#AIGC##LLM##RAG# RAG:专补LLMs短板_减少LLM幻觉并多模态/RAG 技术最新进展
RAG技术,即检索增强生成,标志着自然语言处理领域的重大进展。通过整合先前知识,它提升了大型语言模型的性能,广泛应用于多模态领域和垂直行业。本文深入探讨了RAG技术的演进历程、技术发展、LLMs问题及其解决方案,为读者提供了对这一前沿技术的全面理解。
RAG 与 LLMs
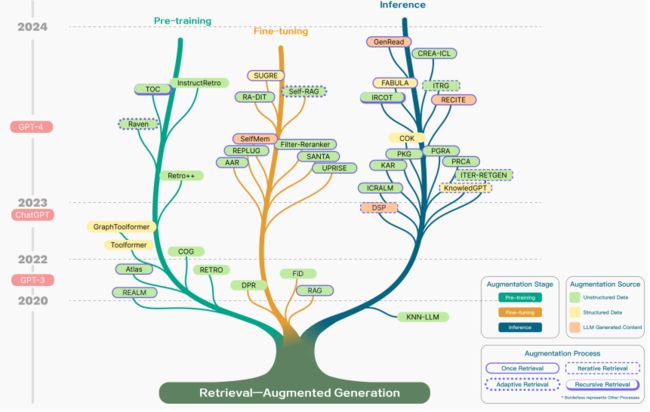
RAG 演进历程
RAG 技术的演进历程可以分为几个关键阶段,总结如下:
- 预训练阶段: RAG 概念首次于2020年提出,初期研究侧重于如何通过预训练模型注入额外知识,以增强语言模型的能力。这个阶段旨在使模型能够更好地利用先前的知识。
- ChatGPT时代: 随着ChatGPT的出现,对于运用大型模型进行深层次上下文学习的兴趣激增。这推动了 RAG 技术在研究领域的快速发展,引入了更复杂的上下文学习。
- LLMs潜力的开发: 随着大型语言模型(LLMs)潜力的进一步开发,研究开始关注如何提升模型的可控性,以满足不断演变的需求。RAG 技术逐渐转向增强推理能力,并尝试在微调过程中引入各种改进方法。
- GPT-4时代: GPT-4的发布标志着 RAG 技术的深刻变革。研究重心转向一种新的融合 RAG 和微调策略的方法,同时持续关注对预训练方法的优化。这一阶段旨在进一步提高模型的性能和适应性。
总体而言,RAG 技术从提出到今天经历了多个关键阶段,不断演化和改进,以适应不断发展的自然语言处理需求。
RAG 技术发展
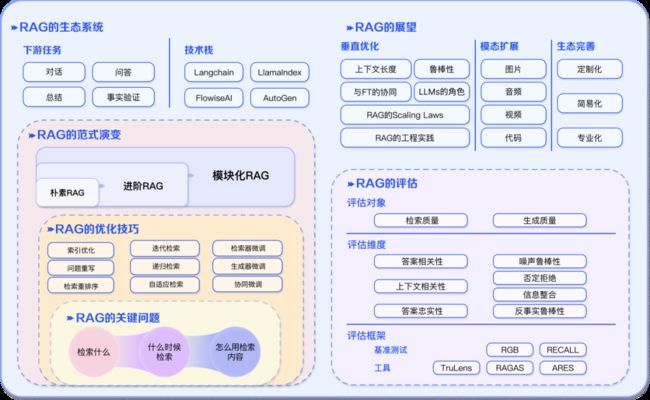
在RAG技术的发展过程中,可以从技术范式的角度将其总结为以下几个阶段:
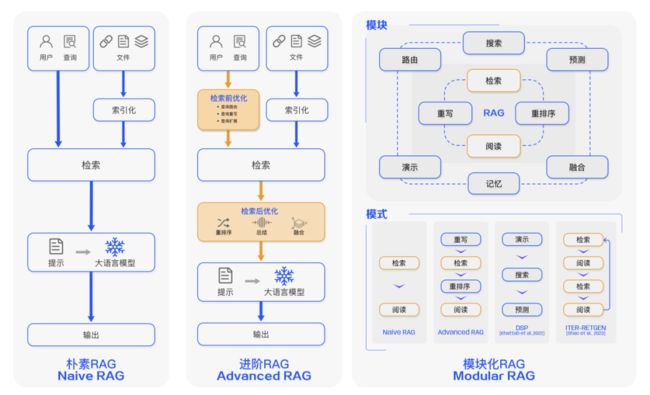
- 朴素(Naive RAG):
- 索引: 将文档库分割成较短的Chunk,并通过编码器构建向量索引。
- 检索: 根据问题和chunks的相似度检索相关文档片段。
- 生成: 以检索到的上下文为条件,生成问题的回答。
- 进阶的 RAG(Advanced RAG):
- 在Naive RAG中存在检索质量、响应生成质量和增强过程中的挑战。
- 数据索引: 通过更精细的数据清洗、设计文档结构和添加元数据等方法提升文本的一致性、准确性和检索效率。
- 检索前处理: 使用问题的重写、路由和扩充等方式对齐问题和文档块之间的语义差异。
- 检索后处理: 通过重排序文档库避免 “Lost in the Middle” 现象,或通过上下文筛选与压缩缩短窗口长度。
- 模块化 RAG(Modular RAG):
- 随着技术的发展,出现了模块化RAG的概念。
- 结构上更自由和灵活: 引入更多具体功能模块,如查询搜索引擎、融合多个回答。
- 技术融合: 将检索与微调、强化学习等技术融合,设计和编排多种RAG模式。
- 范式的继承与发展: 模块化RAG不是突然出现的,而是Naive RAG和Advanced RAG的继承与发展关系,前者是后者的一种特例形式。
综合而言,RAG技术在朴素、进阶和模块化三个阶段的发展过程中,不断突破传统的检索-生成框架,提升了检索质量、响应生成质量和整体性能。
LLMS 问题
LLMs(大语言模型)型虽然具有令人印象深刻的能力,但也存在一些问题:
- 误导性的“幻觉”: 模型可能会产生误导性的结果,即其生成的信息可能不准确或不完全符合实际情况。
- 信息过时: 模型依赖的信息可能会过时,因为它们在训练时使用的数据可能不包括最新的信息。
- 处理特定知识时效率不高: 在处理某些特定领域的知识时,模型可能效率不高,可能由于缺乏足够的领域专业性或深度。
- 缺乏专业领域的深度洞察: 模型可能缺乏对专业领域的深度理解,从而在特定领域的任务中表现不如专业人士。
- 推理能力欠缺: 模型在推理方面可能存在不足,可能难以正确推断复杂或抽象的关系,从而影响其在某些任务中的表现。
在现实世界的应用中,数据需要定期更新以反映最新的发展。生成的内容必须具有透明性和可追溯性,以便有效地控制成本并确保数据隐私的保护。
因此,仅仅依赖于那些被称为“黑盒”模型的简单方法是不够的。我们需要更为精细的解决方案来满足这些复杂的需求,以确保系统在不断变化的环境中能够持续提供准确和可信的信息。
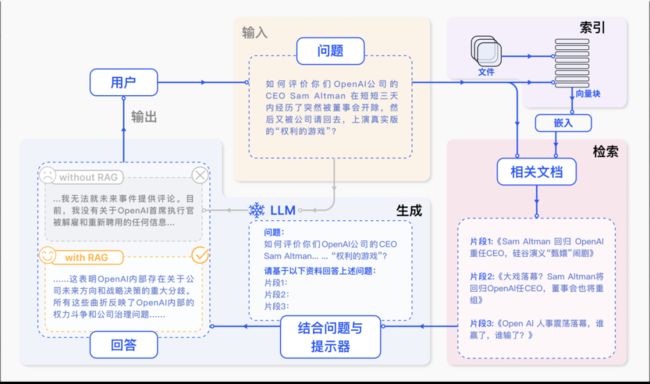
RAG 解决LLMs 幻觉
检索增强:能够与外部世界互动,以不同的形式和方式获取知识,从而提高所生成内容的事实性和合理性。
然而,世界上还有更多的知识存储在不同的结构和模式中,如图像和视频,这些知识往往是传统文本语料库无法访问、无法获得或无法描述的。
检索多模态知识以增强生成模型。
解决当前面临的事实性、推理、可解释性和鲁棒性等挑战提供了一个前景广阔的解决方案
RAG 核心 :Retrieval、Augmentation、Generation
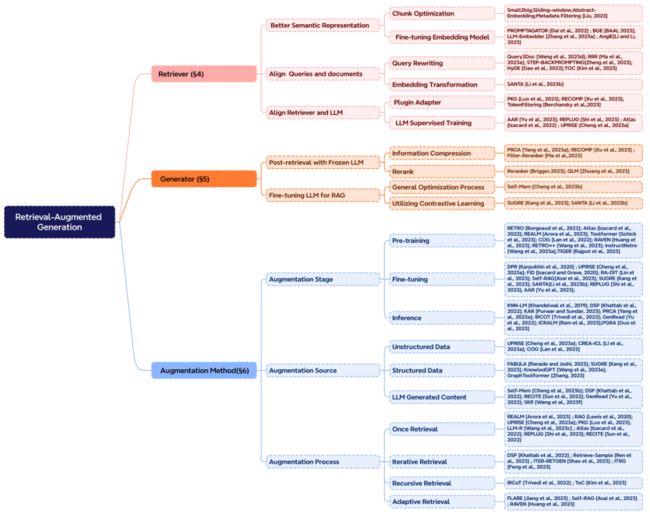
在构建一个优秀的RAG系统时,三个核心部分分别是“检索”(Retrieval)、“增强”(Augmentation)和“生成”(Generation)。这三个部分正好对应了RAG的首字母,是系统中不可或缺的关键组成部分。在注重增强部分的前提下,需要考虑以下三个关键问题:
- 检索什么?
- 确定在检索阶段要获取的信息,这直接影响到生成阶段的输入。选择合适的检索内容能够为模型提供更有价值的上下文信息,提高生成的准确性和相关性。
- 什么时候检索?
- 确定检索增强应该在RAG系统的哪个阶段进行。这可能包括预训练、微调和推理三个阶段。决定检索的时机会影响外部知识的参数化程度,以及所需的计算资源。
- 怎么用检索的内容?
- 确定如何有效地利用检索到的内容进行增强。这可能涉及到如何整合外部知识,将其融入生成模型的过程中。有效的使用检索的内容对于提升系统性能至关重要。
在检索增强的阶段,有一些关键方面需要考虑:
- 检索增强的数据源:
- 可以选择多种形式的数据作为增强的来源,包括非结构化的文本数据(段落、短语、单词),结构化数据(带有索引的文档、三元组数据、子图),或者充分发挥LLMs自身生成内容的能力,从模型自身生成的内容中检索。
- 检索增强的过程:
- 最初的检索可以是一次性过程,但在RAG的发展过程中,出现了更复杂的方法,如迭代检索、递归检索以及由LLMs自行判断检索时机的自适应检索方法。选择合适的检索过程能够更好地适应不同场景和需求。
构建一个强大的RAG系统需要综合考虑上述问题,平衡检索的精度和效率,以及如何将检索到的信息融入到生成模型中,从而实现更准确、相关和可信的语言生成。
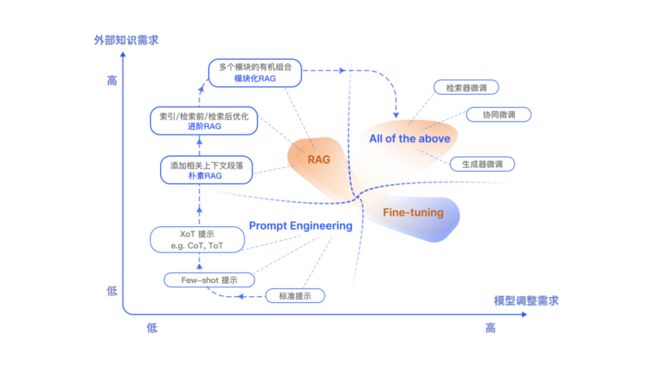
RAG 和微调如何选择
RAG,LLMs 主要优化手段还包括了提示工程 (Prompt Engineering)、微调 (Fine-tuning,FT)。他们都有自己独特的特点。根据对外部知识的依赖性和模型调整要求上的不同,各自有适合的场景。
RAG vs. FT:
- RAG(Retrieval-Augmented Generation):
- 类比:给模型一本教科书,用于特定查询的信息检索。
- 优点:适用于特定问题,信息检索高效。
- 注意:擅长整合新知识,适用于快速迭代新的用例。
- FT(Fine-Tuning):
- 类比:学生随着时间内化知识,模仿特定结构、风格或格式。
- 优点:通过增强模型知识、调整输出和教授复杂指令提高性能和效率。
- 注意:不太擅长整合新知识,相对固定于已学知识。
- 互补关系:
- RAG和FT并非相互排斥,可相互补充使用。
- 联合使用可能产生最佳性能,充分发挥各自优势。

评估RAG的方法RAG评估方法概述:
质量评分:
- 上下文相关性: 评估生成的答案是否与上下文相关。
- 答案忠实性: 确保生成的答案忠实于检索到的信息。
- 答案相关性: 衡量答案是否与用户查询相关。
关键能力评估:
- 噪声鲁棒性: 模型对输入中的噪声或干扰的处理能力。
- 拒答能力: 评估模型是否能够合理拒绝某些查询。
- 信息整合: 能否有效整合多个信息源。
- 反事实鲁棒性: 模型对虚构或不准确信息的处理能力。
评估框架:
- 基准测试: 包括RGB和RECALL等传统量化指标。
- 自动化评估工具: RAGAS、ARES、TruLens等,提供全面的性能评估。
评估维度总结:
- 评估对象: 主要关注RAG模型的生成答案。
- 评估维度: 包括上下文相关性、答案忠实性、答案相关性以及关键能力的多个方面。
- 评估指标: 通过多种基准测试和自动化评估工具来全面衡量性能。
这些评估维度结合了传统量化指标和专门的RAG评估标准,为深入理解RAG模型的性能和应用提供了全面的评估框架。

多模态检索增强生成
多模态检索增强生成(RAG)是指通过检索与生成目标相关的信息,来增强生成模型性能的技术。RAG 具有广阔的应用前景,包括文本生成、图像生成、视频生成等。
多模态学习的确是一个很有趣且具有挑战性的领域。通过整合不同模态的数据,我们可以获得更全面、丰富的信息,从而提高机器学习系统在各种任务中的性能。
在多模态生成模型中,文本-图像生成是一个典型的应用场景。通过将文本描述与图像关联,模型可以学习到语义上的联系,实现生成与描述相符的图像。这在创意写作生成和多语言翻译等任务中都具有很大的潜力。
当然,这个领域也面临一些挑战,如获取大量多模态数据以训练模型、设计能够产生有语义输出的网络结构等问题。解决这些挑战将有助于进一步推动多模态学习的发展,使其在实际应用中更加有效。

原理
RAG 通常包括两个阶段:
- 检索阶段:从多模态数据库中检索与生成目标相关的信息。
- 生成阶段:使用检索到的知识或信息指导生成模型的生成过程。
挑战
首先,由于生成模型依赖于内在知识(权重),可能导致产生许多虚幻的结果。其次,由于参数量庞大,传统的预训练和微调方法的更新成本极高,已经变得难以实际应用。作为一种解决之道,RAG 方法为语言模型与外部世界有效互动提供了一个极具前景的解决方案。

RAG 在近年来取得了显著的进展,但仍面临一些挑战,包括:
- 数据稀缺问题:多模态数据集的获取和标注成本高昂,因此数据稀缺问题一直是多模态生成领域的挑战。
- 模态不一致问题:不同模态的数据往往存在不一致性,这给多模态检索和合成带来了困难。
- 模型复杂度问题:多模态检索增强生成模型往往具有复杂的结构,这给模型的训练和部署带来了挑战。
未来的研究将致力于解决这些挑战,以推动多模态检索增强生成领域的发展。
趋势
RAG 已经在多个下游 NLP 任务中得到广泛应用,包括机器翻译、对话生成、抽象概括和知识密集型生成。其中,许多方法着重于利用检索文本信息。例如,Guu等人(2020b)和Izacard等人(2022)采用了将检索系统与编码器或序列到序列语言模型进行联合训练的方法,在性能上取得了与使用更多参数的大型语言模型相当的成果。近期的研究还提出了将检索系统与思维链(CoT)推理提示相结合的方法,以增强语言模型的性能。
以下是一些值得关注的趋势:
- 多模态检索和合成技术的融合:未来的研究将致力于将多模态检索和合成技术进行深入融合,以提高生成模型的性能。
- 多模态生成模型的泛化能力研究:多模态生成模型在特定任务上取得了显著的进展,但它们的泛化能力仍有待提高。
- 多模态生成模型的安全和可靠性研究:多模态生成模型可以生成逼真的文本、图像、音频等,因此它们可能被用于生成虚假信息或传播有害内容。

应用场景
图片
**视觉问题解答(Visual question answering, VQA) **
图片说明 (Image captioning)
有视觉基础的对话 (Visually grounded dialogue)
文本生成(Text generation)
代码
借助于NLP深度学习的进展,出现了一种通用的检索增强生成范式,为软件开发人员提供了有效的工具。这种范式不仅在代码补全中表现良好,还在代码生成和自动程序修复等任务中取得了显著的成果。然而,现有方法通常将编程语言和自然语言视为等价的标记序列,忽略了源代码的丰富语义。为了解决这一问题,最新的研究集中在多模态学习上,将代码注释、标识符标签和抽象语法树等附加模态纳入代码预训练模型,以提高代码的泛化性能。这种多模态检索增强生成方法在特定代码任务中已经证明了其可行性。
文本到代码生成(Text-to-Code Generation)
代码到文本的生成(Code-to-Text Generation)
代码补全(Code Completion)
**自动程序修复 (Automatic Program Repair,APR) **
作为中间步骤的代码推理(Reasoning over Codes)
结构化知识
幻觉的一个解决方案是利用检索到的结构化知识(如知识图谱、表格和数据库)进行基础生成。
问题解答(Question Answering,QA)
一般文本生成(General text generation)
用知识推理(Reasoning with knowledge)
以知识为基础的对话(Knowledge-grounded dialogue)
音频
文本音频数据增强(Text-audio data augmentation)
**音乐字幕(Music captioning) **
音乐生成(Music generation)
视频
视频对话(Video-grounded dialogue)
**视频字幕(Video captioning) **
LLM增强(LLM augmentation)
研究挑战
垂直优化面临的挑战与解决方案:
- 长下文长度的挑战:
- 问题: 当检索内容过多,超过LLMs上下文窗口限制时,如何处理?
- 解决方案: 探索更灵活的上下文处理方式,考虑引入分段机制或动态选择关键信息以适应长下文。
- 鲁棒性的挑战:
- 问题: 如何处理检索到的错误内容,进行过滤和验证?怎么提高模型的抗毒、抗噪声能力?
- 解决方案: 引入强化学习机制,让模型学习对错误信息的过滤,加强对异常情况的处理,提高模型的鲁棒性。
- 与微调协同的挑战:
- 问题: 如何协同RAG和FT,组织串行、交替还是端到端的训练方式?
- 解决方案: 探索混合训练策略,通过串行或交替的方式融合RAG和FT的训练,使它们相互协同提升性能。
- Scaling-Law的挑战:
- 问题: RAG模型是否满足Scaling Law?在什么场景下可能出现Inverse Scaling Law?
- 解决方案: 进行规模化实验和评估,了解RAG在不同规模下的性能表现,寻找可能存在的Scaling Law或Inverse Scaling Law现象。
- LLMs的角色的挑战:
- 问题: 如何更充分地挖掘LLMs在RAG中的潜力?
- 解决方案: 考虑在检索、生成、评估阶段中更灵活地使用LLMs,探索新的架构和方法以优化LLMs在RAG中的表现。
- 工程实践的挑战:
- 问题: 如何降低超大规模语料的检索时延?如何保证检索内容不被大模型泄露?
- 解决方案: 优化检索引擎的工程实践,使用分布式计算和高效索引技术来提高检索效率;引入隐私保护机制以防止泄露。
发展方向
检索增强型多模态推理(Retrieval Augmented Multimodal Reasoning)
构建多模态知识索引(Building a Multimodal Knowledge Index)
多模态检索预训练(Pretraining with Multimodal Retrieval)
参考文献
https://arxiv.org/abs/2312.10997 Retrieval-Augmented Generation for Large Language Models: A Survey
https://arxiv.org/abs/2401.05856 Seven Failure Points When Engineering a Retrieval Augmented Generation System
https://download.csdn.net/download/weixin_45312236/88720208 2023 中国开源开发者报告
**
**