【图像分割】【深度学习】UNet Pytorch代码-数据预处理模块解析
【图像分割】【深度学习】UNet Pytorch代码-数据预处理模块解析
文章目录
- 【图像分割】【深度学习】UNet Pytorch代码-数据预处理模块解析
- 前言
- DRIVE数据集简介
- 数据预处理模块
-
- 自定义预处理操作
-
- 随机尺寸调整 RandomResize
- 随机水平翻转 RandomHorizontalFlip
- 随机竖直翻转 RandomVerticalFlip
- 随机裁剪 RandomCrop
- 标准化 Normalize
- 其他预处理操作
- DriveDataset类
-
- __init__ 函数
- __getitem__函数
- __len__函数
- collate_fn函数
- 总结
前言
在详细解析UNet代码之前,首要任务是成功运行UNet代码【win10下参考教程】,后续学习才有意义。本博客讲解UNet的数据预处理模块代码,不涉及其他功能模块代码。
博主将各功能模块的代码在不同的博文中进行了详细的解析,点击【win10下参考教程】,博文的目录链接放在前言部分。
DRIVE数据集简介
DRIVE(Digital Retinal Images for Vessel Extraction)数据集是用于视网膜病变研究的数据集,相关图像均来自于荷兰的糖尿病视网膜病变筛查计划,其被用于视网膜图像中的血管分割比较研究。在深度学习领域,该数据集主要用于研究和评估视网膜血管分割算法的性能。
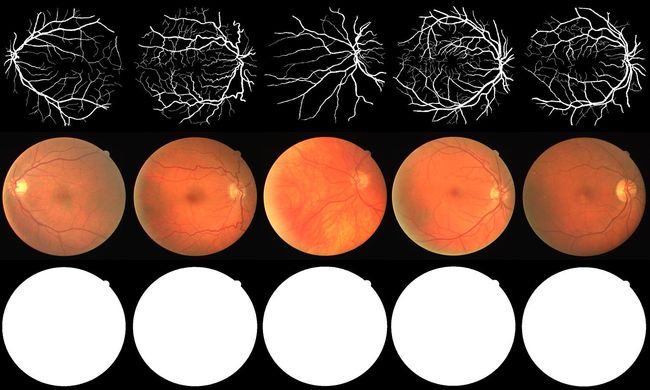
第一行是标签图像:手工标记出了图像的血管区域和非血管区域(二值化图像)
第二行是原始图像:视网膜图像
第三行是mask图像:标记出图像的眼球和非眼球区域(二值图)
博主提供了上图拼接效果的代码,需要拷贝将三种图片都放到一个文件内。
import os
import random
from PIL import Image
# 图像文件夹路径
image_folder = r"images"
# 读取图像文件夹中的所有图片
image_files = os.listdir(image_folder)
# 选取前15张图片
image_files = image_files[:15]
# 统一图像的尺寸到指定大小
width = 300
height = 300
target_size = (width, height)
# 读取图像并存储在一个列表中
images = []
for image_file in image_files:
# 图片地址
image_path = os.path.join(image_folder, image_file)
# 读取图片
image = Image.open(image_path)
# 调整图片大小
image = image.resize(target_size)
images.append(image)
# 创建新的空白图像,用于拼接 5行3列
result_width = width * 5
result_height = height * 3
result_image = Image.new("RGB", (result_width, result_height))
# 将图像拼接到空白图像上
for i in range(15):
# 图片的起始(左上角)坐标
x = (i // 3)* width
y = (i % 3) * height
# 将图片放置到拼接图片的对应位置
result_image.paste(images[i], (x, y))
# 保存拼接后的图像
result_image.save("result_image.jpg")
通常分割数据集只有用于区分目标和背景的mask标签数据集和原始图像数据集俩部分,个人感觉DRIVE数据集是将mask标签数据集拆分成了俩个步骤,即划分出眼球的mask图像和划分出血管区域的标签图像,其实博主感觉可以合二为一。
数据预处理模块
按照代码执行顺序依次讲解遇到的每个数据已处理操作。
DriveDataset不是PyTorch的内置函数或类,是一个自定义的数据集类,继承自torch.utils.data.Dataset类,并重写其中的方法来实现自定义数据集的加载和预处理逻辑。get_transform函数则是自定的一些预处理操作方式。
在train.py的main函数中
# 训练集
train_dataset = DriveDataset(args.data_path,
train=True,
transforms=get_transform(train=True, mean=mean, std=std))
# 测试集
val_dataset = DriveDataset(args.data_path,
train=False,
transforms=get_transform(train=False, mean=mean, std=std))
自定义预处理操作
get_transform函数中定义了后续预处理操作中所需要的一些参数变量,在训练阶段和测试阶段,对数据的预处理操作是有所区别的。
在train.py的main函数中
# 自定义预处理操作
def get_transform(train, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
# 基础图像大小
base_size = 565
# 裁剪图像大小
crop_size = 480
if train:
# 训练阶段的数据预处理方式
return SegmentationPresetTrain(base_size, crop_size, mean=mean, std=std)
else:
# 测试阶段的数据预处理方式
return SegmentationPresetEval(mean=mean, std=std)
- 训练阶段的数据预处理方式:包括了图像的随机尺寸调整、随机水平竖直翻转以及随机裁剪等操作,对数据进行了增强,有助于提高模型的泛化能力和鲁棒性。
# 训练阶段数据预处理操作 class SegmentationPresetTrain: def __init__(self, base_size, crop_size, hflip_prob=0.5, vflip_prob=0.5, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)): # 最小尺寸 min_size = int(0.5 * base_size) # 最大尺寸 max_size = int(1.2 * base_size) # 随机尺寸调整操作 trans = [T.RandomResize(min_size, max_size)] # 随机水平翻转操作 if hflip_prob > 0: trans.append(T.RandomHorizontalFlip(hflip_prob)) # 随机竖直翻转操作 if vflip_prob > 0: trans.append(T.RandomVerticalFlip(vflip_prob)) trans.extend([ # 随机裁剪 T.RandomCrop(crop_size), # 转tensor T.ToTensor(), # 标准化 T.Normalize(mean=mean, std=std), ]) # 一系列预处理的操作 self.transforms = T.Compose(trans) def __call__(self, img, target): return self.transforms(img, target) - 测试阶段数据预处理操作:通常不需要进行数据增强,因为只需要模型进行准确的评估和推断,而不希望引入额外的随机性,因此只需要对数据进行标准化操作。
# 测试阶段数据预处理操作 class SegmentationPresetEval: def __init__(self, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)): self.transforms = T.Compose([ # 转tensor T.ToTensor(), # 标准化 T.Normalize(mean=mean, std=std), ]) def __call__(self, img, target): return self.transforms(img, target)
这里的预处理操作都是自定义的,博主在接下来的博文内容将逐一进行详细的讲解。
为什么要自定义一些预处理操作而不是用pytorch自带的,这是因为在分割任务中,需要同时对图像和标签都进行完全一致的预处理,pytorch自带的操作一次只能对一个进行预处理,而且很多预处理都是随机的,图像和标签分开预处理很大程度会发生不一致的错误。
随机尺寸调整 RandomResize
对原始原始图像和标签同时进行了随机尺寸调整,它们的随机值是一致的。将图像的较短边调整为指定的大小(随机值),并保持原始图像的宽高比。
在transforms.py中
# 随机图像大小调整
class RandomResize(object):
def __init__(self, min_size, max_size=None):
# 给定图像的尺寸范围(最大最小)
self.min_size = min_size
if max_size is None:
max_size = min_size
self.max_size = max_size
def __call__(self, image, target):
# 从图片尺寸范围内随机选择一个尺寸
size = random.randint(self.min_size, self.max_size)
# size是int类型,根据选择的尺寸调整原始image大小,根据最小边来等比例缩放图像
image = F.resize(image, size)
# 根据选择的尺寸调整原始target大小,根据最小边来等比例缩放图像,最近邻插值,否则target不再是二值图像
target = F.resize(target, size, interpolation=T.InterpolationMode.NEAREST)
return image, target
对标签需要采用最近邻算法,否则调整之后的标签就不再是二值图像
随机水平翻转 RandomHorizontalFlip
生成的随机值小于指定阈值时,对原始原始图像和标签同时进行了随机水平翻转 。
# 随机图像水平翻转
class RandomHorizontalFlip(object):
# 水平翻转的概率
def __init__(self, flip_prob):
self.flip_prob = flip_prob
def __call__(self, image, target):
if random.random() < self.flip_prob:
# 根据概率阈值对image和target进行水平翻转
image = F.hflip(image)
target = F.hflip(target)
return image, target
随机竖直翻转 RandomVerticalFlip
生成的随机值小于指定阈值时,对原始原始图像和标签同时进行了随机竖直翻转。
class RandomVerticalFlip(object):
def __init__(self, flip_prob):
# 竖直翻转的概率
self.flip_prob = flip_prob
def __call__(self, image, target):
if random.random() < self.flip_prob:
# 根据概率阈值对image和target进行竖直翻转
image = F.vflip(image)
target = F.vflip(target)
return image, target
随机裁剪 RandomCrop
在指定的阈值范围内随机生成裁剪区域的元组,即裁剪框的左上角坐标(x,y) 和裁剪框的大小(w,h),对原始原始图像和标签同时进行裁剪。
# 随机图像裁剪
class RandomCrop(object):
def __init__(self, size):
# 裁剪尺寸
self.size = size
def __call__(self, image, target):
# 对image和target进行padding填充
image = pad_if_smaller(image, self.size)
# mask的话填充的是255,代表不感兴趣的区域
target = pad_if_smaller(target, self.size, fill=255)
# 获得裁剪的起点(左上)和终点(右下)坐标(w,h)
crop_params = T.RandomCrop.get_params(image, (self.size, self.size))
# 对image和target进行裁剪
image = F.crop(image, *crop_params)
target = F.crop(target, *crop_params)
return image, target
指定的阈值可能超出了原始图像和标签的尺寸范围,不足裁剪的大小,因此需要对原始图像和标签进行填补,使二者的宽和高都大于指定的阈值。
# 填充图像满足指定尺寸
def pad_if_smaller(img, size, fill=0):
# 获得图像最小边
min_size = min(img.size)
# 图像最小边小于给定size,则用给定值fill对图像进行padding填充
if min_size < size:
ow, oh = img.size
padh = size - oh if oh < size else 0
padw = size - ow if ow < size else 0
img = F.pad(img, (0, 0, padw, padh), fill=fill)
return img
标准化 Normalize
只需要对原始图像做标准化: x i n e w = x i − μ σ x_i^{new} = \frac{{{x_i} - \mu }}{\sigma } xinew=σxi−μ,因为标签是二值化图像。
# 对图像进行标准化
class Normalize(object):
def __init__(self, mean, std):
# 均值和标准差
self.mean = mean
self.std = std
def __call__(self, image, target):
# 对image和target标准化
image = F.normalize(image, mean=self.mean, std=self.std)
return image, target
其他预处理操作
这俩操作比较好理解,中心裁剪通过给的目标尺寸对图像进行中心裁剪操作,ToTensor将图像数据转换为神经网络可以处理的张量格式。
# 中心裁剪
class CenterCrop(object):
def __init__(self, size):
self.size = size
def __call__(self, image, target):
image = F.center_crop(image, self.size)
target = F.center_crop(target, self.size)
return image, target
# numpy转化成tensor
class ToTensor(object):
def __call__(self, image, target):
image = F.to_tensor(image)
target = torch.as_tensor(np.array(target), dtype=torch.int64)
return image, target
将所有的预处理都打包在一起。
# 打包一系列预处理操作
class Compose(object):
def __init__(self, transforms):
# 一系列预处理操作
self.transforms = transforms
def __call__(self, image, target):
for t in self.transforms:
# 对image和target进行一系列预处理
image, target = t(image, target)
return image, target
DriveDataset类
通过继承torch.utils.data.Dataset类,,创建一个自定义的数据集类,并实现其中的必要方法,还可以额外添加自定义的方法,以便在训练和测试过程中使用。
DRIVE数据集有三个图像输入,不同于常规的图像和标签的二输入模式,因此需要重写以便支持三输入模式。
在my_dataset.py中
init 函数
在 init 方法中,实现加载和预处理数据的逻辑。
def __init__(self, root, train, transforms=None):
super(DriveDataset, self).__init__()
# 当前模式
self.flag = "training" if train else "test"
# 数据集路径(训练集或测试集)
data_root = os.path.join(root, "DRIVE", self.flag)
# 严重数据集是否存在
assert os.path.exists(data_root), f"path '{data_root}' does not exists."
# 预处理操作
self.transforms = transforms
# 获取所有图像名称
img_names = [i for i in os.listdir(os.path.join(data_root, "images")) if i.endswith(".tif")]
# 获取所有图像地址
self.img_list = [os.path.join(data_root, "images", i) for i in img_names]
# 分割标签
self.manual = [os.path.join(data_root, "1st_manual", i.split("_")[0] + "_manual1.gif")
for i in img_names]
# 检查所有标签,保证都有与原始图片一一对应
for i in self.manual:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists.")
# mask图片
self.roi_mask = [os.path.join(data_root, "mask", i.split("_")[0] + f"_{self.flag}_mask.gif")
for i in img_names]
# 检查所有mask图片,保证都有与原始图片一一对应
for i in self.roi_mask:
if os.path.exists(i) is False:
raise FileNotFoundError(f"file {i} does not exists.")
# 简单说明一下,原始图片是有除了眼球以前的背景部分,mask的作用是剔除眼球的背景,分割标签的作用则是将眼球中有用的前景标记出来
__getitem__函数
getitem 方法根据索引返回一个样本的数据和标签。
def __getitem__(self, idx):
# 加载图片
img = Image.open(self.img_list[idx]).convert('RGB')
# 加载标签
manual = Image.open(self.manual[idx]).convert('L')
# 标签二值化,[0,1] 0是背景 1是前景
manual = np.array(manual) / 255
# 加载mask
roi_mask = Image.open(self.roi_mask[idx]).convert('L')
# 对二值化图像进行反转,黑变白,白变黑[0 255] 0是前景 255是背景
roi_mask = 255 - np.array(roi_mask)
# roi_mask眼球部分先置黑[0],然后加上manual标签前景[1]标记出眼球部分正确的前景[1],背景[0]标记出眼球部分正确的背景[0]
# roi_mask眼球外部分先置白[255],无论加上manual标签前景[0]或者背景[1]都是眼球外部分背景[255],这部分就是可以忽略的不感兴趣部分,在眼球外
# 最终标签 [0 1 255]
mask = np.clip(manual + roi_mask, a_min=0, a_max=255)
# 对图像和标签做预处理
if self.transforms is not None:
img, mask = self.transforms(img, mask)
return img, mask
__len__函数
len 方法返回数据集的样本数量。
def __len__(self):
return len(self.img_list)
collate_fn函数
这个方法不是继承torch.utils.data.Dataset类的必须方法,是自定义额外加上的,用于指定如何对样本进行批量处理。
# 静态方法
@staticmethod
def collate_fn(batch):
images, targets = list(zip(*batch))
# 图像填充0
batched_imgs = cat_list(images, fill_value=0)
# 标签填充255,代表不敢兴趣的区域
batched_targets = cat_list(targets, fill_value=255)
return batched_imgs, batched_targets
数据集中的样本具有不同的大小或形状,需要对它们进行对齐或填充,以便能够形成一个批量进行并行计算。
# 统一所有输入的形状
def cat_list(images, fill_value=0):
# 分别提取batchsize个图片的[C,W,H]三个维度,选择每个维度的最大值统一当前batchsize的图像形状
max_size = tuple(max(s) for s in zip(*[img.shape for img in images]))
# [B,C,W,H]
batch_shape = (len(images),) + max_size
# 创建一个值全是fill_value的新图片集[B,C,W,H]
batched_imgs = images[0].new(*batch_shape).fill_(fill_value)
for img, pad_img in zip(images, batched_imgs):
# 将原始图片所有值对应赋值到新图片上,理解成变相的padding
pad_img[..., :img.shape[-2], :img.shape[-1]].copy_(img)
return batched_imgs
这里是对齐填充,表现的效果示意图如下所示
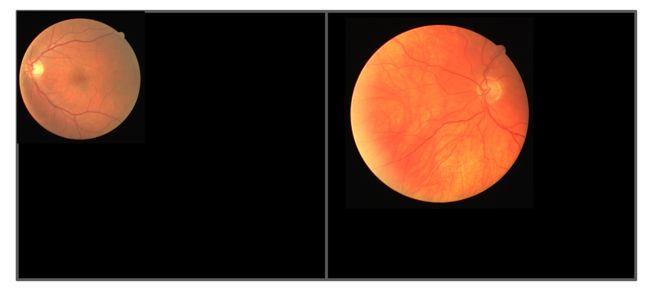
cat_list不在DriveDataset类的成员函数,但是也在my_dataset.py文件中
将collate_fn参数设置为DriveDataset类的collate_fn函数,将其与数据加载器关联起来,在迭代DataLoader时,每次返回一个经过collate_fn处理的批量数据。
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=True,
pin_memory=True, # 将Tensor对象存储到固定内存中的方法
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=1,
num_workers=num_workers,
pin_memory=True,
collate_fn=val_dataset.collate_fn)
在train.py文件中
总结
尽可能简单、详细的介绍UNet 网络中的数据预处理模块的结构和代码。