取特定列
# 提取身高大于170的人所有信息
test$height > 170
test[test$height > 170,]
# 提取身高大于170的人的所有人体重信息
test$height > 170
test[test$height > 170,'weight']
# 提取身高大于170体重大于70的人的所有信息
test$height > 170 & test$weight > 70 # & 指and
test[test$height > 170 & test$weight > 70,]
# 提取所有男生信息
test$gender == "male"
test[test$gender == "male",]
test[test$gender != "female",] # !=指不等于
# subset函数
subset(test, select = 'height')
subset(test,height>170)
subset(test,height>170,select = c('gender','weight'))
# 男性和女生的平均身高
test$gender=='male'
maleh = test[test$gender=='male','height']
test$gender!='male'
femaleh = test[test$gender!='male','height']
maleh
femaleh
mean(maleh)
mean(femaleh)
tapply(test$height,test$gender,mean) # 使用tapply
t.test(maleh,femaleh) # T检验查看差异显著性
t.test(height~gender,data = test) # T检验查看差异显著性
# 计算男性和女性体重差异
t.test(weight~gender, data = test)
# 计算BMI并添加到表中
bmi = test$weight/(test$height/100)^2
cbind(test,bmi) #第一种添加方法
test$BMI = bmi # 第二种添加方法
write.table(test,'/Users/zhangzhishuai/Downloads/13 lesson13 R数据框(一)/dataframe/bmi_1.txt', sep = '\t', quote = FALSE)
示例文件:
| 
|