Transformers Tutorial教程3-7
Introduction
Transformers库的一个使用,用这个库就可以很轻松地去使用和训练自己的一个预训练语言模型。
outline
介绍什么是Transformers,为什么要用它
介绍一些比较常用的接口
最后会给出一个demo,帮助你们快速地入门

what is Transformers?
之前已大概了解了BERT、GPT这样的一些预训练语言模型,在BERT和GPT提出了之后,这样的预训练语言模型在各种各样的下游任务上都大幅超过了以往的神经网络模型,包括像RNN、LSTM之类的一些模型,因此的话越来越多的工作它就致力于去提出有没有可能有更好的一个预训练语言模型,他们的这些工作,有可能是针对架构进行了一些改进,提出了更好的架构,也可能是针对预训练的方式去进行了一些变动,提出了更好的训练方式,也有可能就单纯的用了一个更高质量的语料等等,这样造成了预训练语言模型在BERT之后像雨后春笋一样大量涌现了。
这是一件好事,同时也是一件负担,无论你是工程师或者是一个研究者,这样一个模型的快速迭代对你来说都是一种非常大的压力,比如你是工程师,你对于每一个模型进行实现的时候,你都要保证模型里面的每一处细节都和原论文一样,这个其实是非常困难的,并且如果来一个新的模型你就要重新实现一遍,那显然是不太现实。那例如你是一个研究者,你其实只是想要在之前的模型的基础上作出一点小的改动,那你其实也需要首先去完成这样模型的复现,而且你也需要大量的语料以及非常大量的计算资源来进行一个预训练,因此每一次你都需要从头去实现模型,那对于希望使用预训练模型的人来说其实是一种折磨。

很自然的我们就会想有没有可能有一个就相当于第三方的库,能够帮助我们,第一,帮助我们去很轻松地去复现各种各样预训练语言模型paper的结果,第二,比如你是一个工程师,你希望有这样一个库,它能够帮助你非常快速地去进行模型的部署,第三,可能你是一个研究者,你希望有这样一个库能够让你非常自由地去自定义你自己的模型,就在之前的模型基础上进行一些简单的修改。
非常幸运的是,这些愿景已经实现,hugging face 公司提出来了一个Transformers的库,它整合了非常多的预训练语言模型。

这个库有几个优点,比如:
1、提供了非常多的模型,可以从5万多个模型中随意挑选出来一个,然后通过一两行代码进行一个简单的加载就可以使用
2、支持现在一些主流的预训练、深度学习的框架,比如常用的pytorch,tensorflow,以及一个新兴的深度学习框架叫做Jax
这门课程基本上是基于pytorch,所以你们可以给予pytorch来使用这个Transformers库。
处理NLP以外的模型外,它还支持像音频方面的预训练模型,然后还有视觉方面的预训练模型,最近视觉方面的预训练模型非常火,比较知名的像vit之类的一些模型,也可以在这里用Transformers库进行一个下载和加载,非常容易使用,基本上没有什么门槛,只需要去学会那么几个接口的使用就可以完成,从预训练的模型的下载加载到fine-tune然后保存,一系列流程都可以非常轻松地完成。
现在大部分关于预训练模型的研究工作都是基于Transformers库来完成的,当然有些工程为了追求极致的速度,它可能会进行一些优化,然后去用一些其他优化更好的库,但比如说你只是一个普通研究者想要做一些你自己idea的一些快速的验证之类的,那可能你的首选就会是Transformers这个库。之后会介绍一个工具包BMtrain,他有了类似于Transformers这样的易用性,能够帮助和加速你的训练。

使用Transformers的pipeline
首先介绍的是transformers这个库里面的一个pipeline这样的一个接口,他的一个使用场景主要是,比如说你是一个工程师,你就只是想要拿一个现成的,预训练好的或者说发现更好的一个模型来完成你的下游任务。
如下我现在想要一个现成的模型,来帮助我完成sentiment analysis情感分析这样一个工作,那我就可以直接从这个transformers里面import一个pipeline,把我的任务名给他输进去,然后他就能够根据这个任务名给你一个已经在这个任务上fine-tune好的模型,在这个例子里面,我们就把它存到这个classifier里面。有了这样一个模型以后,我们就可以把我们的数据,比如说这边是一个句子叫做I love you把它传进去,那这个classifier就会输出一个结果,然后输出这一段句子是positive还是negative,然后具体的这个输出到底是什么样子,我们会在之后的demo里面看到。
另比如说你想做一个question answering,就是做一个机器问答,你也可以把这个task name换成question answering,然后它就可以给你load进一个question answering的模型,你只需要给他你的context、question,然后他就能根据你的context、question给出对应的一个结果。
基本上这个pipeline的话,它会自动地根据你的task名字去load进行一个在这个task上的fine-tune好的模型来帮助你完成这个任务,那你其实也可以传进你自己自定义的一些模型,以及他有非常多支持的任务,可以上官网看一下。
如果你不满足于只是用,你也想去fine-tune出自己的一个模型,就是基于之前的pre-train好的模型去fine-tune一个自己的模型,比如在自己的数据集自己的任务上进行一个fine-tune,那你可能就需要去学习一些稍微底层一点点的接口。

Tokenization
那第一个的话就比如说,我们现在有自己的数据,那有这个数据以后,我们当然要做第一件事情就是一个tokenization。
但其实不同的那个pre-train的模型他有非常多不同的tokenization的方式,像GPT,他的tokenization就是一个BPE;BERT 、ELECTRA用的就是wordpice;ALBERT、T5用的是sentencepiece,也就是说不同的预训练模型,它是有自己不同的tokenization的方式的,而且他们的词表也不一样。
在我们复现这些模型的时候,其实是会带来一些麻烦的,你复现一个模型,你还要去针对这个模型去实现他的tokenization的方式,这个其实挺麻烦的,但幸运的是这个hugging face已经帮我们全部都包装好了,只需要一个简单的语句,就是你先import一个AutoTokenizer,用AutoTokenizer去调用他的一个from_pretrained方法,然后把你的模型的名字给他传进去。
比如以下例子,我们传的是一个bert-base-uncase,那这个bert-base就是这个模型的大小,它是一个base级别的一个大小。uncase就是说,我们这个load模型,它是他的那个input句子里面它是不区分大小写的,也就是他会把所有的大写都转换成小写,当然你也可以load一个bert-base-cased,这是一个区分大小写的模型。然后在load进这个tokenizer以后,你只要把你的句子给他传进去,他就能自动帮你完成tokenizer,然后输出到inputs这个结果里,具体的输出格式,我们会在之后的demo里看到时什么样子。

Frequently-used API常用的接口
其他的一些比较常用的接口,就比如说,你想要load一个pre-trained模型,也非常简单,你只需要两句话,一句话就是tokenizer这个load,刚已说过,那这个model的load其实非常像,就比如说我们现在想要load一个用来做那个sentence classification model,我们就可以调用这样的一个AutoModelForSequenceClassification模型的名字,我们就可以完成这个模型的下载和加载。
以下事例中的model其实已经是一个预训练好的模型,tokenize也是刚刚已经讲过。
跑这个模型也很容易,你只需要把这个input给他直接塞到模型里面,他就能够把这个模型在这个input上面进行运行,然后给出你最后的结果。
比如说你在fine-tune完以后,你想要把这个模型给他保存下来其实也很简单,你只需要调用一个save_pretrained,然后输入你的那个保存的路径其实就好了。
那之后你就可以直接用from_pretrained这样的一个接口,去调用出刚刚已经训练好的这样一个模型。
总的流程大概就是这样。

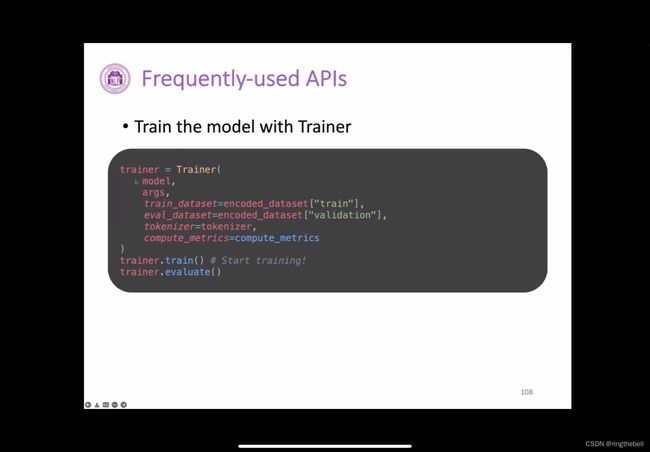
当然,如果你不太想要去真的去接触到里面,就是模型在fine-tune的时候,那些比如说optimizer的update、数据的迭代之类的,hugging face其实也给了你一个非常方便的一个包装好的一个类,它叫做trainer。
你只需要把这个trainer优化相关的args参数,然后把数据集tokenizer,还有这个计算metric的方式全部给他统统塞进去,他就已经帮你构建好了这样的一个类,
然后你只需要调用这个trainer.train(),他就可以帮你自动的把模型给跑起来。最后的话可以调用trainer.evaluate(),相当于自动化地帮你完成这个训练的过程以及这个评测的过程。
https://colab.research.google.com/drive/1tcDiyHIKgEJp4TzGbGp27HYbdFWGoIU_?usp=sharing