Python爬虫—爬取网页视频
开始爬取网页视频第一步
介绍以下现在网页视频大多是流媒体形式播放,将视频分为多个一小段视频为ts文件
我们需要取安装一些爬虫必需一些库以及在这中需要的一些第三方库
requests库是python3中的主要的爬虫库
我们调用win + R ,输入cmd确定,输入以下
pip install requests
Cryto库是用于解码ts文件的库,和上面一样调出系统命令,输入:
pip install cryto
安装好后,这个需要你找到这个库的文件安装位置,将cryto库名首字母改为大写即可
在这里路径可以根据需求进行修改,根据下面指示就可以成功下载
代码运行后,我们需要先观察是ts文件链接是否完整,如果不完整可以根据提示输入
接下来上代码:
#os库,re库,time库 python自带无须安装
import requests
import re #正则库
import time
#Crypto(秘密的).Cipher(密码)库可以用于加密和解密
from Crypto.Cipher import AES #用解密ts文件的库
import os
import winsound #用于调用系统铃声
#获取m3u8文件下的ts文件
def web_m3u8(url,url_ts):
try:
url_m3u8 = url
print('正在下载中~')
time.sleep(1)
print('请稍等')
header = {"user-agent":"选择使用的浏览器"}
res = requests.get(url_m3u8,headers = header)
res.encoding = 'UTF-8'
model = r"[^#\s].*.[ts|key]"
#获取m3u8的密钥模板
model_key = r'[^A-Z-:\s128="URI,].*'
res_content = re.findall(model,res.text)
#用于收集ts链接的列表
list = []
#单独提出key加到第一项
url_i = re.findall(model_key,res_content[0])
#''.join(对象)将元组,列表,转成字符串
url_i = ''.join(url_i)
list.append(url_i)
#将用正则遍历到的所有ts视频链接遍历到列表中
for i in res_content[1:]:
#将每个ts文件的视频下载链接,添加到列表list中
url_i = url_ts + i
list.append(url_i)
print('加载完毕')
return list
except Exception as reason:
print('异常原因:', reason)
#爬取未加密的视频文件,未合并视频
def loadvideo(list,name):
try:
print('正在下载请稍等')
i = 1
for j in list:
header = {"user-agent":
"同上"}
res_1 = requests.get(j, headers = header)
content = res_1.content
path = r"输入存放路径\{0}{1}.ts"
with open(path.format(name,i),'wb') as w:
w.write(content)
print('{0}.下载{1}完成'.format(i,j))
i += 1
print('下载完成')
except Exception as reason:
print('异常原因:' + reason)
#用于下载完成时报警
def sound():
duration = 1000 # 时间单位毫秒
freq = 440 #声音频率单位Hz
winsound.Beep(freq,duration)
#爬取加密的ts视频文件,未合并ts视频文件
def deconde(list,name):
try:
print('正在下载中请稍等')
a = 1
for url in list:
header = {"user-agent":
"同上"}
res_1 = requests.get(url, headers=header)
if url == list[0]:
key = res_1.content
#创建一个解密器对象
cryptor = AES.new(key,AES.MODE_CBC,key)
#下载已经解密的视频格式
with open(r'输入存放路径\{0}{1}.ts'.format(name,a),'ab') as wb:
#用解密对象.decrypt()对文件进行开锁
video = cryptor.decrypt(res_1.content)
wb.write(video)
print('{0}下载{1}完成'.format(a,url))
a += 1
print('完成下载')
except Exception as reason:
print('异常原因:' , reason)
#将多个视频合并到一个视频中
def addvideo(list,name):
try:
variety = input('#腾讯=t#爱奇艺=a#默认=m# >> 选择你想要播放的视频软件:')
print('正在下载请稍等')
i = 1
for j in list:
header = {"user-agent":
"同上"}
res_1 = requests.get(j, headers=header)
content = res_1.content
if variety == 't':
path = r"输入存放路径\{0}"+'.mpg'
elif variety == 'a':
path = r"输入存放路径\{0}"+'.mp4'
elif variety == 'm':
path = r"输入存放路径\{0}"+'.ts'
with open(path.format(name), 'ab') as w:
w.write(content)
print('{0}.下载{1}完成'.format(i, j))
i += 1
print('下载完成')
except Exception as reason:
print('异常原因:' , reason)
#爬取加密的文件并合并
def addcrytovideo(list,name):
try:
print('正在下载中请稍等')
a = 1
for j in list:
header = {"user-agent":
"同上"}
res_1 = requests.get(j, headers=header)
if j == list[0]:
key = res_1.content
# 创建一个解密器对象
cryptor = AES.new(key, AES.MODE_CBC, key)
# 下载已经解密的视频格式
with open(r'输入存放路径\{0}.ts'.format(name), 'ab') as wb:
# 用解密对象.decrypt()对文件进行开锁
video = cryptor.decrypt(res_1.content)
wb.write(video)
print('{0}下载{1}完成'.format(a, j))
a += 1
print('完成下载')
except Exception as reason:
print('异常原因:', reason)
print('注意这中方法只用于ts文件加密和未加密文件类型')
url = input('请输入m3u8链接:')
choice = input('是否需要下载吗?(否/要)')
list = web_m3u8(url,'')
#获m3u8的ts文件链接
if choice == '要':
name = input('请输入影片名称:')
cryto = input('是否未加密类型(否/是)')
add_url = str(input('你可以根据m3u8链接文件情况添加链接:(不需要添加空格+回车)'))
list = web_m3u8(url, add_url)
if cryto == '是':
#未加密方法
addcrytovideo(list, name)
sound()
else:
#加密方法
addvideo(list,name)
sound()
else:
#返回一个ts文件链接的列表
print(list)
例子:
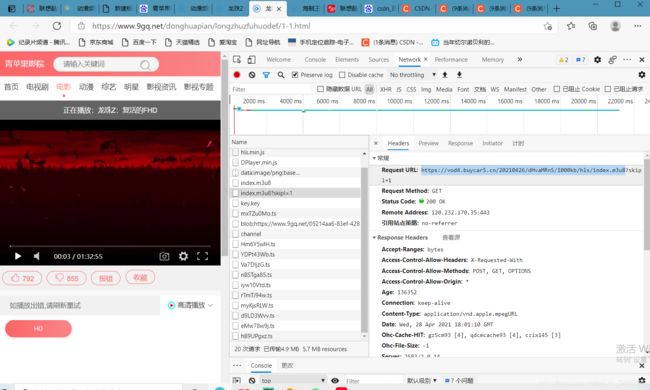

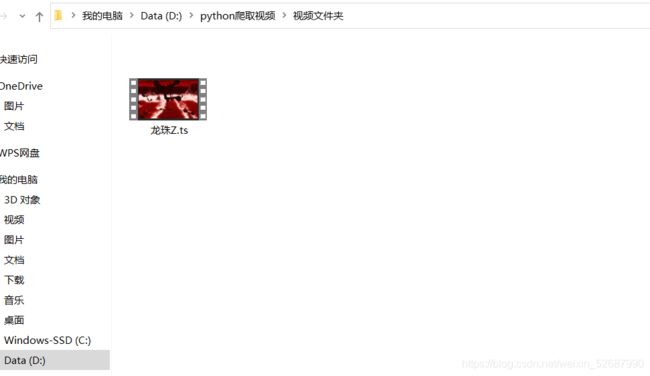
在代码中还有两个函数未用到,大家可以根据需要自己去使用
作为一个刚学python爬虫的我来说,还有很多地方需要改进,还有一些知识暂时为未涉及,不过”路漫漫其修远兮,吾将上下而求索“
那就先这样吧,下次见 ,bye~