Opencv(C++)学习 TBB与OPENMP的加速效果实验与ARM上的实践
背景:在某个嵌入式上的图像处理项目功能开发告一段落,进入性能优化阶段。尝试从多线程上对图像处理过程进行加速。经过初步调研后,可以从OPENMP,TBB这两块进行加速,当前项目中有些算法已采用多线程加速,这次主要是对比以上两个加速模块与多线程加速效果的对比。现在PC上实验,然后再移植相关库。
环境准备:WIN11 ,VS2022 ,Debug 64
1、编译OPENCV。
经测试,编译过程是否选择TBB,MP相关选项对加载对应库和使用不影响。
2、安装TBB。(https://www.intel.com/content/www/us/en/developer/tools/oneapi/base-toolkit-download.html)
VS配置之打开相关模块。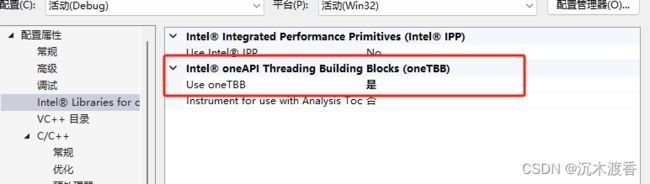
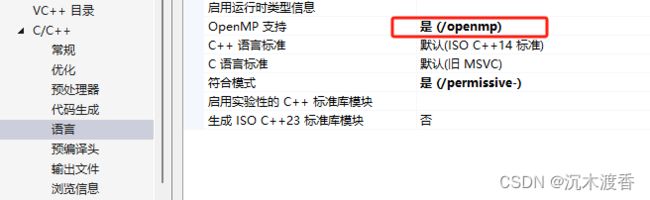
对比过程:实验对比的对象包括:
1、基础FOR循环。
2、多线程。
3、原数据相同的TBB。
4、原数据独立的TBB。
5、原数据相同的OPENMP;
6、原数据独立的OPENMP;
测试数据为960*600的图像,测试内容为对该图进行大尺寸滤波操作。
测试代码:
#include 实验结果:
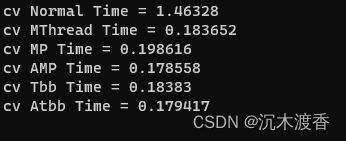
实验结论:
1、OPENMP,TBB可以有效对并行处理进行加速,其效果与多线程处理基本持平。
2、OPENMP,TBB的优势在于代码编写相对简单,也不用考虑线程数的设置。
3、OPENMP,TBB的基础数据独立与否,对测试速度基本不影响(待定,有的同学说会导致各线程等待访问同一数据,引起耗时增加),也可能和PC的性能较好有关。但尽量去保证数据独立性,避免处理结果错误。
ARM实践 TODO