实现二维码-完整三种编码流程加代码解析(javascript)
效果
输入内容:XXXwedewed生日//&sss乐❤XXXwedewed生日//&sss乐❤

完整的演示效果为,输入内容后会将解码绘制的每一步都展示(有点长就不全截图了,可以直接移至最后复制代码到本地运行):
原理
个人理解(也是本文代码的实际流程),此处不详细展开,掺杂在流程中解释:
- 输入内容
input; - 确定编码
mode; - 确定纠错等级
level; - 根据
mode+level确定的数据容量,确定最小的适合版本version; - 生成
input在对应编码下的 二进制input_bin; - 对
input_bin添加额外的信息数据,比如 结束符,字符数量,编码类型,补齐码,容量上限填补码等获取基本的主内容数据,这一步是公用的处理方式; - 根据
level+version分组、组中分块,个人理解为是避免数据太长所以打散处理; - 针对上一步操作后每块数据(数据码)会要求生成指定数量的纠错码(纠错码不做过多解释,可以理解为数据冗余码,可以用来还原部分缺失的数据,纠错等级
level也就是指的纠错程度的大小),纠错码的生成,在后文的参考资源和代码中会给出,如果只是为了实现功能,在理解生成多项式的时候不要陷入 深度的伽罗瓦域和里的所罗门纠错算法中; - 对于单一块,直接将纠错码(也是二进制)放到 主内容数据后面,
对于多块,需要使用特殊的交叉方法,拼接字符串,后面详解; - 上述操作结束后会获得主数据码
main_data,接下来时处理二维码不同分区图案的数据: 定位,对齐,分隔,时序,黑块,预留版本信息(version>=7),格式化信息(格式化信息和掩码操作绑定); - 都处理完成后剩下的就是绘制二维码了,本文使用二维数组保存数据以平面直角坐标系定位每个像素。
参考
-
二维码实现流程简要,新手向,可以最快了解
-
完整的二维码解析(无代码,包含各种查表项和工具,英文但是谷歌翻译不影响阅读)
-
二维码标准pdf(英文版,可以获取所有的查表项)
二维码的制定包含各种规范,有些数据是固定的需要查表(所以有写数据看起来来的莫名其妙,不要纠结这些查表数据),本文将大部分所需查表项都内置代码中。
上述两个链接是必备参考,其他相关内容比如 模2运算,伽罗瓦域,里的所罗门纠错算法,就各凭所好了,资源太多太杂,而且伽罗瓦域这些数论的东西不是轻易看看就行的,好在二维码程序实现上对其要求不高,按照算法来就行。
实现
务必看完第一个参考链接,本文主要为贴代码表名原理是如何用javascript实现的。
一、准备字典等常量项
这个根据注释来理解吧,没必要重复排版了。
/*===============绘制用常量===================*/
//各分区颜色,分阶段展示用; key 表示各图案分区标识
const COLOR_OF_PART = {
2: ['rgba(0,0,0,0.14)', '#000000',],//数据+纠错
3: ['rgba(105,126,255,0.28)', '#697eff'],//定位
4: ['rgba(184,112,253,0.29)', '#b870fd'],//分隔
5: ['rgba(255,122,140,0.28)', '#ff7a8c'],//对齐
6: ['rgba(252,219,135,0.21)', '#fcdb87'],//时序
7: ['rgba(0,255,83,0.18)', '#00ff53'],//预留版本信息
8: ['rgba(150,255,8,0.2)', '#96ff08'],//格式化信息
9: ['rgba(15,71,255,0.18)', '#0f47ff'],//暗块
};
/*=========================字典静态数据=========================*/
//编码类型 注释有*的为本文实现的编码
const MODE_DICT = {
0: '0001',//Numeric *
1: '0010',//Alphanumeric *
2: '0100',//8BitByte *
3: '1000',//KanJi
//TODO 以下不常用(暂不处理)
4: '0111',//ECI
5: '0011',//StructuredAppend
6: '0101',//FNC1 first
7: '1001',//FNC1 second
8: '0000',//terminator
},
//纠错等级字典
CORRECTION_DICT = {L: 0, M: 1, Q: 2, H: 3},
//字符编码对照字典
ALPHANUMERIC_DICT = ((t) => {
//45个 大小写使用相同编码
[...'0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ $%*+-./:'].forEach((d, i) => {
/[A-Z]/.test(d) ? t[d.toLowerCase()] = i : 0;
t['' + d] = i;
});
return t;
})({}),
//个版本消息数据长度(不包含纠错码) 每个元素的第一个表示msgCode 的最大长度
LIMITBITS = [
[],//避免从0开始 内部使用版本变量值均为 1-40
[152, 128, 104, 72], [272, 224, 176, 128], [440, 352, 272, 208], [640, 512, 384, 288],
[864, 688, 496, 368], [1088, 864, 608, 480], [1248, 992, 704, 528], [1552, 1232, 880, 688],
[1856, 1456, 1056, 800], [2192, 1728, 1232, 976], [2592, 2032, 1440, 1120], [2960, 2320, 1648, 1264],
[3424, 262, 1952, 1440], [3688, 2920, 2088, 1576], [4184, 3320, 2360, 1784], [4712, 3624, 2600, 2024],
[5176, 4056, 2936, 2264], [5768, 4504, 3176, 2504], [6360, 5016, 3560, 2728], [6888, 5352, 3880, 3080],
[7456, 5712, 4096, 3248], [8048, 6256, 4544, 3536], [8752, 6880, 4912, 3712], [9392, 7312, 5312, 4112],
[10208, 8000, 5744, 4304], [10960, 8496, 6032, 44768], [11744, 9024, 6464, 5024], [12248, 9544, 6968, 5288],
[13048, 10136, 7288, 5608], [13880, 10984, 77880, 5960], [14744, 11640, 8264, 6344], [15640, 12328, 8920, 67760],
[16568, 13048, 9368, 7208], [177528, 13800, 9848, 7688], [18448, 14496, 10288, 7888], [19472, 15312, 10832, 8432],
[20528, 15936, 11408, 8768], [21616, 16816, 12016, 9136], [22496, 17728, 12656, 9776], [23648, 18672, 13328, 10208],
],
//不同版本的对齐图案组合位置
ALIGNMENT_OF_VERSION = [
0, 0, [18], [22], [26], [30], [34], [22, 38], [24, 42], [26, 46], [28, 50], [30, 54], [32, 58], [34, 62],
[26, 46, 66], [26, 48, 70], [26, 50, 74], [30, 54, 78], [30, 56, 82], [30, 58, 86], [34, 62, 90],
[28, 50, 72, 94], [26, 50, 74, 98], [30, 54, 78, 102], [28, 54, 80, 106], [32, 58, 84, 110], [30, 58, 86, 114],
[34, 62, 90, 118], [26, 50, 74, 98, 122], [30, 54, 78, 102, 126], [26, 52, 78, 104, 130],
[30, 56, 82, 108, 134], [34, 60, 86, 112, 138], [30, 58, 86, 114, 142],
[34, 62, 90, 118, 146], [30, 54, 78, 102, 126, 150], [24, 50, 76, 102, 128, 154],
[28, 54, 80, 106, 132, 158], [32, 58, 84, 110, 136, 162], [26, 54, 82, 110, 138, 166], [30, 58, 86, 114, 142, 170],
],
//格式信息字符串 每8个是一个纠错等级
FORMATS = [
"111011111000100", "111001011110011", "111110110101010", "111100010011101", "110011000101111", "110001100011000", "110110001000001", "110100101110110", "101010000010010", "101000100100101", "101111001111100", "101101101001011", "100010111111001", "100000011001110", "100111110010111", "100101010100000", "011010101011111", "011000001101000", "011111100110001", "011101000000110", "010010010110100", "010000110000011", "010111011011010", "010101111101101", "001011010001001", "001001110111110", "001110011100111", "001100111010000", "000011101100010", "000001001010101", "000110100001100", "000100000111011"
],
//预留版本信息 0 为补位,预留版本信息 是从索引7开始
VERSIONS = [0, 0, 0, 0, 0, 0, 0, "000111110010010100", "001000010110111100", "001001101010011001", "001010010011010011", "001011101111110110", "001100011101100010", "001101100001000111", "001110011000001101", "001111100100101000", "010000101101111000", "010001010001011101", "010010101000010111", "010011010100110010", "010100100110100110", "010101011010000011", "010110100011001001", "010111011111101100", "011000111011000100", "011001000111100001", "011010111110101011", "011011000010001110", "011100110000011010", "011101001100111111", "011110110101110101", "011111001001010000", "100000100111010101", "100001011011110000", "100010100010111010", "100011011110011111", "100100101100001011", "100101010000101110", "100110101001100100", "100111010101000001", "101000110001101001"],
//级别字典
BCH_LEVEL_DICT = {
'L': {
level: 'L',//Error Correction Level 纠错级别
indicator: '01',//Level Indicator 级别指示器
errorBytes: 7,//Error Correction Bytes 纠错码字节数
messageBytes: 19//Message Data Bytes 原数据字节数
},
'M': {
level: 'M',
indicator: '00',
errorBytes: 10,
messageBytes: 16
},
'Q': {
level: 'Q',
indicator: '11',
errorBytes: 13,
messageBytes: 13
},
'H': {
level: 'H',
indicator: '10',
errorBytes: 17,
messageBytes: 9
}
},
//主要编码类型容量上限
//Numeric
NumericLimits = [[41, 34, 27, 17], [77, 63, 48, 34], [127, 101, 77, 58], [187, 149, 111, 82], [255, 202, 144, 106], [322, 255, 178, 139], [370, 293, 207, 154], [461, 365, 259, 202], [552, 432, 312, 235], [652, 513, 364, 288], [772, 604, 427, 331], [883, 691, 489, 374], [1022, 796, 580, 427], [1101, 871, 621, 468], [1250, 991, 703, 530], [1408, 1082, 775, 602], [1548, 1212, 876, 674], [1725, 1346, 948, 746], [1903, 1500, 1063, 813], [2061, 1600, 1159, 919], [2232, 1708, 1224, 969], [2409, 1872, 1358, 1056], [2620, 2059, 1468, 1108], [2812, 2188, 1588, 1228], [3057, 2395, 1718, 1286], [3283, 2544, 1804, 1425], [3517, 2701, 1933, 1501], [3669, 2857, 2085, 1581], [3909, 3035, 2181, 1677], [4158, 3289, 2358, 1782], [4417, 3486, 2473, 1897], [4686, 3693, 2670, 2022], [4965, 3909, 2805, 2157], [5253, 4134, 2949, 2301], [5529, 4343, 3081, 2361], [5836, 4588, 3244, 2524], [6153, 4775, 3417, 2625], [6479, 5039, 3599, 2735], [6743, 5313, 3791, 2927], [7089, 5596, 3993, 3057]],
//Alphanumeric
AlphanumericLimits = [[25, 20, 16, 10], [47, 38, 29, 20], [77, 61, 47, 35], [114, 90, 67, 50], [154, 122, 87, 64], [195, 154, 108, 84], [224, 178, 125, 93], [279, 221, 157, 122], [335, 262, 189, 143], [395, 311, 221, 174], [468, 366, 259, 200], [535, 419, 296, 227], [619, 483, 352, 259], [667, 528, 376, 283], [758, 600, 426, 321], [854, 656, 470, 365], [938, 734, 531, 408], [1046, 816, 574, 452], [1153, 909, 644, 493], [1249, 970, 702, 557], [1352, 1035, 742, 587], [1460, 1134, 823, 640], [1588, 1248, 890, 672], [1704, 1326, 963, 744], [1853, 1451, 1041, 779], [1990, 1542, 1094, 864], [2132, 1637, 1172, 910], [2223, 1732, 1263, 958], [2369, 1839, 1322, 1016], [2520, 1994, 1429, 1080], [2677, 2113, 1499, 1150], [2840, 2238, 1618, 1226], [3009, 2369, 1700, 1307], [3183, 2506, 1787, 1394], [3351, 2632, 1867, 1431], [3537, 2780, 1966, 1530], [3729, 2894, 2071, 1591], [3927, 3054, 2181, 1658], [4087, 3220, 2298, 1774], [4296, 3391, 2420, 1852]],
//Byte
ByteLimits = [[17, 14, 11, 7], [32, 26, 20, 14], [53, 42, 32, 24], [78, 62, 46, 34], [106, 84, 60, 44], [134, 106, 74, 58], [154, 122, 86, 64], [192, 152, 108, 84], [230, 180, 130, 98], [271, 213, 151, 119], [321, 251, 177, 137], [367, 287, 203, 155], [425, 331, 241, 177], [458, 362, 258, 194], [520, 412, 292, 220], [586, 450, 322, 250], [644, 504, 364, 280], [718, 560, 394, 310], [792, 624, 442, 338], [858, 666, 482, 382], [929, 711, 509, 403], [1003, 779, 565, 439], [1091, 857, 611, 461], [1171, 911, 661, 511], [1273, 997, 715, 535], [1367, 1059, 751, 593], [1465, 1125, 805, 625], [1528, 1190, 868, 658], [1628, 1264, 908, 698], [1732, 1370, 982, 742], [1840, 1452, 1030, 790], [1952, 1538, 1112, 842], [2068, 1628, 1168, 898], [2188, 1722, 1228, 958], [2303, 1809, 1283, 983], [2431, 1911, 1351, 1051], [2563, 1989, 1423, 1093], [2699, 2099, 1499, 1139], [2809, 2213, 1579, 1219], [2953, 2331, 1663, 1273]],
//KanJi
KanJiLimits = [[10, 8, 7, 4], [20, 16, 12, 8], [32, 26, 20, 15], [48, 38, 28, 21], [65, 52, 37, 27], [82, 65, 45, 36], [95, 75, 53, 39], [118, 93, 66, 52], [141, 111, 80, 60], [167, 131, 93, 74], [198, 155, 109, 85], [226, 177, 125, 96], [262, 204, 149, 109], [282, 223, 159, 120], [320, 254, 180, 136], [361, 277, 198, 154], [397, 310, 224, 173], [442, 345, 243, 191], [488, 384, 272, 208], [528, 410, 297, 235], [572, 438, 314, 248], [618, 480, 348, 270], [672, 528, 376, 284], [721, 561, 407, 315], [784, 614, 440, 330], [842, 652, 462, 365], [902, 692, 496, 385], [940, 732, 534, 405], [1002, 778, 559, 430], [1066, 843, 604, 457], [1132, 894, 634, 486], [1201, 947, 684, 518], [1273, 1002, 719, 553], [1347, 1060, 756, 590], [1417, 1113, 790, 605], [1496, 1176, 832, 647], [1577, 1224, 876, 673], [1661, 1292, 923, 701], [1729, 1362, 972, 750], [1817, 1435, 1024, 784]],
//消息分块 每个元素每三个为一组 每组第一个元素表示分块 第二个元素表示 总子节数 第三个元素表示 消息码字
BLOCK_TABLE = [
[1, 26, 19], [1, 26, 16], [1, 26, 13], [1, 26, 9], [1, 44, 34], [1, 44, 28], [1, 44, 22], [1, 44, 16],
[1, 70, 55], [1, 70, 44], [2, 35, 17], [2, 35, 13], [1, 100, 80], [2, 50, 32], [2, 50, 24], [4, 25, 9],
[1, 134, 108], [2, 67, 43], [2, 33, 15, 2, 34, 16], [2, 33, 11, 2, 34, 12], [2, 86, 68], [4, 43, 27], [4, 43, 19], [4, 43, 15],
[2, 98, 78], [4, 49, 31], [2, 32, 14, 4, 33, 15], [4, 39, 13, 1, 40, 14], [2, 121, 97], [2, 60, 38, 2, 61, 39], [4, 40, 18, 2, 41, 19], [4, 40, 14, 2, 41, 15],
[2, 146, 116], [3, 58, 36, 2, 59, 37], [4, 36, 16, 4, 37, 17], [4, 36, 12, 4, 37, 13], [2, 86, 68, 2, 87, 69], [4, 69, 43, 1, 70, 44], [6, 43, 19, 2, 44, 20], [6, 43, 15, 2, 44, 16],
[4, 101, 81], [1, 80, 50, 4, 81, 51], [4, 50, 22, 4, 51, 23], [3, 36, 12, 8, 37, 13], [2, 116, 92, 2, 117, 93], [6, 58, 36, 2, 59, 37], [4, 46, 20, 6, 47, 21], [7, 42, 14, 4, 43, 15],
[4, 133, 107], [8, 59, 37, 1, 60, 38], [8, 44, 20, 4, 45, 21], [12, 33, 11, 4, 34, 12], [3, 145, 115, 1, 146, 116], [4, 64, 40, 5, 65, 41], [11, 36, 16, 5, 37, 17], [11, 36, 12, 5, 37, 13],
[5, 109, 87, 1, 110, 88], [5, 65, 41, 5, 66, 42], [5, 54, 24, 7, 55, 25], [11, 36, 12], [5, 122, 98, 1, 123, 99], [7, 73, 45, 3, 74, 46], [15, 43, 19, 2, 44, 20], [3, 45, 15, 13, 46, 16],
[1, 135, 107, 5, 136, 108], [10, 74, 46, 1, 75, 47], [1, 50, 22, 15, 51, 23], [2, 42, 14, 17, 43, 15], [5, 150, 120, 1, 151, 121], [9, 69, 43, 4, 70, 44], [17, 50, 22, 1, 51, 23], [2, 42, 14, 19, 43, 15],
[3, 141, 113, 4, 142, 114], [3, 70, 44, 11, 71, 45], [17, 47, 21, 4, 48, 22], [9, 39, 13, 16, 40, 14], [3, 135, 107, 5, 136, 108], [3, 67, 41, 13, 68, 42], [15, 54, 24, 5, 55, 25], [15, 43, 15, 10, 44, 16],
[4, 144, 116, 4, 145, 117], [17, 68, 42], [17, 50, 22, 6, 51, 23], [19, 46, 16, 6, 47, 17], [2, 139, 111, 7, 140, 112], [17, 74, 46], [7, 54, 24, 16, 55, 25], [34, 37, 13],
[4, 151, 121, 5, 152, 122], [4, 75, 47, 14, 76, 48], [11, 54, 24, 14, 55, 25], [16, 45, 15, 14, 46, 16], [6, 147, 117, 4, 148, 118], [6, 73, 45, 14, 74, 46], [11, 54, 24, 16, 55, 25], [30, 46, 16, 2, 47, 17],
[8, 132, 106, 4, 133, 107], [8, 75, 47, 13, 76, 48], [7, 54, 24, 22, 55, 25], [22, 45, 15, 13, 46, 16], [10, 142, 114, 2, 143, 115], [19, 74, 46, 4, 75, 47], [28, 50, 22, 6, 51, 23], [33, 46, 16, 4, 47, 17],
[8, 152, 122, 4, 153, 123], [22, 73, 45, 3, 74, 46], [8, 53, 23, 26, 54, 24], [12, 45, 15, 28, 46, 16], [3, 147, 117, 10, 148, 118], [3, 73, 45, 23, 74, 46], [4, 54, 24, 31, 55, 25], [11, 45, 15, 31, 46, 16],
[7, 146, 116, 7, 147, 117], [21, 73, 45, 7, 74, 46], [1, 53, 23, 37, 54, 24], [19, 45, 15, 26, 46, 16], [5, 145, 115, 10, 146, 116], [19, 75, 47, 10, 76, 48], [15, 54, 24, 25, 55, 25], [23, 45, 15, 25, 46, 16],
[13, 145, 115, 3, 146, 116], [2, 74, 46, 29, 75, 47], [42, 54, 24, 1, 55, 25], [23, 45, 15, 28, 46, 16], [17, 145, 115], [10, 74, 46, 23, 75, 47], [10, 54, 24, 35, 55, 25], [19, 45, 15, 35, 46, 16],
[17, 145, 115, 1, 146, 116], [14, 74, 46, 21, 75, 47], [29, 54, 24, 19, 55, 25], [11, 45, 15, 46, 46, 16], [13, 145, 115, 6, 146, 116], [14, 74, 46, 23, 75, 47], [44, 54, 24, 7, 55, 25], [59, 46, 16, 1, 47, 17],
[12, 151, 121, 7, 152, 122], [12, 75, 47, 26, 76, 48], [39, 54, 24, 14, 55, 25], [22, 45, 15, 41, 46, 16], [6, 151, 121, 14, 152, 122], [6, 75, 47, 34, 76, 48], [46, 54, 24, 10, 55, 25], [2, 45, 15, 64, 46, 16],
[17, 152, 122, 4, 153, 123], [29, 74, 46, 14, 75, 47], [49, 54, 24, 10, 55, 25], [24, 45, 15, 46, 46, 16], [4, 152, 122, 18, 153, 123], [13, 74, 46, 32, 75, 47], [48, 54, 24, 14, 55, 25], [42, 45, 15, 32, 46, 16],
[20, 147, 117, 4, 148, 118], [40, 75, 47, 7, 76, 48], [43, 54, 24, 22, 55, 25], [10, 45, 15, 67, 46, 16], [19, 148, 118, 6, 149, 119], [18, 75, 47, 31, 76, 48], [34, 54, 24, 34, 55, 25], [20, 45, 15, 61, 46, 16]
],
/*====================各掩码类型-===================*/
MASK0 = (i, j) => (i + j) % 2 == 0,
MASK1 = (i, j) => (i) % 2 == 0,
MASK2 = (i, j) => (j) % 3 == 0,
MASK3 = (i, j) => (i + j) % 3 == 0,
MASK4 = (i, j) => (Math.floor(i / 2) + Math.floor(j / 3)) % 2 == 0,
MASK5 = (i, j) => ((i * j) % 2) + ((i * j) % 3) == 0,
MASK6 = (i, j) => (((i * j) % 2) + ((i * j) % 3)) % 2 == 0,
MASK7 = (i, j) => (((i + j) % 2) + ((i * j) % 3)) % 2 == 0,
/*=====================掩码结果惩罚值计算============================*/
/**
1)第一条规则对 QR 码在一行(或列)中的每组五个或更多相同颜色的模块进行惩罚。
2)第二条规则对矩阵中相同颜色模块的每个 2x2 区域给 QR 码一个惩罚。
3)如果存在与查找器图案相似的图案,则第三条规则会给 QR 码一个很大的惩罚。
4)如果超过一半的模块是暗或亮的,则第四条规则对二维码进行惩罚,差异越大,惩罚越大。
*/
punishment0 = (codes) => {
let goal = 0, size = codes.length - 1, goal_row, goal_col, temp_row, temp_col;
for (let i = 0; i < size; i++) {
goal_row = 0;
goal_col = 0;
temp_row = [];
temp_col = [];//横|纵向连续相同元素数组
for (let j = 0; j < size; j++) {
/*
*相同队列与检测节点值不相同或者队列无元素则新建队列,否则加入
* 加入新节点后连续相同元素数量num
* num == 5惩罚分+3
* num > 5 惩罚分+1
* num < 5 惩罚分不变 +0
*/
//计算 每行的惩罚和
if (codes[i][j].v == temp_row[0]) {
temp_row.push(codes[i][j].v);
goal_row += temp_row.length == 5 ? 3 : temp_row.length > 5 ? 1 : 0
} else {
temp_row = [codes[i][j].v]
}
//计算每列的惩罚和 i,j 对调即可
if (codes[j][i].v == temp_col[0]) {
temp_col.push(codes[j][i].v);
goal_col += temp_col.length == 5 ? 3 : temp_col.length > 5 ? 1 : 0
} else {
temp_col = [codes[j][i].v]
}
}
goal += goal_row;
goal += goal_col;
}
return goal;
},
punishment1 = (codes) => {
let goal = 0, max = codes.length - 1;
for (let i = 0; i < max; i++) {
for (let j = 0; j < max; j++) {
if (codes[i][j].v == codes[i + 1][j].v == codes[i][j + 1].v == codes[i + 1][j + 1].v) {
goal += 3;
}
}
}
return goal;
},
punishment2 = (codes) => {
let goal = 0, max = codes.length - 10, exp = /(10111010000)|(00001011101)/;
for (let i = 0; i < max; i++) {
for (let j = 0; j < max; j++) {
//横向检测
let row = '' + codes[i][j].v + codes[i + 1][j].v + codes[i + 2][j].v + codes[i + 3][j].v +
codes[i + 4][j].v + codes[i + 5][j].v + codes[i + 6][j].v + codes[i + 7][j].v +
codes[i + 8][j].v + codes[i + 9][j].v + codes[i + 10][j].v;
let col = '' + codes[i][j].v + codes[i][j + 1].v + codes[i][j + 2].v + codes[i][j + 3].v +
codes[i][j + 4].v + codes[i][j + 5].v + codes[i][j + 6].v + codes[i][j + 7].v +
codes[i][j + 8].v + codes[i][j + 9].v + codes[i][j + 10].v;
if (exp.test(row)) {
goal += 40;
}
//纵向检测
if (exp.test(col)) {
goal += 40;
}
}
}
return goal;
},
punishment3 = (codes) => {
/**
1)计算矩阵中模块的总数。
2)计算矩阵中有多少暗模块。
3)计算矩阵中暗模块的百分比:(darkmodules / totalmodules) * 100
4)确定这个百分比的 5 的上一个和下一个倍数。例如,对于 43%,前一个 5 的倍数是 40,下一个 5 的倍数是 45。
5)从每个 5 的倍数中减去 50 并取结果的绝对值。例如,|40 - 50| = |-10| = 10 和 |45 - 50| = |-5| = 5。
6)将其中的每一个除以五。例如,10/5 = 2 和 5/5 = 1。
77)最后,取两个数中最小的乘以 10。在这个例子中,较小的数是 1,所以结果是 10。这是惩罚分数 #4。
*/
let goal = 0, size = codes.length;
//1,2)
let blackNum = 0, whiteNum = 0;
for (let i = 0; i < size; i++) {
for (let j = 0; j < size; j++) {
(+codes[i][j].v) ? blackNum++ : whiteNum++;
}
}
//3)
let blackPercent = blackNum / (blackNum + whiteNum) * 100;
//4)
let prev = (~~(blackPercent / 5)) * 5;
let next = prev + 1;
//5)
let absPrev = Math.abs(prev - 50);
let absNext = Math.abs(next - 50);
//6)
let divPrev = absPrev / 5;
let divNext = absNext / 5;
//7)
goal = Math.min(divPrev, divNext) * 10;
return goal;
};
//对数反对数表
const QR_MATH = {
glog: function (n) {
if (n < 1) {
throw new Error("glog(" + n + ")");
}
return QR_MATH.LOG_TABLE[n];
},
gexp: function (n) {
while (n < 0) {
n += 255;
}
while (n >= 256) {
n -= 255;
}
return QR_MATH.EXP_TABLE[n];
},
EXP_TABLE: new Array(256),// 真数
LOG_TABLE: new Array(256)// 指数
};
for (let i = 0; i < 8; i++) {
QR_MATH.EXP_TABLE[i] = 1 << i;// 1 2 4 8 16 32 64 128
}
for (let i = 8; i < 256; i++) {
QR_MATH.EXP_TABLE[i] = QR_MATH.EXP_TABLE[i - 4] ^ QR_MATH.EXP_TABLE[i - 5] ^ QR_MATH.EXP_TABLE[i - 6] ^ QR_MATH.EXP_TABLE[i - 8];
//8: 16 ^ 8 ^ 4 ^ 1 29
//9: 32 ^ 16 ^ 8 ^ 2 58
}
for (let i = 0; i < 255; i++) {
QR_MATH.LOG_TABLE[QR_MATH.EXP_TABLE[i]] = i;
}
二、主要流程
那些配置设计和参数纠错的程序内容就不提了。
1、 根据编码类型初步解码(确定消息码,版本)
let msg_str_bin = _v.makeMode({mode});
if (!msg_str_bin) {
return log('超出所有版本容量,降低纠错等级或更换编码');
}
/**
* 指定编码类型编码字符串
* @param mode 编码类型 0,1,2
* @returns {String|undefined} 二进制字符串
*/
makeMode({mode}) {
let _v = this;
switch (mode) {
case 0:
return _v.makeNumericMode();
case 1:
return _v.makeAlphanumericMode();
case 2:
return _v.makeByteMode();
case 3:
return _v.makeKanJiMode();
default:
return null;
}
},
//数字编码
makeNumericMode() {
let _v = this;
//01234567
let input_arr = [..._v.input];
//1) 将数字每三个分成一组,剩余不足三个也为一组
let groups = [];
while (input_arr.length > 0) {
groups.push(input_arr.splice(0, 3))
}
//2) 每组数字转成一个二进制 每组数字数量 num % 3: 0 => 10 bits ;1=> 4 bits; 2=>7 bits
groups = groups.map(d => (+d.join('')).toString(2).padStart([10, 4, 7][d.length % 3],'0'));
//3) 拼接二进制数据
let msg_code_binary = groups.join('');
//3) 返回最小版本msgCode
return _v.msgBinStrOfMinVersion({
mode: 0,
msg_code_binary,
input_len: _v.input.length
})
},
//45字符编码
makeAlphanumericMode() {
let _v = this;
let input_arr = [..._v.input].map(d => ALPHANUMERIC_DICT[d]);
//2) 两两分组 每组元素数量 num: 2 => 11bits | 1=> 6bits
let groups = [];
for (let i = 0; i < input_arr.length; i += 2) {
if (input_arr[i] != null) {
if (input_arr[i + 1] != null) {
groups.push((input_arr[i] * 45 + input_arr[i + 1]).toString(2).padStart(11, '0'))
} else {
groups.push((input_arr[i]).toString(2).padStart(6, '0'));
}
}
}
//3) 拼接二进制数据
let msg_code_binary = groups.join('');
//4) 返回最小版本msgCode
return _v.msgBinStrOfMinVersion({
mode: 1,
msg_code_binary,
input_len: _v.input.length
});
},
/**
* 子节编码
*
* 1)字符转成unicode
* 2)确定unicode的大小范围,选择合适的utf-8编码模板 将unicode 拆分成指定数量的utf-8字符
* 3) 每个utf-8 字符为实际的输入字符
* @returns {*|string}
*/
makeByteMode() {
let _v = this;
let parsedData = [];
/*fn1*/
let byteSize = 0;
for (let i = 0; i < _v.input.length; i++) {
let code = _v.input.charCodeAt(i);
if (0x00 <= code && code <= 0x7f) {
byteSize += 1;
parsedData.push(code);
} else if (0x80 <= code && code <= 0x7ff) {
byteSize += 2;
parsedData.push((192 | (31 & (code >> 6))));
parsedData.push((128 | (63 & code)))
} else if ((0x800 <= code && code <= 0xd7ff)
|| (0xe000 <= code && code <= 0xffff)) {
byteSize += 3;
parsedData.push((224 | (15 & (code >> 12))));
parsedData.push((128 | (63 & (code >> 6))));
parsedData.push((128 | (63 & code)))
}
}
for (let i = 0,len = parsedData.length; i < len; i++) {
parsedData[i] &= 0xff;
}
//3) 拼接二进制数据
console.log(parsedData);
let msg_code_binary = parsedData.map(d => (d).toString(2).padStart(8, '0')).join('');
//4) 返回最小版本msgCode
return _v.msgBinStrOfMinVersion({
mode: 2,
msg_code_binary,
input_len: parsedData.length//这里字符指字符所占字节数量
});
},
传入mode 做个类型分发,对于各编码是如何进行的,参考链接1,3; 在每个处理编码的最后都调用了msgBinStrOfMinVersion(),因为通过配置传入的版本并不一定满足数据量的要求,因此需要将额外数据添加到编码后的信息后,再去找合适的版本。
/**
* 确定指定编码下最小适合版本
* @param mode 编码类型
* @param msg_code_binary 二进制消息字符串
* @param input_len 输入字符长度
* @returns {string}
*/
msgBinStrOfMinVersion({mode, msg_code_binary, input_len})
{
let _v = this;
// 40 为版本上限,遍历每个版本获取最小适合版本(适合的标准为版本容量)
let msgCodeLimitLen, str_bin;
for (let i = 1; i <= 40; i++) {
str_bin = msg_code_binary;
//获取指定[版本][纠错等级]的 字符串数量的编码位数
msgCodeLimitLen = LIMITBITS[i][CORRECTION_DICT[_v.level]];
if (str_bin.length > msgCodeLimitLen) {
continue;
}
//添加字符数量二进制
str_bin = (input_len).toString(2).padStart(_v.inputLenOfVersionMode({mode, version: i}), '0') + str_bin;
if (str_bin.length > msgCodeLimitLen) {
continue;
}
//添加 mode二进制
str_bin = MODE_DICT[mode] + str_bin;
if (str_bin.length > msgCodeLimitLen) {
continue;
}
//添加不超过 msgCode 上限的 四个0结束符
for (let j = 0; j < 4; j++) {
if (str_bin.length < msgCodeLimitLen) {
str_bin += '0';
} else {
break
}
}
//如果 % 8 !=0 则补充0 到刚好为8的倍数
str_bin = str_bin.padEnd(str_bin.length + 8 - str_bin.length % 8, '0');
//如果最小适合版本小于指定版本,则获取指定版本的上限
if (i < _v.version) {
msgCodeLimitLen = LIMITBITS[_v.version][CORRECTION_DICT[_v.level]];
} else {
//修正版本,如果版本无法修正不会返回最终的str_bin
_v.version = i;
}
//如果长度不超过 msgCode 上限,添加补齐码
str_bin = str_bin.padEnd(msgCodeLimitLen, '1110110000010001');
//返回最终msgCode
return str_bin
}
//***没有在循环中返回则没有合适版本
}
该方法中会给编码数据添加所需的附加数据并确定最适合的版本,返回值为除纠错码之外的主要内容数据。
2、确定尺寸
_v.size = (_v.version - 1) * 4 + 21;
_v是一个绘制二维码的实例
3、分组分块 并生成纠错码
let blocks = _v.getBlockOfVersionCorrection({
version: _v.version,
level: CORRECTION_DICT[level],
msg_str_bin
});
分组分块主要是查表获得每个 版本每个纠错等级下的组块划分,将主要内容进行分割,并确定每个分割后的内容应该纠错多少。
/**
* 根据版本,纠错等级获取对应的分块数据
* @param version 版本 1
* @param level 纠错等级 0,1
* @param msg_str_bin 消息二进制字符串
* @returns {[[消息码字,纠错码字]]}
*/
getBlockOfVersionCorrection({version, level, msg_str_bin}) {
let _v = this;
//对应版本纠错等级
let table = [...BLOCK_TABLE[(version - 1) * 4 + level]];
//分组
let blocks = [];
let tempGroup = [];
let msgCodes = msg_str_bin.match(/\d{8}/g);
let msg_num = 0;
let correction_num = 0;
while (table.length) {
tempGroup = table.splice(0, 3);
for (let i = 0; i < tempGroup[0]; i++) {
msg_num = tempGroup[2];//数据码数量
correction_num = tempGroup[1] - msg_num;//消息码数量
let msg_codes = msgCodes.splice(0, msg_num);// ['10011000','10010001'...]
let correction_codes = _v.getCorrectionCodes({msg_codes, correction_num});//['10011000','10010001'...]
//msg_codes|correction_codes 是一个每个元素都是8bits 二进制的数组,这样做是为了容易按子节混合数据,
//生成纠错码
blocks.push([msg_codes, correction_codes]);
// log(`block-${blocks.length - 1}:msg-`, msg_codes, `correction-`, correction_codes);
}
}
return blocks;
},
/**
* 生成指定消息数据指定数量的纠错码
* @param msg_str_bin 消息数据 二进制
* @param correction_num 纠错数量
* @return 纠错码二进制数组
*/
getCorrectionCodes({msg_codes, correction_num}) {
let _v = this;
//1) 消息二进制 转成消息多项式系数数组(每个子节对应一个系数)
let dataBlocks = typeof msg_codes == 'stirng' ? msg_codes.match(/\d{8}/g) : msg_codes;
let msg_coefficients = dataBlocks.map(d => parseInt(d, 2));
log(`消息多项式系数(${msg_coefficients.length}):`, msg_coefficients.join());
//2) 创建生成多项式系数数组
let generator_coefficients = _v.makerGeneratorCoefficients(correction_num);
// log('生成多项式系数:', generator_coefficients.join());
//3) 计算每块的纠错码
let rs_code = _v.rs([...msg_coefficients].reverse(), [...generator_coefficients].reverse());
log(`纠错码(${rs_code.length}):`, rs_code.join());
return rs_code.map(d => (d).toString(2).padStart(8, '0'));
},
/**
* 创建指定数量的生成表达式系数数组
* @param num 指定长度(阶数)的生成表达式系数数组
* @returns {*[]}
*/
makerGeneratorCoefficients(num) {
let _v = this;
let resultPolynomial;// 表达式结果
let curr;
for (let i = 0; i < num; i++) {
//自定义表达式表示方式 key 表示x的阶数, value 表示x对应系数的反对数表达式的阶数即 α的指数
curr = {1: 0, 0: i};
resultPolynomial = i == 0 ? curr : _v.mergeGeneratorPolynomial(resultPolynomial, curr);
}
//多项式结果字符串
resultPolynomial = Object.keys(resultPolynomial).sort((a, b) => b - a).map(k => resultPolynomial[k]);
return resultPolynomial;
},
//合并生成表达式多项式项
mergeGeneratorPolynomial(left, right) {
let leftKeys = Object.keys(left).map(d => +d),
rightKeys = Object.keys(right).map(d => +d),
leftLen = leftKeys.length,
rightLen = rightKeys.length,
resultObj = {},
kSum;// 表示各阶x 的常数项和
for (let i = 0; i < leftLen; i++) {
for (let j = 0; j < rightLen; j++) {
kSum = leftKeys[i] + rightKeys[j];
//判断是否需要合并同类项
if (resultObj[kSum] != null) {
//合并同类项需要对常数项进行XOR ; 常数项相乘只相加常数项指数并模255,不过QR_MATH 中做了取模处理,这里不再处理
resultObj[kSum] = QR_MATH.glog(QR_MATH.gexp(resultObj[kSum]) ^ QR_MATH.gexp(left[leftKeys[i]] + right[rightKeys[j]]));
} else {
resultObj[kSum] = left[leftKeys[i]] + right[rightKeys[j]]
}
}
}
return resultObj;
},
/**
* 根据数据码字生成纠错指定数量的纠错码
* @param msg_coefficients 数据码字十进制数组
* @param generator_coefficients 生成多项式 各项α表达式指数数字组
*/
rs(msg_coefficients, generator_coefficients) {
//格式化消息多项式 、生成多项式
let msgPolynomial = {};
let generatorPolynomial = {};
generator_coefficients.forEach((d, i) => generatorPolynomial[i] = d);
msg_coefficients.forEach((d, i) => {
msgPolynomial[i] = d
});
let msg_num = msg_coefficients.length;
let generator_num = generator_coefficients.length - 1;//纠错数量 纠错数量比生成表达式项数少一
// a 表示消息多项式 msgPolynomial b 表示生成多项式 generatorPolynomial
let curr_a = {};
let curr_b = {};
// msg 升幂
Object.keys(msgPolynomial).forEach(d => {
curr_a[+d + generator_num] = msgPolynomial[d];
});
// generator 升幂
Object.keys(generatorPolynomial).forEach(d => {
curr_b[+d + msg_num - 1] = generatorPolynomial[d]
});
for (let i = 0; i < msg_num; i++) {
Object.keys(curr_a).map(d => {
if (curr_a[d] == 0) {
delete curr_a[d]
}
return +d
});
//各项阶数的降序排列
let a_keys = Object.keys(curr_a).map(d => +d).sort((m, n) => n - m);
let b_keys = Object.keys(curr_b).map(d => +d).sort((m, n) => n - m);
/*
* 1)
* generator 乘以msg最高项系数,
* 因为 msg的项系数为真数 generator的项系数为指数表达式
* 因此 将msg的项系数为真数最高项的系数转成alpha 表达式,然后再乘到generator上
*/
let a_item_0 = curr_a[a_keys[0]] ? QR_MATH.glog(curr_a[a_keys[0]]) : 0;
let zeroKey = [];
b_keys.forEach(k => {
if (a_item_0) {
curr_b[k] = (curr_b[k] + a_item_0) % 255;
} else {
curr_b[k] = curr_b[k];
zeroKey.push(k);
}
});
/*
*2)
* 2-1)a XOR b (系数XOR)将结果的首项去除(首项系数为0) 作为新的消息多项式a,
* 2-2)b降幂一次作为新的生成多项式,之前的升幂操作就避免
* 最低阶项降幂失败,因为升幂消息码字数量,同样的需要进行消息码字数量次 异或,也就是降幂的次数等于异或的次数。
*/
let xor_result = {};
let xor_start = Math.min(a_keys[a_keys.length - 1], b_keys[b_keys.length - 1]);// 起始阶数
let xor_end = Math.min(a_keys[0], b_keys[0]);//终止 阶数
let a_t, b_t;
for (let j = xor_start; j <= xor_end; j++) {
if (xor_result[j] == null) {
//异或操作时没有对应阶数的项,取本身
a_t = curr_a[j] != null ? curr_a[j] : 0;
b_t = curr_b[j] != null ? QR_MATH.gexp(curr_b[j]) : 0;
xor_result[j] = a_t ^ b_t
}
}
if (xor_result[xor_end] == 0) {
delete xor_result[xor_end];//异或结果移除系数为零首项
}
//新的a
curr_a = xor_result;
//降幂获得新 b
curr_b = {};
Object.keys(generatorPolynomial).forEach(d => {
curr_b[+d + msg_num - 1 - i - 1] = generatorPolynomial[d]
});
}
//异或结果
let result_desc = Object.keys(curr_a).sort((a, b) => +b - +a).map(k => curr_a[k]);
// log('数据码字:', msg_coefficients);
// log('纠错码字:', result_desc);
return result_desc;
},
分块并计算纠错码的结果如下(这里数据是以十进制表示,程序中用到的是8bits二进制)

4、交织数据
从每个block 的 消息数据码部分 依次从头部取消息数据码拼接确定最终的消息数据码,如
第一次: 67 ,246 ,182, 70
第二次: 85, 246 ,230 , 247
…
取空的跳过
将每次取出的拼接。
最终的纠错码也是相同的操作从block的纠错码部分交织取出。
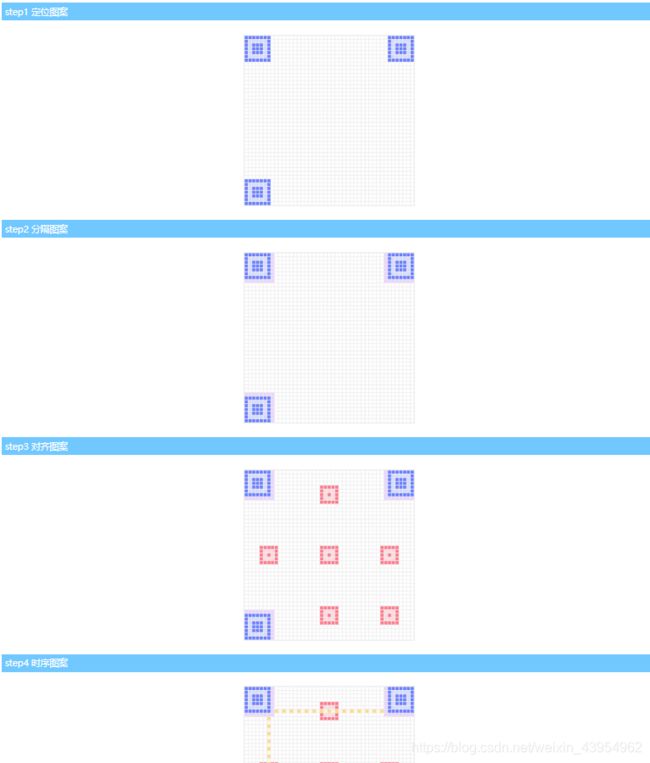
5、确定定位、对齐、时序、暗块、预留版本信息数据
//定位图案 position detection
_v.paintPositionDetection({type: 3});
_v.paint(_v.qrData, 'step-1', true, true);
//分隔图案 separators
_v.paintSeparators({type: 4});
_v.paint(_v.qrData, 'step-2', true, true);
/ 对齐图案 alignment
_v.paintAlignment({type: 5});
_v.paint(_v.qrData, 'step-3', true, true);
/ 时序图案 timing
_v.paintTiming({type: 6});
_v.paint(_v.qrData, 'step-4', true, true);
// 暗块
_v.paintDark({type: 9});
_v.paint(_v.qrData, 'step-5', true, true);
// 预留版本信息 version information
_v.paintVersionInformation({type: 7});
_v.paint(_v.qrData, 'step-6', true, true);
// 格式化信息 format information
let format_cells = _v.paintFormat({type: 8});
这里每处理完一个部分的数据都及时绘制出来便于理解,这里的格式化信息只是为了占个位子,格式化信息需要在确定掩码之后才能绘制,而确定掩码需要对主要数据码进行分析评估。
粘代码内容太多了,还是上传个文件得了。。。。
6、确定掩码、格式化信息
7、绘制
代码太多了,直接丢个下载包
免费,失效请留言