20240122面试练习题10
1. Redis为什么执行这么快?
二、Redis为什么这么快?
1、完全基于内存,数据存在内存中,绝大部分请求是纯粹的内存操作,非常快速,跟传统的磁盘文件数据存储相比,避免了通过磁盘IO读取到内存这部分的开销。
2、数据结构简单,对数据操作也简单。Redis中的数据结构是专门进行设计的,每种数据结构都有一种或多种数据结构来支持。Redis正是依赖这些灵活的数据结构,来提升读取和写入的性能。
3、采用单线程,省去了很多上下文切换的时间以及CPU消耗,不存在竞争条件,不用去考虑各种锁的问题,不存在加锁释放锁操作,也不会出现死锁而导致的性能消耗。
4、使用基于IO多路复用机制的线程模型,可以处理并发的链接。
2. Redis是单线程执行还是多线程执行?它有线程安全问题吗?为什么吗?
1、Redis5及之前是单线程版本
2、Redis6开始引入多线程版本(单线程+多线程 版本)
请求是多线程的,但核心的内存读写操作(或者说读写计算)仍然是单线程的。
线程安全的场景:
1、单个键的读写操作:对于单个键的读操作和写操作是线程安全的。多个线程可以同时读取或写入同一个键,不会引发并发问题。
例如:
SET key value
GET key
2、原子操作:Redis 提供了一些原子性的操作,例如 INCR、LPUSH、SADD 等。这些操作是线程安全的,多个线程同时执行也不会引发问题。
例如:
INCR counter
LPUSH mylist value
SADD myset value
3、发布与订阅:Redis 的发布与订阅功能是线程安全的,多个线程可以同时进行发布和订阅操作。 例如:
PUBLISH channel message
SUBSCRIBE channel
线程不安全的场景:1、多个键的事务操作:如果多个线程同时对不同的键进行事务操作,可能会引发竞态条件。在这种情况下,需要使用分布式锁或其他并发控制技术来保证操作的一致性。
例如:
MULTI
SET key1 value1
SET key2 value2
EXEC
2、对于同一个键的并发写操作:如果多个线程同时对同一个键进行写操作,可能会引发竞态条件。在这种情况下,需要使用分布式锁或其他并发控制技术来保证操作的一致性。
例如:
SET key value1
SET key value2
总之,对于单个键的读写操作、原子操作和发布与订阅功能,Redis 是线程安全的。但在多个键的事务操作和对同一个键的并发写操作时,需要注意并发问题,并使用适当的并发控制机制来保证数据的一致性。
3. 在实际工作中,使用Redis实现了哪些业务场景?
1、缓存
例如:热点数据缓存(商品信息详情),可以提升热点数据的访问效率。
2、分布式锁
String 类型setnx方法,只有不存在时才能添加成功,返回true
public static boolean getLock(String key) {
Long flag = jedis.setnx(key, "1");
if (flag == 1) {
jedis.expire(key, 10);
}
return flag == 1;
}
public static void releaseLock(String key) {
jedis.del(key);
}
3、全局ID
int类型,incrby,利用原子性
incrby userid 1000
分库分表的场景,一次性拿一段
4、计数器
int类型,incr方法
例如:文章的阅读量、微博点赞数、允许一定的延迟,先写入Redis再定时同步到数据库
5、限流
int类型,incr方法
以访问者的ip和其他信息作为key,访问一次增加一次计数,超过次数则返回false
6、位统计
String类型的bitcount
字符是以8位二进制存储的
例如:在线用户统计,留存用户统计
setbit onlineusers 01
setbit onlineusers 11
setbit onlineusers 20
7、购物车
String 或hash。所有String可以做的hash都可以做。
例如:
key:用户id;field:商品id;value:商品数量。
+1:hincr。-1:hdecr。删除:hdel。全选:hgetall。商品数:hlen。
8、用户消息时间线timeline
list,双向链表,直接作为timeline就好了。插入有序
9、消息队列
List提供了两个阻塞的弹出操作:blpop/brpop,可以设置超时时间
blpop:blpop key1 timeout 移除并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
brpop:brpop key1 timeout 移除并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
10、抽奖
自带一个随机获得值
spop myset
11、点赞、签到、打卡
假如上面的微博ID是t1001,用户ID是u3001
用 like:t1001 来维护 t1001 这条微博的所有点赞用户
点赞了这条微博:sadd like:t1001 u3001
取消点赞:srem like:t1001 u3001
是否点赞:sismember like:t1001 u3001
点赞的所有用户:smembers like:t1001
点赞数:scard like:t1001
12、商品筛选
// 获取差集
sdiff set1 set2
// 获取交集(intersection )
sinter set1 set2
// 获取并集
sunion set1 set2
筛选商品,苹果的、ios的、屏幕在6.0-6.24之间的,屏幕材质是LCD屏幕
sinter brand:apple brand:ios screensize:6.0-6.24 screentype:lcd
13、用户关注、推荐模型
follow 关注 fans 粉丝
相互关注:
sadd 1:follow 2
sadd 2:fans 1
sadd 1:fans 2
sadd 2:follow 1
我关注的人也关注了他(取交集):
sinter 1:follow 2:fans
可能认识的人:
用户1可能认识的人(差集):sdiff 2:follow 1:follow
用户2可能认识的人:sdiff 1:follow 2:follow
4. Redis常用数据类型有哪些?
1、String(字符串)
字符串类型是Redis中最为基础的数据存储类型,每个键最大可存储数据512MB
使用方法:
redis 127.0.0.1:6379> set key1 value1
OK
redis 127.0.0.1:6379> set key2 value2
OK
redis 127.0.0.1:6379> get key1
value1
redis 127.0.0.1:6379> get key2
value2
redis 127.0.0.1:6379> set onlineNum 0
OK
redis 127.0.0.1:6379> incr onlineNum
(integer) 1
redis 127.0.0.1:6379> incrby onlineNum 4
(integer) 5
redis 127.0.0.1:6379> decr onlineNum
(integer) 4
适用场景:
很常见的场景用于统计网站访问数量,当前在线人数等。
2、Hash (散列Hash)
hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象或者map。Redis中的散列可以看成具有String key和String value的map容器,可以将多个key-value存储到一个key中。
使用方法:
redis 127.0.0.1:6379> hset user name zhangsan
(integer) 1
redis 127.0.0.1:6379> hmset user user age 10 sex 30
(integer) 2
redis 127.0.0.1:6379> hget user age
"10"
redis 127.0.0.1:6379> hmget user name sex
1)"zhangsan"
2)"30"
redis 127.0.0.1:6379>
适用场景:
存储、读取、修改用户属性(name,age,pwd等)
3、list (列表)
列表是简单的字符串列表,按照插入顺序排序。双向链表,可从头部或尾部插入或取出数据。
使用方法:
redis 127.0.0.1:6379> lpush users zhangsan
(integer) 1
redis 127.0.0.1:6379> lpush users lisi
(integer) 2
redis 127.0.0.1:6379> lpush users xiaofang
(integer) 3
redis 127.0.0.1:6379> lrange users 0 10
1) "xiaofang"
2) "lisi"
3) "zhangsan"
redis 127.0.0.1:6379> rpush users chacha
(integer) 4
redis 127.0.0.1:6379> lrange users 0 10
1) "xiaofang"
2) "lisi"
3) "zhangsan"
4) "chacha"
redis 127.0.0.1:6379> rpop users
"chacha"
redis 127.0.0.1:6379> rpop users
"zhangsan"
redis 127.0.0.1:6379> lpop users
xiaofang
redis 127.0.0.1:6379>
适用场景
1)最新消息排行榜(如朋友圈的时间线)。
2)消息队列。生产者可以用push操作将任务存在list中,消费者用pop操作将任务取出。
4、set (无序集合)
列表是简单的字符串列表。数据插入无序且不可重复。
使用方法:
redis 127.0.0.1:6379> sadd friends zhangsan
(integer) 1
redis 127.0.0.1:6379> sadd friends lisi
(integer) 1
redis 127.0.0.1:6379> sadd friends zhangsan
(integer) 0
redis 127.0.0.1:6379> sadd friends wupeng
(integer) 1
redis 127.0.0.1:6379> scard friends
(integer) 3
redis 127.0.0.1:6379> sismember friends wupeng
(integer) 1
redis 127.0.0.1:6379> sismember friends shasha
(integer) 0
redis 127.0.0.1:6379> srem friends shasha
(inetegr) 0
redis 127.0.0.1:6379> srem friends zhangsan
(integer) 1
redis 127.0.0.1:6379> scard friends
(integer) 2
redis 127.0.0.1:6379>
适用场景
利用不可重复性,实现求共同好友、访问某地址ip去重,当前在线用户人数去重等
5、zset (有序集合)
redis的zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复
使用方法
redis 127.0.0.1:6379> zadd rank 97 zhangsan
(integer) 1
redis 127.0.0.1:6379> zadd rank 70 lisi
(integer) 1
redis 127.0.0.1:6379> zadd rank 78 wupeng
(integer) 1
redis 127.0.0.1:6379> zadd rank 75 zhangsan
(integer) 1
redis 127.0.0.1:6379> zcard rank
(integer) 3
redis 127.0.0.1:6379>
适用场景
排行榜、带权重的消息队列
5. 存储Session信息你会使用哪种数据类型?为什么?
Session 数据结构复杂且需要频繁更新或查询其中的个别字段,通常建议使用哈希表来存储 Session;而在 Session 数据较为简单、不涉及局部更新的情况下,使用字符串存储也是可行的选择
6. 有序集合底层是如何实现的?
Redis中的有序集合zset底层实现采用了两种编码方式:
REDIS_ENCODING_SKIPLIST 跳跃列表
REDIS_ENCODING_ZIPLIST 压缩列表
当zset满足以下两个条件的时候,使用ziplist:
保存的元素少于128个
保存的所有元素大小都小于64字节
不满足这两个条件则使用skiplist。
7. 什么是跳表?为什么要用跳表?
跳表是一个随机化的数据结构,实质就是一种可以进行二分查找的有序链表。
跳表在原有的有序链表上面增加了多级索引,通过索引来实现快速查找。
跳表不仅能提高搜索性能,同时也可以提高插入和删除操作的性能。
8. 说一下跳表的查询流程?
把一些节点从有序表中提取出来,缓存一级索引,就组成了下面这样的结构:

要查找17这个元素,只要从一级索引往后遍历即可,只需要经过1、6、15、17这几个元素就可以找到17了。
查找11这个元素,从一级索引的1开始,向右到6,再向右发现是15,它比11大,此路不通,从6往下走,再从下面的6往右走,到7,再到11。
同样地,一级索引也可以往上再提取一层,组成二级索引,如下:
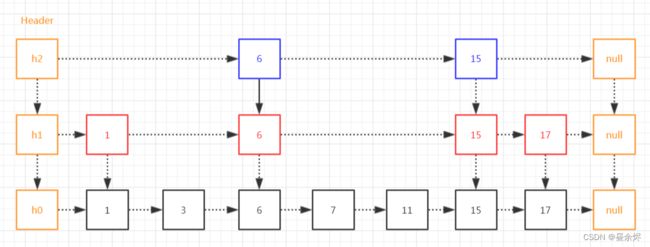
9. 说一下跳表的添加流程?为什么要有“随机层数”这个概念?
每一个元素添加到跳表中时,首先需要随机指定这个元素在跳表中的层数,如果随机指定的层数大于了跳表的层数,则在将元素添加到跳表中之前,还需要扩大跳表的层数,而扩大跳表的层数就是将头尾节点的层数扩大。
关于“随机层数”的概念,其主要目的是为了保持跳表的平衡性。如果我们固定每个元素的层数,那么在某些情况下,跳表可能会退化成普通的链表,从而导致查找效率降低。通过随机选择每个元素的层数,我们可以确保跳表的高度大致为log(n),从而保证查找、插入和删除操作的时间复杂度为O(log n)
10. 使用Redis如何实现分布式锁?
想要实现分布式锁,必须要求Redis有互斥的能力。可以使用SETNX命令,其含义是SET IF NOT EXIST,即如果key不存在,才会设置它的值,否则什么也不做。两个客户端进程可以执行这个命令,达到互斥,就可以实现一个分布式锁。
加锁操作完成后,加锁成功的客户端,就可以去操作共享资源,例如,修改MySQL的某一行数据。操作完成后,还要及时释放锁,给后来者让出操作共享资源的机会。释放锁直接使用DEL命令删除这个key即可。
// 加锁
SETNX lock_key 1
// 业务逻辑
DO THINGS
// 释放锁
DEL lock_key
以上实现存在一个很大的问题,当客户端1拿到锁后,如果发生下面的场景,就会造成死锁。
程序处理业务逻辑异常,没及时释放锁
进程挂了,没机会释放锁
以上情况会导致已经获得锁的客户端一直占用锁,其他客户端永远无法获取到锁。
为了解决以上死锁问题,最容易想到的方案是在申请锁时,在Redis中实现时,给锁设置一个过期时间,假设操作共享资源的时间不会超过10s,那么加锁时,给这个key设置10s过期即可。
但以上操作还是有问题,加锁、设置过期时间是2条命令,有可能只执行了第一条,第二条却执行失败,例如:
SETNX执行成功,执行EXPIRE时由于网络问题,执行失败
SETNX执行成功,Redis异常宕机,EXPIRE没有机会执行
SETNX执行成功,客户端异常崩溃,EXPIRE没有机会执行
总之这两条命令如果不能保证是原子操作,就有潜在的风险导致过期时间设置失败,依旧有可能发生死锁问题。在Redis 2.6.12之后,Redis扩展了SET命令的参数,可以在SET的同时指定EXPIRE时间,这条操作是原子的,例如以下命令是设置锁的过期时间为10秒。
SET lock_key 1 EX 10 NX